
煤与瓦斯突出预测的随机森林模型
2014-01-31 12:10温廷新张波邵良杉
计算机工程与应用 2014年10期
温廷新,张波,邵良杉
WEN Tingxin,ZHANG Bo,SHAO Liangshan
辽宁工程技术大学系统工程研究所,辽宁葫芦岛125105
System Engineering Institute,Liaoning Technological University,Huludao,Liaoning 125105,China
1 引言
随着煤矿开采深度和开采强度的增加,以及复杂的地质条件和应力环境变化等因素导致各种动态灾害的发生。其中,煤与瓦斯突出是煤矿进行深部开采过程中一个主要的动力灾害。我国煤矿开采场众多,煤与瓦斯突出是最为常见却危害最为严重的事故,煤与瓦斯突出问题日益显著[1-2]。煤与瓦斯突出是另一种类型的瓦斯特殊涌出,是围岩和煤体内部聚积的大量潜能的快速释放。煤与瓦斯突出能够在短时间内向巷道喷出大量瓦斯及碎煤,破坏巷道内的设施和风流状态,直接危害人的生命,造成人员伤亡和财产损失[3-4]。我国煤矿生产每年都会因为煤与瓦斯突出导致数百人伤亡,煤与瓦斯突出是煤矿安全生产的巨大威胁。因此,煤与瓦斯突出预测研究是煤矿工程中值得重视的研究领域,构建有效的煤与瓦斯突出预测模型对煤与瓦斯突出实现有效预测具有重大意义。
煤与瓦斯突出预测方法是指导煤与瓦斯突出防治工作的前提,目前对于煤与瓦斯突出预测和评价已经出现很多研究方法。其中,刘俊娥等[5]人用支持向量机方法对煤与瓦斯预测作评价;郭德勇等[6]人在煤与瓦斯预测中运用了神经网络模型;高卫东[7]运用Fisher判别法预测煤与瓦斯突出;以及还有时间序列法[8-9]等对煤与瓦斯突出作预测。虽然各位学者在煤与瓦斯突出预测和监控问题中提出了自己的方法,每种方法都有各自的优点,取得较好的应用效果,促进了该研究领域向前发展,但各方法也有自己的不足,如神经网络存在过学习、收敛速度慢,支持向量机依赖于核参数和惩罚参数的选取等缺陷。再加上煤矿井下深部开采所处的是一个自然的环境,地质条件以及外界因素复杂,影响煤与瓦斯突出的因素多样,以及因素之间存在一定的相关性,传统的预测方法在预测结果上与实际情况会存在一定出入,煤与瓦斯突出等级的正确预测率仍需要进一步提高。
在煤与瓦斯突出影响因素分析中,对选取的相关程度较高的影响因素,利用因子分析提取公共因子,进行因素间的浓缩,减少影响因素之间的相关性,然后以分析得到的影响因素共同作为随机森林的输入变量,用随机森林算法进行训练预测。随机森林算法是基于决策树(decision tree)的分类器集成算法,融合了Bagging和随机特征选取两大机器学习技术[10]。随机森林具有需要调整的参数较少、分类速度很快,能有效处理高维大样本数据等特点,它避免了决策树中出现的过拟合问题。因此,文中基于因子分析建立了煤与瓦斯突出预测的随机森林模型,将其运用到实际工程当中,验证其预测模型的有效性。
2 相关理论
2.1 因子分析
因子分析(Factor Analysis)是多元统计分析的一个重要分支,是由英国心理学家C.Spearman提出的[11-13]。因子分析是通过对变量之间关系的研究,找出能够综合原始变量的少数几个因子,使得少数几个因子能够反映原始变量的绝大部分信息,进行数据的浓缩。因子分析的研究内容十分丰富,常用的因子分析类型有R型因子分析和Q型因子分析。其中R型因子分析是针对变量作因子分析,Q型因子分析是针对样品作因子分析。
根据文中研究的实际需求,选用R型因子分析。假设原有p个变量x1,x2,…,xp,且每个原有变量在进行标准化之后都是均值为零、标准差为1的标准化变量,将原变量x1,x2,…,xp用m(m<p)个因子F1,F2,…,Fm线性组合来表示,因子分析的数学模型表示如下:

式(1)中εi是特殊因子,表示了因子变量不能解释原有变量的部分;公共因子F1,F2,…,Fm彼此之间是两两正交的;aij表示的是公共因子的负载,在各个因子变量不相关的情况下,因子载荷aij相当于多元回归中的标准回归系数,就是第i个原有变量和第j个因子变量之间的相关系数(即xi在第j个公共因子变量上的相对重要性),aij的绝对值越大,则公共因子Fi和原有变量xi关系就越强。
2.2 随机森林算法
随机森林算法[14]是由Breiman于2001年提出的一种集成学习算法,常见的集成学习算法还包括装袋算法和提升算法。集成学习是一种机器学习范式,现已成为国际机器学习界研究的热点,集成学习方法弥补了单一方法的不足。随机森林是以分类回归树CART为基本分类器,并且包含多个由Bagging集成学习技术训练得到的决策树,当输入待分类的样本时,最终的分类结果由单棵决策树的输出结果投票决定[15-16]。
随机森林是一个树型分类器{h(x,θk),k=1,2,…,n}的集合。其中元分类器h(x,θk)是用CART算法构建的没有剪枝的分类回归树;x是输入向量;θk是独立同分布的随机向量,决定了单棵树的生长过程;随机森林的输出采用简单多数投票法(针对分类)或所有树输出结果的简单平均(针对回归)得到。随机森林算法步骤如下:
(1)从原始训练数据集S={(xi,yi)} (i=1,2,…,n)中bootstrap抽样生成k个训练样本集,每个样本集是每棵分类树的全部训练数据。
(2)每个训练样本集单独生长成为一棵不剪枝叶的分类树hi。在树的每个节点处从M个特征中随机挑选m个特征(m≤M),在每个节点上从m个特征中依据Gini指标选取最优特征进行分支生长。这棵分类树进行充分生长,使每个节点的不纯度达到最小,不进行通常的剪枝操作。
(3)根据生成的多个树分类器对新的测试数据xt进行预测,分类结果按每个树分类器的投票多少而决定,即分类公式为:
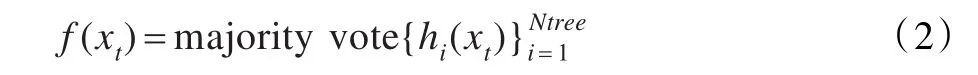
上式中,用majority vote表示多数投票,Ntree表示随机森林中树的个数。在训练过程中每次抽样生成自助训练样本集,原始训练数据集中不在自助样本中的剩余数据被称为袋外数据(out-of-bag,OOB),OOB数据被用来预测分类的正确率,每次的预测结果进行汇总得到错误率的OOB估计。
随机森林的边缘函数[17]:

随机森林的泛化误差上界:

式(4)中,ρ是相关系数的均值,s是分类器的强度,s=Ex,ymr(x,y)。随机森林通过在每个节点处随机选择特征进行分支,最小化了各棵分类树之间的相关性,提高了分类精确度。
3 煤与瓦斯突出预测的随机森林模型及应用
3.1 影响因素的相关性分析
对于煤矿井下深部开采是处于一个复杂的自然环境,影响煤与瓦斯突出的影响因素具有多样性等,通常是在突出危险区域测取和煤与瓦斯突出密切相关的一些物理参数或指标观察数据,同时考虑实际预测中影响指标数据的易取性,选取能够间接反映煤与瓦斯突出的影响因素进行相关预测分析。
文中根据文献[18]提供的数据,选取了最大主应力(X1)、瓦斯压力(X2)、瓦斯含量(X3)、顶板岩性(X4)、距断裂距离(X5)、煤层厚度(X6)、开采垂深(X7)、绝对瓦斯涌出量(X8)和相对瓦斯涌出量(X9)9个影响因素作为煤与瓦斯突出预测的评价指标,这几个评价指标对于煤与瓦斯突出的影响在文献[18]中已相应说明。
为了减少变量因素之间信息的冗余,提高相互独立性,对这9个影响煤与瓦斯突出的因素(如表2)运用SPSS软件进行普通相关性分析,求得Spearman等级相关系数和T检验的统计值Sig。由分析的结果表明,最大主应力(X1)、瓦斯压力(X2)、瓦斯含量(X3)、开采垂深(X7)、绝对瓦斯涌出量(X8)和相对瓦斯涌出量(X9)这6个变量因素之间的T统计量的检验值Sig小于0.05,相关系数是显著异于0的,说明了这六个变量因素之间的相关性较强,存在着信息交互;而另外三个变量因素之间的T统计量的检验值Sig大于0.05,说明了这三个变量之间的相关性比较弱,彼此关联程度低。
3.2 因子分析检验
在进行相关性分析之后得到相关性较强的6个变量(最大主应力、瓦斯压力、瓦斯含量、开采垂深、绝对瓦斯涌出量和相对瓦斯涌出量),对这6个变量进行因子分析提取公共因子,对影响因素进行降维。但在对变量因素进行因子分析之前,先要检验这6个变量因素是否适合进行因子分析。
运用SPSS软件对这相关性较强的6个变量因素进行KMO检验和巴特莱特球体检验(Bartlett)。其检验的结果如表1所示,KMO的检验值为0.851,适合做因子分析;同时Bartlett球体检验统计值的显著性概率Sig为0,小于0.05的显著水平,因此接受备择假设,认为适宜作因子分析。根据这两个检验的结果,表明了相关性较强的这六个变量因素可以进行因子分析。

表1 KMO和Bartlett检验
3.3 基于因子分析的煤与瓦斯突出的随机森林预测模型
煤与瓦斯突出强度大小可以分为4个不同程度类型[18],即无突出,小型突出,中型突出和大型突出四类。在该预测模型中数据来源于文献[18],选取了19组煤与瓦斯突出样本作为训练数据(表2),另外选取其中5组样本作为模型的测试数据(表4),对影响煤与瓦斯突出相关性较强的6个变量因素进行因子分析,实现数据的降维,提取公共因子,再结合相关性较弱的影响因素共同作为预测模型的输入,以四个不同突出强度作为输出,建立基于因子分析的随机森林预测模型。
将表2中相关性较强的最大主应力、瓦斯压力、瓦斯含量、开采垂深、绝对瓦斯涌出量和相对瓦斯涌出量,这六个变量因素运用SPSS 16.0软件进行因子分析,由得到的碎石图如图1所示,由图中可以看出前两个公共因子的特征值变化比较明显,从第二个公共因子之后的特征值变化就变得平缓许多,根据碎石原则,相关性较强的这6个变量因素进行因子分析之后能提取出两个公共因子F1和F2,这两个公共因子的累计贡献率为96.246%,即这两个公共因子解释了原来6个变量96.246%的信息。
提取F1和F2两个公共因子,由因子载荷矩阵难以看出两个公共因子的实际含义,所以通过旋转坐标轴,使负载尽可能向正负一或零的方向靠近,因而得到因子载荷旋转矩阵(表3)。载荷旋转矩阵使得两个公共因子的实际意义凸显出来,由表3可知,公共因子F1主要由瓦斯含量、开采垂深、绝对瓦斯涌出量和相对瓦斯涌出量四个因素组成,公共因子F2由最大主应力以及瓦斯压力组成。由碎石图可看出公共因子F1的特征值变化明显,说明了它在煤与瓦斯突出预测的影响因素当中,其影响性比较大。再由旋转后的因子得分矩阵可求得因子值,求出的F1和F2的对应值如表2所示(部分数据)。
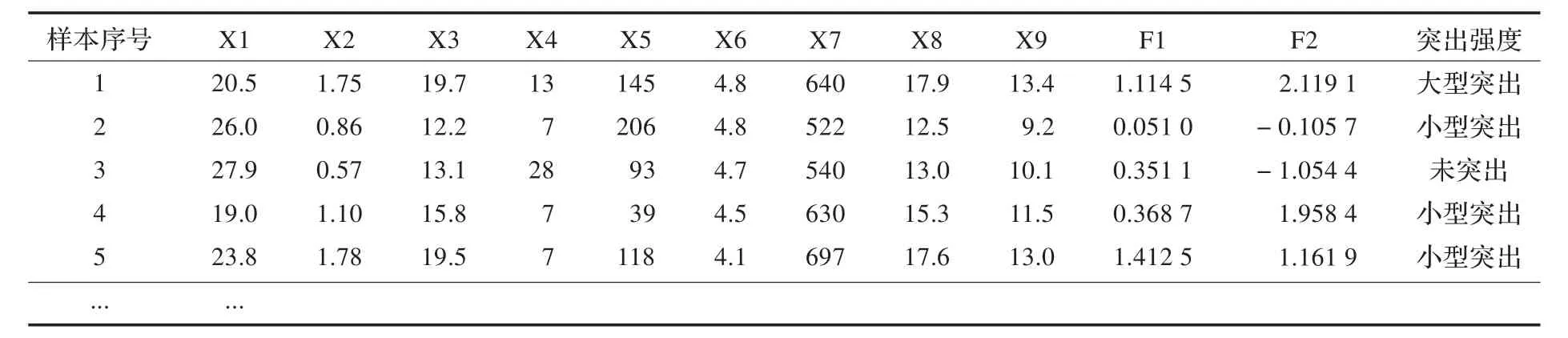
表2 测试样本数据(部分)

图1 碎石图
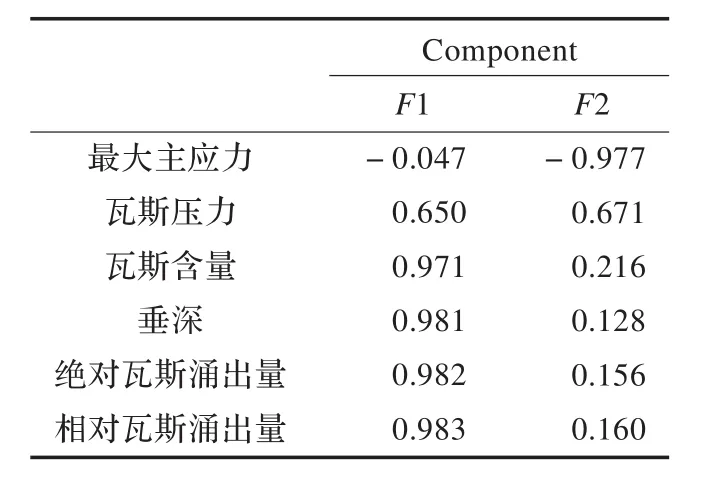
表3 因子载荷旋转矩阵
通过相关性分析得到的三个相关性较弱的变量因素(顶板岩性、距断裂距离、煤层厚度),和进行因子分析所提取的两个公共因子(F1和F2),这五个变量因素共同作为随机森林预测模型的输入,基于Matlab 7平台上做随机森林编程训练,设置变量个数mtry=4,随机森林的树的个数ntree=500,用表2中样本数据进行预测模型的训练,确定5个变量因素与4个煤与瓦斯突出强度之间的非线性关系,在样本集的训练过程中,图2是袋外数据的错误率变化,估计了随机森林的泛化误差,从图中可看出随机森林预测模型的错误率极低。
随机森林预测模型训练好之后,用表4中5组数据进行煤与瓦斯突出强度的测试,表4中数据依然需进行因子分析提取公共因子作为预测模型变量输入。为了验证该模型分类预测的准确率,同时将其与Fisher判别分析方法(FDA,Fisher Discriminant Analysis)[11]及BP神经网络方法进行比较,其中运用SPSS软件操作完成Fisher判别预测,并设定BP神经网络的输入层神经元个数为5(输入变量个数),隐含层神经元个数为10,输出层神经元个数为3:0-0-0(无突出),0-0-1(小型突出),0-1-0(中型突出),1-0-0(大型突出),因此建立5-10-3结构的BP神经网络。随机森林(RF)测试类别、Fisher测试类别(FDA)和BP神经网络(BPNN)测试类别与真实类别的对比结果如表4中所示。图3是随机森林对煤与瓦斯突出强度的测试结果,从图中可看到,对于这5个小样本测试数据,随机森林的误判率为0,同时从表4中各预测模型的结果对比得出:其他两种预测模型在预测结果上与瓦斯突出实际类别存在出入,RF预测的准确率要高于其他两种算法模型,由此可以表明,基于随机森林建立的煤与瓦斯突出强度预测模型具有较高的准确率。
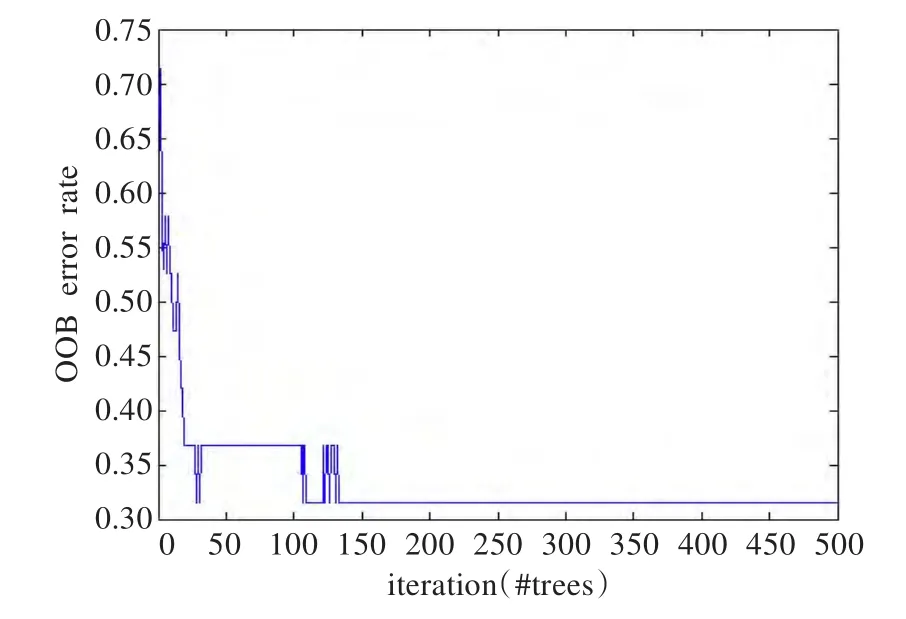
图2 袋外数据错误率

图3 RF预测结果

表4 预测模型测试结果对比
4 结束语
(1)本文在借鉴国内外文献的基础上,运用了因子分析方法,对影响煤与瓦斯突出预测的相关程度较高的影响因素进行因子分析,减少变量因素之间的信息冗余,以提高模型预测精度,同时,通过相关性分析得到,就煤与瓦斯突出强度预测而言,文中选取的最大主应力、瓦斯压力、瓦斯含量、开采垂深、绝对瓦斯涌出量和相对瓦斯涌出量这个六个变量之间相关性极高。
(2)由相关性较弱的三个影响因素顶板岩性、距断裂距离以及煤层厚度和因子分析提取的公共因子F1、F2,这5个变量共同作为随机森林预测模型的输入,经过训练以及预测结果的对比显示,基于因子分析建立的煤与瓦斯突出强度预测的随机森林模型,其预测准确率极高,预测的结果与煤矿的实际情况较为吻合,为煤与瓦斯突出预测提供了指导作用,同时也为该领域的研究提供了新的思路。
(3)本文尝试着将因子分析理论和随机森林理论结合运用到煤与瓦斯突出等级预测问题当中,通过测取一些与瓦斯突出相关的静态因素的数据进行预测。在后续工作当中,需要考虑影响煤与瓦斯突出的时变性因素,测取大样本数据,分析提取更具有代表性的影响因素,提高随机森林的泛化能力,进一步提高煤与瓦斯突出等级预测的正确率。
[1] Wold M B,Connell L D,Choi S K.The role of spatial variability in coal seam parameters on gas outburst behaviour during coal mining[J].International Journal of Coal Geology,2008,75(1):1-14.
[2] 聂百胜,何学秋,王恩元,等.煤与瓦斯突出预测技术研究现状及发展趋势[J].中国安全科学学报,2003,13(6):43-46.
[3] 刘俊娥,曾凡雷,郭章林.基于RS-SVM模型的煤与瓦斯突出多因素风险评价[J].中国安全科学学报,2011,21(7):21-26.
[4] 李坤,由长福,祁海鹰.煤矿煤与瓦斯突出数学模型的建立[J].工程力学,2012,29(1):202-206.
[5] 刘俊娥,曾凡雷,郭章林.基于RS-SVM模型的煤与瓦斯突出多因素风险评价[J].中国安全科学学报,2011,21(7):21-26.
[6] 郭德勇,李念友,裴大文,等.煤与瓦斯突出预测灰色理论-神经网络方法[J].北京科技大学学报,2007,29(4):354-357.
[7] 高卫东.Fisher判别法在煤与瓦斯突出危险程度预测中的应用[J].中国安全科学学报,2010,20(10):26-30.
[8] 董春游,曹志国,商宇航,等.基于G-K评价与粗糙集的煤与瓦斯突出分类分析[J].煤炭学报,2011,36(7):1156-1160.
[9] 邓明,张国枢,陈清华.基于瓦斯涌出时间序列的煤与瓦斯突出预报[J].煤炭学报,2010,35(2):260-263.
[10] 马昕,郭静,孙啸.蛋白质中RNA-结合残基预测的随机森林模型[J].东南大学学报:自然科学版,2012,42(1):50-54.
[11] 马庆国.管理统计[M].北京:科学出版社,2008:308-335.
[12] 邵良杉,赵琳琳.露天采矿爆破振动对民房破坏的旋转森林预测模型[J].中国安全科学学报,2013,23(2):58-63.
[13] 王玉宝,单仁亮,蔡炜凌,等.西山矿区煤巷掘进速度影响因素因子分析[J].煤炭学报,2011,36(6):925-929.
[14] Breiman L.Random forests[J].Machine Learning,2001,45(1):5-32.
[15] 董师师,黄哲学.随机森林理论浅析[J].集成技术,2013,2(1):1-7.
[16] 杨帆,林琛,周绮凤,等.基于随机森林的潜在k近邻算法及其在基因表达数据分类中的应用[J].系统工程理论与实践,2012,32(4):815-825.
[17] 庄进发,罗键,彭彦卿,等.基于改进随机森林的故障诊断方法研究[J].计算机集成制造系统,2009,15(4):777-785.
[18] 朱志洁,张宏伟,韩军,等.基于PCA-BP神经网络的煤与瓦斯突出预测研究[J].中国安全科学学报,2013,23(4):45-50.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
建材发展导向(2019年5期)2019-09-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
作文大王·笑话大王(2017年1期)2017-02-21
山东工业技术(2016年15期)2016-12-01
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24