
基于多策略的新浪微博大数据抓取及应用
2014-01-23 10:46叶嘉麒唐陈意任福继
合肥工业大学学报(自然科学版) 2014年10期
孙 晓, 叶嘉麒, 唐陈意, 任福继
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
新浪微博在发展初期,主要采用国外的Twitter的发展模式。但随着发展而表现出的个性化差异,让新浪微博增加了更多适应于中国用户的客户体验。
新浪微博拥有庞大数目的用户群体基础,日均微博总发送量维持在5 000×104~1×108条之间。用户状态、用户关注及粉丝等信息已经成为非常庞大且具有价值的数据,如何去获得及处理这些数据,成为十分热门和值得关注的研究方向[1-3]。文献[4]以新浪微博为基础,对网络舆情进行分析研究;文献[5]以姚晨微博为例研究微博传播机制;文献[6]对微博用户行为特征与关系特征进行实证分析;文献[7]介绍了早期新浪微博数据挖掘方案及获取新浪微博数据的2种方法,即利用新浪微博API和网络爬虫解析微博网页获得数据,并对2种方法进行了对比测试;文献[8]将Twitter与中国本土微博服务进行比较,重点讨论了微博服务所具有的研究价值;文献[9]在Twitter上以话题敏感度为基础,研究转发路径上具有影响力的用户,并引入主题-内容相关的方法分析影响力;文献[10]在Twitter数据获取上提出了基于Twitter List API和Lookup API的大量用户数据采集方案;文献[11]尝试通过关键词生成来挖掘中文微博的兴趣点。
本文尝试提出利用新浪微博API(OAuth2.0认证)以及利用网络爬虫的多策略方法解析weibo.com和weibo.cn协同工作的方案,实现新浪微博数据的高效抓取,在最大程度上以有限的权限持续获得有效数据,并对网络爬虫的可行性进行测试,完善爬行策略。另外,利用SVM训练微博情感模型,对热门话题进行趋势分析与情感倾向性判断。
1 基于API的数据获取
Web2.0时代的到来,使平台开放成为目前的发展趋势,越来越多的产品走向开放,新浪API也不例外。开发者可以通过向固定的网络地址提交参数,服务器返回请求数据给开发者的应用程序使用。相比网络爬虫方式获取数据,新浪微博开放API接口使用更加简洁方便和高效。
1.1 使用OAuth2.0调用新浪微博API
在 OAuth2.0标准[12]下调用新浪微博 API,主要有直接在URL使用参数传递访问及将参数加入请求头内进行访问。
OAuth2.0授权下API返回的均为JSON格式数据,JSON是一种轻量级的数据交换格式,文件不具有明显的强结构特征。即使在复杂的JSON对象中,电脑均能根据需要处理JSON格式中的数据。
在使用API之前,需要了解新浪微博API的接口定义及各个参数含义,新浪微博接口限制用户每个小时只能请求一定的次数。
频繁地调用API会导致暂时无法从API获得数据,所有请求都会无任何返回。为了避免过高频率访问新浪API接口,一方面可以通过新浪接口实时查询当前剩余访问次数,另一方面,需要对程序进行线程控制,以平均访问频率。
1.2 新浪微博API与SDK比较
新浪SDK中封装了众多从授权到数据获取的各功能程序,SDK建立在API基础之上,基于SDK的工程可以大大降低程序开发工作量。目前,已有Java、C++、Python等13种不同语言版本,这些SDK版本还在不断地完善中,功能性与稳定性也在不断加强,对于常规的API访问需求完全可以满足要求。但其中也存在一些漏洞和不完善的地方,所以对于某些需要定制的数据服务,还需要直接从API基础上进行扩展,并且可以根据具体问题的需求进行扩展。
2 基于多策略的微博信息获取
通过调用API接口可以实现新浪微博数据的便捷获取和解析,伴随着大数据时代的来临,数据量成为衡量的新标准,新浪在一系列的更新与改革中添加了更多的限制。例如,API中单位时间访问次数的限制,部分API接口需要更高级的权限才能访问,部分查询功能根本没有公开API接口等。因此,本文将研究方向转向利用多策略网络爬虫与网页解析技术来获取更多微博信息的途径上。
2.1 新浪微博模拟登陆程序算法过程
网页版微博分为PC端浏览器微博与手机版网页微博,两者并非完全一致。通过对登陆页面的源码分析可知,2种登陆方式完全不同。
在使用爬虫对指定微博页面爬取之前,无论从weibo.cn还是从weibo.com的策略模式上获取数据,都需要先解决通过网页登陆的问题。
在手机微博(http://weibo.cn)站点上,对提交表单分析后可知,weibo.cn登陆时用户名密码属于明文传输,提交的表单中主要参数为password的name值,vk的value值。通过登陆成功后获得的Cookies可以继续访问其他微博的内容,weibo.cn返回页面的编码格式为UTF-8。
在成功登陆后,登陆所返回的Cookie中包含一个gsid字段,以get方式在网址中加入此参数,就能以该用户的身份去访问新浪微博。
在新浪微博PC网页端(http://weibo.com)上模拟登陆,流程基本一致,加上新浪微博的不断更新版本,操作比在手机微博上模拟登陆复杂。
在新浪微博网页端登录,先要请求预登陆prelogin-url的链接地址,使用get方法得到返回的数据,从中提取servertime、nonce、pubkey和rsakv值作为备用数据。网页提交的表单中用户名为base64编码后的值,密码的编码方式已经替换为RSA加密方式,之前的登陆密码编码方式是对password经过3次SHA加密,且在其中加入了servertime和nonce的值来混淆。当前新浪微博登陆已经更新加密方式为RSA加密,使用返回的JSON数据中的pubkey及rsakv对passwd进行RSA加密得到。
新浪微博的RSA加密过程[13]如下:
(1)先创建一个rsa公钥,公钥的2个参数新浪微博都给了固定值,均为16进制字符串,转换一下进制即可,2个参数分别为pubkey和js加密文件中的10001。
(2)步骤(1)加密过程后,需要向通行证地址http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.4)请求数据,其中加入参数rsakv,将pwencode值修改为rsa2,其余根据表单需要的name对应找到value,使用post方法提交,当response中的retcode值为0时,表明登陆成功。
(3)登陆后获得Cookies可以继续访问其他微博的内容。在使用爬虫时还发现,在weibo.com上请求返回页面的内容中,中文字符经过了Unicode 1次编码,网址经过了Unicode 2次编码,需要转码才能够读取。
对于2种不同途径登陆的新浪微博,获取的数据具有不同的特征和限制。
2.2 微博用户资料库的建立
图1所示为Uid库建立的流程图。用户个人信息字段见表1所列,用户微博信息字段见表2所列。
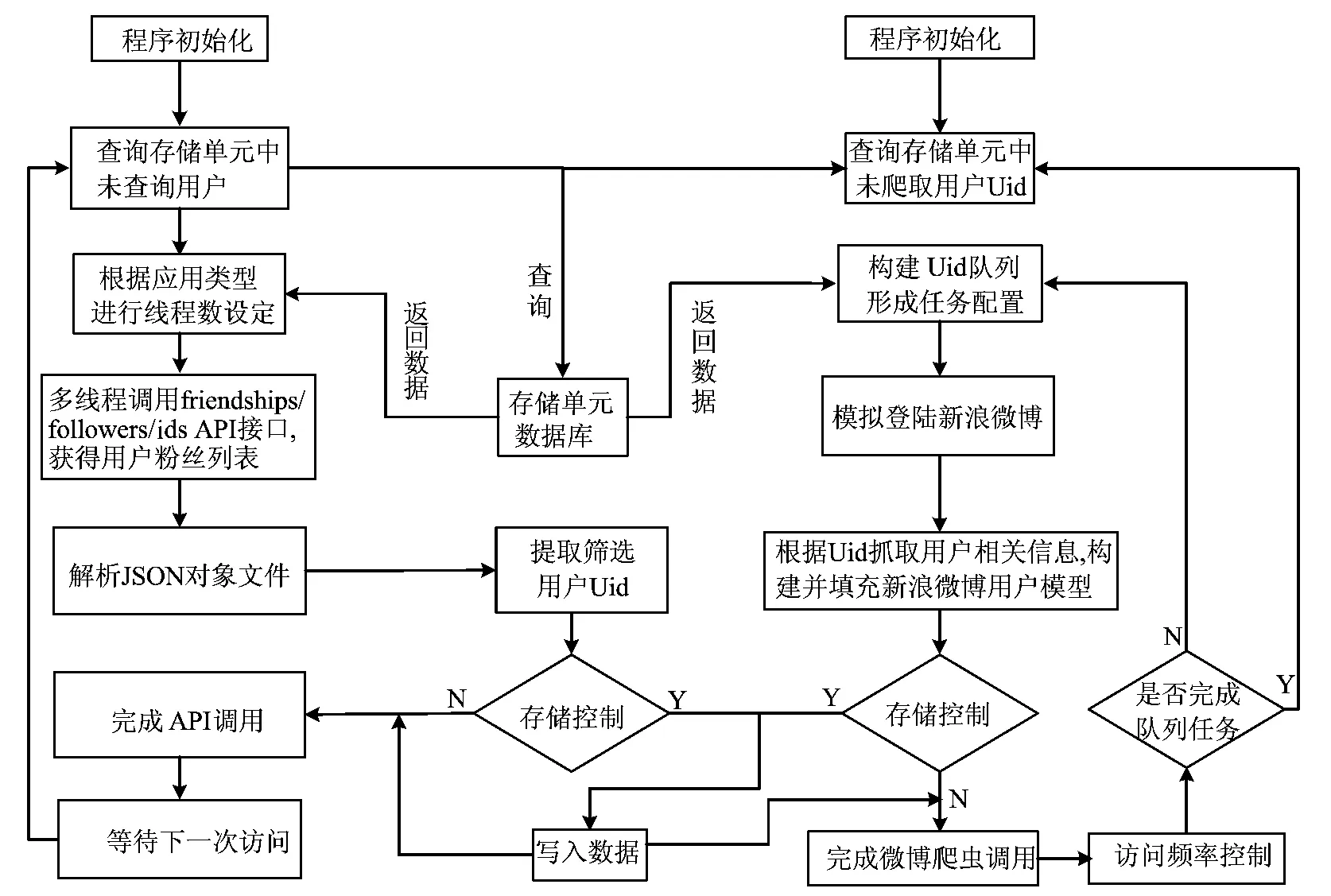
图1 用户资料库建立程序流程图
对于微博信息的实验与分析,需要大量完整的数据包。
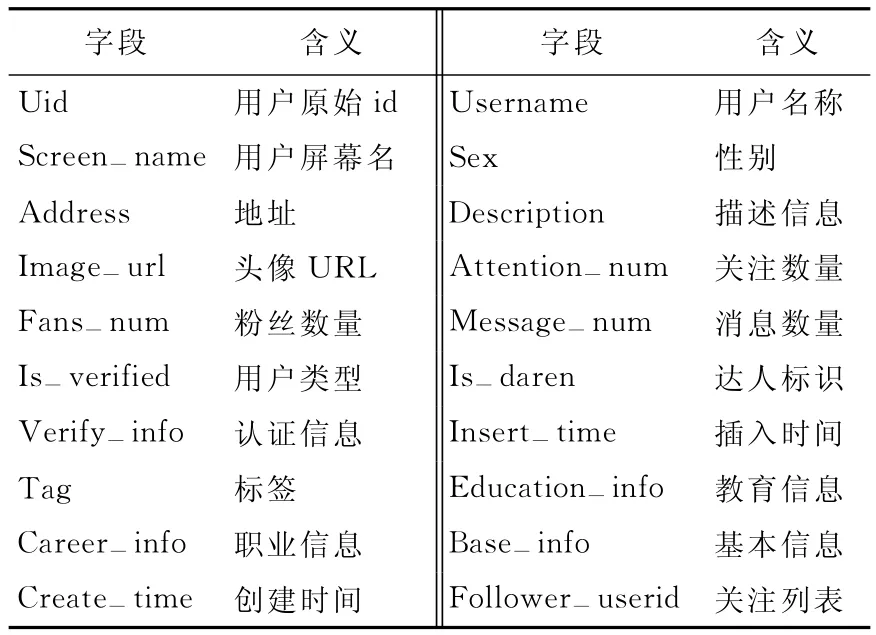
表1 用户个人信息字段
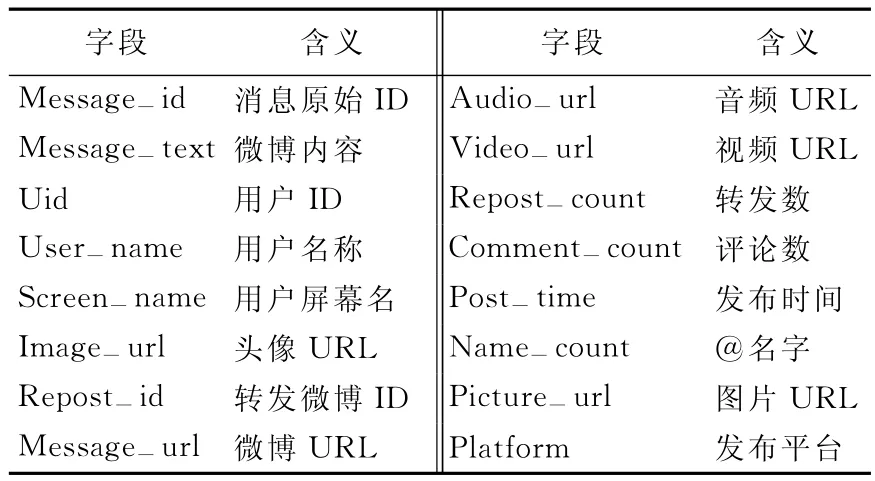
表2 用户微博信息字段
对于单个用户,其唯一标识为微博用户Uid,通过Uid可以获取用户的个人信息及粉丝列表,关注列表甚至新版微博中的心情投票值。但是对于大规模的微博用户信息获取,首先需要数量庞大的Uid作为爬虫程序的入口。对于这个问题,可以采用先人工收集筛选一部分质量比较好的微博Uid,例如1 000个,然后以1 000个Uid作为基数,通过API获取其各自的粉丝Uid列表,对这些Uid进行去重处理,扩充整个Uid库,几次循环,直至达到阈值设定的数量。从Uid库中可以利用爬虫进行数据爬取,虽然效率相对较低,但可以持续获得大量的有效数据,比API具有更高的灵活性。在获取一定量的微博用户与用户微博的基础上,可以开展用户关系分析、微博传播途径分析及关键微博分析等任务,这些任务在社交关系与舆论分析上都具有比较重要的研究价值。
2.3 微博情感分析模型的建立
中文微博文本情感分析主要分为文本预处理、情感信息抽取和情感分类,其中情感信息抽取分为情感词、主题和关系的抽取。微博主观文本情感分类方法主要是基于语义词典的情感计算和基于机器学习的情感分类[14]。
目前,基于SVM(support vector machine,简称SVM)的机器学习方法在中文微博情感极性判断上被广泛应用。
SVM是一种基于统计机器学习理论的模式识别方法,主要用于模式识别领域。本文使用的SVM工具是由台湾大学林智仁博士等开发的一套支持向量机算法库Libsvm。
中文微博文本长度被限制在140个中文字符,可以包含多个句子,不同短句之间的情感极性不尽相同,如果把整句句子赋予一种极性可能会影响训练效果。更加网络化的词汇、网络新词层出不穷,成为一段时间内的流行语,具有更深层次的含义,例如,“打酱油”、“放弃治疗”、形式多样的表情及比较随意的表达方式等,这些都是在中文微博情感分析过程中需要认真考虑的因素。文献[15]在微博语料上,对于表情符号规则方法、情感词典规则方法及SVM层次结构的多策略方法进行了探索研究,并进一步详细分析了方法特征。其实验结果显示,与前2种规则方法相比,基于SVM层次结构多策略的方法效果最好。本文将采用训练多个SVM分类器的方法,对话题微博文本进行情感倾向性判断。
训练语料库采用NLPCC2013会议在中文微博情绪识别测试中提供的样例数据,共4 000句,已标注整句及分句情感。情感词典采用Hownet情感词表及大连理工情感词汇本体库;停用词表为哈工大停用词表。训练SVM分类器过程如下:
(1)按照主客观分类特征描述方法,从训练语料的微博内容中提取主客观分类特征,训练主客观 SVM 分类器[15]。
(2)从训练语料分句中提取极性分类特征,特征词选择采用卡方公式统计,即
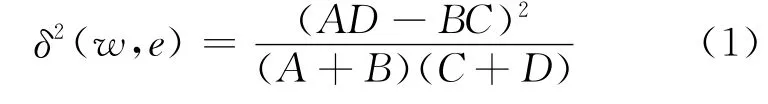
其中,w为候选词;e为词w所在句子的情感倾向性;A为包含词w并且属于e类情感的评论或微博数;B为包含词w但不属于e类情感的评论或微博数;C为不包含词w但属于e类情感的评论或微博数;D为不包含词w且不属于e类情感的评论或微博数。
特征词产生后,利用TF-IDF产生特征词的权重,然后根据每条微博的正负向情感标签训练SVM分类器。
3 实验及数据分析
测试机器为SONY CS36笔记本,Inter core P8700双核,4 GB内存,Windows7平台下 E-clipse EE,程序由Java开发实现,接入网络为10 MB共享教育网。
3.1 查询结果文件大小比较
本文提出了基于新浪微博API与网络爬虫的2大类共3种新浪微博数据获取方案。测试中首先人工选择100位粉丝超过5 000人的新浪微博用户,以保证用户的所有数据均可以通过API和网络爬虫正确获取。
新浪微博API最多只能返回5 000名粉丝的Uid信息,在weibo.com上只能查询到1 000名粉丝Uid信息,在weibo.cn上和API方式一样,能查询到5 000名粉丝Uid信息。表3所列为100个用户的粉丝Uid信息查询返回大小对比,在测试中,JSON是基于API的查询结果。
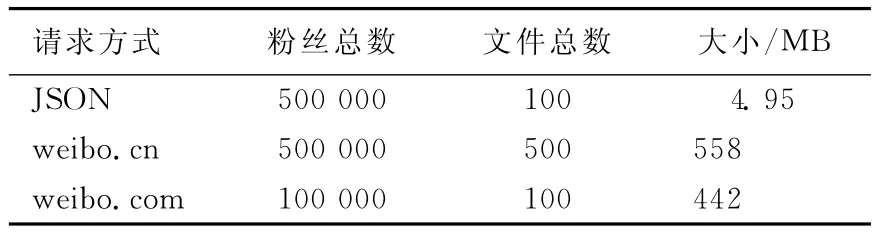
表3 用户粉丝查询文件大小对比
相比于通过API获取用户粉丝,可以发现网络爬虫方式获取的数据更加庞大,在获取同样数量粉丝的前提下,文件体积要大近百倍。这是因为网络爬虫保留了Html源文件文本中的大量地址信息及Javascript标签等内容,因此,通过网络爬虫的方式解析用户状态效率,远小于通过调用API方式得到用户信息的方式。
3.2 访问次数限制测试
从API访问获取数据的限制可以由新浪微博开放平台直接得到,从API文档中还能发现,新浪微博API不提供关键词搜索这一功能。
对于weibo.com及 weibo.cn上的访问限制,并没有一个很明确的数据,故设计了相关的爬虫程序,用来最大限度接近单账号登陆后的极限访问次数。实验结果见表4所列。从中可以看出,在网页weibo.com上,登陆后对于用户资料与用户微博的获取不受限制,因此,可以作为构建微博用户资料库的数据获取途径。而手机weibo.cn也可以作为数据获取途径,作为辅助数据来源。对于应用爬虫对关键词信息的搜索数据获取,新浪微博具有相应的限制,与API的不提供相比,已经能够获取部分数据。对于此限制,可以通过构建账号池的方式获得大量数据。

表4 爬虫限制
3.3 热门关键词微博搜索与分析
2013年上半年,对于食品安全的话题在微博上经常出现。本实验以上海地区死猪事件的关键词为例,进行各省份和地区微博关键词搜索,采集时间为2013年3月3日至2013年4月5日。由于新浪微博API不提供相应接口,故实验首先注册一系列微博账号,再通过爬虫获取34个省份及地域下的微博内容,进行抽样统计分析。共采集微博68 000余条,经过整理后,微博数据的省份和地区分布如图2所示。
从图2中可知,死猪事件在上海、北京、广东、江苏、浙江的微博数量比较多,其中上海、江苏、浙江、广东为死猪事件影响地区,北京地区数量较多是因为主要政府部门位于北京地区,对于死猪事件的调查过程以及结果公布主要通过官方微博等途径发布。其他省份和地区的微博数量基本均衡,可见各地均对食品安全事件有着较高的关心程度。
除了微博的省份和地区分布以外,还对微博发布时间进行了统计,如图3所示。从图3中可以发现,整体的微博发布量趋势呈现2个峰的形式,在3月10日左右微博发布量开始增加,到3月14日开始下降并维持在一定数目,然后在3月28日左右微博发布量又开始增加,到4月1日又开始下降。微博上围绕某一事件主题的微博数量变化,与这一事件的发展有着密不可分的关系。
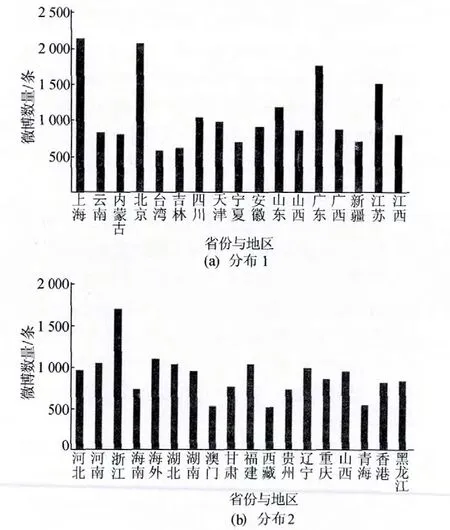
图2 采集微博数量省份与地区分布情况
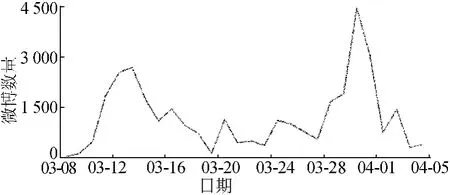
图3 微博发布时间分布
新浪新闻关于上海死猪的专题报道中收录了相关的所有新闻[16-17]。最早一条名为《黄浦江上游松江水域发现死猪929头未影响供水》的新闻,发布时间为3月9日18:10,从而推断出3月10日左右的微博数量增加是由于这一事件的曝光引起的。在这一则新闻之后,日常的新闻基本上是每天打捞死猪的数量与官方的一些表态与评论。
直到3月29日,一则《上海漂浮死猪清捞完成 将加强检查防止不合格肉》,官方宣告死猪的清理工作完成,此后又有2则记者探访类的新闻发布,引起了又一波微博上的讨论,至此死猪事件基本平息。
对于事件的微博进行情感倾向性分析,可以推测出舆论的观点倾向。对于话题微博的处理如下:
(1)首先对于微博内容进行分句。
(2)用主客观SVM模型对分句进行预测。
(3)对于主观微博SVM极性模型进行情感极性预测,然后根据正负向分句的个数,对微博进行分类,即
正向情感(正向分句数>负向分句数);
负向情感(正向分句数<负向分句数);
中性情感(正向分句数=负向分句数)。
实验结果如图4所示。
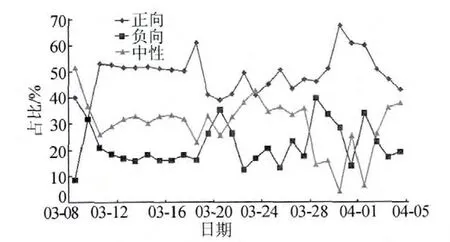
图4 微博情感分布
从图4中可以看出,微博的负向情感变化趋势与微博发布时间的趋势相似,随着微博发布量的增加而增加;微博的正向情感变化趋势从起初的平稳转向波动;微博的中性情感则和微博的负向情感一样,起伏波动。
4 结束语
本文分析了新浪官方API的数据获取方式,阐述了其用法与限制,通过分析2种网页微博的登陆流程完成模拟登陆,设计用户资料库的字段与存储方式,完成新浪微博数据挖掘的流程。通过设计实验与对于热门事件的搜索与分析,实现了数据挖掘方案的测试与应用。实验表明,通过API并结合混合策略的方式可以最大效率地获得微博数据,同时,通过对于网路爬虫的改造,可以完成新浪微博API中由于权限等原因无法取得的数据。
在新浪微博的数据挖掘方案中,还具有许多可以定制化的挖掘方案,以适应不同的数据需求,挖掘的深度与广度也可以根据需要设定。如何有效率并且低代价地获取所需要的数据,需要继续研究拓展。
对微博数据进行更大规模的分析处理,则需要大量的微博数据,随着时间增加,如何更好地组织和存储这些微博数据需要进一步考虑,另外,微博中的新词[17]和微博的关系数据也具有研究价值,如何对其有效处理也需进一步研究。
[1]谢爱平.从网络营销工具的使用看凡客诚品的发展[J].中国电子商务,2011(4):21.
[2]21世纪经济报.2013年新浪微博寻找新大陆[DB/OL].[2013-02-23].http://jinhua.house.sina.com.cn/news/10292163302.shtml.
[3]新浪科技.新浪微博2012年度盘点[DB/OL].[2012-12-19].http://tech.sina.com.cn/i/13447902817.shtml.
[4]张岚岚.新浪微博的网络舆情分析研究[D].上海:华东师范大学,2011.
[5]张钰雪.新浪微博传播机制研究[D].成都:西南大学,2011.
[6]王晓光.微博客用户行为特征与关系特征实证分析:以 “新浪微博”为例[J].图书情报工作,2010,54(14):66-70.
[7]廉 捷,周 欣,曹 伟,等.新浪微博数据挖掘方案[J].清华大学学报:自然科学版,2011,51(10):1300-1305.
[8]Chen S,Zhang H,Lin M,et al.Comparison of microblogging service between Sina Weibo and Twitter[C]//Computer Science and Network Technology(ICCSNT),2011 International Conference on.IEEE,2011:2259-2263.
[9]Cano A E,Mazumdar S,Ciravegna F.Social influence analysis in microblogging platforms:a topic-sensitive based approach[J].Semantic Web,2011,1(5):1-16.
[10]房伟伟,李静远,刘 悦,等.Twitter数据采集方案研究[J].山东大学学报:理学版,2012,47(5):73-77.
[11]Liu Z,Chen X,Sun M.Mining the interests of Chinese micro bloggers via keyword extraction[J].Frontiers of Computer Science,2012,6(1):76-87.
[12]新浪公司.新浪微博开放平台[DB/OL].[2012-3-15].http://open.weibo.com/.
[13]红黑联盟.模拟新浪微博登录算法[DB/OL].[2013-3-5].http://www.2cto.com/kf/201303/192970.html.
[14]周胜臣,瞿文婷,石英子,等.中文微博情感分析研究综述[J].计算机应用与软件,2013,30(3):161-164.
[15]谢丽星,周 明,孙茂松.基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报,2012,26(1):73-83.
[16]新浪新闻.新浪新闻关于上海死猪的专题报道[DB/OL].[2013-04-15].http://roll.news.sina.com.cn/s-sizhuall/index.shtml.
[17]孙 晓,李承程,叶嘉麒,等.基于重复字串的微博新词非监督自动抽取[J].合肥工业大学学报:自然科学版,2014,37(6):674-678,724.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
读者(2021年20期)2021-09-25
现代信息科技(2021年21期)2021-05-07
中国生殖健康(2020年5期)2021-01-18
小太阳画报(2019年10期)2019-11-04
中华诗词(2018年9期)2019-01-19
中国生殖健康(2018年5期)2018-11-06
电子制作(2017年9期)2017-04-17
阅读时代(2017年3期)2017-03-11
电子设计工程(2015年6期)2015-02-27