
基于聚类分类法的信息过滤技术研究
2014-01-21 00:51:44李全鑫魏海平
电子设计工程 2014年20期
李全鑫,魏海平
(辽宁石油化工大学 计算机与通信工程学院,辽宁 抚顺113001)
随着互联网的蓬勃发展与普及Web凭借其方便、快速、低成本的特性成为企业及个人不可或缺的信息发布工具。当Web带给人们极大便利的同时,却也产生出负面的严重问题,那就是我们每天浏览的Web页面中含有推销广告或是一些有害的不良信息,甚至还有病毒,加剧了计算机病毒、网络诈骗、色情犯罪的传播与信息安全方面的问题。面对不良信息Web页面日益严重的情况,如何对信息进行分类过滤已是非常重要的问题。
本研究在研究分类算法的基础上,提出了一个简单且方便且易于理解适用于文本信息过滤的方法。
1 相关技术介绍
1.1 支持向量机
支持向量机(support vector machine,简称 SVM)是以统计学习理论为基础发展而来的机器学习系统。其核心思想是寻找两个类别之间进行优化分隔的超平面(Separating Hyper-Plane),也就是寻找该超平面与两类数据间的最大边界(Maximized Margin)[1]。SVM 的另一个特点是可以通过不同的核心函数(Kernel Function),将训练数据映射到不同的高维度空间,来处理线性不可分的情形。
SVM利用已知类别的数据进行训练,并从这些训练数据(Training Data)之中,选出一些支持向量(Support Vectors)来代表整体的数据,之后再产生一个训练模型(Training Model),这一个训练模型将被作为后续预测数据类别的依据。由于随着时间及空间的变化,Web内容的差异也变很大,因此网页的信息分布难以事先了解,所以无法决定采用哪个SVM核心函数。大部分研究人员都是采用尝试法来选择合适的核心函数及相对应参数,因此需要花费漫长的时间,且无法保证可以得到相关参数的最佳值[2]。
在现实的信息过滤中,所面对的页面内容是随时变动的,其特征值也会经常改变。当使用机器进行学习时,必须经常的再训练(Re-train)才能维持较高的准确度,同时,用于机器学习的参数选择必须合适,这样所得分类器的再训练才能有高的准确度。
因此,我们希望设计一种可以适合于现实中信息过滤的方法,不用在乎信息集的习性、特征的选择、机器学习核心及参数的选定,一样可以很高的准确度[3]。下面将引入聚类分类法(Clustering Launched Classification,CLC)应用于信息过滤。
1.2 聚类分类法
聚类分类法(CLC)的参数选择及使用相当的简单。在其它相关领域的应用中,CLC已有相当不错的表现,本研究将CLC应用于信息过滤,并且跟SVM进行准确度的比较。
CLC在训练阶段以K-means分群算法将训练数据分群,并增加聚类的数量,直到每一个聚类中大部分数据属于相同的类为止。然后再去计算聚类数据间的相似度,以找出聚类间相似度最高的数据,这些数据被称为支援向量[4]。CLC方法的运行步骤如下所示:
训练阶段
1)设定聚类的数量k等于类别的数量;
2)采用K-means分群算法,将训练集中的数据Xi,i=1,2,3,…,n,分成 k 个聚类 Ck,k=1,2,3,…,n;
3)在每个聚类 Ck,单一类别的数据数量/总数据数量<参数 t,则 k=k+1,并返回执行步骤 2),此处的参数 t由用户设定;
4)将聚类Ck中,数据数量最多的类别留下,其余类别的数据则视为噪声删除;
5)在每一个聚类中,寻找每一个训练数据在每一个不同类别的最近邻居,称为支持向量,并以所有的支持向量组成CLC的训练模型。
预测阶段
1)计算测试数据和所有支持向量间的相似度;
2)找出与测试数据最相似的支持向量,而此支持向量的类别信息就是预测的结果。
由以上述步骤可以知道,CLC在训练阶段已经将大量的输入数据转换成少量的支持向量,从而在测试阶段能够迅速地完成预测结果。当使用者操作CLC时,只需要设定一个参数t,而且其预测结果对于参数值的大小并不敏感,因此相当容易使用。
2 信息过滤架构模型
本研究所设计的信息过滤架构模型如图1所示,共包含了信息过滤研究过程所需的3个处理步骤[5]。

图1 信息过滤架构模型图Fig.1 Diagram of information filter model architecture
本研究的基本架构模型建立的步骤如下:
1)数据前置处理:此步骤属于信息文本的前置操作,首先去除不需要的信息数据,例如:照片、HTML程序代码等。本研究使用的信息文本已经将前置处理完成;
2)网页内容转换:将每一个网页内容转换成向量,而网页内容中文字出现的次数则是每一个向量中的分量。这些分量即是每个网页的特征值;
3)网页特征选取:此步骤将由步骤2)的输出结果中,挑选出与网页类别相关性较高的特征来作为SVM及CLC产生训练模型的依据。在特征选择法方面,使用的是互动信息多项式模型(MI Multinomial Model),该模型是由互动信息(MI)发展而来的,特征值数量为500时对分类法可以有较高的准确度;
4)数据分类:本研究使用SVM及CLC进行信息过滤准确度的比较。SVM将选择不同的核心函数及相对应参数来测试。CLC也将针对单一参数,进行参数值的测试;
5)分类准确度验证:对信息过滤的准确度进行验证和评估。
3 实验与分析
3.1 实验环境
本实验在Windows 2008操作系统、2G内存、1.6GHz双核CPU环境下进行,从网络上搜集500个网页(合法400份,非法100份)进行前期的训练[6]。
3.2 实验过程设计
本研究将采用CLC,并与SVM在信息过滤的所得结果进行准确度的验证评估。实验数据使用户互动信息多项式模型为特征选择方法,所产生的训练数据的特征值数量为500。表1所列出的是SVM在本实验中所使用的参数。

表1 SVM使用的核心函数和参数Tab.1 Corefunctions and parameters used SVM
由上表可知,3种核心函数都使用了SVM的惩罚函数C,C为大于 0的实数。参数 d(Degree)是 Polynomial核心函数的指数值,必须是大于1的实数。参数g(Gamma)则是RBF核心函数中的系数,可以改变向量相减后的数值大小,该参数必须为大于0的实数。
本文在SVM实验中,采用较常见的Linear、Polynomial及RBF核心函数,以间隔递增方式选取SVM各个核心函数的相关参数值。对于核心函数及其相关参数值的选取,并没有经过特别的演算法去调整及选择。由于选用的SVM的核心函数有3种,因此以3种核心函数及其相对应参数相互搭配,分别可以如表1所示的实验参数组合。
由于训练数据的类别只有两种,因此CLC分类过程所产生的每一个聚类中,其单一类别数据数量超过全部数量50%(t值)时,该聚类就不再分裂。完成分类步骤之后,从每一个生成的聚类中取出数据数量较多的那一个类别,作为该聚类的代表类别。在本研究实验中,由于CLC所需要设定的唯一参数t,且最大值为1。这里设定CLC的参数值t从0.5开始递增,而每一个参数值间隔0.05,总共可以得到11组,如表格2所示。

表2 CLC的参数Tab.2 The parameters of CLC
3.3 结果与分析
在SVM中使用Linear核心函数对合法及非法网页的实验结果如图2所示。
图中Y轴表示准确度,X轴表示 Linear核心函数的参数值。可以看出SVM使用Linear核心函数进行信息过滤的实验时,一开始得到的准确度非常的低;当惩罚C>0.01后,才能获得比较高的准确度。在非法页面的实验中,最高与最低的准确度相差14%;而在合法页面的实验中也相差40%。由此可知,SVM使用Linear核心函数所得到的准确度,会随着参数的变化而呈现较大的差异,稳定程度不高。
在SVM中使用Polynomial核心函数对合法及非法网页的实验结果如图3所示。
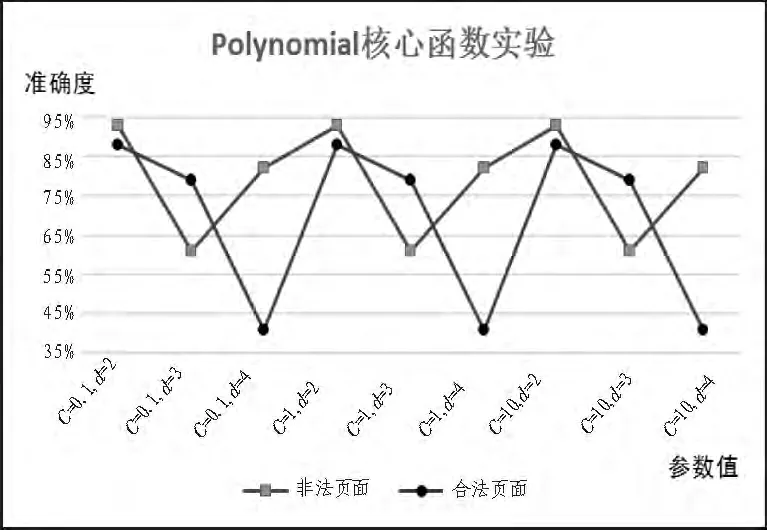
图3 实验二:Polynomial核心函数实验Fig.3 Diagram of experiment 2
图中Y轴表示准确度,X轴表示Polynomial核心函数的参数值。可以看出SVM使用 Polynomial核心函数进行信息过滤的实验时,得到的准确度呈现上下震荡的情况。在合法页面的实验中,当参数d为4所得到的准确度最低。在非法页面的实验中,当参数d为3时所得到准确度最低。由此可见准确度对于参数d及惩罚参数C值的变化非常的敏感;要选出能获得高准确度的参数组合,非常困难。如果选择的参数不合适,其所得到的准确度将会非常的低,只能以大?的参数组合来测试。
在SVM中使用RBF核心函数对合法及非法网页的实验结果如图4所示。
图中Y轴表示准确度,X轴表示RBF核心函数的参数值。可以看出SVM使用RBF核心函数进行信息过滤的实验时,得到的准确度也呈现上下震荡的情况。结果表示,假使RBF核心函数使用了不适合的参数,得到的准确度也会非常的低。要得到满意的结果,还是要经过多次的测试。
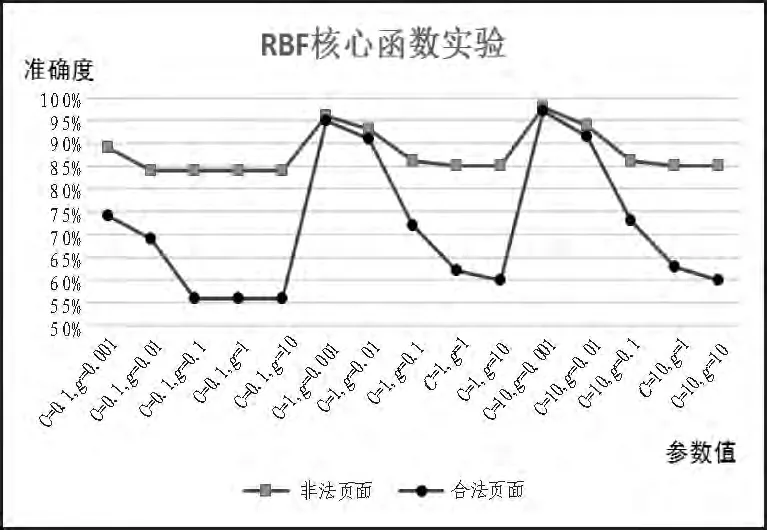
图4 实验三:RBF核心函数实验Fig.4 Diagram of experiment 3
综上所述,SVM的准确度对于参数的选值非常敏感,因此用户很难获得适合的参数。对于经常改变内容的网页内容来说,过滤器的训练模型必须经常进行再训练(Re-train)才能获得信息过滤的高准确度,需要花费相当漫长的时间,SVM并不是一种优秀的过滤方法。
利用CLC方法对合法及非法网页的实验结果如图5所示。
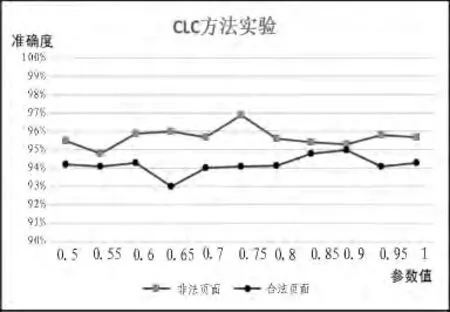
图5 实验四:CLC方法实验Fig.5 Diagram of experiment 4
从上图可知,使用CLC进行信息过滤的实验中,不同的参数值t对准确度的结果并没有很明显的影响。非法页面的实验结果显示,CLC最高与最低准确?的浮动范围只有2.1%,而合法页面的实验结果显示,CLC最高与最低准确度的浮动范围也只有2.4%。实验表明,CLC的准确度对于参数的变化并不敏感,使用CLC进行信息过滤,操作过程简单而且能够得到稳定的准确度,比SVM更适合作为信息过滤器。
4 结论
分类算法在图形识别、文本信息识别等领域具有广泛的应用。本文研究了一种基于聚类分类法实现信息过滤的技术,详细介绍了把算法的主要思想,并说明了过滤架构模型和实现的过程。通过实验表明,该方法是是实现信息过滤的实用工具。将该方法进行动态软件化是未来的研究方向。
[1]Begg R K,Palaniswami M,Owen B,Support Vector Machines for Automated Gait Classification[C]//IEEE Transactions on Biomedical Engineering,2005:828-838.
[2]Kim D S,Nguyen H,Park J S.Genetic Algorithm to Improve.SVM Based Network Intrusion Detection System[C]//.Proc of the 19th International Conference on Advanced Information Networking and Applications,2005:155-158.
[3]Hammamii M,Chahir Y,Chen L.Web guard:A web filtering engine combining textual,structural,and visual content based analysis [J].IEEE Transactions on Knowledge and Data Engineering,2006,8(2):272-284.
[4]Chen T S,Lin C C,Chiu Y H,et al.A NewBinary Classifier:Clustering Launched Classification[C]//.Proc of International Conference on Lecture Notes in Artificial Intelligence,2005:278-283.
[5]黄晓斌.网络信息过滤原理与应用[M].北京:北京图书馆出版社,2005.
[6]中国互联网违法和不良信息举报情况公告[EB/OL].[2013-09-13].http://net.china.com.cn/jbqk/node_5957.h-tm.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
建筑科技(2018年6期)2018-08-30 03:40:54
电子测试(2017年15期)2017-12-18 07:19:27
中国交通信息化(2016年5期)2016-06-06 03:51:43
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
智能系统学报(2015年4期)2015-12-27 09:38:39
新高考·高二数学(2015年11期)2015-12-23 18:17:44
电子设计工程(2015年6期)2015-02-27 12:04:53
天津冶金(2014年4期)2014-02-28 16:52:58
