
基于路径聚类的页面访问次序的挖掘
2013-11-30 05:02张春娜李轶然
计算机工程与设计 2013年1期
张春娜,李轶然
(辽宁科技大学 软件学院,辽宁 鞍山114051)
0 引 言
随着网络的快速发展,Web站点的体系结构以及服务模式与以往大大不同,用户访问模式与倾向自由度也发生了深层次的变化。网站设计人员需尽可能的优化站点吸引用户,他们也试图去发现一些隐含性的信息,比如某些Web活动的有用模式或是潜在的行为知识,日志文件中用户的关联性、访问习惯、时序关系等。这样,通过有效的分析即可了解用户的行为模式。
一般意义上聚类过程是对某一空间域有限数据集中有限点实施聚类,其最终目的是将有用数据划分为不同的类,保持异类低相似度,同类高相似度[1]。以一个 Web站点为例,通常页面间的关系是网状的,彼此之间通过链接相联系,同一个节点下的子页面相似度较高,也可理解为用户的对该类子页面的兴趣度相似。用户访问Web站点的时序性与兴趣度具有正相关性,对于一个用户群,兴趣相投者往往访问时序也有一定相似性,体现某种规律。比如,用户us1依次访问了网页UR1,UR2,UR3,...,URn,可以以下列式子来表示该用户访问顺序与兴趣度之间的关系
I(UR1)>I(UR2)>I(UR3),...,>I(URn)
这个式子说明用户对页面的访问次序与兴趣度存在一定关系,最先被访问的页面往往兴趣度较高,因此需要采用一种聚类方法对日志文件中页面关系予以处理[2],对相似度较高页面实施归类,据此管理者可根据这种规律性调整站点结构,迎合用户个性化要求。目前,对Web站点日志的分析通常的步骤是对站点信息的预处理[3-4],用户访问行为处理,然后进行路径聚类。
其中文献[5]将用户事务转化为一个三元组,提出一种基于用户访问事务聚类算法。聚类过程中考虑了用户访问页面的先后次序以及时长,但缺乏对访问频繁度的分析,这一点与本文考察重点相悖。
文献[6]所构建的系统基于代理技术,是在线推荐引擎和URL聚类的结合体。提出的推荐规则集生成算法,主要参考关联规则,算法同时考虑了用户浏览次数和停留时间等因素,考虑因素较为全面,只是没有涉及页面的访问次序。
文献[7]采用模糊聚类的方法来处理用户访问事务。其思想是基于模糊和模糊集理论,提出一种从集群模糊边界考虑问题的路径聚类方法,同样,该方式也没有考虑用户访问页面的先后次序;文献[8]另辟蹊径,从提高路径搜索性能的角度出发,结合道路建设的相似性,给出预期路径;而文献[9]是提出了一种新的页面预处理方式,是数据整理工作的前提;文献[10]是关于数据集的聚类簇隶属关系的讨论;文献[11]则从竞争策略的角度获取最佳聚类数。
以上文献中缺少一个共同的聚类分析切合点——网页访问次序,也就是同类中不同节点的有序关系,而这正式本文所研究的重点。
1 聚类准备
路径聚类是找出用户访问行为中某种特性,它体现在用户点击页面路径的相似性所形成的域中。用户对Web站点的访问过程用兴趣轨迹来描述,即由一组链接地址所构成的访问路径。用户群体现出相似路径时,则可将该群体划分为一类,并为其定义访问行为模式,在其域上进行聚类分析,获取有用信息。
日志文件中存放用户访问信息,格式需遵循W3C标准,站点的结构可用有向图表示,如D=(V,M),其中V代表页面集合,M代表页面链接集合。据此可以得到用户行为访问模式。
定义1 Web站点日志文件:假定F为用户访问信息,令F={(fu.ip,fu.us,fu.url,fu.time)|1≤u≤n,f∈F},其中F代表Web站点日志信息,fu表示实际用户u的访问信息,包括用户本身的IP地址fu.ip、用户的标识fu.us、用户访问页的地址fu.url、用户访问页面的具体时间fu.time。
下一步工作的重点是日志文件的整理,即剔除非研究对象,包括页面中的视频、图像、声音等多媒体文件信息,保留文字和HTML格式信息。经过整理后,还需识别出用户事务信息。
在定义用户事务时,需提到一点,用户对某一页面的访问称为会话,不同用户或是同一用户对指定页面的间隔时间访问理解为不同的会话,因为用户对页面的访问可能会有多次。处理事务过程中,需定义一个时间间隔以区分不同会话。
定义2 用户访问事务
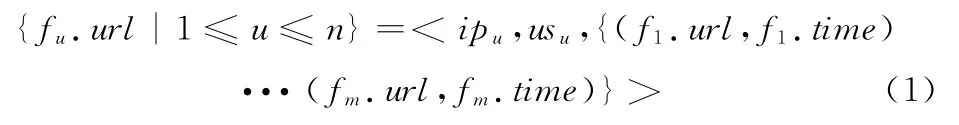
其中,m为用户u访问的最后一个页面。用户在网不同访问行为用T=fi.time-fj.time表示,记T为该用户的时间窗口,1≤i,j≤m。
定义3 用户访问子事务:不同用户不同时间段的访问行为可进一步划分为用户访问子事务。设用户访问事务为UT,则子事务可表示为:.url|1≤v≤n}∈ {fu.url|1≤u≤n},即用户访问事务中任何一个页面列表长度不超过原始页面列表长度的子列表。
定义4 页面链接参数:Web站点中页面不仅仅包括内容信息页面,也需要功能性页面,比如导航页、搜索页、主题页等。页面作用各有不同,数据挖掘中要加以区分,不同类型页面附应于相应权值,涉及到应用的范围权值有高低之分,设定是依据经验,并不失一般性,也可能选取样本数据实施训练进行自适应计算。这里,为了方便以及更好的说明页面的差异性,以经验量化指标限定,称作页面链接向量参数

式中:RLk——第k个页面的页面链接参数,si——该页面被链接的总数,S——页面间总链接数,Q——页面加权因子。
为了遍历每个用户事务,本文试图找到通用的处理方式,步骤如下:
(1)站点用户信息筛选;
(2)对经过筛选后的站点日志文件进行预处理;
(3)将日志中每个用户进行归类,即将每个IP地址相关内容划分成集;
(4)确定访问事务,利用时间窗口T确定每个用户的访问内容,每段访问内容构成一个数据集,称为用户访问事务,进而划分子事务。
(5)考察访问次数与停留时间,对于同一用户同一地址的记录,在访问事务中记录一次,其它访问只记录次数且不放入数据集;每次访问的停留时间则需一一记录,附于每个事务末端;
(6)数据集整理,按时间对用户访问事务进行排序,组成时间序列事务集。
伪代码如下:


在一个时间窗口内,每一个用户访问事务都有一个页面链接列表;同样,相对于全体用户访问事务而言,时间窗口内,新生成的用户事务代表了一个非重复的访问路径,数据集中存放了用户某一段时间访问路径,寻找到路径的相似性,通过算法即可路径聚类,最终发现用户访问模式。
2 K-PathSearch
本文提出K-PathSearch路径聚类算法,该方法通过生成的数据集进行特征聚类,同时考虑到用户的兴趣度,对用户访问页面的先后次序进行处理,经过多次迭代聚类,得到真正反映用户实际情况的访问序列。本文在充分考虑访问次序的前提下,剔除了多余的同址访问记录,比照其它方法,该算法更加高效可靠,具体算法思想如下:
(1)设定数据集F,设定参数k用来划分聚类数;
(2)设计聚类中心,并对其初始化。即将数据集中n个事务,以k为单位划分聚类,注意聚类中每个用户事务必须保证与聚类中心相似度总和最小;
(3)依据聚类中心模型重新计算聚类中心,并将聚类结果演化成矩阵,整理聚类中心与相关矩阵,组成收敛评价函数Q;
(4)经过有限次循环计算收敛评价函数Q,算法返回值应逐步收敛,直到符合要求止,否则跳转到(3)继续迭代。
定义5 兴趣度:传统的聚类分析是对给定的空间散列点有限集的取样,或是对某一数据体的分析与归纳,最终使零散变为规整;而针对Web站点,因其具有一定的规律性,站点间可组成有序的序列。因此,用户访问Web站点对某一页面的关注度,可表示为Interest(fuurl,RL),用户访问地址序列可表示为(f1url,f2url,···,fnurl),不同兴趣度决定访问次序
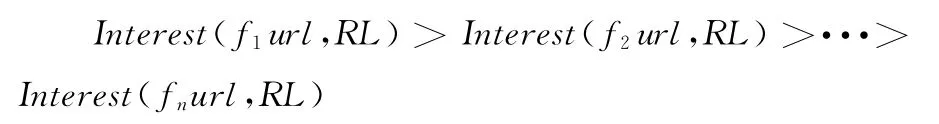
其中Interest(fkurl,RL)1<k<n。
设有群体用户u1,u2,···,un,访问 Web站点用数列表示
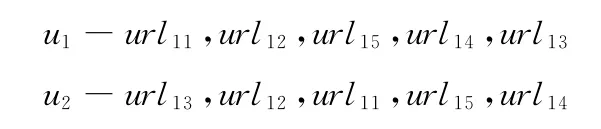
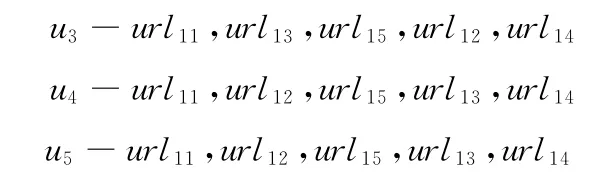
可见,访问次序不仅适用于单体,亦适用于群体特征描述。分析数列得到群体用户访问路径url11,url12,url15,url13,url14,相应兴趣度可表示为
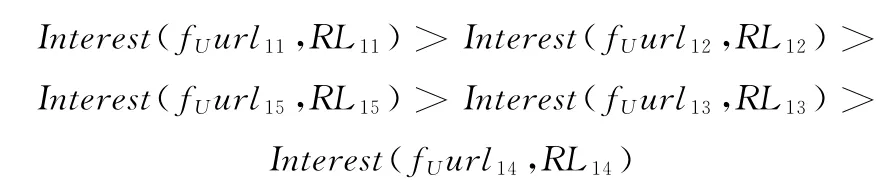
其中,U代表群体,即个体用户的访问次序决
定整个群体的兴趣度。
需提出一点,若用户访问事务中出现重复出现的url,注意用户地址兴趣度的累计,地址信息只记录一次即可。
定义6 相似度:相似度与兴趣度存在一定因果关系,即在同一链接中,两个用户对于某一网页兴趣度一致,说明两个用户相似度较高;反之较低。设两个用户访问事务分别为Si和Sj,则相似度可表示为
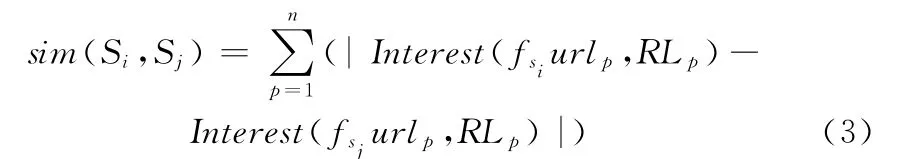
其中,兴趣度差值的绝对值越接近于0,表明二者相似度越高。
定义7 聚类中心:基于回归分析中散点图,本文假设用户兴趣度为自变量,选择的链接地址为因变量,则不同类型的访问用户相关数据点应产生聚合,并最终拟合。通过定义3,得到用户访问路径图如图1所示。
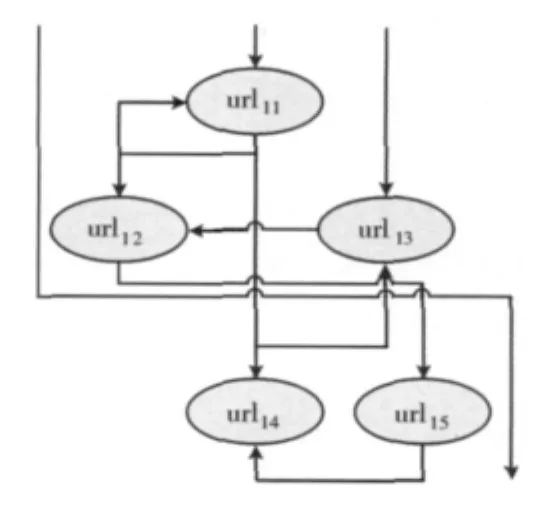
图1 用户访问路径
由上所述,给出如下定义:用户访问最长拟合路径,即,将从初始地址出发,集合成员所有访问地址最为相似的最长路径。由此,得到聚类C={ci|1<i<n},ci中包括若干个用户访问事务,一个类中的事务相似度较高,群体中心,即类中兴趣度累加最大的路径,全路径可用下式表示
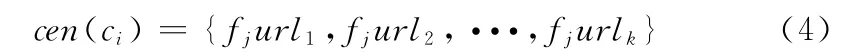
其中,最大路径表示为
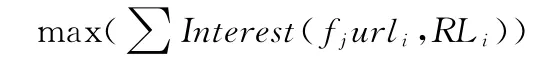
参考定义5中数列,即可得到最长拟合路径,在这个数列中,我们假定用户访问路径是定长的,为了方便处理,将其转化为向量形式,表示如下
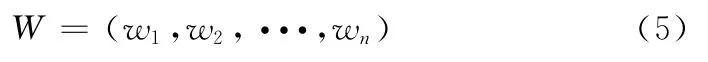
将用户访问事务向量演化成矩阵
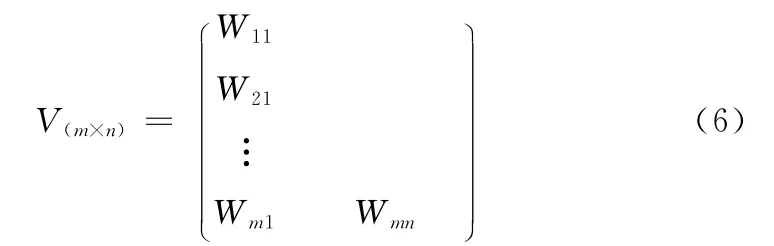
式中:m——Web站点日志中所有用户事务,n——每个用户事务的长度,即访问地址数,这里假定长度定长。
本文提出K-PathSearch算法并非传统的层次聚类方法,而是以相似度为参考条件,对路径进行分类的方法。算法的核心思想是将事务集合划分为若干个聚类,cen(ci)表示第i组依据兴趣度组成的页面,需要提出的是,这个路径可能并不是真实存在,要考虑的问题围绕式(5)与式(3)展开,定义聚类拟合函数如下所示
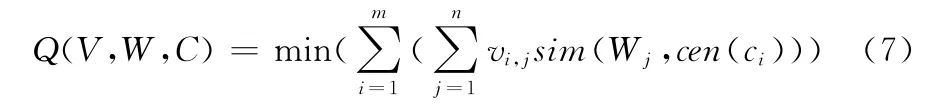
式中:vi,j——矩阵中一项,最大值m和n可相等,亦可不等。对拟合函数的求解过程做如下假设:由于W是V的子集,这里的操作分两个步骤,分别将Q(V,W,C)中除了W之外其它两个参数分别设为常量,以进行求解。
(1)设C为常量,求解Q(V,W,C)
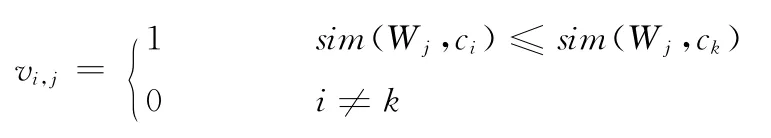
其中,1≤k≤m。
(2)设W为常量,求解Q(V,W,C):
1)设定初始常量C0,求解Q(V,W,C),从而得到初始W0;
2)设k=0,以C0、W0推导C1,依次类推,得到C2,···,Cm,进而得到W1,W2···,Wn。推导过程中,若Q(V,W,Ci)=Q(V,W,Ci+1),则输出相应W,结束算法;否则,执行第三步;
3)以C0、W0推导W1,同样得到W2,···,Wn,进而得到C1,C2···,Cm。此时,若Q(V,Wj,C)=Q(V,Wj+1,C),则输出相应C,算法结束;否则跳转到第二步。
依此计算,经过有限次的迭代,算法将收敛并得到一个局部最优解。
3 实验验证
本文实验数据取自于电子商务旅游网站服务器日志,区间为2011年5月至2011年9月,数据经过预处理剔除掉一些不必要的数据,得到多条内容访问记录。整个网站包括225个页面,用户访问页面容量56M,经过算法分析,得到用户访问事务3221个,群体用户平均访问路径长度为6.2。本文按时间区间对五组数据进行验证,算法应用前后对比表见表1。
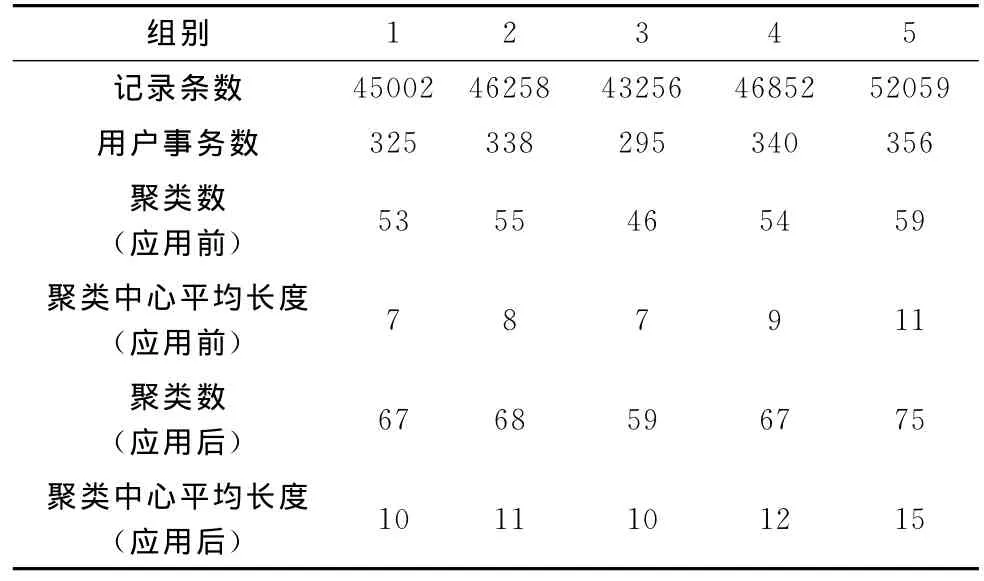
表1 算法应用前后对比
从实验数据看出,算法应用后聚类数较之前提高26%,聚类中心平均长度提高38%,提高幅度较大,达到预期效果。二者对站点访问用户的细分以及站点内容本身的分类影响较大,其直接对用户的划分产生作用,更能有效的反应用户的个性化特征,故,有助于管理者调整网站结构、细分用户,条理清晰。因此,算法可认为是有效的。
4 结束语
基于用户对Web站点的访问次序,本文提出了KPathSearch算法,它是一种分割聚类方法,用于聚类用户访问路径。文中重点考察用户的兴趣度,在设定用户访问事务的基础上,引入页面链接参数,利用参数因子以区分页面性质,这样即可对经过预处理后的页面实施二次整理,以方便页面聚类分析。再者,算法应用后聚类数显著增加,更加便于理解用户的真实需求,网站管理者可及时调整站点结构以迎合客户。同时,算法也考虑了页面之间的关系,比照用户相似度试图提供一些个性化较强的服务。
[1]Vassiliki A Koutsonikola,Athena I Vakali.A fuzzy bi-clustering approach to correlate web users and pages[J].International Journal of Knowledge and Web Intelligence,2009,1(1/2):3-23.
[2]LIU Yunfeng.A text information extraction algorithm based on tag xpath clustering[J].Computer Applications and Software,2010,21(11):199-202(in Chinese).[刘云峰.一种基于标签路径聚类的文本信息抽取算法[J].计算机应用于软件,2010:21(11):199-202.]
[3]Yang S H,Lin H L,Han Y B.Automatic data extraction from template generated Web pages[J].Joumal of Software,2008,19(2):209-223.
[4]Ou Jian-Chih,Lee Chang-Hung,Chen Ming-Syan.Efficient algorithms for incremental Web log mining with dynamic thresholds[J].The VLDB Journal,2008,17(4):827-845.
[5]LU Qun,ZHANG Zhongneng.Research on path clustering in web sites[J].Computer Applications and Software,2008,25(8):205-206(in Chinese).[卢群,张忠能.Web站点的路径聚类研究[J].计算机应用与软件,2008,25(8):205-206.]
[6]SONG Jiangchun,SHEN Junyi.An intelligent recommendation system based on web navigation path clustering[J].Information and Control,2007,36(1):119-124(in Chinese).[宋江春,沈钧毅.一个基于Web访问路径聚类的智能推荐系统[J].信息与控制,2007,36(1):119-124.]
[7]Hong Yu,Hu Luo,Chu Shuangshuang.Web users access paths clustering based on possibilistic and fuzzy sets theory[C]//ADMA(1),2010:12-23.
[8]Lee Jae-Min,Hwang Byung-Yeon.Two-Phase path retrieval method for similar XML document retrieval[G].LNCS 3681:Khosla R,et al.(Eds.):KES,2005:967-971.
[9]WU Junjie,CHEN Junjie,ZHAO Shuanzhu.Research of path clustering based on the access interest of users[J].Computer Engineering and Applications,2005,41(36):170-171(in Chinese).[吴俊杰,陈俊杰,赵栓柱.基于用户访问兴趣的路径聚类研究[J].计算机工程与应用,2005,41(36):170-171.]
[10]CHEN Jianmei,LU Hu,SONG Yuqing.A possibility fuzzy clustering algorithm based on the uncertainty membership[J].Journal of Computer Research and Development,2008,45(9):1486-1492(in Chinese).[陈健美,陆虎,宋余庆.一种隶属关系不确定的可能性模糊聚类方法[J].计算机研究与发展,2008,45(9):1486-1492.]
[11]Yu Yijun,Lin Huaizhong,Chen Chun.Personalized web recommendation based on path clustering[C]//Proceedings of the 10th WSEAS International Conference on Computers,2006:148-153.
猜你喜欢
保健医苑(2022年1期)2022-08-30
华人时刊(2021年13期)2021-11-27
动漫界·幼教365(中班)(2021年4期)2021-05-23
心声歌刊(2020年4期)2020-09-07
河南水利年鉴(2020年0期)2020-06-09
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
通信技术(2012年4期)2012-02-15
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
