
基于词性分析的产品评价信息挖掘
2013-11-30 05:01冯秀珍
计算机工程与设计 2013年1期
冯秀珍,郝 鹏
(北京工业大学 软件学院,北京100124)
0 引 言
互联网的快速发展,产品交易方式也随之改变,以电子商务的产品交易方式在生活中占了很大的比例。顾客在购买了产品之后,会在相应的产品评价系统里表达使用产品的感受,如针对产品的某个特征不是很满意,而对产品的另外一个特征很满意等。对这类信息的抽取、分析,可以得到顾客都对哪些特征进行了评价,评价的语义倾向如何,是正面评价还是负面评价。这些信息反应了该产品在顾客心中的使用情况,进而了解顾客对该类产品的需求信息。这类信息的挖掘可以为企业新产品的开发和产品的推荐提供重要的参考价值,可以作为企业进行下一步生产决策的重要的理论依据。
目前,很多学者对这个领域进行了深入研究。如,文献[1]提出了利用关联规则挖掘的方法对训练集进行训练,得到一些产品特征及其评价的信息抽取规则,按照这些规则进行产品特征及其评价的信息抽取并可视化展示。文献[2-4]在基于互信息(PMI)的基础上提出把测试短语与给定的积极短语之间的互信息减去测试短语与给定的消极短语之间的互信息的值作为测试短语的语义倾向(SO),SO(phrase)=PMI(phrase,”excellent”)-PMI(phrase,“poor”),其中,互信息PMI(word1,word2)=log2 {P(word1 & word2)/P(word1)P(word2)}。尽 管这类文章中提到的方法在对特征提取与语义倾向判别上有很好的效果,但这类文章大都集中在对英文进行处理,很少涉及对中文进行处理的。对中文的产品评价内容进行产品特征提取和语义倾向判别难度要比英文大的多,这主要是因为汉语具有很大的歧义性、多义性、结构复杂性、上下文相关性等特点。最近几年,针对汉语的特征提取与语义倾向判别也有相应的文章出现,如文献[5]提出一种基于汉语语法格式的特征抽取和基于HowNet的语义倾向判别。文献[6]提出了基于词共现的特征提取和互信息(PMI)的语义倾向判别等。
针对北京某一个电子商务网站上的一款相机的评价内容,本文首先用标点符号进行切分,切分后把每一个单独的句子作为处理单元单元进行分词和词性标注。结合每一评论语句中提到的产品特征和评价对相应的词性进行分析后发现:评论语句中能表达产品特征及评价的词都与一定的词性相联系;当评论语句中出现多个可能表达产品特征或评价的词性时,选择词性的顺序也是不一样的。因此,本文在对语料库中可能表达产品特征和评价的词性进行频数统计后排序,把词性排序后的先后顺序作为对应词性在表达产品特征和评价的重要程度,并按照词性的重要程度顺序建立了一个词性重要程度高则优先考虑的产品特征及其评价的筛选规则,然后根据不同情况建立相应评价的语义倾向计算公式。通过对实验结果进行分析,证明本文的方法在产品特征抽取及评价抽取并对评价语句的语义倾向进行判别有很好的效果。
1 产品特征及语义抽取系统架构
图1展示了产品特征及相应评的抽取策略,主要包括5个步骤:产品评论内容抽取、分词和词性标注、产品特征和及其评价信息的抽取、评价信息的语义倾向判断、产品特征的同义词替换。
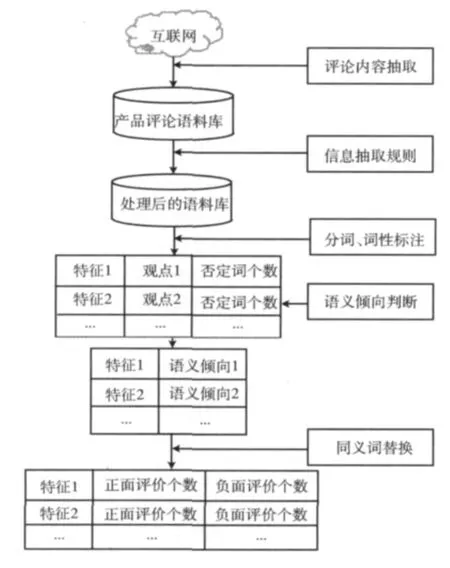
图1 产品特征及语义抽取系统架构
(1)第一步是从互联网上抽取顾客对产品评论的具体内容。这些产品评论信息是没经过任何处理直接从网上抽取下来的,它是我们分析的原始数据。
(2)第二步是抽取的评论内容进行分词和词性标注。抽取下来的评论虽然能表达一定的产品特征及相应的评价信息,但是面对这些没有任何特点的句子必须寻找一个恰当的方式进行处理,分词和词性标注是目前最为常用的手段。
(3)第三步是利用一定的抽取方法对分词和词性标注后的产品评论语句进行产品特征和评价信息抽取。这一步是整个抽取过程中最重要的一步,也是本文研究的重点。
(4)第四步是对第三步抽取的产品特征的评价信息进行语义倾向判断。针对第三步抽取的产品特征的评价内容本身进行分析是不可能的,因为评价的内容表达是多种多样。但是,无论什么评价,只有3种可能的结果:正面评价、负面评价、中性评价。针对这3种评价进行分析则是可行的。因此,需要对产品特征的评价内容进行语义倾向判断。
(5)第五步是对抽取的产品特征进行同义词替换。不同的顾客在对产品的某一个特征进行评论时可能采用不同的产品特征表达词语,而且这种现象在评论中占有很大的比例。如果不对这些产品特征的同义词进行替换、合并,必将丢失一些信息甚至得到错误的分析结果。
2 涉及的主要技术
2.1 产品评价内容抽取
能够表达对产品特征及其观点的语句有两种:一种是明显表达的语句;一种是潜在表达的语句。比如,针对相机来说,“照片不是很清晰”这句话明显表达了对相机的拍照功能不是很满意;“很模糊”这句话同样也表达对相机的拍照功能不是很满意,只是省略了特征词。针对这两种情况,处理方法也是不一样。明显表达产品特征和观点的语句用一定的方法可以直接抽取出产品特征及相应的评价。但是对于潜在表达的语句,仅根据观点词是没法判断其对应的产品特征的,它要结合实际的抽取产品类型。比如,语句 “很模糊”对于相机则是潜在的表达相机的拍照功能,而对于电视则是潜在表达电视的分辨率特征。因此,为了使我们建立的产品特征及其观点的抽取规则更具有普遍适用性,在评价内容抽取时,这类信息不作为考虑对象,不予抽取。抽取方式采取以标点符号为分隔符,即把每个单句作为抽取的一个单元并进行分析。抽取的单句形式如:“图片不是很清晰”“电池容量太小”等。
2.2 分词和词性标注
众所周知,英文是以词为单位的,词和词之间是靠空格隔开,而中文是以字为单位,句子中所有的字连起来才能描述一个意思。把中文的汉字序列切分成有意义的词,就是中文分词。分词和词性标注是汉语信息处理中重要的基础性工作,在中文信息处理中起着关键性作用。主流的中文分词方法[7-8]有:①基于字符串匹配的分词方法;②基于理解的分词方法;③基于统计的分词方法。
本文的分词系统采用中文分词系统ictclas4j[9],ictclas4j是sinboy在中国科学院张华平、刘群老师研制的FreeICTCLAS的基础上完成的一个java开源项目,简化了原分词程序的复杂度,对中文分词有很好的效果。利用ictclas4j对抽取的每一个产品评论语句进行分词和词性标注,得到如下形式:“图片/n不/d是/v很/d清晰/a” “电池/n容量/n太/d小/a”等。
2.3 产品特征及其评价的抽取规则
建立产品特征及其评价的抽取规则是本文研究的重点和创新点,下面将对本文如何建立产品特征及其评价的抽取规则进行详细阐述。
通过对分词和词性标注后的每一个产品评论语句进行分析后发现:
(1)能表达产品特征的词性主要集中在名词性词语(包括以下子类:名词n,专有名词nz,名词性语素ng等)和动词性词语(包括以下子类:动词v,名动词vn,动词性语素vg等);
(2)能表达对特征评价的词性主要集中在形容词性词语(包以下子类:括容词a,名形词an,形容词性语素ag等);
(3)每一个产品评论语句可能同时含有多个表达产品特征和评价的词性(如,同时出现两个名词性词语或两个形容词性词语等)。
(1)首先,确定表达特征及评价的不同词性及其子类的重要程度顺序。本文通过对北京的一家电子商务网站上的一款相机的评论进行抽取,抽取了20页评论,去除重复的语句和不能表达任何产品特征及其评价的语句后得到197个语句,这197个语句都表达了某一产品特征及其评价。分词和词性标注后对表达产品特征及其评价的词性进行统计,得到表1,表2。

表1 表达产品特征的词性统计

表2 表达观点的词性统计表
分析表1,表2中的数据,易得:
针对表达产品特征的词性主要集中在n,v,vn且它们的重要程度排序如下:Imp(n)>Imp(v)>Imp(vn)>Imp(其它),Imp代表重要程度。
针对表达对特征进行评价的词性主要集中在a,an且它们的重要程度排序如下:Imp(a)>Imp(an)>Imp(其它)。
在对每一个产品评论语句进行产品特征和评价信息抽取时,如果这些词性同时出现时,应该优先考虑重要程度高的词性。
(2)其次,考虑到有些表达产品特征及其评价的词性出现的几率很小如(nz,ag等),去除这些词性后不仅不会影响抽取结果,而且可以提供抽取的效率。因此,在对产品特征及其评价进行抽取时只考虑出现频率最为经常的词性,这样,表达产品特征的词性只需要考虑[n,v,vn],表达对产品特征进行评价的词性只考虑[a,an]。
(3)最后,考虑到表达对产品特征进行评价的形容词性(a,an)的词语只要出现就能表达一定的观点,因为形容词性词语本身就是一种有情感倾向的词语,是表达对产品特征一定评价的词。而表达产品特征的名词性词语和动词性词语则不一定。如,图片/n不/d是/v很/d清晰/a,其中这句话经过分词后 “不”被标注为v,但它不是产品特征。
因此,结合以上分析,本文对每一个产品评论语句进行产品特征及其评价抽取是时,把每一个产品评论句中的a(an)作为产品特征的评价词,并以它为基础寻找其对应的产品特征词。特征词的选择主要是根据上面建立的表达产品特征的词性的重要程度顺序上分别进行考论。具体的产品特征及评价的抽取规则如下:
财政部近期发布消息表示,为进一步提高地方预算完整性,加快支出进度,帮助地方提前谋划和打赢脱贫攻坚战,中央财政近期提前下达28个省(自治区、直辖市)2019年中央财政专项扶贫资金预算909.78亿元,约占2018年中央财政专项扶贫资金1060.95亿元的86%。在此次提前下达的909.78亿元中,安排资金120亿元,继续重点支持西藏、四省藏区、南疆四地州和四川凉山州、云南怒江州、甘肃临夏州等深度贫困地区,并将资金分解到具体区、州。
定义Nword为词性的word的个数,如Na为形容词a的个数,针对产品评论的每一个单独语句:
(1)当Na+Nan=0或者Na+Nan>=3或者Nn+Nv+Nvn=0时,不作考虑。


针对规则(1),当Na+Nan=0,说明没有观点词;当Nn+Nv+Nvn=0,说明没有产品特征词;当Na+Nan>=3,说明一个评论语句出现3个能表达对产品评价的词性,这种情况在我们抽取的训练库中出现的概率为0。所以,这3种情况都不符合提取的要求,不作考虑。
针对规则(2),当产品评论语句中能表达产品特征的词性在一个重要程度级上存在重复时(如,n、n或v、v),选取与能表达对产品评价评价的词性a(an)距离最近的一个为特征词[10],主要是因为形容词性(a、an)修饰与其相邻的名词性(n)或动词性(v、vn)词语是一种常见的特征。如,相机/n的/u电池/n使用/v时间/n太/d短/a,在一个重要程度级n上存在两个词语(相机/n,电池/n),按照规则取与产品评价词 “短”最近的一个,选取结果是“电池”,这种选择方式是正确的。这种特征的存在和人们使用语言的表达方式有很大的关系。但当距离相等时,则意味着在观点的左边和右边各有一个能表达产品特征的词性,这种情况在抽取的训练库中出现的概率同样为0。因此也不作考虑。
针对规则(3),当Nn>=2或(Nn=0,Nv>=2)或(Nn=0,Nv=0,Nvn>=2)时不作考虑主要是出于两点考虑:一是这3种情况出现的概率很小,这3种情况在我们抽取的训练库中出现的概率之和为仅为0.022,因此,去除后不仅不会影响到抽取的总体结果,反而会提高抽取的准确性。
综上所述,按我们的规则对产品评论进行抽取,可能出现以下结果:符合规则(1)的将不作考虑;符合规则(2)的将会抽取一个特征词和一个对产品评价词。如,[图片 清晰];符合规则(3)的将会抽取一个特征词和两个观点词。如,[图片 清晰 漂亮]
2.4 语义倾向判断
由2.3节可知,对产品评价内容进行抽取时只考虑形容词性的词语(a、an)作为对产品评价的可能的词性。因此,本文中产品特征评价信息的语义倾向判别主要是对形容词性的词语的褒贬进行判别。本文在对形容词性的词语进行语义的褒贬判别时采用的是 《知网》发布的 “情感分析用词语集”[11],其中,含有正面情感和正面评价的词语4566个,含有负面情感和负面评价的词语4370个。
另外,对产品评价的语义倾向起到决定性作用的还有否定副词(d)的个数,主要包括:“不”、 “没”、 “没有”等。如果一个产品评论语句中含有一个对产品特征正面评价的评价词,同时含有一个否定副词 “不”,显然,句子的语义倾向由正面评价转换为负面评价,如 “照片/n不/d是/v很/d清晰/a”等。但是,当一个产品评论语句中含有一个对产品特征正面评价的评价词,同时含有两个个否定副词 “不”,显然,句子的语义倾向不发生变化,如 “照片/n不/d是/v不/d清晰/a”等。
这种对产品特征的正面评价和负面评价之间的转换取主要决于否定副词的个数:当每一个产品评论语句中否定副词个数为偶数时,该评论句子的语义将不发生变化;当每一个产品评论语句中否定副词个数为奇数时,句子的整体语义倾向在正面评价与负面评价之间进行转换。
因此,产品评论语句的整体语义倾向取决于产品评价词本身的语义倾向(褒义或贬义)和语句中否定词的个数。但是,考虑到实际情况下,抽取的产品评价词可能不存在于 “情感分析用词语集”[11]中,这种情况下为了减少错误的判断,定义这种词为中性词,即不作语义倾向判断。
针对2.3节中提到的产品特征及评价的抽取规则(2)和抽取规则(3),本文提出以下公式计算每一个评论语句的整体语义。
定义:产品评价词为Opinion,其Opinion的情感色彩为SemanticOpinion。当Opinon为褒义时,SemanticOpinion=+1;当Opinon为贬义时,SemanticOpinion=-1;当Opinon不存在于 “情感分析用词语集”[10]时,即SemanticOpinion=0;句子中否定副词的个数为NumDenyword;每一个对产品特征进行评价的评论语句的整体语义倾向为Semantic,当Semantic为正数m时表示句子整体对特征词赞同m次;当Semantic为负数n时表示句子整体对特征词否定n次。当Semantic为0时表示句子整体对特征词不作判断。
规则(2)中提取的结果中含有产品特征词性和评价词性的个数都为1,无论否定副词的个数为多少都是对一个产品特征词性起作用作用,因此,句子整体的语义倾向Semantic的计算公式如下
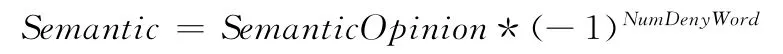
规则(3)中提取的结果中含有产品特征词性的个数为1,但是评价词性的个数都为2,否定副词作用的产品评价词性不同,结果可能不一样。
如 “相机/n 不/d是/v 很/d 好/a而且/c很/d 贵/a”这句话含有两个产品特征的评价词性 “好/a” “贵/a”,一个否定副词 “不/d”,其中 “好/a”是褒义,“贵/a”是贬义。由于否定副词 “不/d”作用于 “好/a”,因此把其中的一个褒义评价转换为一个贬义评价,这样句子其实是对相机的两次负面评价。
如 “相机/n很/d好/a而且/c不/d贵/a”这句同样是含有两个产品特征的评价词性 “好/a” “贵/a”,一个否定副词 “不/d”,其中 “好/a”是褒义,“贵/a”是贬义。但是,由于否定副词 “不/d”作用对象由之前的 “好/a”转换为现在的 “贵/a”,把贬义的 “贵/a”转换为褒义,这样句子其实是对相机的两次正面评价。
考虑到上述情况,本文用一下方法建立句子整体的语义倾向Semantic的计算公式:
假设,不考虑否定副词时,我们可以作以下判断:①当两个产品特征评价词都是褒义时,如,图片/n非常/d漂亮/a清晰/a,“漂亮/a”、“清晰/a”两个产品特征的评价词都是褒义,则句子整体对特征词取2次正面评价,即Semantic=+2;②当两个产品特征的评价词一个是褒义另一个是贬义时,如,相机/n很/d好/a但是/c太/d贵/a了/y,评价词 “好/a”是褒义,评价词 “贵/a”是贬义,这种情况下,取其折中,则句子整体对特征词保存中性评价,即Semantic=0;③当两个产品特征评价词都是贬义时,如,相机/n很/d差/a而且/c贵/a,评价词 “差/a” “贵/a”都是贬义,则句子整体对特征词取两次负面评价,即Semantic=-2;
接下来,根据上面3种情况,考虑否定副词。
因为否定副词对产品特征的评价词起到的作用是语言倾向的转换,因此,只要确定否定副词对哪个产品特征的评价词其作用,再转换这个评价词的语的语义倾向,那么句子整体语言倾向分析仍然是上面考虑的3种情况。对于否定副词对哪个观点词起作用,同样根据文献[10]中提到思想,采取距离否定副词最近的对产品评价的词语作为否定副词起作用的评价词语。当然,如果存在距离相等的情况,不作考虑,毕竟这种情况出现的概率几乎为0。
根据上面的分析,定义为观点词为Opinion1,Opinion2,对应观点词的语义倾向为SemanticOpinion1,SemanticOpinion2,根据距离,判断Opinion1所拥有的否定副词的个数NumDenyWord1,判断Opinion2所拥有的否定副词的个数NumDenyWord2,因此,句子整体语义倾向Semantic计算公式如下
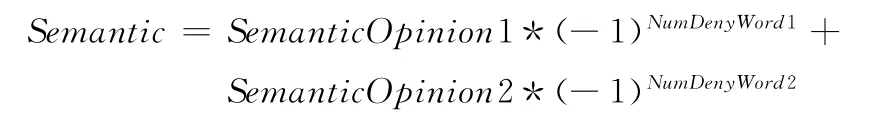
特别说明的是,针对规则(3)中涉及的两个产品特征的评价词,如果其中的评价词没有出现在 “情感分析用词语集”[10]时,根据上面的定义SemanticOpinion=0,这种情况下,规则(3)的语义计算公式则转换为规则(2)的形式,计算结果仍是正确的。
2.5 同义词替换
根据2.4节的分析,对每一个评论语句可能得到相应的产品特征词及相应评价词的语义倾向。若要对语料库中所有的评论语句进行产品特征及评价的语义倾向进行统计,必须要解决同义词问题。如,“照片”和 “相片”是同义词,只有把这两种特征词进行同义词替换、合并后,然后再对产品特征及其相应的评价的语义倾向进行统计的结果才能更准确。
针对同义词之间的关系,国内国外都由很多学者进行研究,如,国外的WordNet[12]就被许多研究人员用于同义词替换和信息抽取。文献[1]在进行同义词替换时也是根据WordNet[12]进行判断是否为同义词的。国内的 How-Net[11]就对同义词之间的关系进入了深入研究,其提供了词语之间的多种关系,如上下文关系、同义关系、反应关系等。文献[13]在对微博就行特征词提取时采用了词性分析与HowNet相结合,提出了一种特征词的选择方法。本文在进行同义词分析、替换时主要也是根据HowNet。
在进行产品特征的同义词替换时,可以根据实际的需要并结合抽取的产品特点,自行增加一定的同义词。比如,在对相机领域进行产品特征及评价抽取时,如果对产品外观进行研究,可以把尺寸、大小、颜色等定义为同义词,这些词的定义主要取决于你所定义的外观的粒度大小。针对某一个产品领域,这些词的数量也是很有限的。因此,通过定义产品领域同义词的方法是可行的,这样也可以大大提高信息抽取的准确性。本文在下面的实验在对产品特征及其评价抽取时,就把 “发货”“送货”“物流”定义为 “服务”的同义词。
3 实 验
本文用java语言在集成开发环境NetBeans下对本文中提出的产品特征及其相应的评价的抽取策略进行实现。本文针对北京的一家电子商务网站--京东商城进行实验,抽取内容是该网站出售的一款尼康相机(型号是s3100)的30页顾客评论内容。考虑到实验抽取结果中含义60个特征词,为了方便展示,实验把输出结果按照产品的特征个数进行先后排序,取排在前面也就是讨论次数最多的产品特征进行可视化展示,具体的输出结果如图2,分析可得:
(1)根据评论次数,顾客购买相机时的关注的特征顺序为:照片>外观>感觉>价格>操作>质量>功能>服务>电池>反应。这是符合顾客实际购买心态的。
(2)顾客对相机的 “照片” “外观” “价格” “操作”“质量”特征的满意程度远远大于不满意程度,这也是 “感觉”的满意程度远大于不满意的原因所在。
(3)其中电池的不满意程度远大于满意的程度,电池的缺陷带导致相机的 “反应”时间太慢,因此,在图标中,反应的不满意程度远大于满意程度。
(4)“服务”虽然不是相机的特征,但作为顾客在网络购物时比较关注的一个方面,同样也被作为特征抽取出来。
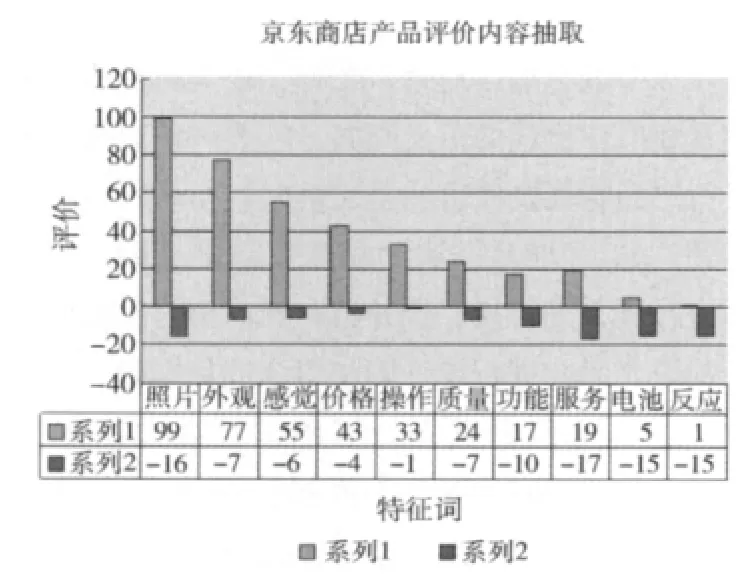
图2 产品评价内容抽取结果分析
通过这款相机的产品介绍得知,这款相机是一款价位低,机身小巧,操作简单,电池容量小等特点的傻瓜相机。这些产品介绍中所描述的信息与实验抽取的结果所反应出的信息基本上是匹配的。
为了对本文所提到的方法的准确性和可行性进行验证,对实验抽取的实验数据按照每一个评论语句反应的产品特征进行人工标注,然后,再次利用我们的方法对数据进行抽取,具体测试结果见表3。
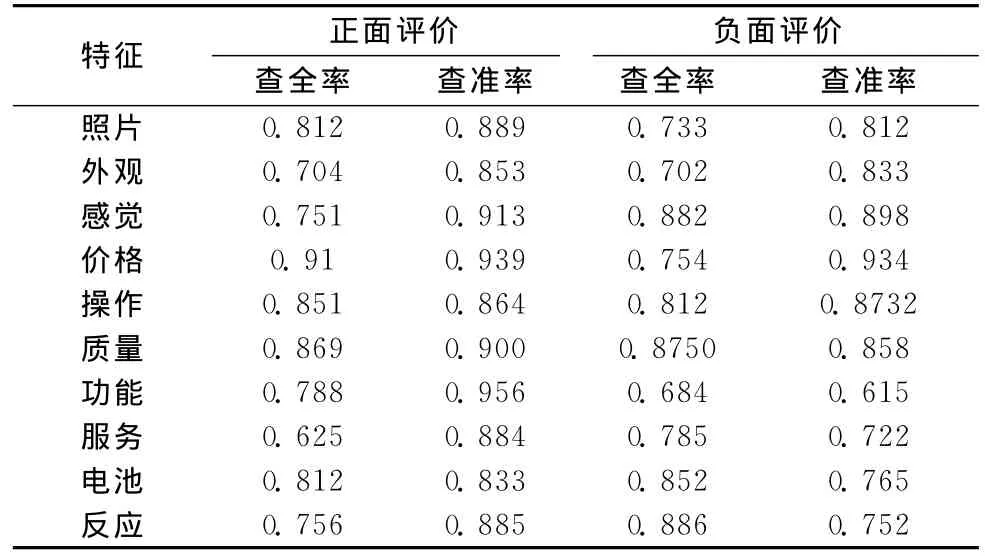
表3 实验结果分析
观察表3可以看出,利用我们的方法对产品评价内容进行产品特征抽取和观点的语义倾向判断有很高的准确率。
4 结束语
表达产品特征及其评价的词都与一定的词性相联系,本文通过对语料库中表达产品特征及评价的词的词性进行频率统计并排序,确定了表达产品特征和评价的词性的重要程度顺序。根据词性的重要程度顺序本文提出了一种新的产品特征及其评价的抽取规则并提出了评价信息的语义倾向计算公式。通过对实验结果分析,证明我们的方法在产品特征及评价的语义倾向判断上有很高的查全率和查准率。但是,本文没有考虑潜在表达的产品特征及相应评价的语句,这必将遗漏一些信息,因此,我们下一步的工作将是对潜在表达的产品特征及其相应评价的语句进行研究。
[1]Liu B,Hu M,Cheng J.Opinion observer:Analyzing and comparing opinions on the web[C]//Chiba,Japan:Proceedings of the 14th International Conference on World Wide Web,2005:342-351.
[2]Luchaichana O,Korkerd W,Tuchinda R.Classifying semantic orientation of domain-dependent words with unknown sentiments[C]//Chaing Mai:International Conference on Electrical Engineering/Electronics Computer Telecommunications and Information Technology,2010:1055-1059.
[3]Wenqian Shang,Youli Qu,Houkuan Huang,et al.A Rolebased customer review mining system[C]//Taipei:IEEE International Conference on Systems,Man and Cybernetics,2006:4855-4860.
[4]Singh V K.An automated course feedback system using opinion mining[C]//Mumbai:World Congress on Information and Information and Communication Technologies,2011:72-76.
[5]Hui Yang,Xu Zhou,Tong Zhou,et al.Semantic inclination mining based on dependency grammar for Chinese BLOG[C]//Changsha:IEEE Fifth International Conference on Bio-Inspired Computing:Theories and Applications,2010:880-884.
[6]Chang Chia-Hui,Tsai Kun-Chang.Aspect summarization from Blogsphere for social study[C]//Omaha,NE:Seventh IEEE International Conference on Data Mining Workshops,2007:9-14.
[7]YANG Chunming,HAN Yongguo.Fast algorithm of keywords automatic extraction in fiel[J].Computer Engineering and Design,2011,32(6):2142-2145(in Chinese).[杨春明,韩永国.快速的领域文档关键词自动提取算法[J].计算机工程与设计,2011,32(6):2142-2145.]
[8]LIU Bo,ZHENG Jiaheng,ZHANG Hu.Consistency check of segment using combination of rule and statistics[J].Computer Engineering and Design,2008,(29)7:1814-1818(in Chinese).[刘博,郑家恒,张虎.规则与统计相结合的分词一致性检验[J].计算机工程与设计,2008,29(7):1814-1818.]
[9]张华平,刘 群.ictclastj[EB/OL].[2008-05-01].http://code.google.com/p/ictclas4j/downloads/list.
[10]DLSI,Univ.Alicante,Alicante.A feature dependent method for opinion mining and classification[C]//Beijing:International Conference on Natural Language Processing and Knowledge Engineering,2008:1-7.
[11]董振东,董 强.知 网 简 介[EB/OL].[2011-05-01].http://www.keenage.eom/zhiwang/.html.
[12]Bwalenz,Didion J.JWNL-Java WordNet Library[EB/QL].[2008-05-14].http://jwordnet.sourceforge.net.
[13]Liu Zitao,Yu Wenchao,Chen Wei,et al.Short text feature selection for micro-blog mining[C]//Wuhan:International Conference on Computational Intelligence and Software Engineering,2010:1-4.
猜你喜欢
三门峡职业技术学院学报(2021年4期)2021-04-19
韩国语教学与研究(2021年3期)2021-03-16
校园英语·月末(2021年13期)2021-03-15
新世纪智能(语文备考)(2020年4期)2020-07-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小学生·多元智能大王(2014年6期)2014-07-09
高中生学习·高三版(2014年3期)2014-04-29
小雪花·初中高分作文(2009年8期)2009-11-16
中学生英语·外语教学与研究(2008年4期)2008-03-18
