
VLIW DSP指令级精度模拟器的快速实现方法
2013-11-30 05:01朱大林郭德源
计算机工程与设计 2013年1期
朱大林,郭德源,何 虎
(清华大学 微电子学研究所,北京100084)
0 引 言
计算机模拟器是指用软件技术和一定的硬件技术,模拟真实的计算机运行过程的系统平台[1]。根据模拟器实现的功能及面向的使用对象不同,可以将其分为两类:功能模拟器和性能模拟器[2]。功能模拟器主要是实现处理器的结构,不包括处理器的微体系结构,具有仿真速度快,但是仿真精度有所损失。现代处理器体系结构的确定通常是一个团队进行性能分析、不断改进的结果[3]。目前常见的用于研究的多种体系结构模拟器有SimpleScalar,SimOS,GEM5,Liberty,QEMU,Simics等[4],但是针对 VLIW 体系结构的模拟器还比较少,特别是不同VLIW DSP体系结构的差异很大,很难有一种通用的模拟器。
本文基于gem5[5]模拟器,通过修改原有的执行流程,提出了一种面向VLIW架构DSP的模拟器的快速实现方法,解决了指令在模拟器上的顺序执行模型和VLIW DSP上并行执行的问题,实现了16/32位混合指令的执行,并定义了完整的指令集,快速实现了一款VLIW DSP的指令级精度的模拟器,满足了VLIW DSP的指令级精度仿真要求。
1 一款分簇VLIW DSP的结构特点
1.1 VLIW DSP的一般特征
VLIW DSP是具有多个功能单元,将多条可以并行执行的指令组合成为一条超长指令,以实现多条指令并行执行。VLIW可以提供较高的指令并行度,同时,由于要求所执行的指令已经由编译器或者编程人员确保为可以并行执行的指令,不需要硬件判断是否可以并行执行,所以,硬件结构比较简单。VLIW DSP指令系统具有以下特点:
超长指令字,一般为128-1024bit,而且指令之间没有依赖性,并且指令操作不会冲突,因此可以并行执行。
一条指令可以包含多个可以并行执行的机器指令,从而提供了更高的指令级并行度[6]。
通常只有一个控制器,每个周期发射一条超长指令,由多条普通指令组成。
1.2 lily处理器的特征
Lily处理器是清华大学微电子所基于自行提出的Gingko处理器结构开发的一款数字信号处理器。如图所示,Lily作为一款高性能数字信号处理器,和模拟器相关的主要特点如下:
为了减少程序使用的存储空间,从而减少功耗,采用了16/32位变长指令集[7]。
采用超长指令字结构,处理器包含6个独立的功能单元,每个时钟周期最多可以并行执行6条指令。
处理器包含3种不同功能单元类型,其中A:算术逻辑运算功能单元,执行加减法算术操作,移位指令和逻辑操作;M:乘法功能单元,执行乘法,乘累加,乘累减,点积等操作;D:数据传输功能单元,执行存储器访问指令以及比较指令。
·片内集成了一个全局寄存器堆和两个本地寄存器堆,全局寄存器堆包含8个32位通用寄存器;本地寄存器堆包含24个32位通用寄存器。其中全局寄存器堆X、Y簇功能单元都可访问,局部寄存器堆分别只有对应的X、Y簇功能单元可以访问。
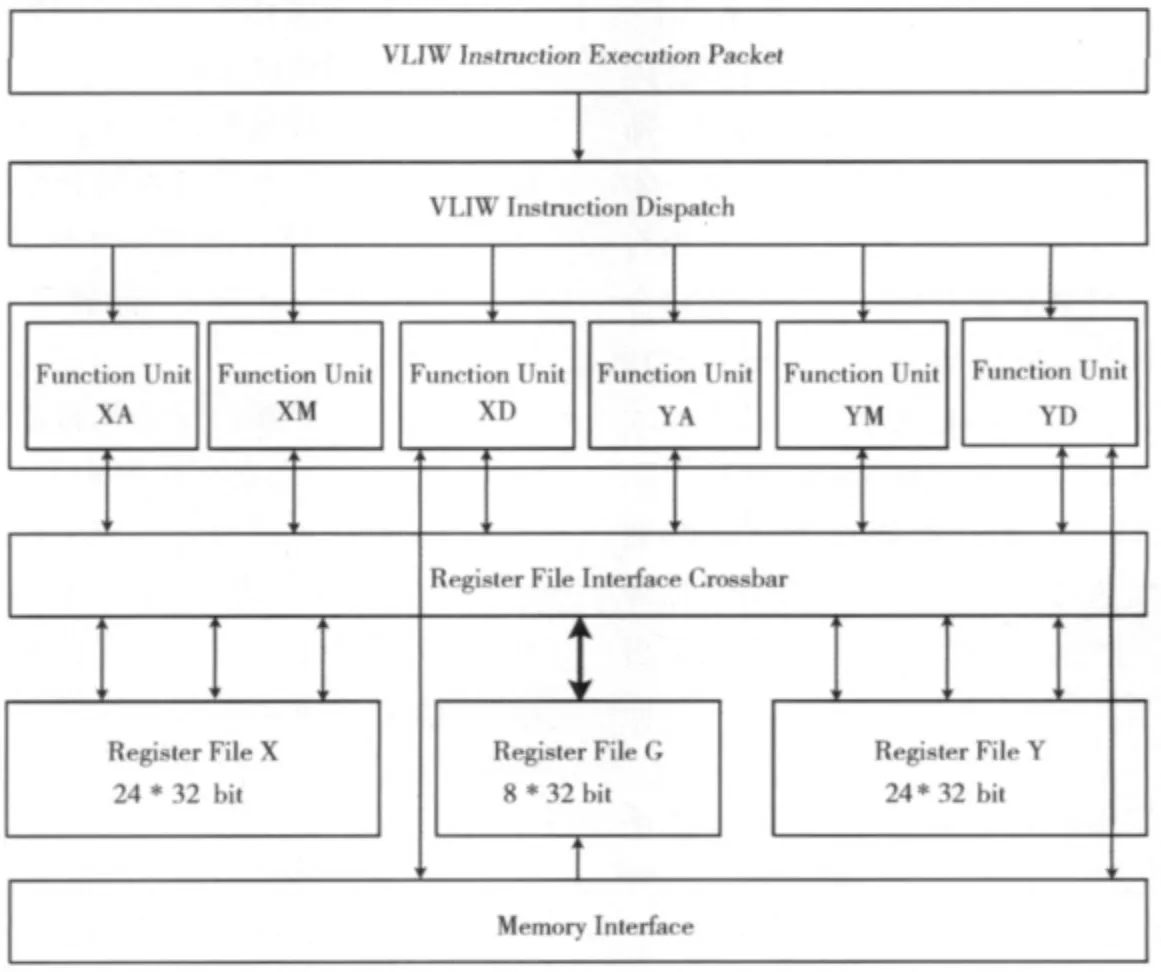
图1 Lily处理器总体架构
2 Gem5模拟器上指令执行流程分析
为了达到以最小代价实现Lily DSP的指令级精度的模拟器的要求,移植基于gem5的AtomicSimple模型进行,其中Atomic是指访存模式,在这种模式下,所有的访存都是在请求发出后立即返回,也就是说没有模拟访存的时间、队列特性[5];Simple模型是指处理器顺序执行,无流水线的指令级精度处理器模拟器[5]。
Gem5的AtomicSimpleCPU是一个顺序执行的过程,具有一般指令级精度模拟器的解释执行方式,具体执行过程如图2所示。
在每一个仿真周期里,首先访问指令页表缓冲(TLB)[8],进行虚实地址转换,然后访问指令缓存取指,然后是解码以及执行,在做一些必要的处理,比如统计指令所在功能单元情况后,PC前进一条指令,然后重复这个过程直到程序结束。
3 Lily处理器在Gem5末拟器上执行过程的建模
3.1 Lily处理器在Gem5模拟器上执行面临的问题
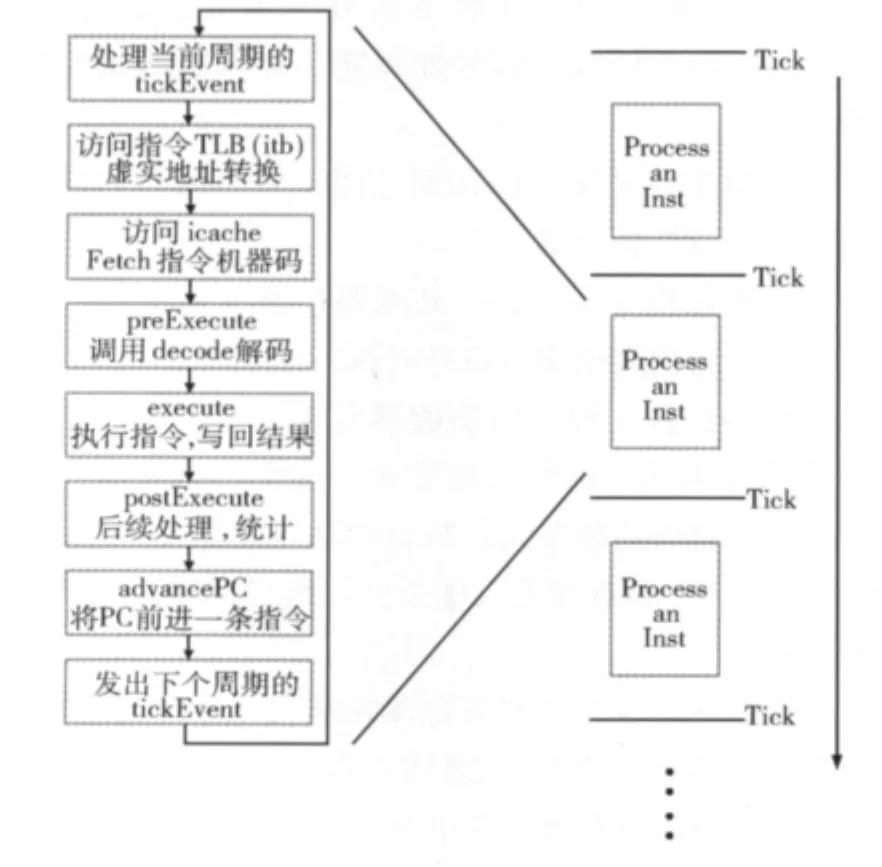
图2 Gem5AtomicSimpleCPU模型
VLIW DSP是一个并行的执行过程,在lily处理器中,有6个功能部件可以并行执行,如何在顺序模型的基础上,实现并行执行的模型,就成为移植VLIW DSP模拟器的难点。在VLIW DSP中,由于多条指令可能同时访存,所以经常采用寄存器分簇的方式,Lily处理器有两个簇,本文将分簇的寄存器堆统一管理。由于模拟器上是顺序执行指令的,一条指令可能会改写某个寄存器,而下一条指令可能也需要访问同一个寄存器,所以会造成寄存器访问冲突。而实际的VLIW DSP是并行的,在指令周期结束后才会写回寄存器,在对寄存器多读一写的情况时,在顺序执行模型下会发生冲突,而硬件并行执行时由于写寄存器是在周期结束时才发生,而这时需要读寄存器的操作已经完成,所以并不存在冲突。所以,在模拟器上需要先备份寄存器堆,一个并行包执行结束后,执行结果再统一写回寄存器。
由于Lily处理器采用了16/32位混合指令以缩小程序长度,而在Gem5的模型上是32位指令的,必须实现一种机制保证能执行16/32位混合指令。
另外,Lily处理器的寄存器是分簇的,包括X、Y簇以及一个全局寄存器堆,而gem5上的寄存器是线性地址,所以需要有一个实现分簇的寄存器堆的转换的机制。
3.2 在Gem5上扩展以支持VLIW DSP的机制
16/32位混合指令机制:由于Gem5的AtomicSimple模型取指的时候,总是从4字节对齐的地方取32位指令,PC的后两位相当于被忽略,所以在Gem5的取指流程中,加入了一个判决机制来保证取指的正确性,其流程如下:
BEGIN
(1)从当前PC取32位指令存入inst1。
(2)从PC+4的地方取32位指令存入inst2。
(3)如果PC & 3不为0,也就是PC不是4字节对齐的时候,将inst1的后16位和inst2的前16位组合成为一条32位指令送给真正的inst。
(4)如果inst是16位指令,则PC=PC+2,否则PC=PC+4。
END
寄存器堆备份/恢复机制:每条并行执行的指令,都应该读取同样内容的寄存器堆,即一条指令不应该影响同一并行组的其它指令访问寄存器,也就是说必须等同一并行组所有指令执行完毕才能写回寄存器堆。这个功能通过在每个新的并行指令组开始时备份寄存器堆、并行组内每条指令执行完后恢复寄存器堆来实现。
指令结果延时写回机制:由于是在指令顺序执行的基础上实现并行执行的模拟,这需要保存任何一条指令的结果(对寄存器堆的修改),到并行指令组执行结束时再写回。另外,如果一条指令的周期数大于1,则需要等待相应个并行指令组周期之后才能写回结果。
通过在每条指令执行之后,保存每条指令的结构,记录寄存器堆的变化、延时周期数等信息,并在适当时间写回,这个功能得以实现。
延时跳转机制的实现:当遇到跳转指令时,保存其目标地址。如果是延迟跳转指令,在5个并行指令组周期之后延迟更新PC。如果是非延迟跳转指令,而且发生跳转的条件满足时,在下个并行指令组周期更新PC,并将统计周期数加5。
分簇寄存器的线性化机制:Lily处理器每个分簇可以访问24个本地寄存器和8个全局寄存器共32个寄存器,在指令编码中可以用5bit来表示,而且5bit最多也只能表示32个寄存器。为了解决Lily处理器硬件上的寄存器分簇方式和模拟器上的寄存器线性地址之间的矛盾,只能在解码的时候根据分簇的信息将寄存器地址线性化。线性化流程如下:
BEGIN
(1)在取指时判断分簇信息。
(2)在解码时,如果是X簇并且不是全局寄存器,则保持原寄存器地址不变;如果是Y簇或者访问的是全局寄存器,则寄存器地址加24。这样,寄存器编制方式由X0,X1…X23,Y0,Y1…Y23,G0,G1…G7变为R0,R1…R55共56个寄存器。
(3)在模拟器上运行完后,显示输出信息时,将线性寄存器地址按相反的过程映射到分簇的寄存器地址。
END
统计信息:提供了对程序执行的总周期数和总指令数进行统计,并计算每周期指令数(IPC);
对A/M/D单元指令数量的统计,并计算百分比;
可以方便添加其它统计信息。
运行时错误检查:Lily处理器对指令的执行有多条限制,如:不能在同一时刻写入同一寄存器,寄存器读写冲突;BD延迟槽不能再出现跳转指令,且延时结束时不应该有未执行完的指令;等等。在VLIWSimpleCPU模型中,加入了这些检查。
3.3 VLIW DSP在gem5上执行流程的模型
如图3所示,首先建立了VLIWSimpleCPU模型,在原来的顺序执行流程中,通过加入两个新的流程实现模拟并行的效果。
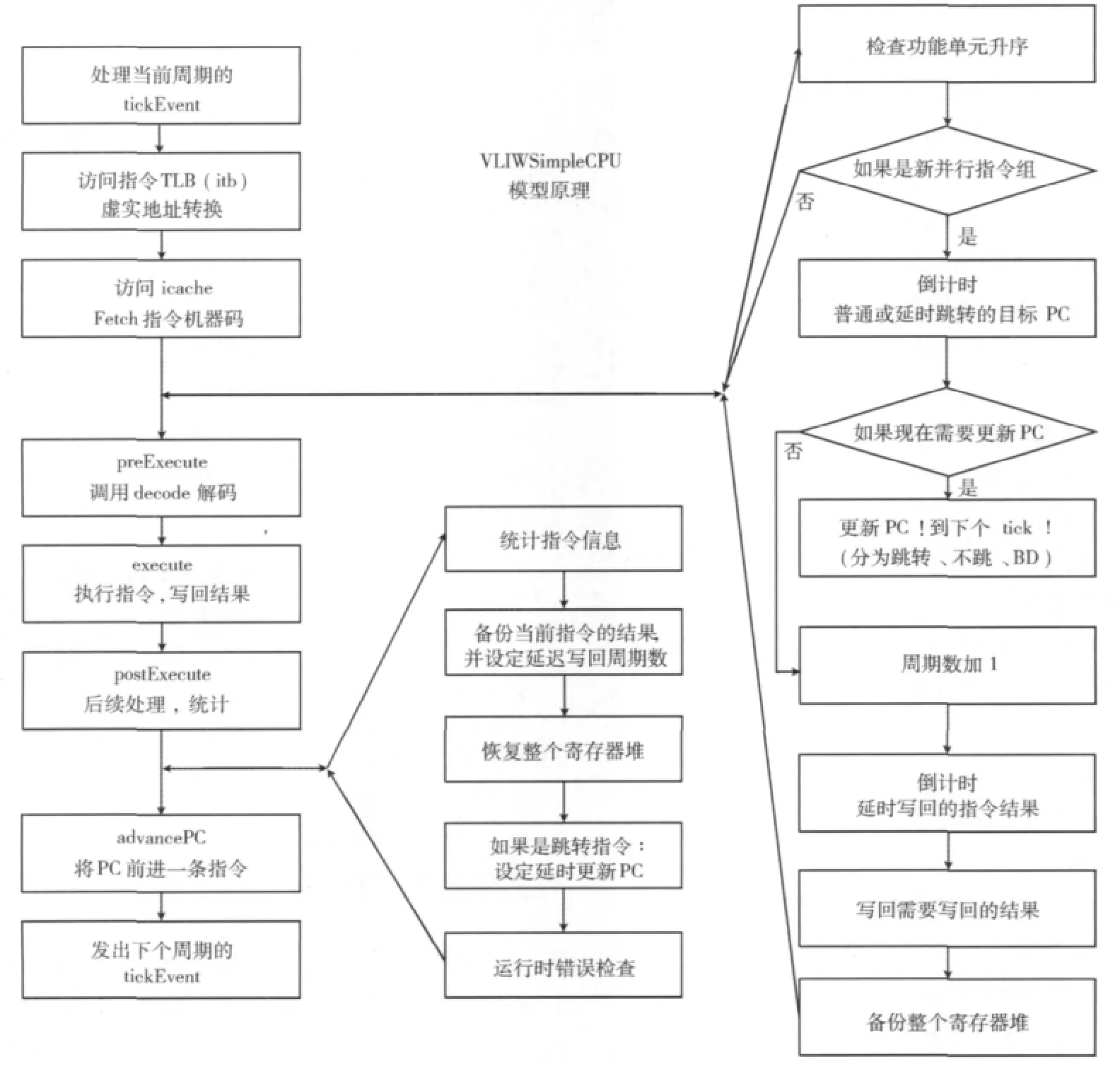
图3 VLIWSimpleCPU流程模型
因为Lily处理器根据获取的超长指令字包中各指令对应的功能单元的编号大小判断当前指令是否能够与下一指令并行执行[9],所以在取指之后,解码之前加入一个流程:首先,检查指令机器码中的功能单元是否升序,也就是说,Lily处理器的功能单元是按照XA、XM、XD、YA、YM、YD顺序来排列的,如果取得的指令的功能单元是升序,说明这是同一个指令组,否则是一个新的指令组。如果不是一个新的指令组,那么,对应着VLIW DSP上还在同一周期,因为所有的控制流程都发生在一个并行指令组执行完成时,所以这条指令进入顺序执行流程。
如果是新的指令组,那么对应着VLIW DSP也前进一个周期,此时,由于延迟跳转或者跳转倒计时减一个周期,需要根据倒计时的值判断是否需要更新PC值。如果需要更新PC值,分为跳转、不跳(条件跳转的条件不成立的情形)、BD(延迟跳转)3种情形,更新PC,到下一个tick,执行另一个新的并行组。如果不需要更新PC值,表示这个新的并行组将会被执行,周期数加1,倒计时延迟写回的结果,写回需要写回的结果后备份整个寄存器堆。
在后续处理之后,PC前进一条指令之前,加入一个流程:统计指令执行的信息,比如功能单元的使用情况;备份当前指令的结果,并设定延迟写回的周期数以模拟多周期指令和并行执行的情况,由于在同一个并行组执行的指令需要使用整个并行组执行前的寄存器堆状态,所以恢复整个寄存器堆以便下一条指令使用,如果是跳转指令,设定延时更新PC,然后进行运行时错误检查。
4 移植步骤
4.1 总体步骤
Gem5[5]模拟器是由美国密歇根大学开发的一款开源处理器模拟器,是可配置、集成多种指令集(ISA)和多种处理器模型的体系结构模拟器。Gem5具有很强的灵活性,提供了多种处理器模型,多种系统模型以及多种存储模型,采用面向对象的设计。Gem5提供了定制硬件的功能,gem5提供了ISA DSL(domain-specific languages)[5],可以用来指定ISA。Gem5的配置主要是由python语言来完成的,而主要结构是用C++来完成的。首先,配置gem5声明新的VliwSimpleCPU模型;然后改写处理器模型及寄存器定义;添加16/32位混合指令取指机制,最后添加处理器的ISA定义。
4.2 配置gem5声明新的处理器模型
修改编译选项,添加超长指令字的处理器选项;修改配置脚本文件,添加VLIW DSP的处理器模型;修改配置文件,添加目标指令信息以及自定义统计标志;
从相似体系结构移植目标处理器的体系结构。
其中配置文件的部分代码如下:
TARGET_ISA=‘lily’
CPU_MODELS=‘InOrderCPU,VliwSimpleCPU’
4.3 改写处理器模型
修改AtomicSimpleCPU模型,实现前面提出的Vliw SimpleCPU模型模拟VLIW DSP执行的情况;
定义寄存器堆。
样品及耗材:蓝莓(蓝雨),余姚市舜南休闲农庄蓝莓种植基地产;葡萄酒果酒专用酵母,安琪酵母股份有限公司;二氧化硫(食品级),天津化工厂;白砂糖(一级),广东江门甘蔗化工厂。
部分代码用伪C++代码描述如下:
VliwSimpleCPU::tick(){
fetch inst;
//检查是否升序判断是否新的并行指令组
checkInstOrder();//功能单元是否升序
if(isNewParallelGroup()){
countDownPCCycle();
if(nowUpdateTargetPC()){
}
BackupRegFiles();
}
//如果不是新的并行指令组则正常执行
RestorRegFiles();
…
updatePC();
}
4.4 添加处理器的ISA定义
首先,定义寄存器类型,TLB,中断等所有处理器相关的特性,然后,是具体指令集的实现,包括指令编码方式的定义,指令模板的定义,条件寄存器选择位的实现,以及全部指令具体功能的定义等。
Gem5提供了很方便的ISA DSL,定义自定义指令集。首先定义位域含义,然后,再定义指令执行的动作。如以下表示指令的23-20位可以用RS表示,然后在执行的时候经过层层解码,最后解出来是一个减法指令,在后面写出具体的动作,这里Rs.sl表示Rs是一个寄存器,由上面的位域定义规定在指令里的位,sl表示属性。这样就规定好了一条指令。
def bitfield RS<23:20>
decode OPCODE1{
0x2:IntOp::sub_16_xa(Rd_16.sl=Rd_16.sl– Rs_16.sl);
…
5 测试验证
在完成了Lily处理器的处理器模型后,需要添加指令集,这里采用了每添加一类指令后,分别对每一类指令的每一条指令分别测试,验证单条指令执行的正确性。测试项目如表1所示,测试结果表明,gem5正确模拟执行了指令集里的所有指令。

表1 模拟器单条指令测试
在单独测试完每一条指令的正确性后,还需要测试模拟器运行Lily处理器的典型应用程序的正确性以及周期数。如图4所示,测试结果表明,模拟器上的周期数和硬件上执行的周期数是一致的,达到了指令级精度的要求。
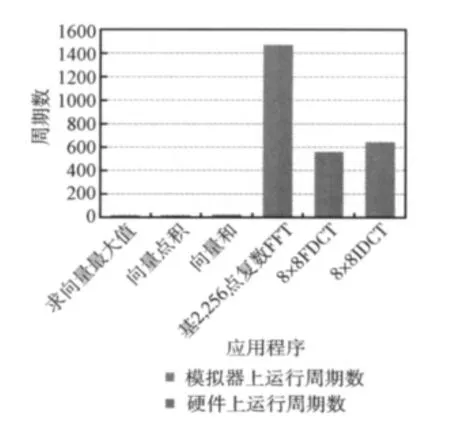
图4 模拟器测试周期数(向量长度为32)
6 结束语
Gem5是m5和gems最好的部分的综合[5],gem5采用了面向对象的编程模型,通过良好的层次结构,使得用户可以方便的添加新的处理器模型[10],在gem5模拟器的基础上,通过移植,快速实现了一款VLIW DSP的指令级精度的模拟器。相较于其它实现方法,本文提出的实现方法利用了开源软件,在原有的模型上加入了VLIW DSP的处理流程模型,具有原理简单,降低了实现复杂度,实现迅速的优点,满足了VLIW DSP的指令级精度仿真的需求。
在需要模拟处理器的更多细节,以及需要进行性能仿真时,gem5提供了其它的具有更多细节的处理器模型。可以基于有更多细节的模型进行移植。
[1]YANG Wei,CHEN Mingyu,XU Jianwei.Fast implementation of cycle-level processor simulator[J].Computer Engineering and Applications,2010,46(6):63-66(in Chinese).[杨伟,陈明宇,许建卫.一种时钟级处理器模拟器的快速开发方法[J].计算机工程与应用,2010,46(6):63-66.]
[2]YANG Yibin.Design and implementation of multi-target instruction set simulator[D].Zhengzhou:The PLA Information Engineering University,2009(in Chinese).[杨义彬.多目标指令集模拟器的设计与实现[D].郑州:解放军信息工程大学,2009.]
[3]ZHANG Fuxin,ZHANG Longbing,HU Weiwu.Simgodson:a godson processor simulator based on SimpleScalar[J].Chinese Journal of Computers,2007,30(1):68-73(in Chinese).[张福新,章隆兵,胡伟武.基于SimpleScalar的龙芯CPU模拟器Sim-Godson[J].计算机学报,2007,30(1):68-73.]
[4]XU Jianwei,CHEN Mingyu,YANG Wei,et al.Technology and trends of computer architecture simulators[J].Journal of System Simulators,2009,21(20):6325-6331(in Chinese).[许建卫,陈明宇,杨伟,等.计算机体系结构模拟器技术和发展[J].系统仿真学报,2009,21(20):6325-6331.]
[5]Brad Beckmann.The gem5simulator[EB/OL].[2011-06-05].http://www.gem5.org/dist/tutorials/isca_pres_2011.pdf.
[6]YAN Yingjian,YE Jiansen,LIU Junwei,et al.VLIW processor ISA modeling and aided software optimization technology[J].Computer Engineering and Design,2009,30(11):2727-2729(in Chinese).[严迎建,叶建森,刘军伟,等.VLIW处理器ISA建模与辅助软件优化技术[J].计算机工程与设计,2009,30(11):2727-2729.]
[7]Yuan Liu,Hu He,Teng Xu.Architecture design of variable lengths instructions expansion for VLIW[C]//Changsha,Hunan:IEEE 8th International Conference on ASIC,2009.
[8]David A Patterson,John L Hennessy.Computer organization and design[M].3rd ed.San Francisco:Morgan Kaufmann Publishers,2005:521-527.
[9]Huawei Technologies Co,Tsinghua University.A Parallel Execution Method and Equipment for VLIW[P].China:200810101451.9,2009(in Chinese).[华为技术有限公司,清华大学.一种超长指令字指令并行执行方法及装置[P].中国:200810101451.9,2009]
[10]ZHAO Jingyan.Implementation of ARCA3Full system based on M5[D].Harbin:Harbin Institute of Technology,2010(in Chinese).[赵景琰.基于M5的方舟3全系统实现[D].哈尔滨:哈尔滨工业大学,2010.]
猜你喜欢
有色金属设计(2022年4期)2022-02-04
小哥白尼(趣味科学)(2021年6期)2021-11-02
故事作文·高年级(2021年4期)2021-05-06
小哥白尼(神奇星球)(2021年11期)2021-03-08
计算机应用(2020年5期)2020-06-07
电子制作(2019年10期)2019-06-17
电子技术与软件工程(2018年1期)2018-03-22
现代防御技术(2016年1期)2016-06-01
海军航空大学学报(2015年1期)2015-11-11
空间控制技术与应用(2015年4期)2015-06-05
