
上下文感知的分布式缓存数据重均衡方法
2013-11-30 05:01:38秦秀磊张文博
计算机工程与设计 2013年1期
朱 鑫,蒲 卫,秦秀磊,张文博,钟 华
(1.中国科学院软件研究所 软件工程技术研究开发中心,北京100190;2.中国科学院研究生院,北京100190;3.解放军卫生信息中心,北京100842)
0 引 言
作为一种新的基于互联网的IT服务增值、使用和交付模式,云计算自产生以来就得到工业界和学术界的广泛关注,目前正变成商业上的现实[1]。云计算环境下,为了解决传统关系型数据库的性能瓶颈,分布式缓存技术得到广泛应用,为用户提供高性能、高可用、可伸缩的数据缓存服务。从云计算三层服务模式(基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS))的角度划分,分布式缓存位于PaaS层,提供应用加速与平台的状态维护服务。
由于应用数据访问的不均衡性,缓存系统中往往存在若干热点数据分区,包含较多热点数据分区的节点负载较高,易达到性能瓶颈,而应用访问模式的时变性也会导致热点数据分区的分布随时间而变化[2]。因此缓存系统需要定期地执行数据重均衡操作,以保障数据和负载在各节点间均衡分布,最大化资源利用率,提升系统性能。
数据迁移过程中,缓存系统的性能会下降。如根据淘宝Tair[3]的迁移数据访问机制,对某些访问请求需要增加一次服务器转发操作,导致系统的平均响应时间增加。因此在制定数据重均衡方案时,应尽量缩短迁移时间。
当前主流的云平台均使用虚拟化技术来屏蔽底层硬件的差异性及实现资源的快速部署。如亚马逊的EC2和微软的 Windows Azure分别使用了基于Xen[4]和基于 Hyper-V的虚拟化技术。对于部署在云平台中的缓存系统而言,节点间的数据迁移会受到以下两方面环境上下文的影响:
(1)迁移节点的物理位置:迁出节点(数据分区从其迁出的缓存服务器节点)和迁入节点(数据分区迁入的缓存服务器节点)所在的VM可能位于同一台物理机,也可能位于不同的物理机。两种情况下数据迁移的物理路径有显著差别,因而迁移速度不同。
(2)VM间性能干扰:由于VM间存在性能干扰,无论是同一物理机内还是跨物理机的数据迁移的速度都会随着物理机上部署的VM数量和运行状态的变化而变化。
本文在基于Xen虚拟化技术搭建的VM集群上部署分布式缓存系统,研究环境上下文对分布式缓存数据重均衡的影响,提出了一种上下文感知的分布式缓存数据重均衡方法。该方法由两部分组成:①迁移时间预测模型。根据VM状态预测物理机内和物理机间迁移一定数据量所需的数据迁移时间,为数据重均衡方案的制定提供依据。②上下文感知的数据重均衡算法。基于对缓存数据分区数据量和网络流量的细粒度监测,该算法同时考虑缓存数据量均衡,网络流量均衡和迁移时间较短这3个优化目标,以制定有效的数据重均衡方案。使用Yahoo公司的云存储服务测试基准YCSB[5]对上述方法进行了测试,实验结果表明,该方法能够准确预测迁移时间,上下文感知的数据重均衡算法与传统数据重均衡算法相比,能够提供较好的均衡效果及较短的迁移时间。
本文的研究工作基于中科院软件所自主研发的分布式缓存系统OnceDC[6]进行。OnceDC采用类似亚马逊Dynamo[7]的分区机制,数据被存储在分区中,单个缓存服务器节点(简称缓存节点)可包含多个分区。此外OnceDC采用缓存客户端主动路由及缓存集群管理器集中管理的方式。
1 研究动机
1.1 Xen的I/O模型
在基于Xen的虚拟化体系结构中,每个客户操作系统都运行在一个虚拟域(domain)中。其中,dom0是特权域,拥有原生设备驱动,具有直接访问I/O设备的特权,并通过和Xen虚拟机控制器(virtual machine monitor,VMM)的交互来控制和管理其它的虚拟域(称为domU)。dom0向domU提供I/O设备模型和平台,domU访问IO资源均需经过dom0进行。如图1所示。
图1中,假设dom1(准确的讲是对应的VM,下同)需要和dom2进行网络通信,那么,他们之间发送的网络包会通过dom0传递,但不会经过物理网卡。而如果dom1要和另一台物理机上的某个VM通信,网络包会经过两台物理机的dom0,同时会经过两台物理机的网卡。由于物理机内和物理机间VM通信均会经过dom0,因此一台物理机上有多个VM同时进行网络I/O操作时会发生性能干扰。
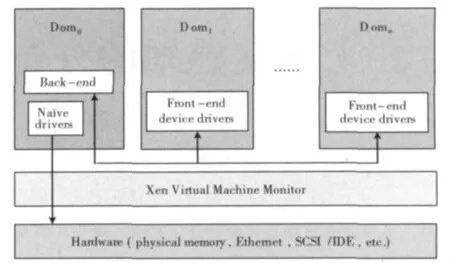
图1 Xen的I/O模型
1.2 虚拟化环境上下文对迁移时间的影响
1.2.1 实验方案
为了研究Xen虚拟化环境下迁移节点所处的物理位置以及VM间性能干扰对数据迁移产生的影响,我们基于YCSB生成客户端负载,然后在不同环境上下文条件下迁移数据,寻找迁移时间的变化规律。实验基于的软硬件环境与3.1节一致。在每个VM上部署1个OnceDC缓存服务器节点。变化部署的VM数量时,通过改变YCSB实例的个数,保证每个缓存节点承担的负载不变。执行一条迁移命令将定量数据从一个缓存节点迁移到另一个缓存节点,统计迁移时间。
1.2.2 实验结果分析
图2给出了迁出节点与迁入节点所在VM位于同一个物理机和不同物理机这两种情况下分别迁移50M,100M,200M,300M数据所用的时间。可以看到跨物理机间的迁移相比同一物理机内的迁移,需要消耗更多的时间,并且随着迁移数据量的增加,两者之间的差距也在增大。
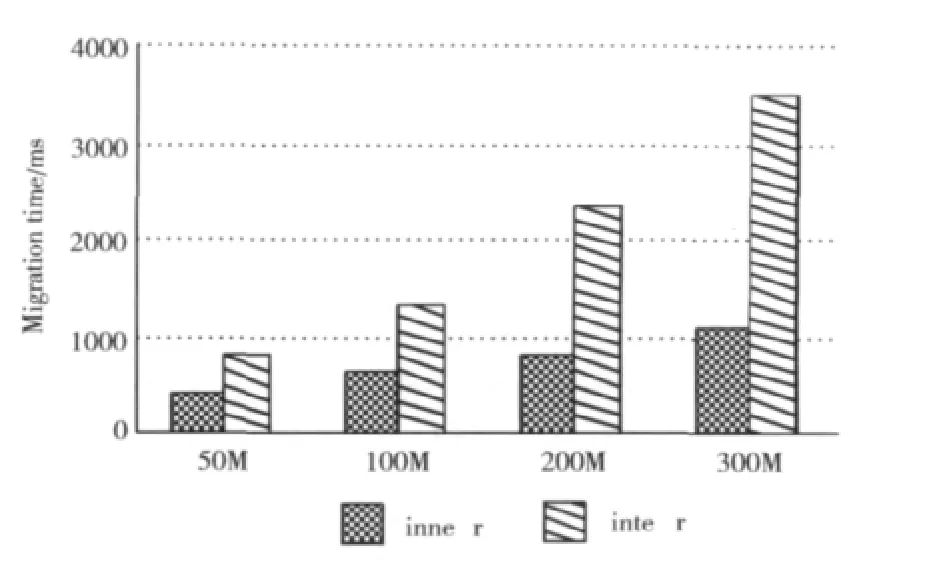
图2 缓存节点物理位置对迁移时间的影响
图3对比了部署不同数量VM的情况下,位于同一物理机内的两个缓存节点间分别迁移50M,100M,200M,300M数据所用的时间。对于每种迁移数据大小的一组数据,均以仅部署两个VM时的迁移时间为基准标准化。由图3可知,同一物理机内的两个缓存节点间迁移数据时,VM间的性能干扰使迁移时间最多增加了近2倍(迁移50M数据时)。
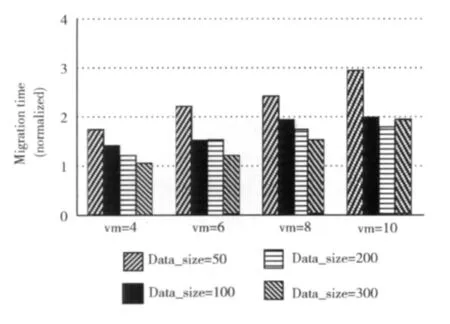
图3 VM间性能干扰对迁移时间的影响(物理机内迁移)
图4对比了部署不同数量VM的情况下,位于不同物理机的两个缓存节点间分别迁移50M,100M,200M,300M数据所用的时间。VM=(x,y)表示迁出节点和迁入节点所在的物理机中分别部署了x与y个VM。对于每种迁移数据大小的一组数据,均以VM=(1,1)时的迁移时间为基准标准化。由图4可知,物理机间迁移数据时,VM间的性能干扰对迁移时间的影响更为显著,迁移时间最多增加了3倍。
综上可见,迁移节点所处物理位置和VM间的性能干扰对缓存系统的数据迁移具有无法忽略的影响,因此在制定数据迁移计划时需要考虑该因素。
1.3 XenMon工具数据分析
1.3.1 实验方案
基于XenMon[8]工具对性能干扰因素进行深入分析。XenMon是由惠普实验室开发的一款应用于Xen平台的性能监测工具。其底层使用xentrace和xenbaked收集数据,前端使用Python编写的xenmon提供界面展示。变化物理机上缓存节点(VM)的部署数量,分别在物理机内和物理机间迁移100M数据,使用XenMon监测迁移过程中Xen平台的性能。其它实验设计与1.2节一致。
1.3.2 实验结果分析
图5给出了在物理机内迁移时,迁出节点所在domain(dom1)部分性能指标随VM数量的变化情况。各监测指标均以部署2个VM时的测量值为基准标准化。随着VM数量的增加,VM对网络资源的竞争越来越激烈,因而dom1在I/O等待队列的时间逐渐增长(blocked(%)_dom1);系统中运行队列的长度得以降低,处于可运行状态(runnable)的VM获得时间片相对容易,导致等待时间逐步降低(waited(%)_dom1);I/O阻塞越来越多,导致消耗的CPU资源降低(cpu(%)_dom1),同时每秒执行次数降低(ex/s_dom1)。
图6给出了在物理机间迁移时,迁出节点所在domain(dom1)及其所在物理机的dom0部分性能指标随VM数量的变化情况。各监测指标以VM=(1,1)时的测量值为基准标准化。随着VM数量的增加,各VM间I/O竞争越来越激烈,因而dom0进入阻塞状态及I/O切换的次数增加(Block_dom0与Switch_dom0),内存页映射次数增加(PageMap_dom0);系统中运行队列的长度得以降低,迁出节点所在VM处于可运行状态(runnable)时获得时间片相对容易,导致每次执行的等待时间降低(Waited/ex_dom1)。
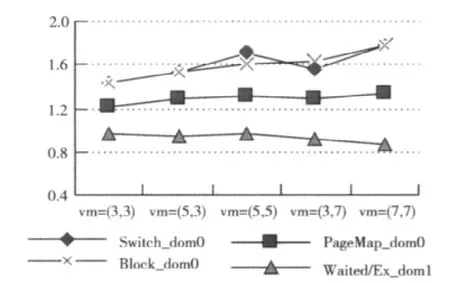
图6 XenMon监测指标随VM数量的变化(物理机间迁移)
可见,XenMon的监测数据反映了VM间性能干扰的程度。
2 上下文感知的分布式缓存数据重均衡方法
由上文可知,①迁移节点所处的物理位置以及VM间性能干扰对分布式缓存的数据迁移具有无法忽略的影响。②XenMon收集的监控数据指标较好的反映了Xen虚拟化环境下VM间的性能干扰。③数据重均衡过程的一个重要的优化目标是尽可能的减少数据迁移时间。因此本章首先基于统计学习方法建立虚拟化环境下XenMon收集的底层监测数据与迁移时间之间的映射关系,即迁移时间预测模型;然后以该模型为基础,提出一种基于细粒度资源监测的上下文感知的数据重均衡算法,从而改善虚拟化环境下缓存系统的性能。
2.1 迁移时间预测模型
2.1.1 模型目标
我们的目标是建立XenMon监测数据,迁移数据量与迁移时间的映射关系。具体来说,希望建立如下函数
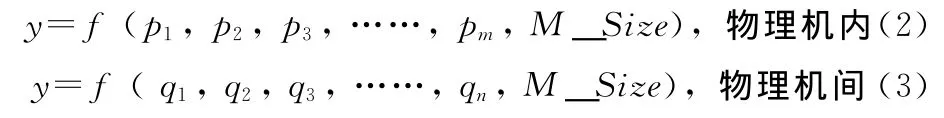
pi(1<=i<=m),qi(1<=i<=n)分别为物理机内和物理机间迁移时间预测模型选取的监测指标。M_Size表示迁移数据量,y表示迁移时间。
2.1.2 监测指标的选取
XenMon包含的监测指标较多,在分析了各指标的意义后,我们选择关注如表1所示的监测指标。

表1 XenMon监测指标的选取
表1中包含的各监测指标的含义说明如下:
·CPU(%):domU使用cpu的时间占对应统计间隔的百分比。
·Blocked(%):domU由于等待I/O事件发生而阻塞的时间占对应统计间隔的百分比。
·Waited(%):domU处于可运行状态,等待被调度的时间占对应统计间隔的百分比。
·Waited/ex:domU平均每次被调度运行需要等待被调度的时间。
·Ex/s:domU每秒被调度运行的次数。
·Wake:统计间隔内dom0被唤醒的次数。
·Block:统计间隔内dom0等待I/O事件发生所用的时间。
·Switch:统计间隔内系统中发生的domU切换次数。
·PageMap:统计间隔内发生的页映射次数。
2.1.3 数据预处理
为了减少监测指标数量级间的差异对建模过程产生的影响,我们对收集到的监测数据进行Z标准化(Z-standardization)处理,如式(4)所示

式中:μ、σ——所有样本的均值、方差,X——样本值,X*——标准化后的值。
2.1.4 线性模型
我们基于回归分析的方法构建线性预测模型,函数关系式如式(5)、式(6)所示。物理机内数据迁移
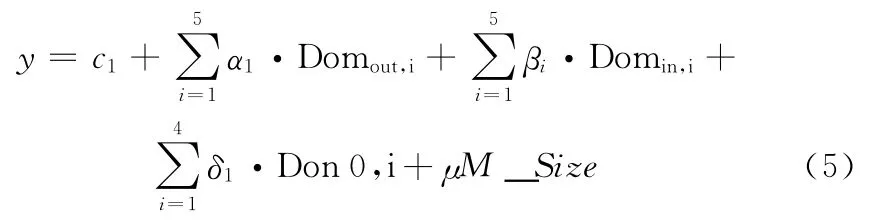
式中:αi,βi,δi,μ——回归系数,c1——常量。
物理机间数据迁移
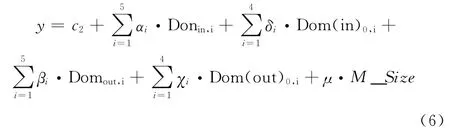
式中:αi,δi,βi,χi,μ——回归系数,c2——常量。
在构建线性模型的过程中,我们采用了两种方法:主成分分析法和逐步回归法。
(1)主成分分析法
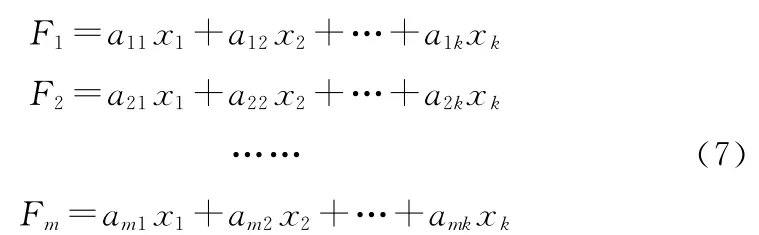
主成分分析(principal components analysis,PCA)也称为主分量分析,是一种对高维变量进行综合与降维的统计分析方法。我们先使用主成分分析从原变量中提取出若干具有最佳解释能力的新综合变量(也称成分),这些综合变量由原变量线性组合得到,可以反映初始变量的大部分信息,如式(7)所示。然后将上述成分作为回归变量进行最小二乘回归分析得到最终的模型。我们称这种方法建立的线性模型为PCA-LM。
(2)逐步回归法
在线性回归模型中,若干变量或全部变量的样本观测值之间可能存在某种线性关系,这种现象即多重共线性,该现象会降低模型估计的精度。逐步回归(stepwise regression)是一种常用的消除多重共线性、选取 “最优”回归方程的方法。其做法是逐个引入自变量,引入的条件是该自变量经F检验(F-test)是显著的,每引入一个变量后,对已选入的变量进行逐个检验,如果原来引入的变量由于后面变量的引入而变得不再显著,那么就将其剔除。引入一个变量或从回归方程中剔除一个变量,为逐步回归的一步,每一步都要进行F检验,以确保每次引入新变量之前回归方程中只包含显著的变量。这个过程反复进行,直到既没有不显著的变量选入回归方程,也没有显著变量从回归方程中剔除为止。我们首先使用逐步回归方法消除冗余指标,然后基于最小二乘法求解模型。将使用这种方法建立的线性模型称作Stepwise-LM。
2.1.5 非线性模型(nonlinear models)
我们首先采用主成分分析法对监测指标进行降维处理,然后构建一个面向主成分的完全二次多项式函数,如式(8)所示
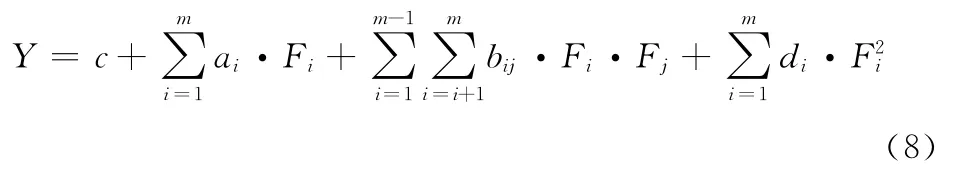
式中:ai,bij、di——回归系数,c——常量,Fi(1≤i≤m)为主成分。在构建该函数时,采用高斯-牛顿(Gaussi-Newton)法进行最小二乘拟合。将这种方法建立的非线性模型简称为PCA-NLM。
2.1.6 模型的训练
我们使用迭代的方法完成模型的训练,选用的训练参数如表2所示。具体做法是首先选取参数的边界值组合作为输入,运行实验并收集采样数据,接下来随机选取边界之间的若干组值再次作为输入收集训练数据。对训练得到的模型的预测错误率进行评估,如果高于设定的阈值(如30%),则进一步将输出值细分,判断每个区间的覆盖情况。如果没有覆盖,则增加能较好覆盖这部分区间的训练数据。

表2 训练模型使用的输入负载
2.2 上下文感知的数据重均衡算法
根据上一节得到的迁移时间预测模型,对于给定的上下文(迁入迁出节点的物理位置,相关domain的XenMon监测数据),可以求得迁移指定数据量所需的迁移时间。为了改善数据重均衡的效果,同时降低迁移时间,本节基于上述模型提出一种上下文感知的数据重均衡算法(contextaware data rebalancing algorithm),简称CADR算法。
为方便描述,先给出如下定义:
定义1 缓存集群C中包含n个缓存节点,分别用S1,S2,……,Sn表示。size[Si]为Si上的分区个数,Si上的第j个数据分区用Sij表示。
定义2mem[Sij],net[Sij]分别为Sij的数据量和网络流量。mem[Si]和net[Si]分别为Si上各分区数据量与网络流量之和,mem-cap[Si],net-cap[Si]分别为Si的内存限额和网络流量限额。
定义3 分别用mem-rate[Si]和net-rate[Si]表示节点Si的内存利用率和网络利用率,mem-rate[Si]=mem[Si]/mem-cap[Si],net-rate[Si]=net[Si]/netcap[Si]。定义节点Si的综合利用率为内存利用率和网络利用率之乘积,用mn-rate[Si]表示。
约束1:为了减少迁移时间,我们设定单个缓存节点的迁移方向是固定的,即在一次数据重均衡过程中不会同时有数据分区的迁入和迁出。
CADR算法存在以下3个优化目标:①缓存节点的数据量均衡;②缓存节点的网络流量均衡;③数据迁移所需时间尽可能短。
CADR算法伪代码如图7所示,说明如下:
(1)1-2行,按照mn-rate将节点划分进迁出节点集合out-set及迁入节点集合in-set。ε为一个大于1的常数,变化ε可以调整算法最终的均衡度及迁移的数据量。
(2)第4行从out-set中选出mn-rate值最高的节点Sf作为当前步的迁出节点。第5-8行从Sf中选出当前步的迁移分区,使得迁出节点的内存利用率和网络利用率之比尽量接近缓存集群的平均值。
(3)第9-19行基于3.1节得到迁移时间预测模型,从in-set中选出一个节点St存放分区P,使得迁移时间最短。
(4)第20行将<Sf,St,P>加入迁移计划中,第21-22行更新Sf,St相应的统计量。
第9行比较耗时,设其平均时间复杂度为O(l),再设缓存集群中分区总数为m,缓存节点数为n,则CADR算法的整体复杂度为O(m(n(l)。迁移时间预测模型使用离线训练的方式得到,在线预测迁移时间时所需的Xen-Mon监控数据通过运行在dom0上的agent收集并定期发送给缓存集群管理器。
CADR算法由缓存集群管理器触发执行。根据其返回结果能够生成新的分区路由信息及迁移计划。为了避免迁移流量过大影响缓存系统的持续可用性,可在迁出节点实施流量控制。此外,应实现迁移数据访问协议以能持续访问迁移中的数据分区。这两方面内容在[6]中作了讨论。

图7 CADR算法
3 实验结果与分析
我们在OnceDC上实现了上下文感知的分布式缓存数据重均衡方法。本章通过实验证明该方法的有效性。
3.1 实验方案
实验环境拓扑结构图如图8所示。S1,S2,S3为三台16核的刀片机,我们在所有刀片机上安装了Xen虚拟化环境。在每个刀片上部署若干个VM,并在每个VM上部署一个缓存服务器节点。测试客户端使用YCSB,且每个YCSB实例部署在4核的普通PC上。YCSB所在物理机和S1,S2,S3之间使用1Gbps的以太网连接。OnceDC的缓存集群管理器部署在一台4核PC上。表3给出了实验环境配置。
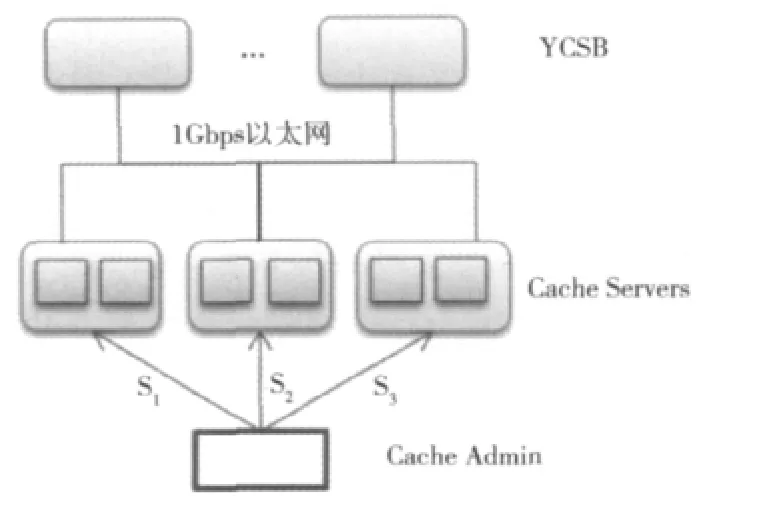
图8 实验环境拓扑结构
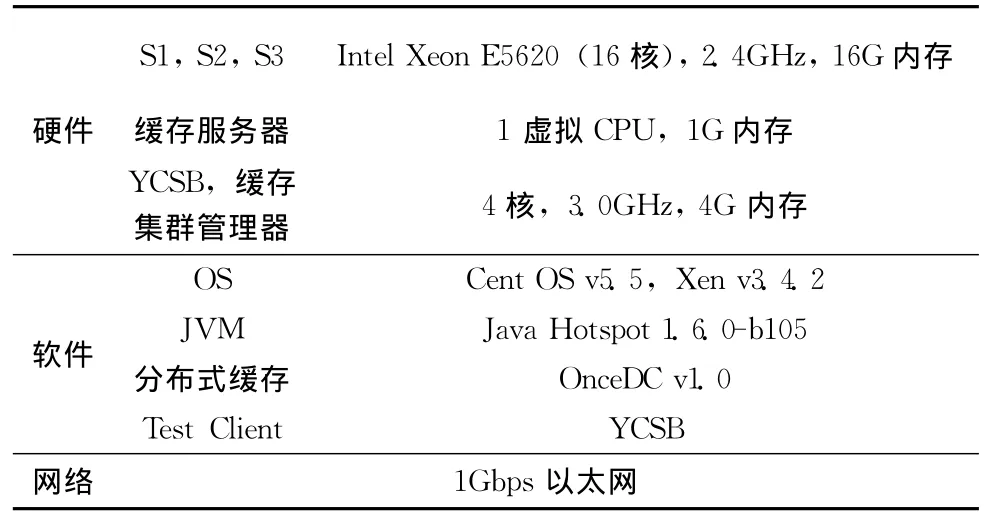
表3 实验环境配置
在两次实验中,每个YCSB实例运行500线程,读写比设为4∶1,每条缓存数据的大小为4KB。
3.2 实验1:迁移时间预测模型的准确度
对于2.1节使用3种方法分别创建的迁移时间预测模型PCA-LM、Stepwis-LM和PCA-NLM,通过实验测量预测错误率的方法来评价其准确度。预测错误率定义为
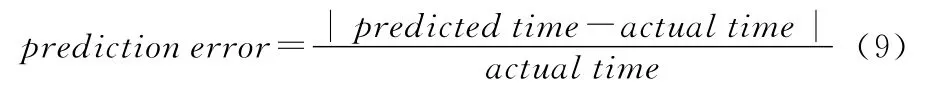
3.2.1 物理机内迁移
在S2和S3上分别部署8和10个VM(缓存节点)。部署6个YCSB实例产生负载,YCSB使用uniform负载模式。变化S1上部署的VM(缓存节点)的数目(4,6,8,10),对于这4种情况,通过缓存集群管理器发出将定量数据(50M,100M)从S1上的一个缓存节点迁移到另一个缓存节点的命令,统计迁移时间,同时收集VM性能数据,按照各模型计算预测的迁移时间。每组配置重复实验5次,分别计算预测错误率,最后取平均值。这样得到物理机内迁移时3种模型的预测错误率如图9所示。
由图9可知,在物理机内迁移时,3种模型的预测错误率差别比较大,如在VM=4时,PCA-LM模型的错误率超过30%,而Stepwise-LM模型的错误率为10%左右。Stepwise-LM模型在各种配置下均具有较低的预测错误率(低于13%)。
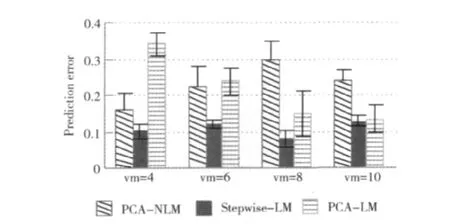
图9 3种迁移时间预测模型的错误率(物理机内迁移)
3.2.2 物理机间迁移
在S3部署10个VM(缓存节点),部署6个YCSB实例来产生负载,YCSB使用uniform负载模式。变化S1,S2上部署的VM及缓存服务器的数目((3,3),(5,3),(5,5),(3,7),(7,7))。对于这5种情况,通过缓存集群管理器发出将定量数据(50M,100M)从S1上的一个缓存节点迁移到S2上另一个缓存节点的命令,统计迁移时间,同时收集VM性能数据,按照各模型计算预测的迁移时间。每组配置重复实验5次,分别计算预测错误率,最后取平均值。这样得到物理机间迁移时3种模型的预测错误率如图10所示。
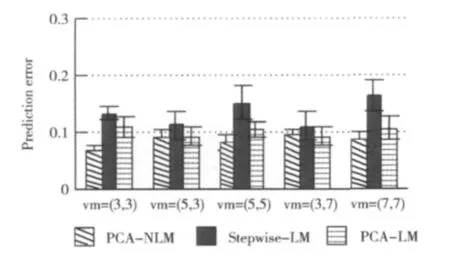
图10 3种迁移时间预测模型的错误率(物理机间迁移)
由图10可知,在物理机间迁移时,3种模型的预测效果都比较理想。其中PCA-NLM模型具有最低的预测错误率(低于10%)。
由本实验可知,迁移时间预测模型具有较高的准确度。
3.3 实验2:数据重均衡算法的有效性
OnceDC原有的数据重均衡算法,也以整个缓存集群的数据量和网络流量均衡为目标,不过其只对每个缓存节点具有的数据量和网络流量进行了监测,因此在制定迁移计划时将一个节点上的多个分区等同对待,忽略了各分区之间数据量和网络流量的差异;同时它也没有考虑虚拟化环境上下文对迁移时间的影响。我们称之为SPDR算法(simple partition based data rebalancing algorithm)。本节比较分别使用CADR算法和SPDR算法进行数据重均衡的效果,以验证CADR算法的有效性。
实验时,在S1,S2,S3上分别部署12,8,10个VM及缓存服务器节点。使用6个YCSB实例来生成访问负载,YCSB按照表4所示的负载模式访问缓存集群。配置缓存集群每2分钟执行一次数据重均衡操作。分别配置SPDR算法和CADR算法进行实验,结果如图11所示。

表4 实验2YCSB的负载模式
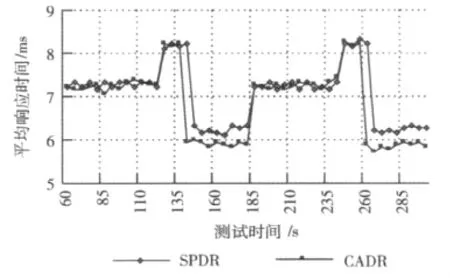
图11 SPDR算法与CADR算法比较
缓存集群初始时按照基于负载权重的分区机制在各缓存节点分配数据分区[6]。由于YCSB的负载模式是latest,导致各缓存节点存在数据量和网络流量不均衡的现象,部分缓存节点cpu和网络利用率接近100%,而某些节点的资源未得到充分使用。在120s,缓存系统第一次运行数据重均衡算法,缓存系统进入不稳定(迁移)状态。在重均衡过程中,由于访问迁移中的数据开销较大,缓存系统的平均响应时间增大。在重均衡完成后,瓶颈缓存节点得到消除,因此系统的平均响应时间与重均衡前相比变小。在180 s,YCSB的负载模式从latest变成zipfian。各缓存节点的负载分布再一次出现不均衡,平均响应时间增大。240s时,第二次数据重均衡操作被触发。与第一次类似,在重均衡过程中,平均响应时间增大,重均衡结束后平均响应时间降到比重均衡前更小的水平。
与SPDR算法相比,CADR算法基于对每个分区的细粒度监控,更好地实现了数据量和网络流量的均衡,因此执行完数据重均衡后平均响应时间更低;同时在制定数据重均衡方案时考虑了虚拟机环境上下文的影响,优先选取迁移时间较短的方案,因此系统的性能抖动区间更小。
上述两个实验表明,针对部署在虚拟化环境下的缓存系统而言,本文提出的迁移时间预测模型具有较高的准确度;上下文感知的数据重均衡算法具有更好的均衡效果且迁移时间更短,能够有效降低缓存系统的平均响应时间,提高系统性能。
4 相关工作
Mei等人[9-10]针对虚拟化环境下VM间的性能干扰问题进行了研究。该研究工作表明,当网络I/O密集型或cpu密集型应用部署在同一物理机时,应用的性能会受到VM间性能干扰的影响。
现有工业界的分布式缓存系统如 Memcached,Terracotta EX,Oracle Coherence等大多不支持在运行时动态地进行数据重均衡,无法适应异构集群环境及实际数据访问情况的多样性。
美国东北大学的Kunkle[11]等人的研究工作在制定迁移计划的同时考虑了迁移开销的优化。作者定义了定值(constant)、线性(linear)、基于经验的(empirical)和非线性(non-linear)等多种模型。迁移算法迭代地选取开销最小的分区迁移方案。该工作的不足是未考虑迁移时间的影响。
加州大学圣巴巴拉分校的Das等人[12-13]针对多承租场景下数据库集群的数据迁移问题,提出了一种轻量级的、基于迭代复制的数据迁移方法,目标是尽可能降低迁移开销。作者同时给出了迁移过程中各种失效的处理及正确性证明。
Kari[14]将存储系统的数据迁移问题规约为图着色(multi-edge coloring problem)问题,目标是在满足各存储节点传输约束的前提下,使数据迁移消耗的时间片最少,即使用的颜色数量最少。与本文关注数据重均衡方案的制定不同,该文关注的是数据重均衡方案制定好后,如何有效的制定迁移计划,缩短全局迁移持续时间的问题。
本文提出的上下文感知的分布式缓存数据重均衡方法面向云虚拟化环境,同时考虑数据量和网络流量的均衡,并且尽可能的减少了迁移时间。
5 结束语
虚拟化环境中,迁移节点的物理位置及VM间性能干扰会对缓存数据迁移产生无法忽略的影响。本文提出一种迁移时间预测模型建模这种影响,在此基础提出一种基于细粒度资源监测的上下文感知的数据重均衡算法。实验结果表明,本文方法能够准确预测迁移时间,有效地均衡应用变化的负载,同时降低迁移时间,从而改善缓存系统性能。
[1]Armbrust M.Above the clouds:A berkeley view of cloud computing[R].Berkeley,California:EECS Department,University of California,2009:1-25.
[2]Zhang Gong,Chiu L,Liu Ling.Adaptive data migration in multi-tiered storage based cloud environment[C]//Miami,FL:Proc of IEEE 3rd Int’l Conf on Cloud Computing,2010:148-155.
[3]Taobao tair[EB/OL].[2012-03-12].http://code.taobao.org/p/tair/wiki/aboutus/.
[4]Barham P,Dragovic B,Fraser K,et al.Xen and the art of virtualization[C]//New York,USA:Proc of ACM SOSP,2003.
[5]Cooper B,Silberstein A,Tam E,et al.Benchmarking cloud serving systems with YCSB[C]//Indianapolis,Indiana,USA:Roceedings of the 1st ACM Symposium on Cloud Computing,2010:143-154.
[6]ZHU Xin,QIN Xiulei,WANG Lianhua,et al.Research on dynamic scaling of elastic distributed cache systems[J].Frontiers of Computer Sciences and Technology,2012,6(2):97-108(in Chinese).[朱鑫,秦秀磊,王联华,等.弹性分布式缓存动态扩展方法研究[J].计算机科学与探索,2012,6(2):97-108.]
[7]Hastorun D,Jampani M,Kakulapati G,et al.Dynamo:Amazon’s highly available key-value store[C]//Washington State,USA:Proc of ACM Symp on Operating Systems Principles,2007:205-220.
[8]Gupta D,Gardner R,Cherkasova L.XenMon:QoS monitoring and performance profiling tool[R].Hewlett-Packard Labs,Technical Report HPL-2005-187,2005.
[9]Mei Yiduo,Liu Ling,Pu Xing,et al.Performance measurements and analysis of network I/O applications in virtualized cloud[C]//Miami,FL:CLOUD,2010.
[10]Pu Xing,Liu Ling,Mei Yiduo,et al.Understanding performance interference of I/O workload in virtualized cloud environments[C]//Miami,FL:CLOUD,2010.
[11]Kunkle D,Schindler J.A load balancing framework for clustered storage systems[C]//Berlin,Heidelberg:Proceedings of 15th International Conference on High Performance Computing,2008:57-72.
[12]Das S,Nishimura S,Agrawal D,et al.Albatross:Lightweight elasticity in shared storage databases for the cloud using live data migration[J].Proceedings of the VLDB Endowment,2011,4(8):494-505.
[13]Elmore AJ,Das S,Agrawal D,et al.Zephyr:Live migration in shared nothing databases for elastic cloud platforms[C]//Athens,Greece:SIGMOD,2011:301-312.
[14]Kari C,Kim Y,Russell A.Data migration in heterogeneous storage systems[C]//Minneapolis,MN:In Proceedings of The 31st Int’l Conference on Distributed Computing Systems,2011:143-150.
猜你喜欢
环球时报(2022-03-29)2022-03-29 17:14:11
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
电子制作(2019年10期)2019-06-17 11:45:10
电子制作(2018年14期)2018-08-21 01:38:20
知识经济·中国直销(2018年7期)2018-07-27 02:49:52
电子测试(2017年11期)2017-12-15 08:57:56
网络安全和信息化(2015年8期)2015-12-03 01:03:34
