
面向PaaS的Web系统动态性能建模工具的设计实现
2013-11-30 05:01胡振碧张文博陈宇行张竹绿
计算机工程与设计 2013年1期
胡振碧,黄 翔,张文博,陈宇行,张竹绿
(1.中国科学院软件研究所 软件工程技术研发中心,北京100190;2.中国科学院软件研究所计算机科学重点实验室,北京100190;3.中国科学院研究生院,北京100049;4.306医院信息科,北京100101;5.中国中医科学院 中医药信息研究所,北京100700)
0 引 言
平台即服务(platform as a services,PaaS)是云计算的关键技术之一,不少大公司开始支持这种模式,包括Google的App Engine和Sina的App Engine等。PaaS将应用运行所需的软件资源和基础设施以服务的形式提供给用户,减少了用户在购置和管理应用生命周期内所必须的软硬件以及部署应用和IT基础设施的成本,同时简化了以上工作的复杂度。
平台服务通常基于自动化的技术通过虚拟化的形式交付,以确保实时动态地满足应用生命周期内的各种功能和非功能需求。Web应用的性能是用户敏感的一个关键性非功能需求,性能下降将直接导致用户流失和商业受损等严重后果。性能保障通常通过资源调度进行实施的,但是传统的反馈控制方法[1-2],只能达到局部优化,难以实现全局资源供给最优,因而高效的性能模型,评估全局资源利用的效率,就成了资源自适应(Self-adaptive)供给的核心。
但是,部署和应用模式的开放与动态性,为性能模型的构造提出了新的挑战:首先,由于应用和平台分属不同组织,难以预先构造Web系统的性能模型;其次,在开放和动态的环境下,用户的使用难以预期,因而也有必要使模型适应负载混合模式的变化。总之,新的使用环境为模型的来源和适应性提出了新的挑战。
传统的建模方法按照模型产生所处的软件生命周期划分,大致可分为基于经验的建模方法[3],基于测试环境的建模方法[4-5]和基于监控的建模方法[6-8]。基于经验 的 方法,主要用于软件需求分析与设计阶段,此时系统并未实现,模型主要依赖设计人员的经验,手工构造。所构造模型与系统实际运行和使用情况偏离较大。基于测试环境的方法主要针对应用的实现与部署阶段,此时系统已经可以运行,通过设计适当的测试用例自动获取性能模型。但是由于测试环境与实际运行环境存在差异,特别测试阶段难以预料用户会如何使用系统,模型也难以适应实际运行环境。基于监测的方法,通常用于负载规模(并发用户数)对性能的影响,因而忽略了负载混合(不同用户请求的混合比例)的影响。不同类型用户请求,对应于应用中不同的服务。忽略负载混合特征可以大大降低模型负载度,但同时也降低了模型预测的准确性。比如100个浏览商品的用户和100个下订单的用户,性能显然有所差异。总的来说,基于经验和测试环境的方法显然不适合新的环境,而现有基于监测的方法,模型精度偏低。因而有必要提出一种更有效的,基于监测的性能建模方法。
针对上述问题,本文给出了一种动态性能建模工具的设计与实现。该工具首先通过在Web系统中插入必要的探针,对系统进行监控,收集系统运行时状态并输出到日志文件中。然后通过周期性的对这些日志进行分析,从大量数据中提取出性能模型,使其与实际用户使用情况相符。其中,关键技术包括探针的插入与调用链构造方法,和大量数据分析与负载混合模式挖掘方法。探针的插入与调用链构造方法主要解决应用执行图构造问题。由于应用与平台分属不同组织,因而难以了解应用内部的执行特征。本文通过插入探针的方式记录应用中服务之间的调用历史,然后再通过对历史信息的分析,构造出应用执行图。负载混合模式挖掘方法主要用于分析用户使用系统的行为。Web应用的负载通常以会话(Session)的形式描述,但是由于日志中的用户记录是离散点,因而需要将离散的记录串联起来,形成完整的会话。日志增长速度非常快,大约为1-10MB/s[9],并且分布在不同的机器上。而会话信息本身又具有离散和分布的特点,比如同一个会话,很可能由于负载均衡的原因,从一台服务器迁移到另一台服务器。因此,本文给出了一种分析大量日志信息,并从中提取出基于会话的负载特征的方法。
1 研究背景
1.1 事务性Web应用PaaS平台
平台即服务(platform as a service,PaaS)是一种云计算服务,提供运算平台与解决方案堆栈即服务。在云计算的典型层级中,平台即服务层介于软件即服务与基础设施即服务之间。PaaS将软件研发的平台做为一种服务,以软件即服务(SaaS)的模式交付给用户。因此,PaaS也是SaaS模式的一种应用。但是,PaaS的出现可以加快SaaS的发展,尤其是加快SaaS应用的开发速度。
事务性Web应用,是当前主流的一种Web应用形式,比如电子商务,电子政务等。本文主要研究支持事务性Web应用的PaaS平台,比如,Google App Engine和Sina App Engine等。基于PaaS平台的应用程序易于构建和维护,可以根据用户的访问量和数据存储需要进行扩展。然而,Web应用的负载具有高可变性(highly variable),其规模和类型动态变化,导致负载激增(workload burstiness)、资源瓶颈转移(resource bottleneck shifting)等现象频繁发生,大大加剧了宿主平台资源管理的难度。
典型的事务性应用具有多层架构的特点,多层架构为应用提供了灵活的,组件化的设计模式。应用被划分为若干组件,并部署在不同的层次上。每层上的组件(Compo-nent)都会为其前驱节点提供特定的功能,并请求后续层次上的组件完成整个请求。在应用的整个生命周期中,各个层次上的组件都会参与到请求的处理之中。根据处理所需的资源量不同,某一层次可能会采用集群技术部署多个服务器。负载均衡器(load balance)负责分发请求,起到均衡各服务器计算开销的作用。
图1为一个事务性Web应用PaaS架构图,前两层由Web服务器和Java应用服务器的集群组成,第三层由不可重复的数据库服务器组成。该负载是基于会话,即由一连串的用户请求组成。首先是用户请求经过负载均衡器的分发到达相应的Web服务器,然后Web服务器与DB服务器进行数据交互,最后将处理好的数据返回给用户。本系统主要关注的是Web服务器和DB服务器的性能,该性能指标包括响应时间、吞吐率、资源利用率。
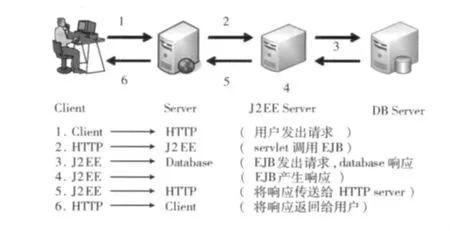
图1 Web应用三层架构
1.2 分层排队网
分层排队网(LQN)模型是扩展后的具有分层体系结构的排队网的一个规范形式,分层所表达的正是上层的服务器向低层的服务器发送请求。在分层排队网中,软件资源被称为任务,所提供的服务类被称为入口,每个入口的需求都可以通过几个阶段来实现,入口的执行时间即为服务时间。
对于Web系统这类应用,一个事务指同一页面上的不同请求,所以同一事务通常存在多条执行路径,不同执行路径上的概率并不一样,而根据轨迹信息构造的事务的带权执行图可以直接转换为对应的LQN结构图。LQN在形式上和体系结构相似,表示为一个非循环的图,节点表示软件组件和硬件资源,边则表示服务请求。只有出边没有入边的 “任务”扮演了客户的角色,中间具有入边和出边的 “任务”表示软件组件。“任务”可以包含多个功能或函数。“入口”包含表示一个服务时间的属性,还可以对其它“任务”的 “入口”发出请求。LQN模型建好后,经过计算,其结果以文件形式输出。
2 系统设计
本工具主旨是通过插入必要监测点,记录应用执行历史,然后再通过相关的日志分析技术从中提取出性能模型,性能模型的分析结果可以供自动分析模块做决策使用。系统架构图如图2所示。
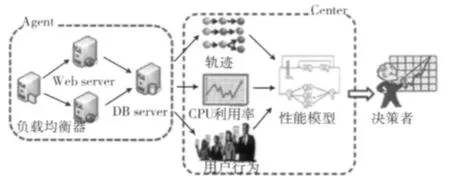
图2 系统架构
性能预测工具主要分为两个部分,一个是收集日志文件,本系统中日志文件主要记录应用的执行轨迹和服务器的资源消耗情况,另一部分是对收集到的日志文件进行分析,然后建立数据模型,最后给出预测结果。如图2所示,Agent部分主要起监控作用,即控制日志文件的收集和停止,具体包括Web服务器中应用的执行轨迹和CPU消耗情况,还有数据库服务器中CPU的消耗情况。Center部分起主控作用,向Agent发布收集和停止的命令,并对收集到的数据进行分析。对应的功能模块如图3所示。
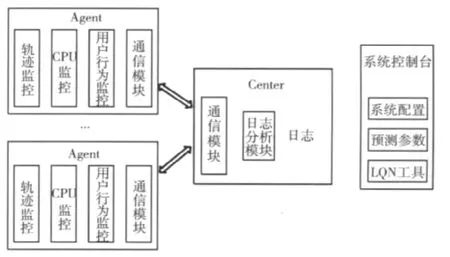
图3 功能模块
系统运行时,Agent部分将轨迹监控模块和CPU监控模块放入Web服务器中,CPU监控模块放入数据库服务器中,当Agent里面的通信模块接收到Center的通信模块发送过来的开始命令后,日志文件开始记录,当接收到停止命令后,日志文件停止记录,并且将收集到的日志文件传送到Center指定的地方,Center接收到数据后,日志分析模块和LQN模块根据用户填入的配置参数分析系统的执行轨迹和资源利用率,并建立LQN模型,最后根据用户的选择展示出预测结果和误差值。
3 系统实现关键技术分析
3.1 监控模块
监控模块主要负责记录应用的执行历史,包括3个部分,轨迹监控、用户行为监控、CPU利用率监控。
(1)轨迹监控是为了了解系统的执行轨迹,根据日志中收集的轨迹信息构造事务的带权执行图。本系统采用Aspectj技术,AspectJ将横切关注点封装为单独的方面,编译程序通过分析其中通知(advice)关联的切点(pointcut)寻找程序中对应的织入点,织入相应的通知调用。本系统中当捕获到一个HttpServlet方面时表示一个事务的开始,然后继续捕获后续执行的所有任务方面,比如数据库访问方面、EJB方面,并记录所有任务的开始时间和结束时间,以便后面计算任务的响应时间,直到该事务结束。
每条事务记录都是由一个HttpServlet任务开始,继而和后续访问的各个任务组成一颗事务树,该过程采用栈实现,具体流程如图4所示。
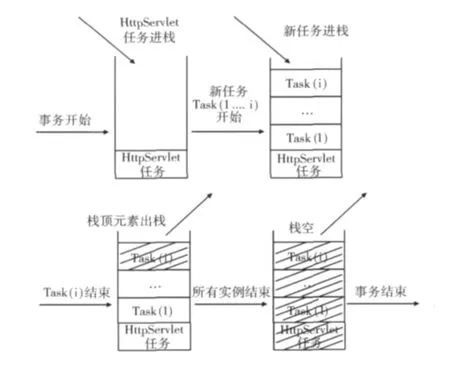
图4 用栈实现事务树的过程
图4中,首先捕获到一个HttpServlet的任务,该任务的实例进栈,并且在该HttpServlet中的请求执行完之前将捕获到的所有任务进栈,如果其中某个任务结束则出栈,并记录下来,直到该HttpServlet任务结束。该过程的伪代码如图5所示。

图5 织入
(2)用户行为监控是为了收集用户的访问路径,记录每一条session的访问流程,用户执行图是一个有限状态机图,下一个请求根据上一个请求的变化而变化,所以需要记录session所有节点的状态和时间,和轨迹监控一样也是采用方面插入的方式实现,捕获访问到的所有HttpServlet页面,session号相同的即为同一个session上的节点。
(3)CPU利用率监控主要用于监控CPU使用情况。资源需求是一个组件执行一次所需要消耗的物理资源量,比如CPU周期或占用的CPU时间等。资源需求描述了处理一次用户请求所需要的资源量,是所有性能模型建模过程中都需要给定的一个关键参数。由于事务型应用每次请求处理所使用的CPU时间极短,因此对方法使用的时间戳精密度要求很高。该系统使用Sigar包实现了CPU资源的监控。
3.2 日志文件分析
用户行为是难以预测的,它受外界环境和信息的影响,比如在一个电子商城中,当出现促销活动时,用户行为很可能从浏览型变为购物型。所以需要收集较长时间的session数据才能提取出用户行为,而日志文件的增长速度迅速,则提取用户行为首先面临的是大数据的处理。而收集到的原始数据又比较杂乱,所以要先对数据进行分类、排序、整理,然后再统计、计算、提取所需的数据,最后将服务的执行图转化为LQN模型。
在建立LQN模型的整个过程中,主要存在如下几个问题:
(1)对3种日志文件进行排序时,日志量非常大,据微软和facebook的技术报告,日志文件增长的速度大概是1-10MB/s[9],在我们的实验中,如果并发用户设置为40,收集一天,在shopping模式下收集到的数据大小为8016M,browsing模式下为5856M,ordering模式下为1387.2M。这些日志文件不仅数据大,而且分布在不同的机器上,因而无法直接分析日志数据,需要分布式日志分析算法的支持,比如MapReduce。但问题是,如果将数据简单的分成几个块单独进行处理,则有可能导致一个用户的执行轨迹被分到了几个块中,最后得到的分析结果很难合并,比如:一条session记录如果被分到不同的块中,则在CBMG统计时无法判断请求的序列。
(2)进行轨迹分析时,节点之间的调用关系可以用树来表示,但是树合并时,合并的结果不一定和实际情况一致;
(3)构造LQN模型时,首先要计算服务时间,CPU资源服务时间不仅很难在实际运行环境中监测出来,而且还会随着软硬件环境的变化而变化,而传统的基于回归分析的方法又难以适用于这种动态变化环境,因此需要采用其它的可监测数据动态的估测服务时间,以适应运行环境的变化。
针对上述可能出现的问题,本文采用如下解决方案:
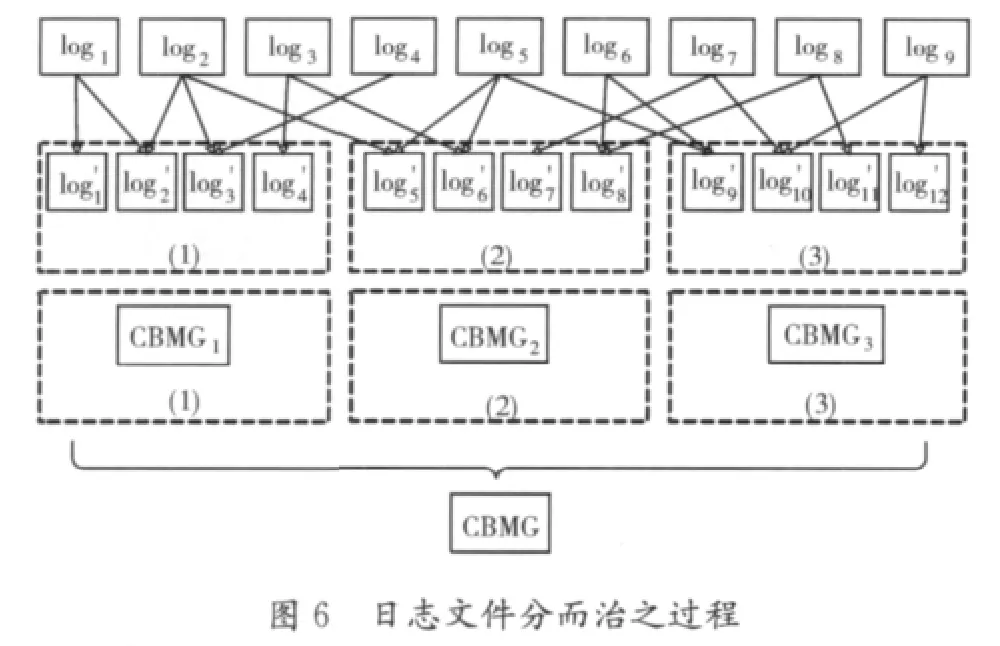
(1)对于大数据的处理,我们采用分而治之的方式,即先将数据分成几个小数据块,然后对每个小数据块进行分析整理,最后将分析的结果合并。分块时为了避免一个用户的轨迹被划分到不同的数据块中,本文采用滑动窗口取模的分块方法。
由于日志文件的大小是确定的,所以可以确定所需分成的块数,然后从session的ID号中按照窗口长度取出相应数字,再按分块的数量取模将轨迹的日志记录映射到相应的块中。如果一次遍历之后,某个分块的大小超过了所规定块的最大值,滑动窗口移动一位,重复上述过程,直到每个分块大小都小于阈值或者窗口无法滑动,最后对分块进行组合,使组合后的分块尽可能地接近于阈值。
各个数据块中计算出各自的分析结果后,合并结果。由于每个transaction数据块分析后得到一颗调用树,所以结果合并的算法同构造调用树的算法一样,都是树的合并。而每个session数据块分析后得到的CBMG存储的是访问次数,只有在结果合并时计算出的CBMG才是概率。
图6是以session文件为例,显示处理流程,首先将log1到log9这9个日志文件分成3部分,然后单独进行分析,CBMG1到CBMG3是各自的分析结果,最后将各CBMG合并为一个。其伪代码如图7所示。

(2)轨迹分析的最终目的是为了构造执行图。执行图表示的是系统运行时的整体结构图,本文关注的是如何从离散的执行轨迹中复原出整个应用执行图。分类排序后的每一个Transaction文件存放的是同一个事务的不同执行路径,所以构造执行图时每读入一个文件表示有一个事务开始,而每一条记录都可以解析为一条调用链,将一个文件里面的所有调用链合并成一棵调用树即为一棵事务树。但是在合成事务树,如果将不对等的节点也进行了合并就会导致结构上的不一致,如图8所示。
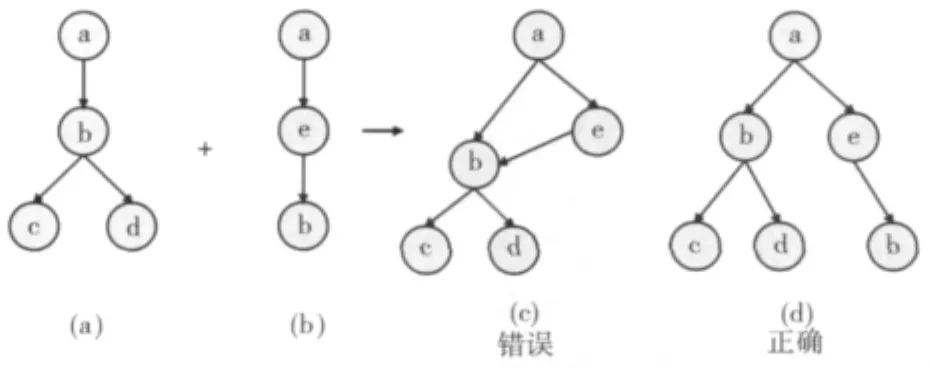
图8 调用链合并过程
图8中图(a)为一棵已有的调用树,图(b)为一条新的调用链,将图(b)合并到图(a)中时,如果合并成图(c),则会出现并不存在的执行轨迹,如a->e->b->c。不一致的原因就在于调用关系a->b与e->b中的节点b并不对等,如果直接进行合并,则会出现上述实际不存在的路径。
将一条轨迹记录解析为调用链时采用的是递归算法。构造事务树时,是不断地将新解析出的调用链合并到已有的调用链中,直到该类型的transaction记录读完为止,采用树的深度递归算法实现。
(3)本系统使用Kalman滤波的方法估算服务时间,Kalman滤波算法是一种最优化回归数据处理算法,它可以通过过滤和逐步修正的方法提高服务时间估算精度。本文首先将不可观测状态x建模为包含N个入口的服务时间的N维向量表示k时刻各入口的平均服务时间,然后,根据可观测得到的总CPU利用率zk进行建模,等式为其中t为各服务的吞吐率,vk为测量误差。所以zk可表示为:zk=HXk+vk,H可以定义为:Hk=[t1t2......tn]。
Kalman算法在每个时间片结束时进行服务时间的迭代评估,初始值包括状态初始值^x0以及初始的误差协方差矩阵P0迭代过程如下:
(1)更新X的状态:=。
(2)更新协方差矩阵:=PK-1+QK。
(3)计算Kalman增益:KK=(+RK)-1。
(4)修正x的状态:=+KK(ZK-HK)。
(5)修正协方差矩阵PK:PK=(I-KKHK)。
迭代过程中,初始值设置为k=0时刻的响应时间乘以CPU空闲率,对角矩阵P0的初始值设置为P0=diag(,,…,),QK表示每一次迭代中 X 变化的协方差矩阵,设置为对角矩阵,对角线元素为迭代过程中 X变化的最大值的平方Qk=diag(ξ1,ξ2,...ξn),其中,RK为测量值的误差,即总CPU利用率的测量误差,可忽略。
4 实验验证
本系统以TPC-W为例,设计了基于会话和基于事务的模型,TPC-W是一个模仿在线商城的企业级应用系统,具体实验对象为Bench4Q,它是中国科学院软件研究所软件工程技术中心开发的遵循TPC-W规范的一套面向多层架构的企业级标准测试基准套件,图9给出了本实验系统的拓扑结构,表1为软硬件环境。
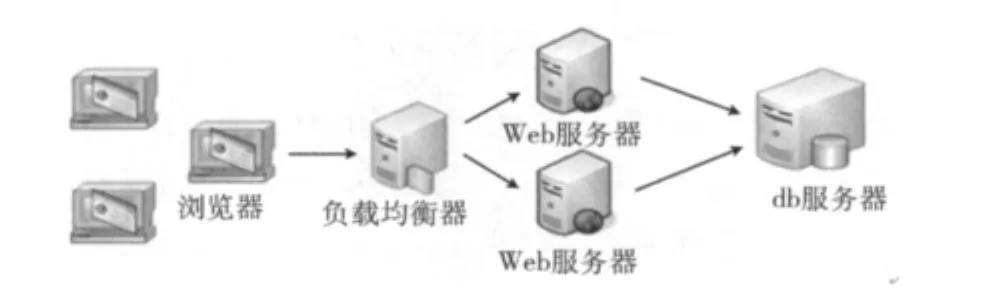
图9 TPC-W实验架构

表1 软硬件环境
在实验过程中,我们将轨迹监控和CPU监控部分部署到应用服务器中,CPU监控部分部署到数据库服务器中,控制部分部署到中心节点服务器中,启动所有服务器,负载生成器产生负载。
4.1 实验1日志文件的运行结果
首先收集一段时间的日志文件,实验操作步骤如下:①打开浏览器,进入中心控制部分的首页,填入应用服务器和数据库服务器的URL地址,启动监控;②一个小时后,停止监控;③配置好日志文件分析参数后然后开始分析;运行结果如图10所示。

图10 运行结果
图10中,在Transaction的子tab页面中给出了Web服务器和数据库的吞吐率、响应时间等性能指标,在Session的子tab页面中给出了并发session数和session长度等数据,在CPU的子tab页面中给出了Web服务器和数据库服务器的平均利用率。从CPU的利用率上我们可以看到Web和数据库服务器的资源利用率的走势,从而可以判断出应用服务器在该负载压力下是否已经达到了瓶颈状态。
4.2 实验2预测结果
实验2是本系统的核心所在,其目的是根据建立的预测模型,给出不同负载下的预测值,包括吞吐率、CPU利用率、响应时间,同时计算出误差值。图11~图13是以图形化的方式展示预测出的吞吐率,包括3种模式shopping、browsing、ordering,折线点为圆形的表示实测值,折线点为正方形表示预测值,其误差不超过10%。
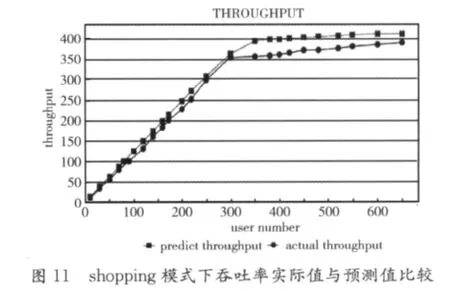
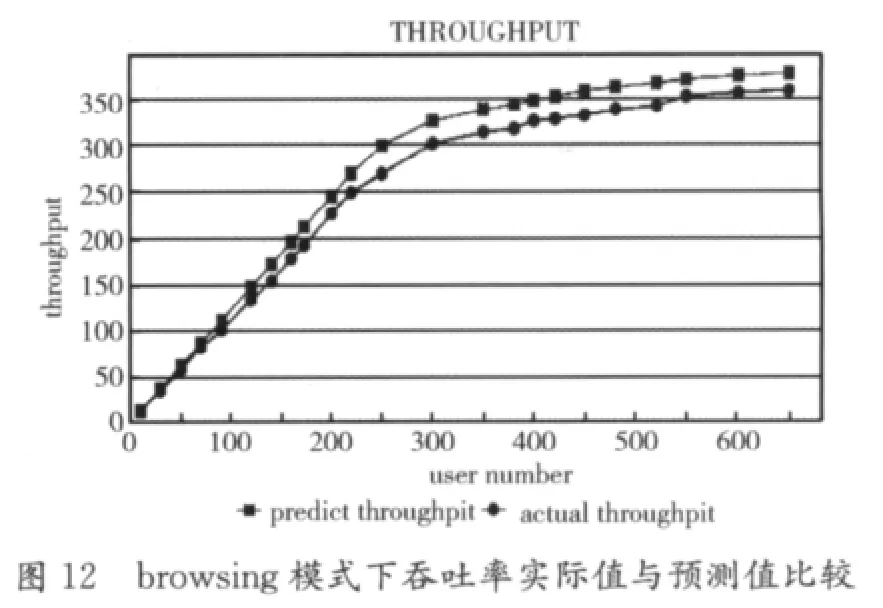
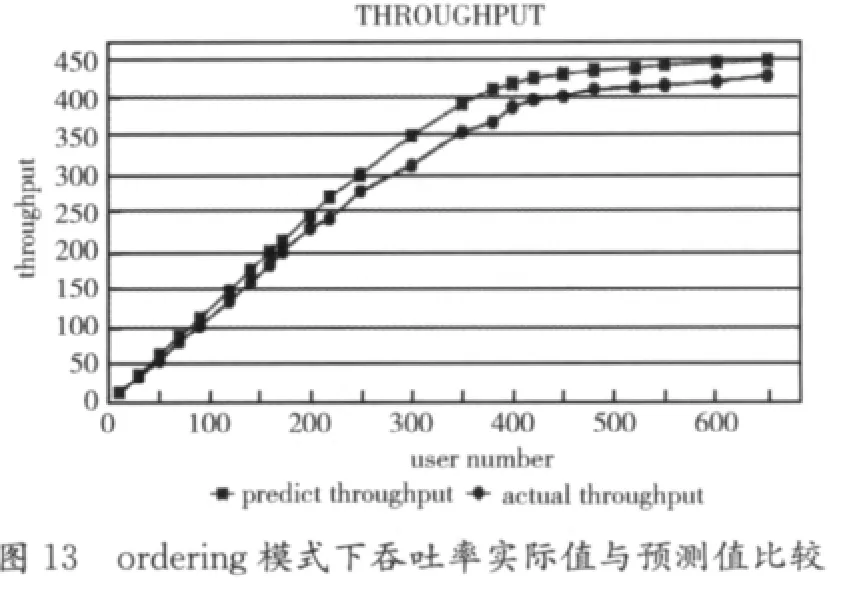
x轴表示负载量,y轴表示吞吐率,从图11~图13中可以看出当负载达到一定值时吞吐率不再上升,说明系统资源利用率达到临界状态。
5 相关工作
William和Smith首先提出了一种基于软件性能工程的方法[10]将性能分析引入软件开发过程中。他们使用UML模型描述软件的架构,重点研究了如何将UML模型转化为执行图。虽然这类方法降低了性能模型构造的难度,但是正确的获得模型所需要的参数(如服务时间和执行图中各路径的权重)仍是一个难题,使得这些方法很难适应于在线系统。Samuel Kounev提出一种基于排队Petri网的方法[11]分析集群环境下的性能。但该方法针对的是服务器一级的性能,因而建模和服务时间的获取都相对简单。但是该方法对软件组件一级的性能却无法获知,也很难分析负载的请求混合比例对系统性能造成的影响。
Cherkasova提出了一种基于服务访问概率进行负载建模的方法[8,12]。作者将到达模式假定为封闭的,所以将用户抽象为并发请求,然后再分析单个请求访问不同服务的概率。但对于开放模式,这种假设很难成立。因为系统并发用户量并不是固定的,会受到用户到达率,访问模式和系统响应的综合影响,所以很难正确刻画出并发请求数的变化以及各个时刻不同服务被访问的概率。而本文则将到达模式与访问模式分离,使其可以独立建模,从而可以更准确的刻画负载的特征。Hrischuk提出了一种基于轨迹监测自动构造性能模型的方法,作者主要关注于分布式软件的轨迹监测技术,解决了不同消息类型的监测方法,而本文考虑的是如何从历史轨迹中统计出执行图的总体特征。
Woodside等人提出了一种从软件设计环境中自动生成LQN模型的方法。其主要目的是直接为设计生产原型代码,然后通过工具监测出各个模块的软件结构,捕获各个组件的资源消耗。但因为该方法依赖于开发阶段的数据和工具,因而并不能适应于运行态的软件,特别是服务时间和负载在设计时是很难预知的。
Fabian提出了一种自动提取性能模型的方法[13],该方法采用一种基于配置的方法,预先定义需要关注的组件,然后利用CPU利用率估算实际执行时间与等待时间的比例,从而获得服务时间,但由于Web系统采用并发执行的模式,服务的执行和等待时间一方面要受到组件自身执行时间和路径上其它组件的影响,一方面还要受到并发规模的影响,所以很难估算在线系统的服务时间。Rolia与Cherkasova分别使用多元回归的方法估算服务时间[8,12],但这类方法依赖于长时间,高质量的监测样本集,而服务时间又是一个易受软硬件环境影响的属性,样本周期跨度过大,则很可能造成部分样本的失效,使样本收集和有效性验证的难度增大。更重要的是服务时间必定大于0。因此需要采用非负的回归计算方法,而这类方法倾向于将大量服务时间置为0,造成估算结果的严重失真。本文则采用了Kalman滤波的方法,该方法最大的特点是基于离散的时间点,近似最优的估算不可观测的属性,避免了收集长时间样本的问题,提高了估算精度。
6 结束语
PaaS是目前平台技术发展的趋势,然而当前的技术主要针对功能性的保障,对于非功能的保障机制仍有欠缺。为了在开放和动态的环境下通过提高资源利用率保障系统的性能,本文主要关注于动态性能建模的问题,利用记录的日志文件信息,在系统运行的情况下,自动构造出性能模型。本文的主要贡献在于:①给出了一种基于面向方面技术的应用行为监测方法,解决了平台在运行时难以获取应用内部细节的问题;②提出了一种基于滑动窗口取模的数据分块方法,解决了大量分布式日志处理的问题;③给出了日志分析算法,解决了从离散的日志信息中,提取完整性能模型的问题。
[1]Marin Litoiu,Murray Woodside,Tao Zheng.Hierarchical model-based autonomic control of software systems[C]//NY,USA:DEAS,2005.
[2]Jerry Rolia.Supporting application quality of service in shared resource pools[J].Communications of THEACM,2006.
[3] Heiko Koziole.Performance evaluation of component-based software systems:A survey[J].Performance Evaluation,2010,67(8):634-658.
[4]Tauseef Israr,Murray Woodside,Greg Franks.Interaction tree algorithms to extract effective architecture and layered performance models from traces[J].The Journal of Systems and Software,2007,80(4):474-492.
[5]Abian Brosig,Samuel Kounev,Klaus Krogmann.Automated extraction of palladio component models from running enterprise Java applications[C]//Brussels,Belgium:On the workshop of 5th International ICST Conference on Performance Evaluation Methodologies and Tools,2009.
[6]Zhang Q,Cherkasova L,Mathews G,et al.R-capriccio:A capacity planning and anomaly detection tool for enterprise services with live workloads[C]//Springer.Berlin:Proceeding of International Middleware Conference,2007.
[7]Qi Zhang,Ludmila Cherkasova,Ningfang Mi,et al.A regression-based analytic model for capacity planning of multi-tier applications[J].Journal of Cluster Computing,2008,11(3):197-211.
[8]Cherkasova L,Kivanc Ozonat.Automated anomaly detection and performance modeling of enterprise applications[J].ACM Transactions on Computer Systems,2009,27(3):6.
[9]Windows Azure and Facebook teams[R].Personal Communi-cations,2008.
[10]Smith C U,Williams L G.Performance solutions:A practical guide to creating responsive,scalable software[M].Addison Wesley,2002.
[11]Samuel Kounev,Performance Modeling.Evaluation of distributed component-based systems using queueing Petri Nets[J].IEEE Transactions on Software Engineering,2006,32(7):486-502.
[12]Zhang Q,Cherkasova L,Mathews G,et al.R-capriccio:A capacity planning and anomaly detection tool for enterprise services with live workloads[R].In Middleware,2007.
[13]Fabian Brosig,Samuel Kounev,Klaus Krogmann.Automated extraction of palladio component models from running enterprise java applications[C]//Brussels,Belgium:International ICST Conference on Performance Evaluation Methodologies and Tools,2009.
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
铁道通信信号(2019年9期)2019-11-25
网络安全和信息化(2019年8期)2019-08-28
思维与智慧·上半月(2018年9期)2018-09-22
现代装饰(2018年5期)2018-05-26
小学生(看图说画)(2017年6期)2017-11-06
中国三峡(2017年2期)2017-06-09
