
不规则网络拓扑结构下的多棵树路由算法研究
2013-11-30 05:01:18宋冠军韩江雪
计算机工程与设计 2013年1期
宋冠军,韩江雪
(1.华北计算技术研究所,北京100083;2.清华大学 软件学院,北京100084)
0 引 言
对于互联网络而言,她主要由下述4个部分组成:路由算法、流控技术、交换技术和拓扑结构。在上述四部分中,核心部分是路由算法。也就是说,影响性能的关键的因素在于如何给某一拓扑网络设计适合的路由算法,让其在进行消息传递时花费相对较少的时间。
当前已经有很多用于构造机群系统的交换式高速互联网,其中Myinet,Autonet,等都是已经成熟的几个。这些网络,一般采用不规则的拓扑结构和虫孔路由交换技术。然而由于不规则网络拓扑结构的复杂性和不可控性,网络中出现环路即通信重叠的可能性大大增加,进而网络中更加容易出现死锁现象。
Sancho,等[1]提出了一种基于深度优先搜索的多棵树路由算法,从而降低了传统breadthfirst路由算法的路由表数量,它的启发式up/down生成算法,大大提高了路由的效率。Puente,等[2]提出了一种基于不规则网络以伪哈密顿周期为基础的自适应路由机制,明显削减了传统的up*/down*路由算法的额外开销,有效地避免死锁的出现,但也同时造成了路由路径的增长。A.Jouraku的文章[3]提出的一种自适应路由算法,使数据包分布的尽可能均衡。Levitin,Karpovsky,和 Mustafa[4]中提出的新算法通过保证最小的路由回路被禁止以消除思索和维护图的连通性。
因此,如何提高系统性能并避免死锁,是本论文主要讨论与解决的问题,也是本研究的核心贡献所在。up*/down*路由现在已被广泛使用,在包括上文提及的多篇论文[5-11]中分别对NOWs系统路由进行了不同角度的阐述,但是这些路由方法存在很多问题,比如自适应性差,根节点的瓶颈等问题。在此之上,本文将提出一种新的路由机制即多根节点自适应路由,来在一定程度上弥补原始up*/down*路由方式的不足。
1 不规则网络拓扑结构下的算法介绍
1.1 NOWS体系的构成
本文的研究对象是不规则网络的路由新机制。其基本的体系结构如图1所示。
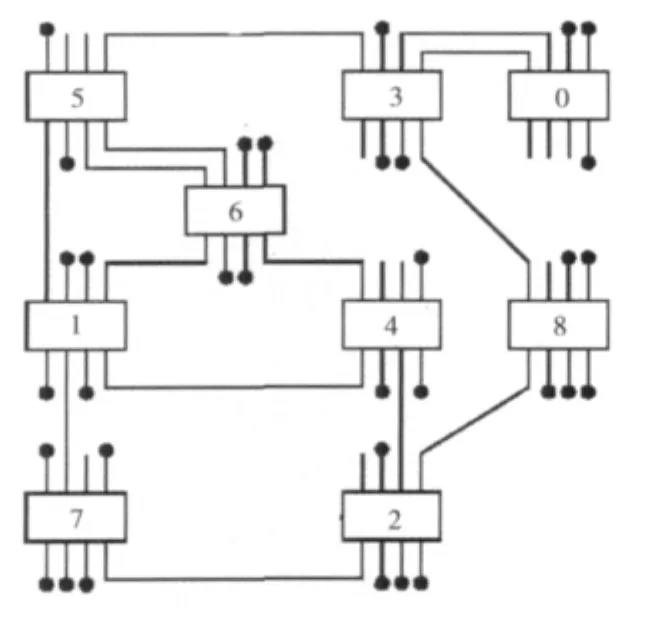
图1 基于开关的不规则互联网络
基于开关的不规则互连网络主要由开关(switch),处理单元(processing elements)和双向物理链路(bidirectional link)组成。
图1中可以看到,0-8号是开关(Switch),每个开关上有若干个端口(此图为8个端口)。每个端口可以连接其他开关的端口,也可以连接本地处理单元(processing elements,PE),还可以空闲不接。
本文以不规则开关网络为研究对象,所提出的算法可以应用到所有不规则网络。
一个互连网络可以用网络拓扑、交换机制、流控机制和路由算法来描述。由于课题本身已经限制了研究的对象是不规则的拓扑网络结构,因此主要着重于对交换机制、流控机制和路由算法做出更有效率的改进。
1.2 up*/down*路由算法
网络的路由算法也分为直接网络的路由和间接网络的路由,规则网络的路由和不规则网络的路由。
本文这里滤去与核心问题不相关的部分,集中介绍不规则间接网络的路由研究情况。
规则网络中由于拓扑结构的可控制性,使得一些死锁问题变得简单。然而,在网络拓扑不规则的前提下,路由算法的设计就变得十分困难,尤其是如何解决死锁避免就更困难了。现有的路由算法只是解决了网络的死锁问题,然而与此同时在网络的其他特性上就无法兼得。这里主要介绍经典的up*/down*路由算法。
up*/down*路由算法是一种禁止拐弯模型,在DEC Autonet网络的路由算法中首次被提出。简单来说,up*/down*路由算法的目的是给每条链路标注上方向(up)或下方向(down),将网络改造成一个无回路的有向图,最后禁止消息由下方向拐向上方向,以此避免了路由算法中的死锁。
下面为up*/down*算法的步骤:
在拓扑网络中选择一个根节点(通常为节点ID最小的那个节点),以该节点为根,生成整个拓扑网络的宽度优先搜索树(BFS树);
指定每条物理链路的方向。对于链路的上方向(up)定义如下:当链路连接的两个节点处在BFS中深度不同的两层时,从层数较深的节点指向层数较浅的节点的方向为上;当链路连接的两个节点处在BFS中深度相同的两层时,从ID较大的节点指向ID较小的节点的方向为上。和上述上方向(up)相反的方向即为下方向(down);
计算路由表。对于每个节点计算它与其他各个节点的最短路径,但是为了避免死锁,路径中只允许出现从上到上(up to up)、从下到下(down to down)和从上到下(up to down)3种拐弯,从下到上(down to up)是非法的。通过屏蔽环路形成条件中的一个,我们能够确保最后生成的路由路径不存在回路依赖关系,也就避免了死锁。
图2显示了一个包含9个结点的网络图G(V,E),图3(图中箭头方向为up方向)所对应的广度优先搜索(BFS)生成树T(G)以及该生成树各个边上方向的指定情况。需要注意的一点是对于每条边的up方向通道,都有一条反向的down方向的通道组成双向连接,考虑到图示效果需清晰的原则,该图中未标出down方向。
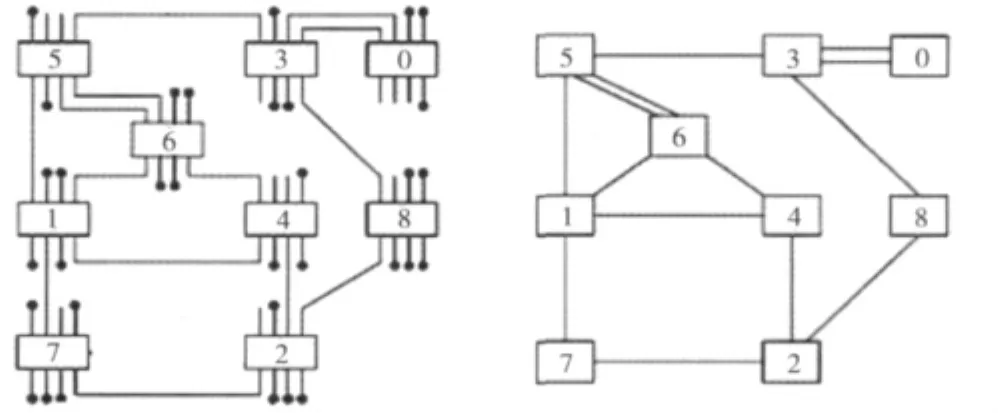
图2 基于开关的不规则拓扑及其通道相关
up*/down*算法的优势在于全部结点的硬件构造与软件设计简易,与此同时该算法还提供了一定的网络自适应性。
但是,up*/down*算法也存在许多缺点。比如:
首先,由于路由算法背身的算法原理,导致在很多情况下所选的路径并不是最短路径,这样一来,消息的传输延时明显上升,严重影响网络性能。
第二,由于树本身的结构使然,网络拥塞容易趋向于根结点附近,同时较难疏散,这就是的网络关键路径传输效率大幅降低,直接影响了网络的吞吐率。
最后,由于算法在高层结点处即算法对应生成树的叶结点处屏蔽的转弯数较多,使得整个网络的通道利用率出现了严重的不平衡,降低了网络的性能。并且随着网络规模的扩大,上述问题变得尤其凸显。
2 多棵树路由算法
在上节中,介绍了不规则网络拓扑中的一种无死锁算法up*/down*算法。但是该算法有许多显而易见的问题,主要有以下三点问题最为严重:
第一网络中单根节点的路由会使得网络的负载分布不平衡,进而使得根节点成为网络的瓶颈;第二由于拐弯的限制使得高层节点附近通道利用率增加;第三网络中路由的平均距离明显增加。这是我们研究多棵树路由算法的直接动机。
那么我们所提出的新路由算法就应该具有以下长处:新路由算法要做到平衡各个通道之间的负载,不能出现网络的负载大部分集中在少部分通道的情况;新路由算法要尽量降低网络中链路的长度,同时还要兼顾避免或减少死锁发生的特性;若新路由算法可能包含死锁,那么应含有解决死锁的流控机制。
多棵树路由算法就是将以上三点作为研发的最终目的而提出的一种新的路由算法。
本文所提出的多棵树路由算法由三部分组成,第一部分是路由表的生成规则,也就是路径的生成算法;第二部分是多棵树路由采用的交换技术;第三部分是多棵树路由采用的流控机制,其中包括平时的流控方式和产生死锁后用于死锁恢复的特殊流控方式。
2.1 路由表的生成算法
我们将图2所对应的不规则网络拓扑适当简化,去掉双链路,将之抽象后得到如图4所示的模拟拓扑结构。
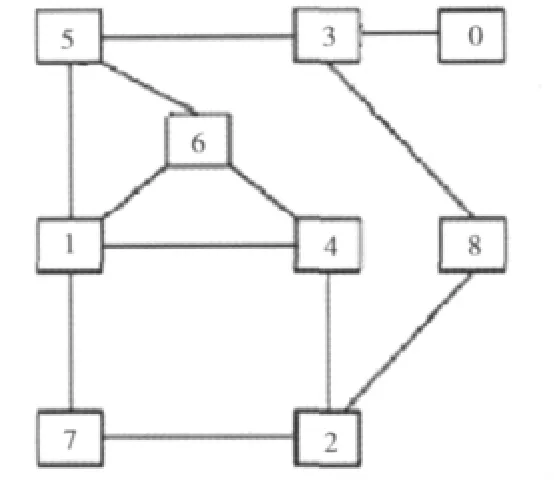
图4 原始物理模型抽象简化后的模拟拓扑结构
根据图4的模拟拓扑结构,我们分别选择节点1或者节点8为根节点,按照up*/down*规则产生的路由路径是不同的,在总共的72条路径中,有17条发生了变化,其中以节点8为根节点产生的新路径比原路径短的有四条,新路径比原路径长的同样是四条,而新路径和原路径一样长的有九条。若我们将原来的节点1称为主根,节点8称为辅助根,在辅助根生成的新路由表中选择那些比原有路由表短的路径代替主根生成的路由表,那么就可以起到缩减路由表中链路的平均长度、平衡主根节点附近通道负载的作用。我们将这种在原有主根基础上增加辅助根的路由算法称为多棵树路由算法。
该算法的具体定义如下:
算法1:createMTRRouter(net,n)
功能:多棵树路由表生成算法
输入:用无向图表示的不规则拓扑网络net,根节点数量n
输出:路由表routerTable
过程:
1.随机选定一个节点r作为主根节点;
2.net=setLevel(net,r);
3.routerTable=findRoute(net);
4.for(k=1;k<n;k++ )
5.随机选定一个节点r’作为副根节点;
6.net=setLevel(net,r’);
7.routerTable’=findRoute(net);
8.for(i=0;i<net中的节点数 ;i++)
9.for(j=0;j<net中的节点数 ;j++)
10.if(routerTable[i][j].length> router-Table’[i][j].length)
11.将routerTable[i][j]的路径替换成routerTable’[i][j]的路径;
12.end if
13.end for
14.end for
15.end for
16.返回routerTable;
算法2:setLevel(net,root)
功能:对一个不规则拓扑网络中的链路设定方向。
输入:链路未分配方向的拓扑网络net,根节点的ID root。
输出:链路已分配方向的拓扑网络net。
过程:
1.根据root节点,用BFS算法计算所有节点的深度;
2.for(net的第一条链路k->最后一条链路)
3.if(k的源节点深度 >k的目的节点深度 )
4.k的方向附为0; //up
5.end if
6.if(k的源节点深度 <k的目的节点深度 )
7.k的方向附为1; //down
8.end if
9.if(k的源节点深度==k的目的节点深度)
10.if(k的源节点ID> k的目的节点ID)
11.k的方向附为0; //up
12.end if
13.if(k的源节点ID< k的目的节点ID)
14.k的方向附为1; //down
15.end if
16.end if
17.end for
18.返回net;
算法3:findRoute(net)
功能:对一个拓扑网络建立路由表。
输入:链路已分配方向的拓扑网络net。
输出:路由表routerTable。
过程:
1.for(i=0;i<net的节点数 ;i++ )
2.for(j=0;j<net的节点数 ;j++ )
3.visit[节点j]=false; //访问记录
4.end for
5.for(节点i的第一条链路link-> 节点i的最后一条链路)
6.if(visit[link的目的节点]==false)
7.visit[link的目的节点]=true;
8.nodeQueue.addLast(link的目的节点);
9.directionQueue.addLast(link的方向);
10.linkQueue.addLast(new queue(link));
11.routerTable[i][link的目的节点].add(link);
12.end if
13.end for
14.while(nodeQueue不为空)
15.node=nodeQueue.removeFirst;
16.lastDirection=directionQueue.removeFirst;
17.lastRoute=linkQueue.removeFirst;
18.for(节点node的第一条链路link-> 节点i的最后一条链路)
19.if(visit[link的目的节点]==false)
20.if(link的方向 >=lastDirection)
21.//只允许路径中出现0->0,0->1,1->1的拐弯,屏蔽1->0的拐弯
22.visit[link的目的节点]=true;
23.nodeQueue.addLast(link的目的节点);
24.directionQueue.addLast(link的方向);
25.newRoute=lastRoute.copy;
26.newRoute.addLast(link);
27.routerTable[i][link的目的节点].add(newRoute);
28.linkQueue.addLast(newRoute);
29.end if
30.end if
31.end for
32.end while
33.end for
34.返回routerTable;
通过该算法,我们就得到了用多棵树算法计算得到的路由表。但是由于将辅助根的路由表的一部分替换掉了主根生成的路由表,因此up*/down*规则产生的无死锁特性将不复存在。因此,我们需要在流控方式上采取与up*/down*算法不同的,带有死锁恢复功能的特殊流控方式。
2.2 多棵树路由的流控机制
我们知道两种解决死锁问题的流控机制,虚通道和冒泡通道。通过研究两种流控方式我们发现,以一条物理通道划分为两条虚通道为例,虚通道流控机制在没有死锁发生时,只有一条虚拟通道被利用,物理通道的利用率很低,在死锁发生后可以通过第二条虚拟通道有效的解决死锁问题;冒泡通道的流控机制只拿出一个flit的buffer,即冒泡通道,来解决死锁问题,在死锁未发生时通道用几乎全部的buffer来运送消息,但是一旦发生死锁,系统就会选择一条消息,用冒泡通道运送该消息,所以当死锁发生时,每次只能运送一条消息,其他消息都要停滞。因此,虚通道技术在死锁发生不频繁时效率较低,而死锁发生时效率较高;与之相反,冒泡通道在死锁未发生时效率较高,但死锁发生频繁时效率较低。
我们发现,在多棵树算法选用一个辅助根时,实际上路由表只有四条链路选择了比原来只有主根的时候更短的路由路径,因此,表中的绝大部分路径还是满足原来的up*/down*算法提供的无死锁特征的。那么可以想见,在系统实际运行、系统负载不高的情况下,一定是处于正常状态的时间更长,而只有少数时间处在死锁状态。因此如果我们选择虚通道的流控方式,等于在绝大部分时间内都处于效率不高的正常状态。因此,我们在多棵树路由算法中,选择冒泡通道作为系统的特殊流控机制。
2.3 多棵树路由的交换机制
我们知道两种最为常见的交换方式,虚跨步交换和虫孔交换。两种交换方式的主要区别在于,虚跨步交换在消息发生堵塞时依然转移报文,因此需要每个通道的buffer至少要能够缓冲整个消息;而虫孔交换在消息发生堵塞时,就地缓冲报文,不再向前推进,所以对通道的buffer长度没有要求,在buffer较小的情况下依然适用(理论上只有一个flit就够)。但是一旦拉得很长的消息被就地缓冲,势必会引起更多消息的堵塞,造成更多的死锁。
在虫孔交换和虚通道流控被广泛使用的现在,研究人员会在不规则网络中考虑将这两种方式联合使用。然而,西班牙瓦伦西亚大学的J.Duato先生等人在中指出在不规则网络中虫孔交换并不是最好的选择,通过测试比较发现:
(1)对于虫孔交换缓冲空间的大小限制了线路的长度,然而虚跨步交换就不会出现这样的问题。
(2)由于在报文阻塞时虫孔交换就地缓冲报文,而虚跨步转移报文,所以虚跨步方式使得路由具有了更大的自适应性。
(3)在简单的开关架构之下,虚跨步交换表现出与虫孔交换相同的性能,在长报文的情况下,表现更为出色。
网络的链路的不确定性从而使得网络延时和缓冲及通道等资源难以确定。该论文指出,在不规则拓扑网络中虚跨步交换技术是最合理的选择。在通道的buffer不是非常珍惜的情况下,采取虚跨步交换在死锁发生是也会有更好的表现。
3 算法性能模拟与比较
本实验是通过模拟器仿真真实的机群环境,并通过调整模拟器的输入参数来达到模拟不同的硬件条件下,多棵树路由算法的表现。本文用于对照实验的是经典的up*/down*路由算法,选取该算法作为对照是因为该算法是不规则拓扑网络常用的路由算法之一,因此对照试验的结果更有参考价值和意义。
我们进行了多种角度的实验,因此在每条实验结果前都会有关于该实验条件的详细说明。所有图表中的数据都是在相同参数下反复试验20次,以取平均值的方式得出的统计结果,因此结果的偶然性和随机性很低,参考价值更大。
实验中输入参数的详细说明如下:
·nodeNumber:网络中的节点数,也就是网络中的处理单元/开关数量;
·nodeBuffer:网络中一条通道的缓冲区大小;
·degree:节点的出入度限制;
·totalCycle:系统运行的总周期数;
·messageLength:系统生成消息时的长度;
·messagePerCycle:系统每隔多少周期注入一条消息;
·rootNumber:多棵树算法中根的总数;
·Continue:系统在执行完totalCycle之后是否继续执行。
实验结果反馈的输出参数如下:
·AverageLength:平均长度,即路由表中所有路径的平均长度;
·ArrivalPercentage:到达率,即totalCycle执行完毕时送到的消息占发送出的所有消息的百分比;
·Traffic-R:送达的消息总长度(以Flit为单位)/(总周期数*网络节点数),衡量网络能力的重要参数之一;
·AddCycles:附加周期数,即totalCycle执行完后,系统又附加了多少周期才将系统中所有未送达的消息送达。
3.1 路由表平均路径长度的比较
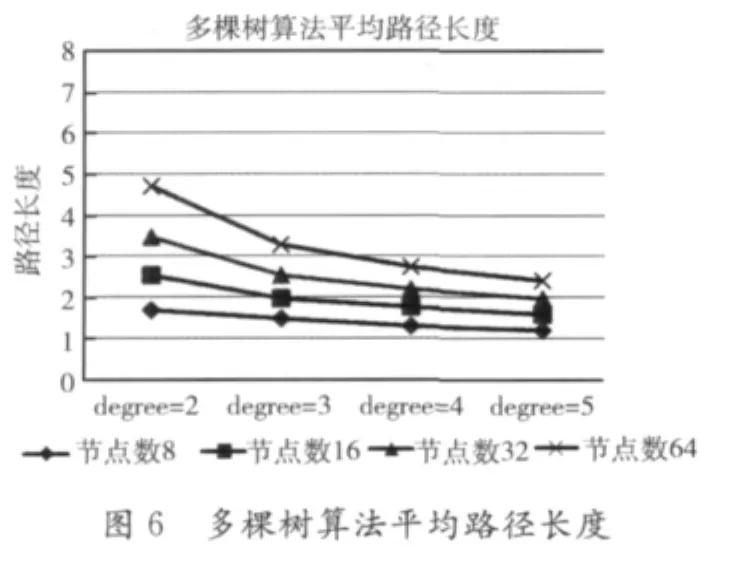
使用多棵树算法解决了路由表中路径过长的问题,我们测试时分别对节点数8、16、32、64,及degree=2、3、4、5的情况下对两种算法生成的路由表平均长度进行比较,其中多棵树算法的rootNumber设为4。结果如图5及图6所示。
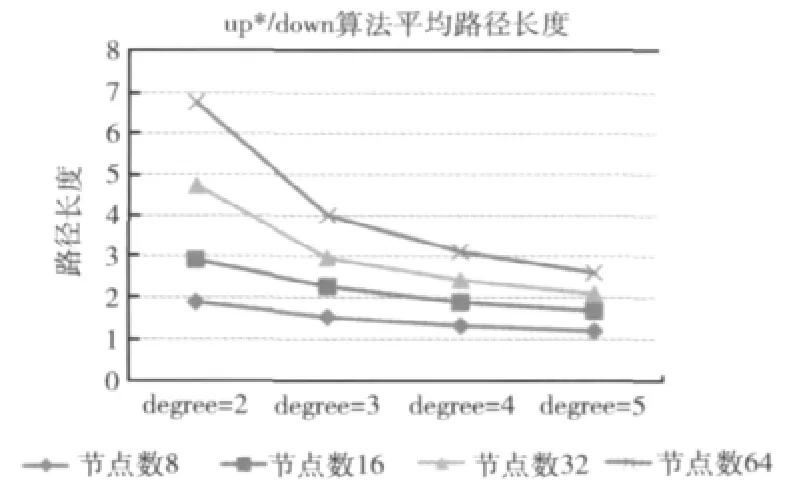
图5 up*/down*算法平均路径长度
从两图对比我们能够明显看出,多棵树算法的平均路径长度比相同条件下的up*/down*算法减少明显,特别是在degree=2的情况下,节点数为64的网络的平均路径由6.77827下降到4.69940,下降幅度高达30.6%。这说明多棵树路由算法对降低路由平均路径由非常明显的效果。
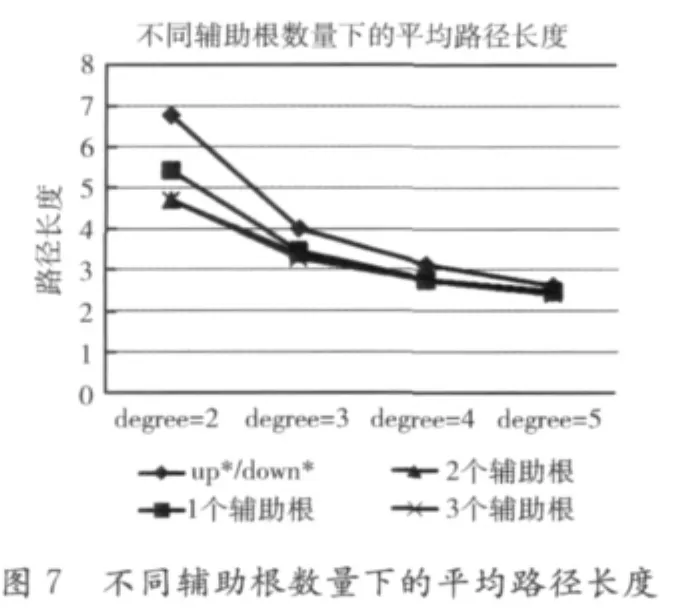
图7是一张逐渐增加辅助根节点,路径平均长度的变化图,节点数量固定在64个,从该图中可以看出,随着辅助根增加,路径平均长度不断减小,但辅助根数量从2增至3后,路径长度变化已很不明显,说明3个辅助根(root Number=4)是一个比较理想的极值。
3.2 在负载变化的网络中的性能比较
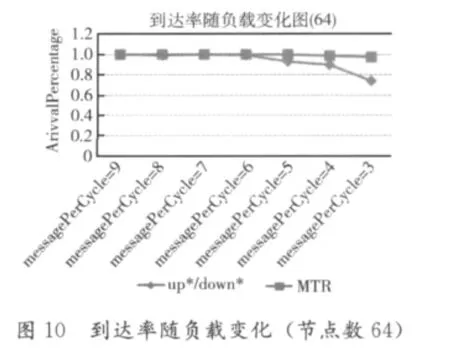
通过修改messagePerCycle参数的大小,我们可以任意修改消息注入的快慢。于是我们选择nodeNumber=64、nodeBuffer=32、degree=2、totalCycle=10000、message-Length=30作为不变量,来检查messagePerCycle从9(网络负载低)到3(网络负载极高)的变化过程中,up*/down*算法和多棵树(MTR)算法(rootNumber=4)的各项指标差异,实验结果如图8~图10所示。
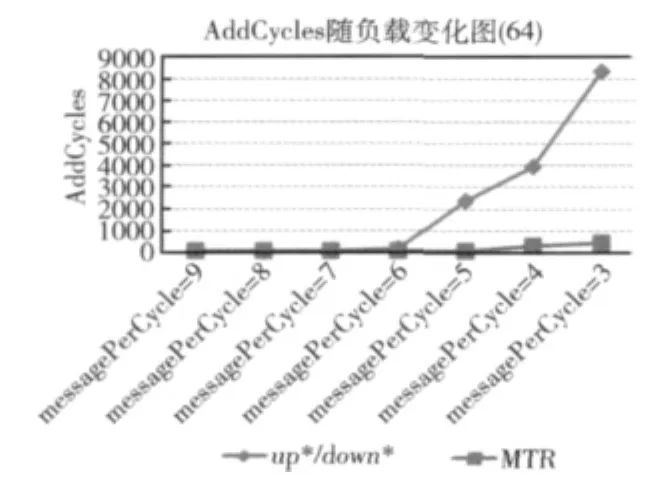
图8 AddCycles随负载变化(节点数64)
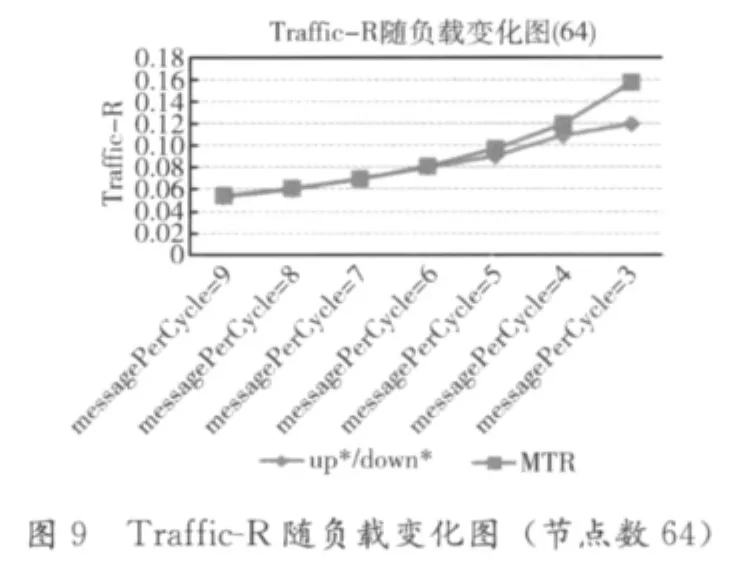
我们可以看出,多棵树算法在负载由低到高的过程中,性能发挥非常稳定。图8中,当messagePerCycle从6变为5时,up*/down*算法的附加周期出现了一个突变,随后则一路飙升;多棵树路由算法的附加周期的增长却十分缓慢,证明多棵树路由算法依然能在短时间内将系统囤积的消息消耗掉。图9也很好的证明了这一点,在高负载条件下,多棵树算法的运载能力开始大幅度领先于up*/down*算法。图10显示了随着系统的负载增大,消息在指定的周期内被送达目的节点的概率。多棵树算法即使在系统负载很大的情况下,仍然能够保持接近1的送达率;而up*/down*算法的送达率却在高负载条件下出现了明显的下滑。
为了证明多棵树算法在不同网络规模下的表现,我们又对节点数为32的网络进行了同样的实验,实验结果证明32个节点产生的结果基本与64节点下的实验结果相类似。
64节点和32节点均属于大规模网络,那么为了验证在小型网络(8节点、16节点)中两种算法的效率如何,我们又进行了两轮实验,第一轮针对16节点的网络(nodeNumber=16、nodeBuffer=32、degree=2、totalCycle=10000、messageLength=30),二轮针对8节点网络的实验(nodeNumber=8、nodeBuffer=32、degree=2、totalCycle=10000、messageLength=30),8节点的小规模网络的实验结果与16节点时类似,多棵树的算法在高负载条件下的运载能力没有明显高于up*/down*算法;多棵树算法的送达率在高负载情况下也有了明显的下降。实验结果显示出多棵树算法在网络规模变小时出现了效率的下滑,究其原因,在于多棵树算法提高网络路由性能的主要途径是降低了路由表路径的平均长度,但当网络规模变小时,up*/down*规则生成的路径的平均长度本身就会减小,多棵树算法的提升空间非常有限,而且由于多棵树是有死锁的算法,在平均路径小的网络中,死锁的产生会更加频繁,因此多棵树算法在死锁恢复上的开销时间将会比网络规模增大时更多。这两种因素结合起来就导致了在网络规模变小时,多棵树路由算法的效率出现了下降。
通过以上3个参数的验证,我们证明了多棵树算法在网络规模较大时存在很大优势:对于系统的负载情况的敏感度远远低于up*/down*算法,在任何种类的负载下都能发挥出稳定的性能和表现。但在网络规模较小时,多棵树算法由于自身局限性效率有所下降,但还是略高于up*/down*算法。
3.3 实验总结
多棵树算法在静态时的优越性。通过比较所生成路由表中路径的平均长度,我们发现多棵树算法在网络规模较大时能够有效地降低系统中路径的平均长度,降幅最大可达30%,避免了up*/down*算法中个别路径长度远大于最短路径长度的问题,但在网络规模较小时,平均路径长度的缩小量并不明显;
多棵树算法在动态时的优越性。通过比较负载增加时消息运送能力的变化,我们可以看出当网络规模较大时,多棵树算法对网络负载的适应能力很强,无论是低负载状态下还是高负载状态下,消息送达率都稳定维持在1左右,这是up*/down*算法所远远达不到的,同时up*/down*算法在高负载时消息的消化处理时间陡然增高,但多棵树算法依然平稳上升,且上升幅度只有up*/down*算法的5%,这说明多棵树算法很好的处理了up*/down*算法因为过于强调无死锁,而忽略了网络自适应能力的问题。但是当网络规模缩小时,由于路由表平均距离的缩小量有限,因此多棵树路由算法出现效率下降的情况,对负载的增大也变的更为敏感,同时在死锁恢复方面花了更多的时间开销。但对比发现,多棵树算法的效率还是要高于up*/down*算法。
4 结束语
本研究提出了一个针对不规则网络拓扑结构的新算法-多棵树路由算法,该算法大大降低了路由表的平均路径长度,平衡了网络中各个通道的利用率,同时能够及时有效的进行死锁恢复,解决了先前路由算法中通道负载集中、通道利用率低、路由表平均路径长度过长的问题。当网络规模较大时该算法表现了很强的自适应能力,和极高的效率;当网络规模较小时也能够有效地防止死锁的出现。尤其针对不规则网络该算法有很强的普适性。无论在静态特性还是动态特性上都确实体现出了其优秀的能力,达到了我们预期的效果。但在小规模网络时效率还有待进一步提升。
[1]Sancho J C,Robles A,Duato J.An effective methodology to improve the performance of the Up*/Down* routing algorithm[J].IEEE Trans on Parallel and Distributed Systems,2004,15(8):740-754.
[2]Puente V,Gregorio J A,Vallejo F,et al.Highperformance adaptive routing for networks with arbitrary topology[J].Journal of Systems Architecture,2006,52(6):345-358.
[3]Jouraku A,Koibuchi M,Amano H.An effective design of deadlock-free routing algorithms based 2Dturn model for irregular networks[J].IEEE Trans on Parallel and Distributed Systems,2007,18(3):320-333.
[4]Levitin L,Karpovsky K,Mustafa M.Minimal sets of turns for breaking cycles in graphs modeling networks[J].IEEE Trans Parallel and Distributed Systems,2010,21(9):1342-1953.
[5]Moraveiji R,Sarbazi-Azad H,Zomaya A Y.A general methodology for routing in irregular networks[C]//Proc 17th Euromicro Int Conf on Parallel,Distributed and Network-Based Processing,2009:155-160.
[6]Moraveiji R,Sarbazi-Azad H,Zomaya A Y.Multispanning tree zone-ordered label-based routing algorithms for irregular networks[J].IEEE Trans on Parallel and Distributed Systems,2011,22(5):817-832.
[7]Lysne O,Skeie T,Reiemo S,et al.Layered routing in irregular networks[J].IEEE Trans on Parallel and Distributed Systems,2006,17(1):51-65.
[8]Theiss I,Lysne O.FRoots:A fault-tolerant and topologyflexible routing technique[J].IEEE Trans on Parallel and Distributed Systems,2006,17(10):1136-1150.
[9]Akiya Jouraku.An effective design of deadlock-free routing algorithms based on 2Dturn model for irregular network[J].IEEE Transactions on Parallel and Distributed Systems,2007,18(3):320-333.
[10]Li Xiaoming,Fu Fangfa,Yang Chao,et al.A solution to irregular 2-D mesh topology network-on-chip[J].Energy Procedia,2011,13:888-895.
[11]Moraveji R,Sarbazi-Azad H,Zomaya A Y.A general methodology for direction-based irregular routing algorithms[J].Journal of Parallel and Distributed Computing,2010,70(4):363-370.
猜你喜欢
液压与气动(2022年1期)2022-12-07 09:08:09
液压与气动(2021年1期)2021-04-08 15:08:40
湖北第二师范学院学报(2020年2期)2020-06-05 02:18:30
科学与财富(2020年35期)2020-03-11 03:01:50
网络安全和信息化(2018年3期)2018-11-07 03:02:44
网络安全和信息化(2017年11期)2017-11-07 09:03:22
分析测试学报(2015年3期)2016-01-13 06:18:12
计算机工程与应用(2014年23期)2014-08-03 15:23:18
电测与仪表(2014年16期)2014-04-22 05:20:30
计算机工程(2014年6期)2014-02-28 01:25:54
