
CPR1000核电项目DCS与第三方系统通讯故障诊断及优化
2013-11-14 11:06:26程保华
电子测试 2013年8期
程保华,朱 雯
(中广核工程有限公司,广东深圳 518124)
1 核电DCS结构及其通讯站
中广核CPR1000核电扩建项目的DCS系统按照不同的安全等级划分为核安全级(1E)及非安全级(NC)两部分,DCS系统与第三方的通讯集中在NC-DCS部分实现。NC-DCS系统的一层网络SNET主要连接有多个FCS现场控制站以及与通讯站;二层网络MNET连接有多个OPS操作员站以及计算服务器RTDB、历史服务器HS等。I/O Server服务器实现控制数据的下行和监视数据的上传。工程师站ES实现对一、二层设备的组态和下装。
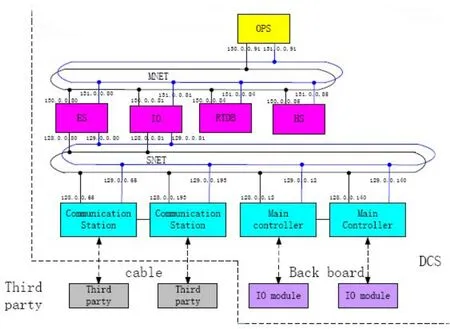
图1 NC-DCS系统结构示意
基于HOLLiAS MACS V6 的NC-DCS平台采用工业控制计算机作为通讯站与第三方系统通讯,通讯站连接在DCS的一层网络SNET上,可与现场控制站(FCS)进行站间通讯并与I/O Server交换数据。NC-DCS平台上的通讯站主要通过串行链路或者以太网链路与第三方系统网关连接,与第三方系统进行通讯协议有三种:基于RS485串行链路的Modbus-RTU、基于以太网TCP/IP的Modbus-TCP、基于以太网TCP/IP的IEC-104通讯。
2 DCS与RGL通讯特点

图2 并行冗余的通讯站链路连接
RGL是核电站的反应堆棒位控制系统,它通过一对网关同时与DCS的1E和NC部分DCS通讯,本文只讨论与NC-DCS部分的通讯。RGL和DCS侧各使用一对通讯站通过两条以太网链路交换数据。DCS侧采用两台工控机构成冗余的67#通讯站,RGL侧采用国外某品牌PLC通讯模块实现数据通讯。双方通讯站出口的以太网电信号通过光电转换器O/E转换成光信号,通过光纤进行连接。
下图为两个冗余的通讯站与第三方系统做以太网并行冗余通讯时的物理连接示意。A和B两个通讯站均冗余地接入一层系统网SNET;A站和B站的SNET2B网口相连,构成冗余网RNET作为两个通讯站之间的冗余状态监视。通讯双方各自的一对通讯站都同时进行数据通讯,但只有作为主站的通讯站才与SNET网络交换数据。如果其中一个DCS通讯站故障或不能与第三方正常通讯,另一个通讯站就能够立即变为主站。
在通讯协议上,双方采用基于TCP/IP的Modbus-TCP协议,DCS侧通讯站为主站,GRL侧为从站。DCS使用Modbus功能码1读取RGL的棒控状态反馈、用功能码3读取棒位、功能码5写控制指令、使用功能码16向RGL侧写棒控设定值。DCS通讯站配置的链路参数中,超时时间设定为500ms,TCP端口号为502。
3 通讯故障及诊断分析
在某次运行人员检查操作员站事件日志时,发现日志中长期存在67#通讯站A/B机与RGL通讯链路故障。经检查,故障发生频率为每天十几次,而且故障后几秒钟后又自动恢复正常。在检查了软件参数配置和硬件链路后都没有发现问题所在之后,我们决定采用报文分析的方法查询故障原因。
报文分析是获取和分析双方通讯链路上往来的数据报文,从而查找和定位故障的诊断方式。报文分析最大优点是可直接看到网络上通讯的最真实数据,通过分析报文数据不仅能够分析出两方数据传输是否正常,还能看到双方传送的每一个具体数据的值是否正确传输。因为工程现场不允许在DCS网关计算机上安装报文分析软件,RGL侧PLC模块也没有报文抓取功能,我们采取了在以太网链路上监听的方式。如下图,断开RGL A侧通讯站与相应光电转换器的以太网线,接入一台带端口镜像功能的诊断用高性能千兆交换机(双方为冗余通讯,断开一条链路不会使通讯丧失),再将诊断用便携PC机接入交换机。通过配置交换机端口映射(如图所示,将Port1或port2映射到Port3)的方式即可取得双方往来通讯的报文。在诊断用PC机上使用了Windows平台下的WinPcap4.1以及dumpcap工具进行抓包,以适应计算机稳定和长期大数据量抓包的性能要求。在报文分析上使用Wireshark软件进行辅助分析。
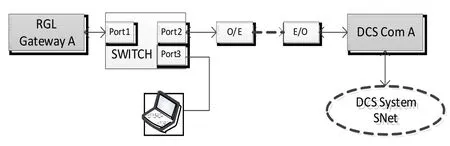
图3 接入设备监听RGL A侧通讯链路上的报文
通过在A/B双侧长期抓包,我们获取了大量报文,经过整理,发现故障原因主要可分为两类,一类是随机发生的RGL无响应导致通讯中断的情况;另一种是在DCS用功能码16写寄存器后发生的RGL侧无响应导致通讯中断的情况。
3.1 第一类故障分析
对于每一条TCP报文而言,它有自己的序列号Sequence number、确认号Acknowledge number以及数据部分长度Len。每条报文的序列号Seq等于对方发来上条报文的Ack号;而确认号Ack等于对方发来上条报文的Seq号+报文携带的应用层数据长度Len。
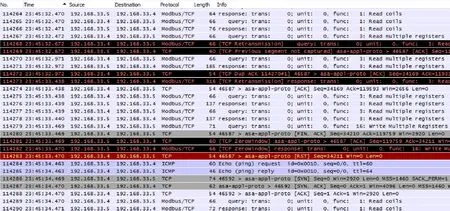
图4 Wireshark软件的报文辅助分析结果
图4为Wireshark软件中对故障部分报文的解读,图5为对双方往来报文的分析示意。如图所示,当IP地址为192.168.33.4的DCS通讯站发出一条使用功能码3读起始地址为0X6E的61个寄存器值的Modbus请求(图5的①表示,这条报文在Wireshark中的编号为114267)后,RGL侧未及时给出响应。DCS通讯站在等待了200ms后,在既未收到TCP确认也未收到Modbus答复的情况下,重新发送了这条TCP报文③(TCP Retransmission)。之后RGL侧仅给出了一条不带任何Modbus应答数据的TCP确认④。DCS在收到报文④后就会发现,报文的序列号Seq119462并不等于RGL侧上一条报文的Seq119309+Len22=119331。可见,RGL网关在发送报文④的时候,它认为自己先前已经将一条序列号Seq =119331、确认号Ack=34157、应用层Modbus答复数据长度为131(序列号119462-119331)的TCP答复报文②发给了DCS,但实际上这条报文RGL网关并未发出。图4中的Wireshark软件也在这条报文上给出了专家诊断信息提示[TCP Previous segment not captured],表示未捕获到RGL侧发出的上一条报文。实际上RGL侧未发出的这一条报文从数据长度131上看正是对DCS请求的答复。接下来,由于DCS通讯站仍未接收到有效的Modbus应答数据,它以一条新的TCP报文⑤再次发出与之前内容相同的一个Modbus请求。同时,因为DCS通讯站通过收到的报文④已经知道RGL有一条报文丢失或未发出,这时DCS再发出的报文⑤的ACK确认号复制了其上一条报文③的ACK号119331,即这是一条带有TCP重复应答信息[TCP Dup ACK]的报文,用于告知RGL侧有报文未收到。
对报文⑤的Modbus请求数据,RGL网关给出了一个带有Modbus响应的TCP答复报文⑥,但未纠正报文⑥中的序列号错乱。DCS随即发出了一条单纯的TCP重复应答报文⑦,再次复制ACK号,告知RGL网关存在序列号跳跃现象,要求RGL网关从丢包的序列号119331开始重发数据。Wireshark软件对报文⑦也给出了专家诊断信息[TCP Dup ACK 114270#1],提示报文⑦是对报文⑤的TCP重复应答。
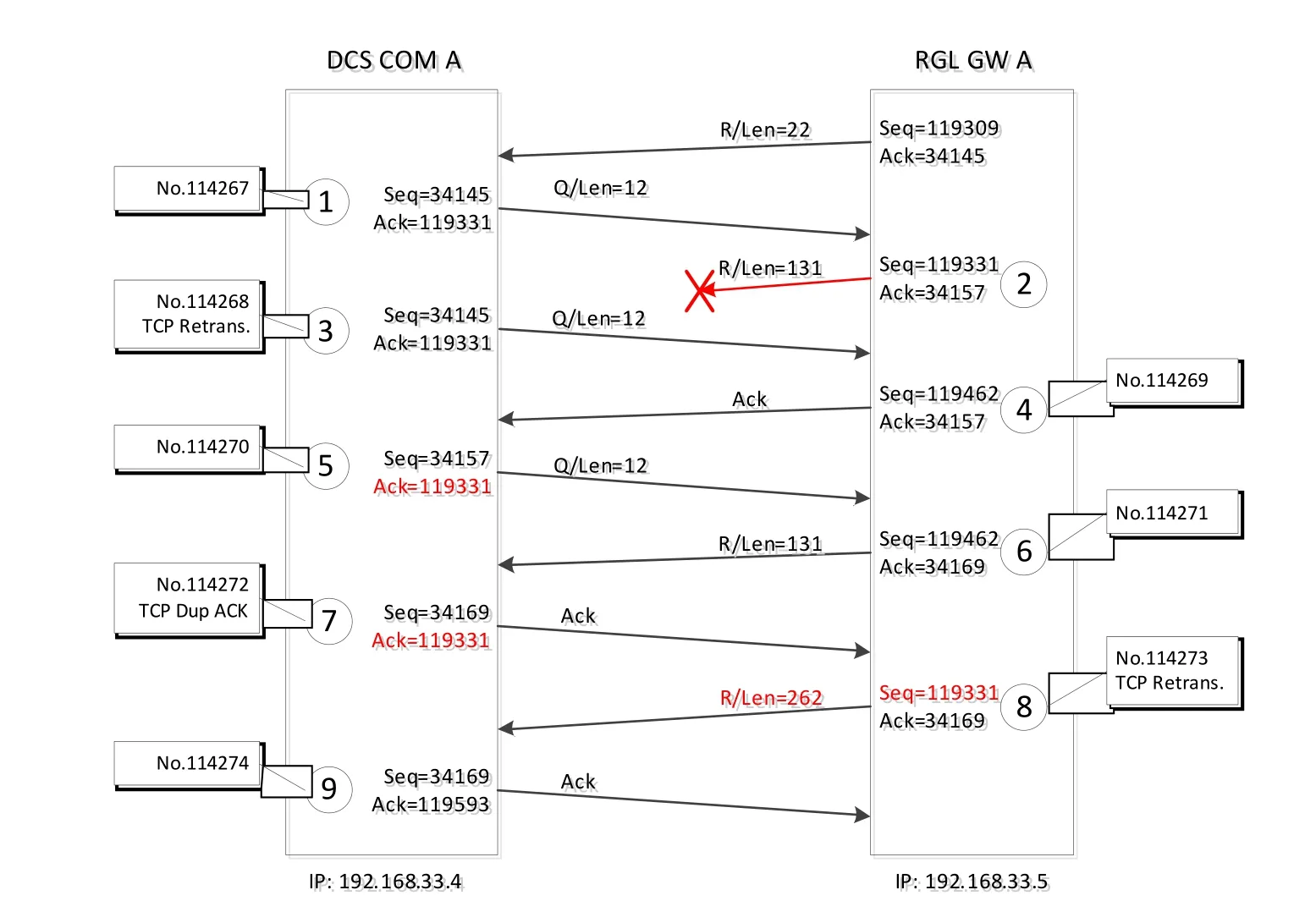
图5 故障部分的报文往来分析示意
两次收到DCS发来的[TCP Dup ACK]信息后,RGL网关发出报文⑧将序列号重置为丢包的序列号119331(也是报文⑦的Ack号),并重发了丢失的数据。但是这条报文⑧却加载了两个完全相同的应用层Modbus应答数据(Modbus PDU),使得这条报文长度达到262(内容如图6所示)。因为报文⑧的这种双Modbus PUD格式不符合通讯双方之前的约定,DCS是无法解析的,因而在发出第⑨条确认报文后,DCS通讯站就出现了程序错误:DCS在此之后对每个发出的Modbus请求都会发送两次,RGL侧也被迫应答两次(报文No.114275~No.114278),最终DCS在No.114280条报文请求终止了通讯。
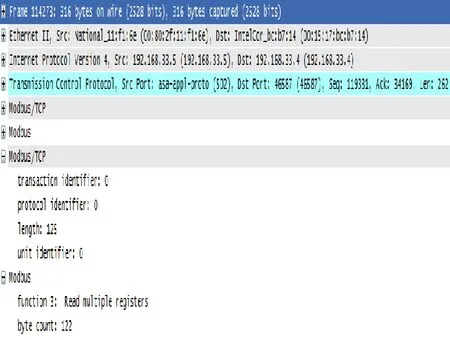
图6 RGL返回的异常报文⑧的详细内容
通过上面的分析可知,引起通讯中断的最初原因是RGL侧未及时响应DCS的请求,然而在DCS的多次请求后RGL其实是给出了正确答复,这本不至于导致通讯中断。但是由于RGL侧发出了一条异常报文⑧,以及DCS通讯站对这条报文的容错处理机制不完善,引起了DCS后续的请求报文的异常,最终导致了通讯中断。
3.2 第二类故障分析
对于第二种故障的情况,其现象都是在DCS使用功能码16向RGL侧写棒控设定值后,RGL通讯站长时间没有响应。超过DCS的等待时间500ms之后,DCS认为RGL侧已经出现故障,于是申请重新建立TCP连接。但是DCS起初尝试的几次TCP SYN同步请求收到的都是RGL网关返回的带有[RST,ACK]字段的应答,说明RGL网关内部没有进程在502端口上监听。一段时间后,RGL侧才给予了TCP握手应答。这种情况比较简单,这里就不给出图文分析。
4 优化方案及实施效果
对于上面分析的两类故障,主要现象都是RGL侧未及时响应DCS的请求报文引发的,这需要RGL厂家进行分析解决。但因为项目现场工期紧张,经过内部分析和讨论,给出了DCS首先能做的优化,拟通过优化措施减少或消除链路中断的故障。
a)修改DCS对RGL侧异常报文的处理机制。在对第一类故障的分析中提到,DCS通讯站在收到RGL侧发来的含有两个重复的应用层Modbus协议数据的异常报文⑧之后也出现了故障,最终导致通讯中断。对此我们认为,DCS虽无力使RGL侧及时应答,但DCS通讯站对于通讯中收到的异常报文应该据有一定的容错能力,只取其中一个应用层数据,避免引发通讯中断。
b)增加发送帧间隔时间。DCS与RGL从建立通讯开始,报文交换密度就比较高,在DCS不进行RGL棒位操作时(大多数情况),双方的通讯数据每秒就能刷新约20个周期,约50ms刷新一次,这显然有些过于频繁,参数配置不合理。经过分析评估,在完全满足性能要求的情况下适当增加刷新周期不但能够减轻双方通讯站的负担,也能够尽量减少因RGL响应慢导致的链路通讯中断的发生。最终DCS通讯站设定了5ms的帧间隔时间,使数据刷新周期增加到100ms,但完全满足数据传输实时性的要求。
c)增加写指令重试次数。在上文对第二中链路故障的分析中提到,DCS在发出功能码为16的写指令而没有收到RGL侧响应,之后DCS通讯站既没有进行任何重试,也没有尝试关闭连接,而是直接要求重新建立连接,这种机制实际上是不合适的。对此,我们要求供应商必须修改通讯驱动的算法,完善响应的机制,并将写指令重试次数则增加到三次,增加给RGL做出应答的机会和时间,以期减少链路故障的发生率。
在现场实施上述优化改造后,一直再未出现过链路故障的报警。但是通过检查报文,RGL侧未及时响应的情况还是存在,只不过DCS通过增加容错和重试次数,每次都避免了通讯中断。近期,RGL侧PLC厂商已在工厂复现故障并分析出原因,后续将进行修改。而本文提出的DCS通讯站的优化方案已经在多个CPR1000在建核电机组上实施,改善了DCS通讯站的性能。
[1]GB/T 19582-2008,基于Modbus协议的工业自动化网络规范
[2]Doyle,J,Carroll,J.D,TCP/IP路由技术,夏俊杰(译),2009-06-01,人民邮电出版社
猜你喜欢
装备制造技术(2020年1期)2020-12-25 05:18:20
成都信息工程大学学报(2020年5期)2020-07-29 08:50:22
网络安全和信息化(2018年4期)2018-11-09 12:01:52
电子制作(2017年24期)2017-02-02 07:14:44
移动通信(2015年18期)2015-08-24 07:45:08
电源技术(2015年7期)2015-08-22 08:48:48
中国交通信息化(2015年11期)2015-06-06 06:51:33
太阳能(2015年7期)2015-04-12 06:49:50
组合机床与自动化加工技术(2014年9期)2014-03-01 02:21:45
计算机与网络(2013年6期)2013-08-15 00:50:42
