
基于多特征提取的识别算法数学建模优化研究
2013-10-24 10:17李华平
哈尔滨师范大学自然科学学报 2013年4期
李华平
(重庆城市管理职业学院)
1 基于统计决策算法的汉字数学模型识别
多特征提取的识别算法数学建模对汉字特征矢量提取有很明显的作用,特征矢量并不是直接对笔迹进行标识,而是对字符图像的特征进行描述.多特征数学模型能够根据训练样本的情况,进行特征矢量分布问题分析,保证数学算法优化,提高其算法的抗干扰能力.数学模型设计过程中需要设计一个分布式的函数,通过多变量正态概率密度函数进行多特征标识,从而能够形成一个样本分布的近似函数,保证把汉字图像的特征提取出来.
2 汉字特征提取数据模型建立
汉字提取与结构特征有紧密的联系,通过大小归一法对归一化的策略进行实施.设原始手写汉字为Y行×X列,归一化后为 height×width列,则:(1)如果X≤width且Y≤height,文字只做平移操作;(2)如果X>width且Y<height,则将文字宽度归一化为width,高度按比例归一化;(3)如果X<width且Y>height,则将文字高度归一化为height,宽度按比例归一化;(4)如果X>width且Y>height,则将文字归一化为height行×width列.保证汉字特征提取能够符合识别算法的要求.识别算法在机构特征数学模型的控制下,保证其线段、特征点、基本笔画、基本笔画方向图能够符合特征函数提取的要求.特征汉字提取需要从字符的几何结构特征出发,保证笔法提取符合夹角的控制要求,数学模型在特征机构设计中需要从 0°,45°,90°和 135°的四个方向进行结构设计,并用1,2,3,4以及 -1,-2,-3,-4分别标记这四个方向及其反方向.令g(x,y)为像素(x,y)的灰度级,对于黑色像素 g(x,y),对于白色像素 g(x,y)=0,字符是由黑色像素组成的图像.
3 特征提取与结构识别数学函数与模型算法优化
特征提取与结构识别方法在汉字等领域的应用越来越多,当前需要借助数学函数和模型对特征提取进行算法设计,并且能够采取更优化的方法,实现特征提取的精确效果.
3.1 手写汉字特征提取与结构优化数学模型研究
数学模型设计优化过程中需要把汉字的笔画分成若干类,然后对每个笔画进行变量分析,从而能够形成一个汉字的特征,然后加入汉字特征数据库,最后通过设计数学函数,形成笔画序列特征和字库特征比较函数,通过图像特征的数学模型比较,可以实现图像的预处理和结构优化.在特征提取算法实施过程中,可以通过数学函数优化对其方向进行细分,通常分为顺时针方向折、逆时针方向折和混合方向折三种.在笔画归类提取过程中会面临一个数学问题,如何进行图像文字读入算法设计的问题,在具体实现中会用到数学模型的斜率,但是在特殊情况下用斜率是不合理的,比如在方向3和7根本就没有斜率,因此在算法模型设计中需要对像素后面第二个点坐标和该点像素指标进行比较,数学模型算法逻辑如下:
(1)若 point[a+2].y=point[a].y 且 point[a+2].x>point[a].x,方向1.
(2)若 point[a+2].y=point[a].y 且 point[a+2].x<point[a].x,方向5.
(3)若 point[a+2].x=point[a].x 且 point[a+2].y<point[a].y,方向3.
(4)若 point[a+2].x=point[a].x 且 point[a+2].y>point[a].y,方向7.
(5)若 point[a+2].y=point[a].y 且 point[a+2].x>point[a].x,方向2.
(6)若 point[a+2].x> point[a].x且 point[a+2].y<point[a].y,方向8.
(7)若 point[a+2].x< point[a].x且 point[a+2].y>point[a].y,方向4.
(8)若 point[a+2].x< point[a].x且 point[a+2].y<point[a].y,方向6.
在获取相应笔划方向的时候,需要根据笔划各个相素的方向,进行综合去噪处理,从而能够消除在收笔和下笔过程中产生的抖动问题,从而能够获取若干个相素点,为消除相素点创造数学模型.根据书写过程中产生的歪曲点和若干奇异点情况,进行算法的距离匹配设计,从而能够产生相似的标准.通常数学模型距离设计为:

其中m为输入文字图像的笔划数,ai为输入文字图像第i笔test[i]的笔划与字库中某组待比较特征的第i笔的相似度,经过大量的调查分析,ai一般取值如表1.
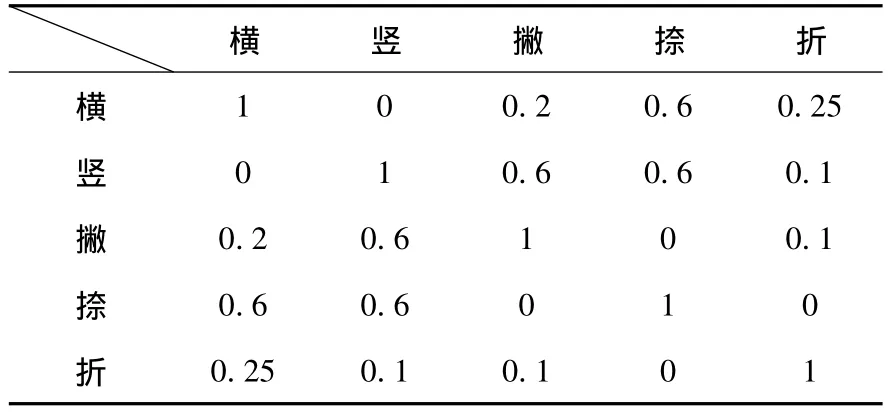
表1 笔划的相似度表
此数学模型算法优化的步骤如下:
(1)从输入点进行数据函数控制,从而能够产生有效的输入点序列.
(2)通过对输入点进行参数控制,确保能够进行去噪处理,从而通过数学距离函数计算出方向码序列.
(3)通过方向码距离函数对去噪处理后的笔画码序列进行处理.
(4)根据距离函数对匹配的汉字进行特征提取和识别.
数学模型算法提取过程中需要根据距离进行阀值dis比较,如果若d<dis,可以通过对字体的特征进行比较,形成序列码,然后按照序列码进行识别优化,确保距离函数能够进行字体特征识别控制,提高字体识别的整体效率.例如:汉字“六”和“文”的笔划序列都是“4134”,所以无法正确识别.
3.2 统计特征数学模型算法的函数结合和改进
统计特征数学模型算法设计过程中需要以基因笔为变量,通过特征参数进行函数改进,确保在手写汉字识别中能够对自体特征库进行优化,提高函数识别的效率.基于统计特征数学模型函数优化过程中需要对汉字结构进行顺利控制,保证每笔画能够产生一定的结构,联机手写汉字识别的过程中,把各类笔画信息通过数学函数表示,让输入的汉字图像能够按照笔画和相素角度设计要求,从而能够产生粗类和细类,提高汉字识别的整体特征效果.函数模型设计过程中通过交叉点和轮廓作为变量,假如在设计过程中有一个交叉段,同时在此附近有一个交叉点,在函数设计过程中如果程序发现有交叉点的时候,需要通过函数进行交叉点分析,确保交叉轮廓能够符合特征控制的要求,让轮廓交叉能够符合特征信息提取的要求,从而能够产生正确的交叉点,让点和点之间的距离符合Nd控制的要求.用Df表示交叉度,让其能够符合交叉点信息控制的要求,对准确定位交叉点的位置会产生重要的作用.保证交叉点控制代码符合数学函数的要求.则有Df=N1+N2+N3+N4.为了确定交叉点的位置,交叉点代码设计中需要通过路径控制,保证其符合轮廓控制的具体要求:
(1)Df=0,表示具有轮廓特征的那一段.
(2)Df=1,标识在这段只有一个轮廓,并且能够根据像素情况性特征控制,确保特征能够符合函数控制要求.
(3)Df> 1且N1,N2,N3,N4至少有两个轮廓段,在轮廓控制过程中通过各种标识量进行信息优化,保证信息控制能够符合汉字特征提取库的规范化要求.
(4)N1 > 1,N2,N3,N4 ≥ 2,至少有两个具有相同方向代码的轮廓段.如果有一对延伸方向相反的d向轮廓段,则标识量Flagd置为1,相反则为0.此时确定交叉点时需要分三种情况讨论:
(a)Flag1+Flag2+Flag3+Flag4=0,轮廓控制过程中需要形成一个正确的交叉点,然后对交叉点与特征的距离符合笔画宽度控制的要求,从而能够形成正确的交叉控制机制,具体实施过程中需要对笔画信息进行优化,确保信息控制符合交叉点的要求.
(b)Flag1+Flag2+Flag3+Flag4=1,只存在一对延伸方向相反的轮廓段.用一段直线将它们连接起来,取该直线的中点作为交叉点.
(c)Flag1+Flag2+Flag3+flag4 > 1,至少存在两个延伸方向相反的轮廓段.任选两对轮廓段,将每对用一条直线相连,两条直线的交点便是所期望的交叉点.
在交叉点提取过程中需要根据汉字特征提取算法对函数进行优化,确保其能够在轮廓设计过程中进行字符瘦化,保证轮廓段能够交叉点结合在一起,从而能够形成一个完整的特征识别算法.在提取交叉点和轮廓的过程中,需要对点特征和线段特征进行分析,从而能够进行信息特征处理,保证基本笔画能够符合数字模型特征的要求,根据特征轮廓信息让不同的笔画能够按照方向图进行函数设计,通过函数进行合并,形成轮廓段基本笔画,依次对各个笔画进行轮廓段共线.记φ1和φ2分别为两个轮廓段的方向角,令φ=min(|φ1-φ2|,360°-|φ1-φ2|)为两段的夹角,若155°<φ<180°,则允许将两段合并.通过函数合并之后需要进行轮廓段控制,确保产生新的特征距离d.当各个交叉节点特征提取完毕,整个特征函数被确定,达到优化控制函数的目的.
3.3 统计特征汉字识别数学函数特征值优化
统计特征函数提取过程中需要对特征变量进行确定,通过对不同特征变量的情况进行分析,从而能够形成一个完整的特征库,对函数设计会产生指导作用.汉字图像在特征设计中需要进行相素分析,从而能够产生分布特征.对特征函数能够更好的提取特征值具有很大的作用.特征值在提取过程中需要形成一个4×4特征值,通过函数转换的方法,把一个汉字图像转换成为一个二值图像,然后进行特征处理,确保特征值能够符合函数图像设计的要求,对优化汉字特征库有积极的影响.通常把一副汉字图像分成4×4=16或3×3=9个区,对统计区每个像素的点数进行控制,然后通过函数把总数统计出来,把这个特征与函数库里的字体特征进行比较,最终能够进行最小字符匹配,如果能够匹配,说明这个特征函数计算出来的特征向量是正确的,反之此特征不在汉字特征库,需要进行算法优化,然后再进行搜索.在算法搜索过程中需要用到两个数学模型,一个是方差距离控制,另一个是绝对值距离控制.当前绝对值算法控制会产生很多的效果,数学模型仿真中,采取4×4划分,然后对各个区域的特征进行特征值计算,仿真如图1所示:

图1 汉字图像的统计特征图
图1是一个汉字图像并对其做了4×4划分,其中各区的特征值如图1所示.
现在把其特征表示为一个数组即test.p[16],若字库中第 i组特征为 tez[i].p[16],则待识别汉字图像与字库里第i个字的距离为:

为了便于识别,需要定义阙值dis,若d<dis,即可认为输入汉字为字库中第i个字符.算法优化的具体步骤如下:
(1)通过对图形进行4×4模式分区,然后通过函数d对每个区的黑色像素点数进行计算.
(2)对每个区域内的黑色点数进行优化,具体实现中通过黑色像素点数除以总的黑色像素点数,然后可以得到 p[i],i=1,2…9.
(3)然后通过返回程序,通过式(2)计算出相应的距离d,然后进行区域匹配判定.
通过此种数学模型进行汉字特征提取,具有形象直观的好处.具体实现过程中可以从如下几个方面进行优化,解决特征提取过程中的各种弊端问题.
(1)通过对字体进行识别,然后对特征库进行优化,可以解决汉字特征歪曲大的问题,通过对d的计算,可以消除这些误差.
(2)由于在现实中汉字特征具有多样性,因此在多特征提取过程中,需要通过d计算可以进行规范化预处理,确保函数特征提取更加规范,符合特征库图像提取的要求.
(3)汉字特征提取过程中存在很多字体很相似的局面,需要通过统计识别算法,对不同特征的函数进行d计算,把最终的信息录入特征库,从而能够特征提取,提高多特征提取的效率.
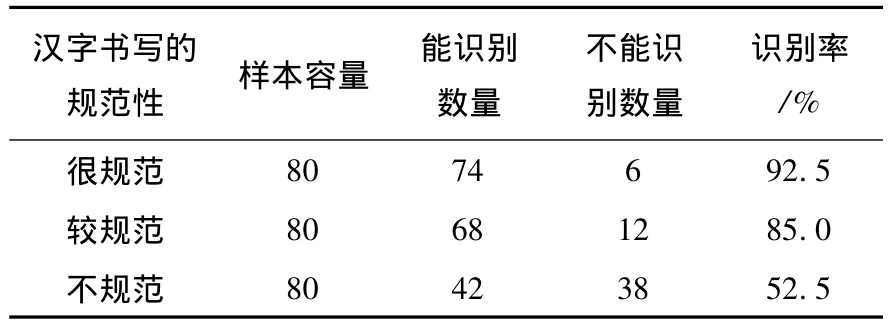
表2 对不同结构汉字的识别率(很规范)
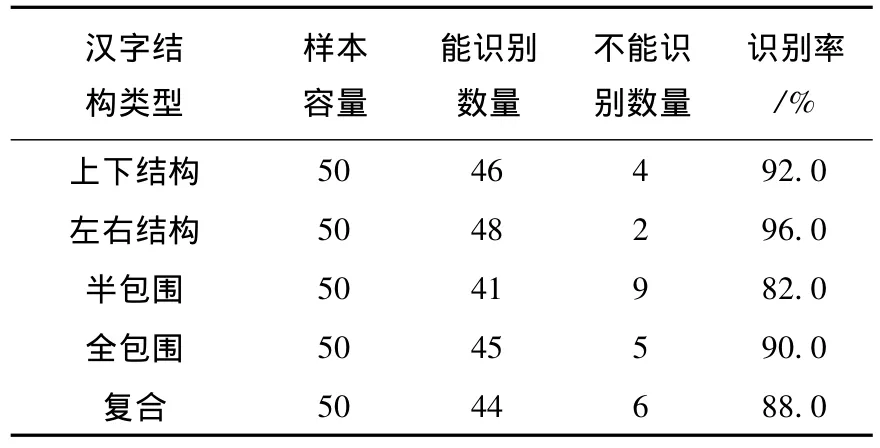
表3 对不同结构汉字的识别率(很规范)
4 结果分析
通过实验可以看出,多特征提取的识别算法可以避免汉字书写过程中不规范的问题,从而能够提高汉字特征识别的效率.对规范化识别的汉字成功率高达90%以上,达到汉字多特征提取数学函数优化的目的,对汉字进行规范化提取具有重要的应用价值.
通过对多特征函数模型优化,可以对汉字进行多特征提取,通过对函数进行算法实现,从而能够产生识别效果.在实验过程中通过特征提取汉字图像如图2所示.

图2 多特征汉字提取示例
算法对书写规范性不同的汉字图像的识别率见表2,表3.
其中,规范性主要是指笔划的标准程度,比如说“横”的歪曲度等.表3给出了该算法对不同结构的汉字的识别效果.
[1] 陈继超.支持向量机技术及其应用[J].科技信息(科学教研),2007(25).
[2] 刘志刚,李德仁,秦前清,等.支持向量机在多类分类问题中的推广[J].计算机工程与应用,2004(7).
[3] 张世辉,孔令富.汉字识别及现状分析[J].燕山大学学报,2003(4).
[4] 杜树新,吴铁军.模式识别中的支持向量机方法[J].浙江大学学报(工学版),2003(5).
[5] 吴涛,贺汉根,贺明科.基于插值的核函数构造[J].计算机学报,2003(8).
[6] 封筠,王先梅.脱机手写体汉字识别技术研究的回顾与展望[J].微型电脑应用,2003(4).
[7] 石繁槐,童学锋.SVM在小字符集脱机手写体汉字识别中的应用研究[J].计算机工程,2002(6).
[8] 鲍胜利,沈予洪.汉字识别技术的新方法及发展趋势[J].实用测试技术,2002(2).
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
新高考·高二数学(2022年3期)2022-04-29
装备制造技术(2020年1期)2020-12-25
World Journal of Psychiatry(2020年4期)2020-07-11
制造技术与机床(2019年11期)2019-12-04
小学生学习指导(中年级)(2019年3期)2019-04-10
中国交通信息化(2017年4期)2017-06-06
中学数学杂志(初中版)(2016年5期)2016-11-01
中华建设科技(2014年6期)2014-08-27
河南科技(2014年5期)2014-02-27