
基于词对依存分类的藏语树库半自动构建研究
2013-10-15 01:38华却才让姜文斌赵海兴
中文信息学报 2013年5期
华却才让,姜文斌,赵海兴,刘 群
(1.青海师范大学 藏文信息研究中心,青海 西宁810008;2.中国科学院 计算技术研究所智能信息处理重点实验室,北京100190;3.陕西师范大学 计算机学院,陕西 西安710062)
1 引言
依存句法树库作为依存句法分析、句法机器翻译、文本挖掘等热门研究领域的支撑语料,其重要性不言而喻。藏语依存句法树构建,从句法标注规范、句法树库构建及其规模均比较滞后。文献[1]结合纯手工构建的藏语依存句法树库(Tibetan Depend-ency Treebank,TDT)规模为1万句左右,采用一层感知机判别式方法训练模型,在3百句测试集上的依存识别正确率达到81%[1],中心词识别正确率为87%,完整依存标注句子正确率为34%。藏语作为SOV语序结构,并含有丰富的格助词接续规则,一句子中中心词在句末,直接宾语和间接宾语在主谓之间[2],导致加大了纯手工标注依存句法或修改小规模训练语料上训练模型,解码分析得到正确率不算高的句法树。因此本文提出基于依存词对分类的藏语依存树库半自动构建方法,在分词标注的语料和句法分析器分析得到的句法树(标注结果不完全正确)上,呈现出比较直观和具有辅助提示功能的依存标注和修改功能。一定程度上加快了藏语依存句法的标注进展,保证了依存标注的正确性。并利用此方法对已有藏语依存句法树库的修改和补充,对已有藏语依存句法分析的正确率提升了3%。
本文第2节介绍了藏语依存句法、标注体系和树库构建情况;第3节提出了依存词对分类模型和特征抽取以及半自动依存辅助模式,包括依存关系辅助模式和依存边标注辅助模型;第4节讨论了基于依存词对分类的半自动句法树库构建及句法分析实验结果。
2 句法理论
2.1 藏语依存句法
句子中词与词之间存在的支配和被支配的关系称作依存关系。其理论可追溯到20世纪50年代,Tesniere.L在其著作《结构句法基础》中首次提出了“依存语法”的概念,主张每个句子有一个中心词(一般为动词),支配句子中的其他成分,而它本身不受任何句子成分的支配。此后为总结依存句法的概念1970年Robinson J.J提出了句法依存关系的四条公理,称之为依存语法的理论基础[3],描述为:(1)一个句子中只有一个成分是核心成分;(2)其他成分直接依存于某一成分;(3)任何成分后不能依存于两个或两个以上的成分;(4)如果成分P依存于成分Q,那么P和Q之间的任意成分R就不能依存到P和Q所构成的跨度之外,成分R或者直接依存于P,或者直接依存于Q,或者直接依存于P和Q之间的某一成分,总之,依存成分之间不能交叉。
依据现有其他语言的依存树库构建经验,例如,斯坦福大学英语依存标准[4]和文献[5]中阐述的中文依存体系,在设计藏语依存句法关系时,同样考虑了对依存关系的易于理解和使用的要求,使其能为藏语句法研究提供真实文本标注素材,便于语言学家从中总结语言规则和规律。用一个三元组r(v,w)描述词对之间依存关系,意为词v支配词w,v是主词,w是从词,r称作v向w的下依存关系。例如,可解释为的主语是“ /nr”。这种句法依存关系有利于从句子的词语线性排列中获取内部语言信息。例如,藏语句子(卓嘎给同学们讲朗萨雯蚌传。)”的依存句法关系可描述为:

依存关系可转换为有向图句法树(V,E)模式,其中每一个词表示图中的一个结点v∈V,词对间的依存关系r为有向边e∈E的标签。上面藏语句子依存分析树同样可以表示为图1。
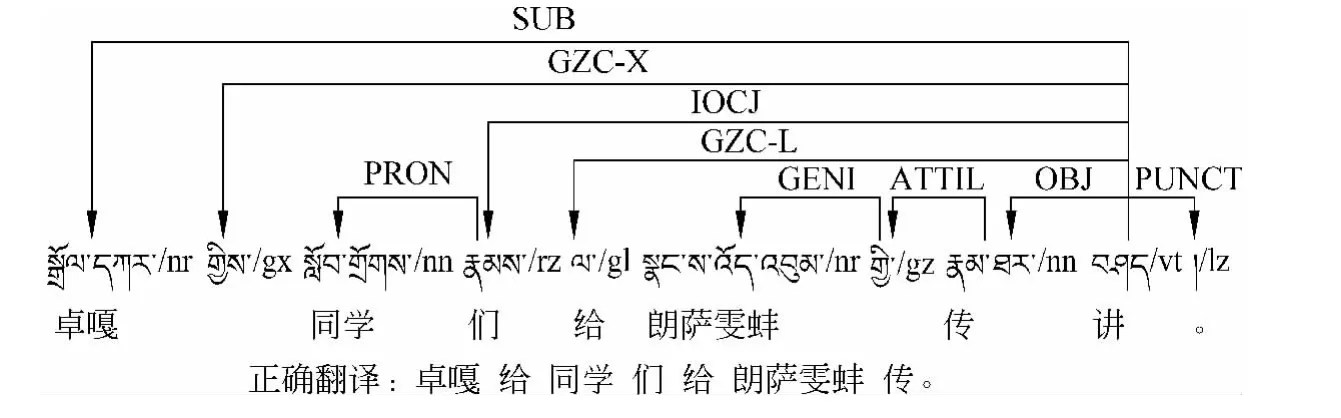
图1 有向图模式藏语依存句法分析树
在没有边标签的依存句法分析应用中,我们可将藏语的依存树结构表示为如下形式:

2.2 句法标注体系及层次结构
传统藏语文法包括两部分,一是文法根本三十颂,讲藏语拼写结构、格助词和各类虚词的用法;二是字形组织法,主要讲以动词为中心的形态变化、时态,施受和能所关系等[6]。藏语句子是格助词、虚词和动词等依据句法理论发生结构关系而成的词语线性排列,其基本语序结构为<主语>+<间接宾语>+<直接宾语>+<结果补语>+<状语>+谓语+<状态补语>。据藏语词频统计,藏语语料库中格助词类的频率最高,其通用度稳定,句子中内部组织成分的层次结构也基本与格助词结合相关。例如,句子中出现主格时,其前面一般为使动成分而后面部分为被动成分,即基本可确定主语和宾语。考虑到依存关系过于细致和庞大,会导致交互式句法分析器的鲁棒性、可操作性下降和统计数据的稀疏等问题,本文结合藏语实际切分标注语料制订了36类藏语依存关系[7],其数量相对英语和汉语比较少,但尽可能使制订的句法依存关系满足藏语的各种语法现象,涵盖句法规律。句子中一条依存句法关系表示了一个支配词(一头节点)和一个被支配词(一个孩子节点)的二元支配关系。由于论文篇幅,本文中对依存句法关系的定义以及与其他主流依存句法体系的差异不作具体赘述,将在藏语依存句法体系一文中做详细讨论。藏语依存句法层次结构如表1所示。

表1 藏语依存句法层次结构见表

SUW-离合词结构SC-待述词结构MOD-修饰QUANT-限定(限量、时间)结构AFFIX-词缀结构QDIG-数词附加语结构GENI-属格结构YY-陈述词结构(“”)OS-饰集词结构PRON-代词结构EXIAU-存在助词结构(“ ”)DUP-词的重叠结构ADVMOD-状语结构ADVANG-状态修饰结构(“ ”)APPOS-同位语结构GLC-关联词结构EXCL-叹词结构FASQP-终结和疑问结构PUNCT-标点符号DEP-未知依存结构
2.3 藏语依存树库及问题
藏语依存树库的构建目前处在起步阶段,是一项比较庞大的工程。以现有依存库TDTreebank 1.0作为训练语料的统计句法分析器分析能力还比较弱,主要原因可归结为句法树库的规模小;人工标注的平均句子词数小于17[1],对一些歧义结构,特别是复杂句子的的分析错误还很多。有了之前TDTreebank 1.0树库语料,目前藏语依存树库的构建大致分为三步,一为预处理,主要对生语料做断句、分词和词性标注,以及语料全半角等的统一工作。本文中使用了青海师范大学的藏语分词和词性标注规范[8];二是机器分析,用句法分析器分析生成句法分析树;三是人工校对。其中第三步是比较枯燥的工作,但也是必须要做的工作,同时也是本文的主要研究介入点。为获得最佳的整体处理效果,人工校对时,需要提供词对依存关系辅助提示、比较可能的复杂歧义结构、交互式鼠标点击连接、修改支配关系、避免交叉依存关系标注以及长句依存标注支持等半自动功能。这些功能对人工校对或者纯人工标注具有事半功倍的效果。接下来为解决以上问题,我们在第3节提出了词对依存分类模型支持的藏语依存树库构建方法,并实现了依存标注和修改工具TibetanDepBuilder V2.4。
3 半自动句法标注
3.1 词对分类模型
3.1.1 模型
若给定包含N个词的一个句子,任意两个词之间都可能存在依存关系,寻找最可能的依存树的任务是从N*(N-1)种可能的依存边(无自环)完全图中寻找分数最大的树,于是,若y为句子x的依存树,则且i≠j,其中(i,j)表示句子x中的词xi和xj之间存在有向边,xi为词xj的父节点;根据Eisner分解法[9]可以将依存树y的分数S(x,y)表示为式(1)。
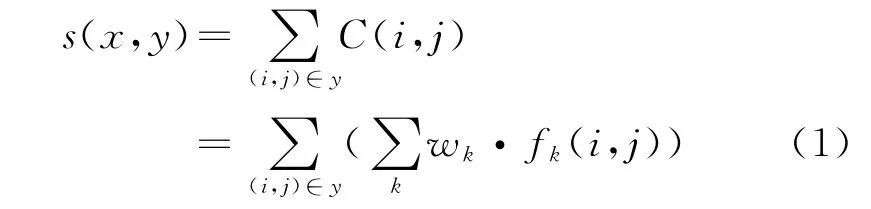
其中fk(i,j)是依存词对i和j之间的第k个特征向量,wk是该特征向量对应的参数向量,可通过训练样本获得。那么最大生成树模型[10]可以表示为式(2)。
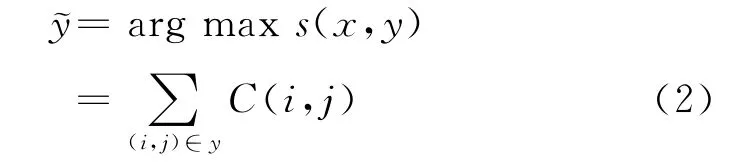
若候选词对依存分类的权重分数C(i,j)转换为概率模型C(i,j)=P,(0≤P≤1),概率P表示候选依存边的强弱,那么基于概率的最大生成树模型可表示为式(3),表示对句子x解码生成的句法树集合中当前句法树y,连乘树中所有候选依存词对的概率值,最后获取概率最大的句法树,如式(3)所示。
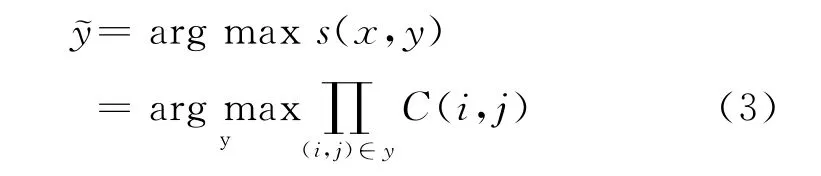
词对分类模型的任务是判断任意候选词对之间是否存在依存边,为有效获得词对依存分类概率值C(i,j),本文采用最大熵分类器训练依存词对特征的概率值,w是ME模型训练得到的参数向量,与每个特征向量是否对依存边有无贡献一一对应,表示贡献程度。f(i,j,r)是依存词对i和j之间的特征向量,表示该词对之间存在一个关系r,其中r∈{+,-},当r=+表示特征向量对该词对的依存边具有贡献,而r=-时却相反,如果一个特征fk(i,j,r)∈f(i,j,r),则其值等于1,表示该特征在训练语料中抽到的特征集中存在,否则不存在,那么词对的依存分类模型可定义为式(4)。
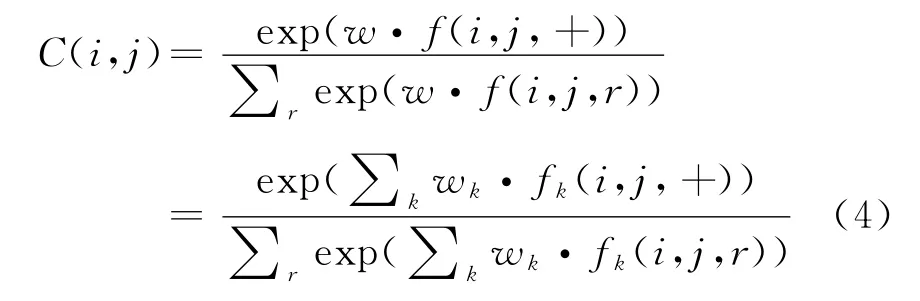
3.1.2 特征抽取
由于词对依存分类特征从一定程度上体现了语言学知识,其特征模板的设计和选择同样是影响机器学习的性能的主要因素之一,在最大生成树模型[11]中提出了每个特征是由词i和j及前后的词语和词性构成。为丰富句法特征信息,Collins distance[12]方法提出了词i和j之间的距离句法信息。这种方法解决了两个词之间顺序位置、相邻关系、是否动词居中以及两个词中间或左右是否存在标点符号等问题。藏语词对依存分类训练和解码中合成了以上两种句法特征生成模板。此外,在此基础上增加了以下特征。
1)两个依存词对i和j之间是否存在楔形分隔符:由于藏语句子中用楔形符号“”表示复合句子句、同位语、从句结尾以及连词“ ”表示分隔符,类似于逗号和顿号功能。
2)两个依存词对i和j之间是否存在主格:主格位于主语之后,表示主语为使动者,而中心词是一个及物动词。
3)两个依存词对i和j之间是否存在于格:于格一般位于间接宾语和直接宾语之间,或者介词宾语末端,充当介词成分。
本文为藏语依存句法分析分别设计了62个藏语词对依存分类特征模板,63个藏语词对依边标注特征模板,具体用于模型训练的特征模板如表2所示。
藏语词对依存分类特征模板内容分四类:(1)一元特征:定义为父结点或子结点(单个词)的特征信息构成;(2)二元特征:由父子结点共同的特征信息构成;(3)词对左右词性特征:考虑到更好地抽取到藏语格助词的搭配规律而补充了此特征信息;(4)距离特征:词对间包括其他词(结点)时的依存关系的特征信息。表2中p-word表示依存树中父结点词,p-pos表示父结点的词性,c-word 表示依存树中子结点词,c-pos 表示子结点的词性,p-pos-1表示父结点左边的词性,c-pos+1表示结点右边的词性,d*表示词对间所包含其他词(依存结点)个数,当d*的值为负数时表示句法树中抽出词对的父结点在子结点的左侧,而当d*的值为整数时表示句法树中抽出词对的父结点在子结点的右侧。藏语词对依存边标注特征模板分五类:除了四类词对依存分类特征模板,还有(5)边标注特征:P-frame用于词对依存分类边标注时用的扩展特征,表示父节点的依存边信息。
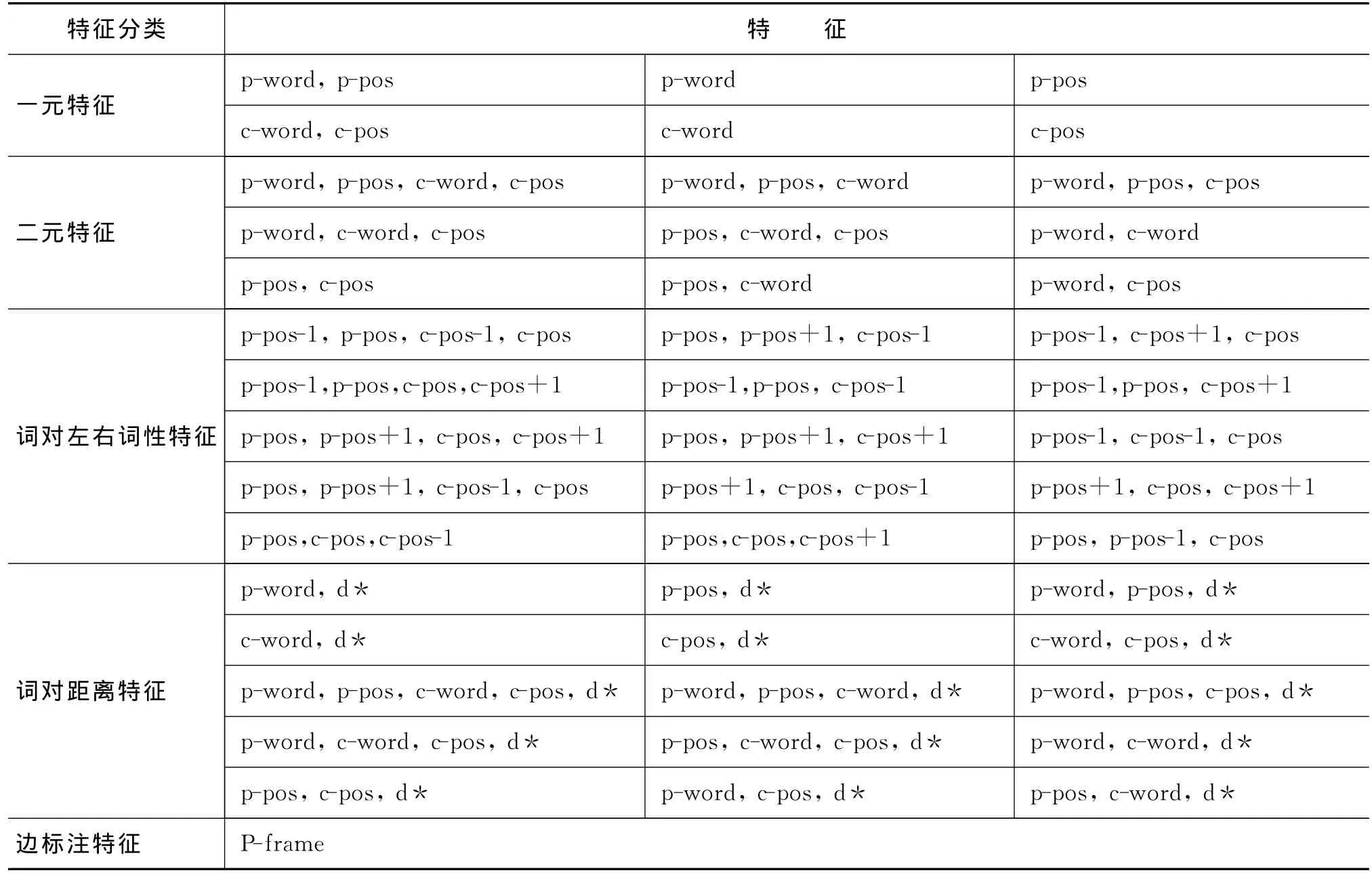
表2 藏语词对依存分类和边标注特征模板
3.2 半自动辅助模式
3.2.1 词对依存分类辅助提示
有了词对依存分类训练模型,接下来的工作是如何应用于一个词性标注好的句子中词语之间的依存标注,并即时呈现出辅助提示功能,一般标注依存词对时有两种方式,自底向上、自顶向下,其中自底向上为首先选择某个被支配词然后找出其所有可能的支配词;而自顶向下是首先在句子中选择一个支配词,然后找出所有可能的被支配词,也就是说自动给出对其余词语的被支配强弱的自动提示。本文采用了第二种自顶向下的模式,如图3所示。图中当前用鼠标选择的支配词(中心词)为“ ”,按词序号,第8和10已被选择为被支配词,8为直接宾语,10为楔形结束符。从词对依存分类辅助提示看出,剩余待被连接的1、2、4和5号词是最可能的被支配词,实际这些词分别为句子中的主语、主格、间接宾语和于格。
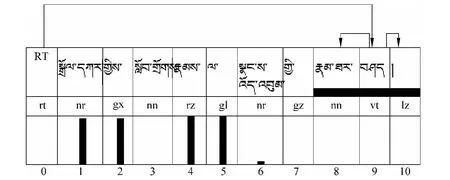
图3 基于词对分类的半自动藏语依存句法标注图
3.2.2 词对依存边自动辅助提示
这部分工作是在确定词对依存分类的基础上进行的,主要完成词对依存边的标注(弧上关系标注)提供自动辅助提示功能,类似于词性标注。根据改进式(4)得到词对分类依存边标注模型,Cl(i,j)表示依存词对i和j之间满足第l个依存边的概率值。f(i,j,l)是依存词对i和j之间特征向量,表示该词对间存在的边类型l,其中l∈{e-types},e-types表示所有可能的依存边,即依存关系类型集。如果一个特征fk(i,j,l)∈f(i,j,e-types)等于1表示该特征在训练语料中抽到的特征集中存在,否则不存在。则词对分类依存边标注模型可定义为式(5)。
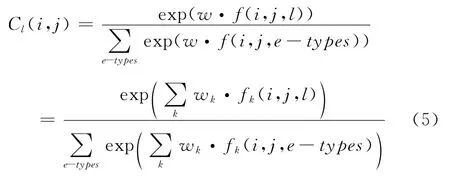
依存边自动辅助提示中,本文依据表1给出的藏语依存句法规范,通过人工标注含有依存边信息700句句法树,利用表2给出的特征模板,包含最后一项依存边标注特征,用最大熵方法训练模型,使用训练出的最大熵模型进行词对弧上关系自动辅助提示和标注,如图4所示。当前选择的支配词是“ ”,被支配词是“ ”。自动辅助提示的最佳依存边为直接宾语OBJ。

图4 词对依存分类的边标注半自动辅助提示图
4 树库构建及实验效果
为训练词对依存分类模型和词对依存边分类模型,本文人工分别构建了2000多句依存句法树和700句依存边标注句法树库,用最大熵训练了模型,并结合这两种词对依存分类模型实现了半自动依存标注和修改工具TibetanDepBuilder V2.4。利用此工具重新校对了人工标注的藏语依存句法树库TDTreebank 1.0,其规模为1万句,平均长度小于17个藏语词,总词数规模为16.7万。整个树库的校对修改率达10%,发现之前人工标注的主要错误包括:(1)复杂句句型的标注错误,包括从句结构,比较长的句子;(2)存在部分标注不一致。此外,本文利用半自动标注工具新标注了1千句句型比较复杂,且词数达20至40间的句法树。已加入到TDTreebank 1.0中,目前 TDTreebank 1.1版本的规模为1.1万句。
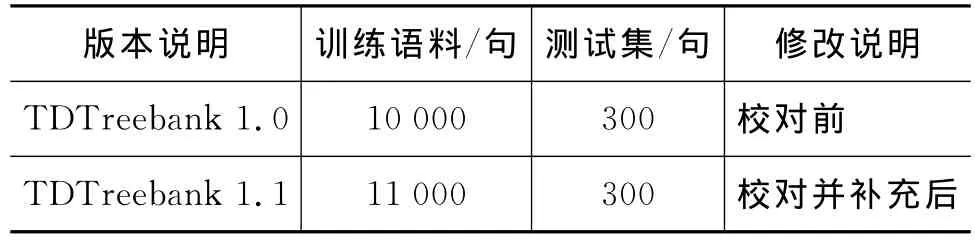
表3 校对树库语料
为了客观评价本文提出的词对依存分类半自动树库构建方法的效率,采用之前研发的判别式藏语句法分析为基线系统,重新校对并增加后的藏语依存树库作为训练语料。用之前的测试语料300句为测试集。以依存关系正确率(depP)、中心词正确率(headP)和整句完全依存正确率(allP)为性能分析指标[1],对系统的藏语依存分析结果进行评价,给出了树库校对前后的评价指标,表4校对前后各项评测指标对比中正确率I为校对之前的评价指标,正确率II为校对后的各项评价指标。效果如图5所示。
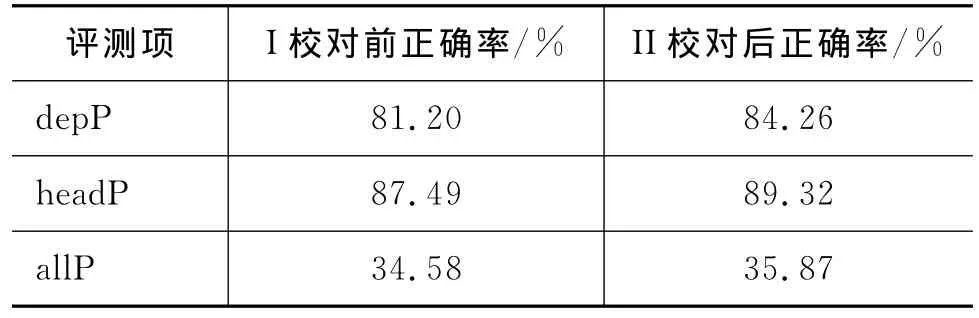
表4 校对前后各项评测指标对比

图5 树库校对前后系统对测试语料的各项评价指标
5 结论
针对藏语依存句法树库构建过程中存在的问题,本文提出词对依存分类的半自动依存句法树构建方法,描述了用于藏语依存句法结构及其标注规范,设计了词对依存分类模型和词对依存边分类模型,结合特征模板,分别在2000多句依存句法树和700句依存边标注句法树上用最大熵训练了模型,用自顶向下标注模式实现了词对依存关系自动辅助提示和依存边类型自动辅助提示功能。
利用本文实现的词对依存分类半自动依存标注工具,校对了藏语依存树库TDTreebank 1.0后,经在同样测试集上实验显示,依存句法评测各项指标均有明显的提高。在很大程度上方便了句法分析树的校对,同时加快了藏语依存句法树库构建的进展。
[1]华却才让,赵海兴.基于判别式的藏语依存句法分析[J].计算机工程.2013,39(4):300-304.
[2]胡书津.简明藏文文法[M].昆明:云南民族出版社,1988.
[3]Peter Hellwig. Dependency Unification Grammar[C]//Proceeding of Coling'86.1986.
[4]Marie-Catherine de Marne de,Christopher D.Manning[M].Stanford typed dependencies manual.2008.
[5]周明,黄昌宁.面向语料库标注的汉语依存体系的探讨[J].中文信息学报,1994,8(3):35-51.
[6]格桑居冕.实用藏文文法[M].成都:四川民族出版社,1987.
[7]华却才让,赵海兴.现代藏语依存句法标注初探[C].第十二届全国少数民族语言文字信息处理学术研讨会,2011.7.
[8]才让加.藏语语料库词语分类体系及标记集研究[J].中文信息学报,2009,23(4):146-148.
[9]Jason M.Eisner.Three new probabilistic models for dependency parsing:An exploration[C]//Proceedings of COLING,1996:340-345.
[10]Jiang Wenbin,Liu Qun.Dependency Parsing and Projection Based on Word Pair Classification[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.Uppsala,Sweden:[s.n.],2010:12-20.
[11]McDonald R,Crammer K,Pereira F.Online Largemargin Training of Dependency Parsers[C]//Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics.Stroudsburg,USA:Association for Computational Linguistics,2005:91-98.
[12]Collins M.A New Statistical Parser Based on Bigram Lexical Dependencies[C]//Proceedings of the 34th Annual Meeting on Association for Computational Linguistics.Stroudsburg, USA: Association for Computational Linguistics,1996:184-191.
猜你喜欢
客联(2022年2期)2022-04-29
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
大连民族大学学报(2021年2期)2021-07-16
西藏研究(2021年1期)2021-06-09
西藏艺术研究(2020年3期)2021-01-18
西藏艺术研究(2020年2期)2020-09-04
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
当代修辞学(2014年3期)2014-01-21
