
云计算资源管理中的预测模型综述
2013-09-10 01:17:12张飞飞吕智慧
计算机工程与设计 2013年9期
张飞飞,吴 杰,吕智慧
(复旦大学 计算机科学技术学院,上海200433)
0 引 言
云计算技术的不断发展,使得云计算能够灵活地、可扩展地、按需地为应用分配所需资源。然而,静态地为虚拟机分配物理资源可能会产生一些问题。如果根据应用的最高负载分配资源可能会导致资源利用率比较低,然而分配资源少了又将导致违反应用的服务等级协议 (SLA)。为了有效地管理资源,实现资源利用率最大化,云计算通常采用基于预测技术的资源管理方法。
目前,在云资源管理方法中存在很多种预测模型,这些模型各有优缺点及适用环境。本文将这些模型分为三大类,分别介绍了这些预测模型的特点,并列出了每种预测模型的主要特征。通过对这些模型的分析,我们给出了基于预测技术的动态云资源管理方法的一般流程。虽然这些模型在某些云环境中能够很好的进行预测,然而应用的多样化致使这些模型并不能适用于所有的情况,也就是说这些预测模型本身还存在一些不足之处。针对这些不足,本文从以下几方面展望了云计算预测模型的发展方向。
1 预测模型介绍
预测技术由来已久,也有一些比较成熟的预测模型。文献 [1]研究了一些短期预测模型,包括差分自回归移动平均模型 (ARIMA),自回归模型 (AR),霍尔特-温特斯指数平滑模型 (Holt-Winters exponential smoothing)。文献[2]通过采用自回归分数整合滑动平均 (FARIMA)过程同时提供短期预测和长期预测。文献 [2]提出一种全局方法进行长期预测。这些传统模型相对复杂,考虑到预测给系统带来的开销,云计算系统通常并不会直接采用这些模型。
随着云计算技术的发展,为了实现虚拟资源的有效管理,预测技术被引入到云资源管理中。目前大部分的预测模型都是基于时间序列分析。本文将预测模型分为三类:基础预测模型,基于反馈的预测模型和多时间序列预测模型。其中基础预测模型和基于反馈的预测模型是单时间序列的预测模型,其分类如图1所示。

图1 预测模型分类
下面分类介绍每个预测模型及其特点:
1.1 基础预测模型
文献 [3]提出一种预测方法,该方法主要用于云资源自动调整大小时应用负载的预测。这个方法采用了二阶自回归移动均值 (ARMA)模型过滤器,其表达式如下

式中:变量β和γ的值分别为0.8和0.15,λ (t)——t时刻负载值。这个算法是ARMA模型的简单应用,存在一些不足点。第一,原始数据未经处理。通常原始数据存在一些干扰数据,需经过预处理,将干扰数据过滤出去,这样有助于提高预测的准确度。第二,将变量β和γ赋值固定值会影响算法的灵活性,降低算法的适应能力。
文献 [4]采用指数平滑 (ES)方法预测请求访问速率,其模型如下

式中:T1——时间粒度,该模型预测T1时间之后的访问速率,即^Λik(t+T1),为上个样本数据Λik(t)和预测数据^Λik(t)的加权平均值,0<γik(t)<1。此模型通过重估计平滑因子γik(t)动态获得合适的平滑指数模型,其中γik(t)定义为平滑误差Aik(t)与绝对误差Eik(t)的比值,即γik(t)=Aik(t)/Eik(t)。在这个模型中,平滑因子的估计很重要,因为这个值直接影响到算法的准确性。
文献 [5]提出一种模型来预测系统在将来某时刻需要的物理机数量。这个预测模型基于自回归分析来进行预测,其模型如下

其中预测值m0为参数向量a与历史需求值mi(i<0)的内积,参数向量a可以通过最小二乘法获得。
以上3个模型都是通过历史数据直接建模并预测,没有考虑到负载模式的特点,这会使得预测模型的适用性受到限制,即在某些情况中预测准确度可能会降低。
文献 [6]提出了一个适用于周期性负载模式的模型,该模型如下

式中:T——负载周期,y(t)——负载值。这个模型包括两个部分,参数ak所在部分为周期预测,它是y值在周期T上的自回归。参数bj所在部分为局部调整,考虑到y(t)与紧跟在y(t)之前的值的相关性。参数n和m为这两个部分的阶。这个模型对周期性负载进行预测时准确度比较高,但是当负载不存在明显的周期性时,该预测模型无法保证其准确性。
文献 [7]提出了一种应用于云计算环境的可预测性弹性资源伸缩方案 (PRESS),该方案采用轻量级的信号处理与统计分析的方法对云环境中资源需求进行预测。该模型利用信号处理技术观察序列的特征,通过快速傅里叶转换计算负载的主频,设为fd,PRESS得到大小为Z的模式窗口,其中Z= (1/fd)×r,r为采样频率。将原始序列分为Q= W/Z 个模式窗口:P1= {l1,…,lz},P2={lz+1,…,l2Z},…,PQ= {l(Q-1)Z,…,lQZ}。PRESS评估所有窗口对Pi和Pj之间是否包含相似模式,如果所有模式窗口都相似,PRESS将所有窗口相同位置样本值的平均值作为预测窗口的值。如果负载没有相似模式,PRESS采用离散马尔科夫链进行短期预测。该预测模型考虑到了负载的模式,并针对不同的负载模式采用了不同的预测方法。
1.2 基于反馈的预测模型
尽管基础预测模型在某些云计算环境中能够满足系统需求,但是为了保证应用的SLA,也有一些预测模型会在预测出结果之后再进行一些工作,比如增加一个补偿值,或者是通过考虑反馈信息进一步完善预测模型的性能等。
文献 [8]为数据库即服务系统提出了一种动态资源分配架构 (DRAF)。在他们使用的预测模型中,时间序列被看作是趋势与噪声的组合,Pi,k(t)=Tri.k(t)+ei,k,其中Tri,k(t)表示趋势,ei,k表示噪声。Tri,k(t)通过自回归分析得到,ei,k认为是正态分布。趋势模式可以表示为Tri.k(t)=b0+b1t+b2t2。噪声用两个参数表示,均值μ和标准差σ。根据正态分布表,μ+1.96σ可以覆盖95%的噪音,所以ei,k=μ+1.96σ。为了减少因资源不足造成应用性能降低的情况,作为一种弥补手段,会在预测值之上增加一个补偿值。然而这样直接加上一个补偿值有时候可能造成资源的浪费。
文献 [9]提出了CloudScale系统,它采用在线资源需求预测和预测误差处理来实现云环境中自适应资源分配。资源需求预测经常存在高估或低估的情况。高估时可能会造成一些资源的浪费,但是应用的性能不会受到影响;然而,低估却会导致违反服务等级协议,因此该模型的重点在于消除低估误差。CloudScale采用在线的自适应的填补方法来解决低估误差。一种方法是在预测的需求之上再加上一个额外的补偿值。另一种方法是在系统运行过程中出现资源不足时,直接将其资源配额提高到做大,或者是通过因子a(a>1)逐步加大。这个模型提示我们预测模型可以通过有效的控制预测误差来提高本身的性能。
文献 [10]提出了一种虚拟资源控制系统AutoControl,在这个系统中,模型估算器输入过去资源分配信息和应用性能信息,得到应用将来的性能目标,然后优化器分配所需资源。对于每一个控制阶段,模型估算器重新计算线性模型。这个线性模型用来逼近应用的资源分配 (ua)与其性能 (ya)之间的量化关系。他们的关系可以表示如下
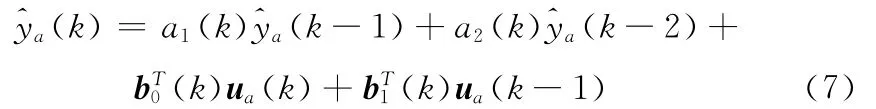
其中a1(k)和a2(k)描述了应用过去和当前性能之间的关系。参数向量b0(k)和b1(k)描述了应用当前性能和最近资源分配之间的关系。有了性能目标,优化器就可以进行所需资源的分配。这个模型充分结合了控制论的理论,应用将来资源需求量由应用的性能和过去资源分配情况共同决定。
1.3 多时间序列预测模型
在多时间序列预测中,模型不但考虑了同种资源的自相关性,同时考虑不同资源之间的交叉相关性。在某些情况下,考虑不同资源的交叉相关性能够提高预测模型的预测效果。
文献 [11]分别从微观和宏观的角度出发对数据中心资源的消耗进行预测。在微观的预测中使用了自回归方法,具体表示如下

式 中:X1j(t)——CPU 的 使 用,X2j(t)——内 存 的 使 用,ε1j(t),ε2j(t)——白噪声 WN (0,σ2)。
文献 [12]提出了应用于云计算环境的多时间序列模型,该模型用于虚拟机负载的特征描述和预测。该模型首先将虚拟机进行分组,然后进行预测。预测分3个步骤:首先,以不同时间粒度分析虚拟机负载在时间上的相关性和不同虚拟机在空间上的相关性,并决定最优时间间隔来建模;其次,从原先的分组中找出可预测的分组;最后,进行预测。该模型采用隐马尔科夫模型 (HMM)进行预测。估计出状态转换以及观察频率之后,给定时刻t的观察可以计算出在时刻t+l时观察概率ot+l
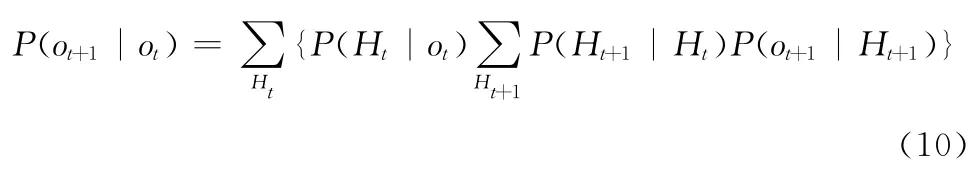
根据这个概率估计就可以预测在时刻t+l最可能的观察

下一个观察就代表了将会出现哪些组。为了提高预测的准确度,这个方法采用了一种综合负载时间相关性和空间相关性的聚类算法。
文献 [13]提出了一个在线系统 (ASAP)来预测云系统虚拟机需求,它采用两层模式进行建模和预测。第一层是多个子模型的自回归组合,在这个组合中,每个子预测模型的权重根据预测误差进行调整。这些子预测模型包括移动均值,自回归,神经网络等。第二层考虑到不同虚拟机之间的关系并利用这种关系来提高预测的健壮性,不同序列之间的相关性能够帮助消除噪声数据的干扰。设cov(t)ij表示资源类型i与它的第j个相关资源的协方差,则类型i在时刻t的需求为

2 预测模型的分析与比较
2.1 模型分类
本文将预测模型分为三类:基础预测模型,基于反馈的预测模型和多时间序列预测模型。经过对不同预测模型的分析发现,基于反馈的预测模型和多时间序列预测模型的核心都是基于基础预测模型实现的,同时多时间序列预测模型可以引入反馈信息的分析以提高其性能,所以多时间序列可以同时兼顾到基于反馈预测模型的优点。我们将这三类模型之间的关系表示如图2所示。
2.2 分析与比较
本节我们将分类对预测模型进行分析和比较,对于每种类型,采用不同的属性进行描述。
2.2.1 基础预测模型
表1列出了基础预测模型的主要特征。其核心方法是自回归,自回归方法是预测技术的基本方法且应用广泛。本文介绍的预测模型大部分是采用最小二乘法估计参数。对于ES模型,平滑因子γik(t)的评估直接影响这个模型的准确度。在这类模型中,PRESS[7]和稀疏自回归模型可以对周期性负载进行相对长期的预测,其它模型都是短期预测,对于长期预测无法保证预测的准确度。

图2 预测模型关系
2.2.2 基于反馈的预测模型
表2列出了基于反馈的预测模型的主要特征。为了保证服务等级协议 (SLA),避免因资源不足导致应用服务性能降低,最简单的一种方法就是在预测结果之上再加上一个额外的补偿值。这种方法相对简单,但是可能会造成资源的浪费。第二种方法就是根据应用的反馈信息,预测模型重新建模,估计模型参数,使得预测模型能够实时的响应应用的变化。
2.2.3 多时间序列预测模型
表3列出了多时间序列预测模型的主要特征。此类预测模型在建模时不但需要考虑同种资源的自相关性,同时考虑不同资源之间的交叉相关性。当系统中不同资源之间存在相关性时,多序列模型能够更好的反映出引起资源变化的因素,有助于提高预测的准确度。同时,采用资源间的交叉相关性能够帮助消除噪声数据对模型准确度的影响。
随着云计算技术的不断发展,动态资源供应已成为云计算环境不可或缺的一部分。为了实现资源的有效利用并保证服务的质量,几乎所有的资源供应方案都采用了预测技术。在应用预测模型的时候需要准确度与复杂性兼顾。通常准确度越高的模型复杂度相对越高,会给系统带来一定的开销,所以在设计与选择预测模型时应考虑云环境的需求,选择适用于它的预测模型。
2.3 基于预测的资源供应一般流程
根据上面的讨论,我们总结出云计算环境中资源供应方案通常包含以下几步:建模,预测,误差纠正,性能分析,重建模,如图3所示。

表1 基础预测模型的分析与比较

表2 基于反馈的预测模型的分析与比较

表3 多时间序列预测模型的分析与比较

图3 基于预测的资源供应框架
3 未来发展
我们介绍并分析了应用于云计算资源管理方法中的预测模型。为了更有效的辅助云计算资源管理,预测模型也随之发展与完善,从最基本的基础模型,到基于反馈的预测模型以及多时间序列预测模型。虽然预测模型得到了不断的进步与发展,其中仍有一些需解决的问题,这些问题可以从以下3个方面进行说明:
(1)误差纠正:很明显,预测模型的准确度直接影响了资源管理的有效性。为了实现资源利用率最大化,同时保证应用性能,云计算系统需准确地为应用分配所需的资源。资源分配的依据就是预测模型得到的预测值,所以高准确度的预测更有助于实现云计算资源管理的目标。在预测中,误差是不可避免,可以通过误差修正以提高预测模型的准确度。在基于反馈的预测模型中,一些模型就是利用了预测值与观察值之间的差值进行误差纠正,比如增加一个补偿值或是增大虚拟机资源配额。这些误差修正方法相对简单,而且本身也存在很多问题。比如,补偿值的大小如何确定,资源配额多大合适,以及何时进行误差纠正等等。如果有一个好的误差纠正方法,预测模型的准确度也将得到提高。
(2)应用性能保证:预测模型辅助云计算资源管理更好地管理与分配资源,然而在应用运行过程中应用资源不足的情况时有发生,所以我们并不能完全依赖预测模型。应用运行时可以通过应用的性能参数 (响应时间,吞吐量等)或是SLA指标观察应用当前运行状态,一旦监测到参数或指标不满足要求时,云资源管理应即刻做出反应。为了实现这一目的,有一些预测模型引入了控制论的方法。在这类模型中,实时地监测应用的运行状态,并在不满足要求时立刻做出响应。然而控制论方法在云计算资源管理中的应用还处在初期,有很大的研究空间。
(3)新型预测模型:目前很多的预测模型都是基于统计分析方法的,然而也存在一些其它的预测模型,例如文献 [14]中采用的基于遗传算法的预测模型,文献 [2]中采用的基于人工神经网络的预测模型以及文献 [7]中采用的马尔科夫链模型等等。对于预测技术,也许存在其它更好的方法来使得预测结果更准确,开销更小等,所以新型的预测模型是值得研究的。
4 结束语
云计算作为一种新型的计算模式受到了广泛关注。在工业界已有一些成功案例,比如Google公司的AppEngine,Microsoft公司的Azure,IBM公司的Blue Cloud,Amazon公司的EC2和S3等。云计算资源管理一直都是云计算的核心,是实现云计算灵活性,可伸缩性,资源共享等特征的基础。为了实现动态资源供应,云计算资源管理通常需要借助预测技术来实现。
本文分析与讨论了应用于云计算环境的预测模型,包括基础预测模型,基于反馈的预测模型和多时间序列预测模型,并在此基础上总结了云计算环境中动态资源供应方法的一般流程。我们可以看到预测模型从基础模型到基于反馈的预测模型及多时间序列预测模型,它一直都在发展与完善。然而这些模型中还是存在一些不足之处,我们从误差纠正,保证应用性能和发展新模型3个方面介绍了预测模型还需完善的地方。预测模型作为云计算资源管理的辅助手段,它的发展必将有助于云计算技术的进步。
[1]Taylor J W,de Menezes L M,McSharry P E.A comparison of univariate methods for forecasting electricity demand up to a day ahead [J].International Journal of Forecasting,2006,22(1):1-16.
[2]Sorjanmaa A,Hao J,Reyhani N,et al.Methodology for long-term prediction of time series [J].Neurocomputing,2007,70 (16-18):2861-2869.
[3]Roy N,Dubey A,Gokhale A.Efficient autoscaling in the cloud using predictive models for workload forecasting [C]//Washington,DC:IEEE 4th International Conference on Cloud Computing,2011:500-507.
[4]Ardagna D,Casolari S,Panicucci B.Flexible distributed capacity allocation and load redirect algorithms for cloud systems[C]//Washington,DC:IEEE 4th International Conference on Cloud Computing,2011:163-170.
[5]Guaenter B,Jain N, Williams C. Managing cost,performance,and reliability tradeoffs for energy-aware server provisioning [C]//Shanghai: Proceedings IEEE INFOCOM,2011:1332-1340.
[6]Chen G,He W,Liu J,et al.Energy-aware server provisioning and load dispatching for connection-intensive internet services [C]//Francisco,California:5th USENIX Symposium on Networked Systems Design and Implementation,2008:337-350.
[7]Gong Z,Gu X,Wilkes J.PRESS:Predictive elastic resource scaling for cloud systems [C]//Niagara Fall:International Conference on Network and Service Management,2010:9-16.
[8]Zhu J,Gao B,Wang Z,et al.A dynamic resource allocation algorithm for database-as-a-service [C]//Washington,DC:IEEE International Conference on Web Services,2011:564-571.
[9]Shen Z,Subbiah S,Gu X,et al.CloudScale:Elastic resource scaling for multi-tenant cloud systems [C]//Cascais,Portugal:2nd ACM Symposium on Cloud Computing,2011:1-14.
[10]Padala P,Hou K Y,Shin KG,et al.Automated control of multiple virtualized resources [C]//Nuremberg,Germany:ACM European Conference on Computer Systems,2009:13-26.
[11]Tan J,Dube P,Meng X,et al.Exploiting resource usage patterns for better utilization prediction [C]//Minneapolis,MN:31st International Conference on Distributed Computing Systems Workshops,2011:14-19.
[12]Khan A,Yan X,Tao S,et al.Workload characterization and prediction in the cloud:A multiple time series approach[C]//Hawaii:13th IEEE/IFIP Network Operations and Management Symposium,2012:1287-1294.
[13]Yexi J,Chang-shing P,Tao L,et al.ASAP:A self-adaptive prediction system for instant cloud resource demand provisioning [C]//Vancouver,BC:11th IEEE International Conference on Data Mining,2011:1104-1109.
[14]Luque C,María J,Ferrán V,et al.Time series forcasting by means of evolutionary algorithms [C]//Long Beach,IEEE International Conference on Parallel and Distributed Processing Symposium,2007:1-7.
猜你喜欢
商品与质量(2021年43期)2022-01-18 05:27:04
大众投资指南(2021年23期)2021-12-06 05:47:06
口腔护理用品工业(2021年4期)2021-11-02 08:23:02
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
中国特种设备安全(2019年1期)2019-03-13 01:06:26
建筑科技(2018年6期)2018-08-30 03:40:54
现代园艺(2018年2期)2018-03-15 08:01:03
中国交通信息化(2016年5期)2016-06-06 03:51:43
山东青年(2016年2期)2016-02-28 14:25:41
