
基于多知识源的语义搭配知识库的构建及应用
2013-09-08 10:18张仰森
计算机工程与设计 2013年6期
管 君,谢 玮,张仰森
(北京信息科技大学 计算机学院智能信息处理研究所,北京100192)
0 引 言
语义搭配的研究是研究文本语义的一种重要手段,目前其应用领域很多,本文主要通过构建语义搭配知识库来解决文本查错问题。我们曾在文献[2]中提出了利用 《知网》中的义原属性构建语义搭配词典来进行语义查错的方法,该方法取得了一定的实验效果,然而,其构建的语义搭配词典在语义转化过程中未进行选择,而是将所有词语搭配直接转化为语义搭配,这样得到的语义级搭配泛化过于严重,有可能会将原本不应转化为语义搭配的词语搭配转化为了语义搭配。
本文利用北京大学计算语言学研究所标注的 《人民日报》语料提取词语搭配,融合 《知网》中的义原属性与《语义词典》中的语义类属性形成义原类,提出了限散度的概念,以控制语义泛化词语的范围。通过计算限散度构建出词语级、半语义级及语义级三层体系结构的语义搭配知识库,最终应用该知识库实现中文文本的语义错误侦测。
1 语义知识库的设计
在中文文本语义查错时,将词语级搭配通过语义泛化为语义级搭配,可以弥补语料库较小这一缺陷。然而泛化后所涉及搭配的范围势必大于或者等于原本纯字词级搭配的范围,如果不加限制的将所有提取的词语级搭配全部直接泛化为语义级搭配,将会有许多未证实搭配的存在,从而出现本来不应转化的搭配而被转化为相应的语义级搭配的情况。为了解决这一问题,本文提出构建三层体系结构知识库并以限散度来确定可以泛化为语义级搭配的词语范围。
1.1 义原类知识库的构建
《知网》是一个被广泛应用于中文信息处理的词汇语义知识库,它提出的义原是用来表征最基本的、不易分割的意义的最小单位。《语义词典》也是一部面向中文信息处理的词汇语义知识库,《语义词典》中描述了每一个词语所属的语义类。
义原和语义类虽从属于不同的词典,但是它们在表述词语语义方面有许多相似之处。首先,它们都描述了词语的详细语义信息。其次,两者结构清晰并且类似,其中语义类体系是标准的树状结构;而义原为稍微复杂的网状结构,可以近似的看成树状结构,两者都准确的描述了不同词语的语义归属,不同词语分布于以语义类或者义原所形成的语义树上。因此,本文将义原与语义类结合,构建了一个义原类属性。
义原类由义原和语义类组成。对于义原部分,动词和形容词只取其词语概念即义项中的主义原,而名词需分别取其义项中的主义原以及5个常见的辅助义原:PartPosition、domain、whole、host和modifier义原;语义类部分为从 《语义词典》提取的语义类属性。由此构建的义原类表如图1所示。

图1 义原类表
其中,如动词 “掂斤播两”的义原类,由义项中的主义原 “计算”和语义类 “其他行为”组成;名词 “滇红”由其主义原和5个辅助义原加语义类构成,其中若义项中没有我们选取的辅助义原或该词语在 《语义词典》中没有对应的语义类,则以 “-”替代。
1.2 搭配知识库的层次结构体系
本搭配知识库分为三层,12个子库。
第一层为字词级搭配库,该层搭配是由北京大学的《人民日报》语料根据相应的提取规则提取而来,由名动(NV)、动名 (VN)、形名 (AN)3个子库构成;
第二层为半语义级搭配库,由名动转义动词 (NV_V)、名动转义名词 (N_NV)、动名转义动词 (V_VN)、动名转义名词 (VN_N)、形名转义形容词 (A_AN)和形名转义名词 (AN_N)6个子库构成;
第三层为完全语义级搭配库,由名动全义原类 (N_NV_V)、动名全义原类 (V_VN_N)和形名全义原类(A_AN_N)3个子库构成。
整个搭配知识库的体系结构如图2所示。

图2 搭配知识库的体系结构
1.3 限散度的定义
很多研究者越来越认识到搭配对自然语言处理的作用,而搭配的语义知识存储是对搭配的最有效存储。然而,是不是所有词都适合转换为相应的语义知识呢?答案显然是否定的。比如 “戴+帽子”这个搭配,转化为相应的义原类为:“穿戴 身体活动+衣物 头 人---衣物”,然而 “佩带”、“披挂”等词也可以转化为 “穿戴 身体活动”,而它们显然不能与帽子搭配,由此可见,如果不加任何限制的将词语搭配转化为语义级搭配,将会出现很多错误搭配被误判为正常搭配的情况,导致召回率较低。
因此,本文提出限散度的概念,以限定可以转化为语义级搭配的词的范围。
定义1 可以与词语j搭配且与词语i同义原的词语,同所有与i义原相同的词语的比值,称为限散度。
限散度公式如式 (1)和式 (2)所示

(其中i为被转化词;j为i的搭配词)

其中,SUMi为人民日报语料中与i义原类相同的词语的总数;为人民日报中,所有与j搭配、且义原类与i的义原类相同的搭配的总数。若W=1,则证明所有与i的义原类相同的词都可以与j搭配;W值越接近1,则表示用该语义搭配代替词语搭配的准确率越高;反之,则表示与该词语i同义原的词语大部分不能与j搭配。
2 语义知识库的构建
2.1 字词级搭配库的构建
本文选用2000年12个月的 《人民日报》标注语料为训练语料库,根据大量观察和统计,结合汉语的语法规律和特点,制定出动名、名动和形名搭配的提取规则。其规则如下:
动名、名动搭配规则[2]:
规则1:若名词位于当前动词之后,提取与该动词距离最远的名词,作为其搭配名词;
规则2:若名词位于当前动词之前,提取与该动词距离最近的名词,作为其搭配名词。
规则3:在规则1、2的前提下,若名词之间有连词或其它标识并列关系的词语或标点,如 “和”、“并且”,则将这几个并列的名词分别抽取出来作为与该动词搭配的名词。
形名搭配规则:
规则1:对于当前形容词,若同时存在前名词与后名词,取后名词为搭配词;
规则2:对于当前形容词,若只存在前名词,则取距离该形容词最近的前名词为搭配词;
规则3:对于当前形容词,若该形容词后面为 “的”,则取 “的”后面连续名词的最后一个名词为搭配词;否则,则取距离形容词最近的一个名词为搭配词;
规则4:对于规则2、3,若形容词之间有连词或其它标识并列关系的词语或标点,如 “和”、“并且”,则分别取每个形容词与名词相搭配。
根据以上规则,提取的搭配如图3所示。
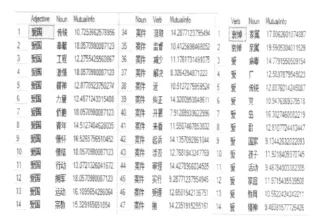
图3 词语级搭配库
2.2 半语义级搭配库的构建
半语义级搭配库,转化方法以动名搭配为例。先以动词为转化词,名词为搭配词进行半语义级的转化,然后根据限散度公式计算限散值。由于语料库规模问题,抽取的搭配只是所有词语搭配很小的一部分,所以导致W值较小,因此本文选取0.1为阈值,大于0.1的搭配,将其转化为动名转义动词 (V_VN)的半语义知识库。之后再将动词作为搭配词、名词为转化词,重复以上过程,提取动名转义名词 (VN_N)的半语义级知识库。
提取的半语义级搭配库如图4所示。

图4 半语义级搭配库
2.3 语义级搭配库的构建
同样以动名搭配为例。由于半语义级搭配已经将其中一个词转化为义原类,所以语义级搭配只需要转化另一半即可,即将已转化为义原类的词看做搭配词,未转化的词作为转化词,同样选取0.1为阈值,转化为语义级搭配库(N_NV_V),提取的语义级搭配库如图5所示。
2.4 语义知识库的构建
根据查错算法的需要,为了降低算法的重复率,本文将已转化为语义级和半语义级的搭配分别从半语义级和词语级搭配库中删除,得到最终的语义知识库。
3 语义错误自动查错算法及实现
在三层语义搭配知识库的基础上,设计语义错误自动查错算法见算法1。
算法1
步骤1 利用分词模块将实际测试语料进行标注。
步骤2 按照名动、动名、形名的提取规则,文本逐句扫描,提取搭配对;
步骤3 将提取的搭配转化为全义原类搭配,查找知识库中的语义级搭配库,如找到该搭配,则此搭配正确,否则,转入步骤4;
步骤4 将搭配分别转化为半义原类搭配库1(前词转化)和半义原类搭配库2(后词转化),查找知识库中的半语义级搭配库,如找到,则该搭配正确,否则,转入步骤5;
步骤5 查找知识库中的词语级搭配库,如找到,则该搭配正确,否则,该搭配错误,加入错误列表wronglist;
步骤6 判断是否为最后一句,如果是则转入步骤7;否则,转入步骤2;
步骤7 将wronglist依次读出并标红,转入步骤8;
步骤8 结束。

图5 语义级搭配库
4 实验结果与分析
根据上文提出的文本语义错误查错算法,本文从小学生语文病句题目中选取了324个病句作为测试语料,其中除了56个语义搭配错误外,还包括了字词级和语法级的错误。我们利用 Visual Studio 2010和SQL Server2005开发了一个智能信息处理平台,启动语义查错功能,得到的实验结果如图6所示,其中错误词语用红色加粗标识。
通过对实验结果进行统计,我们得到如表1所示的统计结果。
有人曾只使用 《知网》,且未使用分层结构筛选可以进行语义转化的词语,其查错结果为:召回率35%,精确率82.3%。通过对比发现,本方法在错误的召回率方面有较大提高,精准率上稍有下降。

图6 实验结果

表1 实验结果统计
通过对实验结果分析,造成精确率低的原因主要有两个:
(1)知识库较小,且涉及领域主要为政治类,较为单一;
(2)分词软件标注错误。
下面,我通过几个例句来详细分析。
例4:“六一”节那天,学生都穿着鲜艳的衣服和红领巾,参加庆祝活动。
分词结果:六一/m ”/w 节/n 那天/t,/w 学生/n 都/d 穿/v着/uz鲜艳/a 的/uj衣服/n 和/c 红领巾/n ,/w 参加/v 庆祝/vn活动/vn。/w
其中,“学生 穿”其实在日常生活中是一个较为常用的搭配,然而,在政治类语料中,此搭配较少,结果就导致 “学生 穿”被标红,而 “鲜艳 衣服”也是这个原因。
例5:公园新设了由两个英国援建的游乐项目。
分词结果:公园/n 新/d 设/v 了/ul由/p 两/n个/q 英国/ns援建/v 的/uj游乐/vn项目/n 。/w
其中,“两”本来应该为数词,而在此处却被标记为名词,所以造成 “设”和 “援建”被标红。
另外,提取搭配的规则还较为粗糙,搭配库的提取方法还有待进一步细化。
尽管如此,我们仍可以看出,义原类及其构建的三层结构语义知识库可以用于文本查错,同时,它也为今后语义错误侦测的研究提出了一个可行的方向。
5 结束语
本文从文本查错应用出发,结合语义学知识,详细介绍了义原类及三层结构知识库的构建,利用该知识库实现的文本查错算法,取得了较好的实验效果。今后会继续扩大语料库的规模与范围,使其能够涵盖更多的领域。另外,对于复合语句或句子成分残缺的语句,因为句子结构较复杂,会影响到查错的准确率,因此,加强句法分析的研究将是今后文本错误侦测工作的一项重要内容。
:
[1]LI Jingning.The semantics collocation theory and english teaching [J].Science & Technology Information,2010 (36):150(in Chinese).[李经宁.浅析语义学的搭配理论与英语教学[J].科技信息,2010 (36):150.]
[2]GUO Chong,ZHANG Yangsen.Study of semantic automatic error-detecting for Chinese text based on sememe matching of HowNet.Computer Engineering and Design,2010,31 (17):3924-3928 (in Chinese).[郭充,张仰森.基于 《知网》义原搭配的中文文本语义级自动查错研究 [J].计算机工程与设计,2010,31 (17):3924-3928.]
[3]ZHENG Fengqiang,LIN Lei,LIU Bingquan,et al.A research on the application of HowNet in named entity recognition [J].Journal of Chinese Information Processing,2008,22 (5):97-101(in Chinese).[郑逢强,林磊,刘秉权,等.《知网》在命名实体识别中的应用研究 [J].中文信息学报,2008,22(5):97-101.]
[4]WU Yunfang,JIN Peng,GUO Tao.Coarse-grained word sense disambiguation using features described in the lexicon [J].Journal of Chinese Information Processing,2007,21 (2):3-8(in Chinese).[吴云芳,金澎,郭涛.基于词典属性特征的粗粒度词义消歧 [J].中文信息学报,2007,21 (2):3-8.]
[5]WANG Xueling.On the correlation between generative semantics and structuralism linguistics [J].Journal of Jilin Agricultural Science and Technology College,2009,18 (1):88-89 (in Chinese).[王雪玲.生成语义学与结构主义语言学发展的关联性研究 [J].吉林农业科技学院学报,2009,18 (1):88-89.]
[6]WANG Suge,YANG Junling,ZHANG Wu.Automatic acquisition of chinese collocation [J].Journal of Chinese Information Processing,2006,20 (6):31-37 (in Chinese).[王素格,杨军玲,张武.自动获取汉语词语搭配 [J].中文信息学报,2006,20 (6):31-37.]
[7]YANG Shouxun.Machine learning for collocation identification[C]//Beijing:IEEE International Conference on Natural Language Processing and Knowledge Engineering,2003:315-320.
[8]DANG H T.The role of semantic roles in disambiguating verb senses [C]//Proceedings of the 43th Annual Meeting of the ACL,2005.
[9]CHEN Jia,LUO Zhensheng.An approach to Chinese word sense disambiguation based on collocation [J].Microcomputer Information,2008,24 (3):187-188 (in Chinese). [陈佳,罗振声.一种基于语义搭配的汉语词义消歧方法 [J].微计算机信息.2008,24 (3):187-188.]
[10]TANG Yi,ZHOU Changle,LIAN Ruiting.Chinese semantic dependency analysis using HowNet [J].Mind and Computation,2010,4 (2):109-116 (in Chinese). [唐怡,周昌乐,练睿婷.基于HowNet的中文语义依存分析 [J].心智与计算,2010,4 (2):109-116.]
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
小天使·一年级语数英综合(2020年4期)2020-12-16
开放教育研究(2020年2期)2020-03-31
制造技术与机床(2019年6期)2019-06-25
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
中国交通信息化(2016年9期)2016-06-06
长江学术(2016年4期)2016-03-11
图书馆研究(2015年5期)2015-12-07
传奇故事(破茧成蝶)(2015年7期)2015-02-28
