
语音情感特征的提取与分析
2013-09-03 08:53杨丽萍
实验室研究与探索 2013年7期
王 薇, 杨丽萍, 魏 丽, 刘 艳
(1.长春大学计算机科学技术学院,吉林 长春130022;2.吉林财经大学信息经济学院,吉林长春130122)
0 引言
语音是人类用来进行相互交流的重要工具之一,承载了丰富的情感信息,是人们用来表达自己思想活动及情感变化的一种重要媒介。语音信号处理是研究用数字信号处理技术对语音信号进行处理的一门学科,是一门交叉学科[1]。语音信号的各种分析和处理技术(时域频域处理、同态处理、线性预测分析、矢量量化、隐马尔可夫模型技术)、语音信号的各种处理及应用(基音提取及共振峰估计、波形编码、声码器、语音合成、语音识别、说话人识别及语音增强)等涉及知识点比较多[2]。其处理目的主要有两方面,一方面是为了高效地传输或储存语音信号信息而进行的语音信号重要特征参数的提取;另一方面是要通过对获取的语音特征参数进行某些运算处理,以达到某种用途的要求。例如对说话人的心理识别、辅助心理治疗、情感语音合成、语音情感识别等。
语音情感识别(Speech Emotion Recognition,SER)是指计算机自动识别输入语音的情感状态[3],即利用计算机分析特定说话人的情感状态及变化,进而确定其内心情绪或思想活动,实现人机之间更自然更智能化的交互[4]。语音情感识别与传统的语音识别不同,传统的语音识别侧重点是对说话者表达的语音词汇的正确识别,而忽略语音信号中包含的情感因素;而语音情感识别的侧重点在于说话者情感类别的确定,而忽略语音信号对应的正确词汇选择。
近几年,语音情感识别已成为国内外信号处理及人工智能等多个领域的研究热点,越来越受到研究者的广泛关注。早在20世纪90年代,国外先后有一些大学及研究机构开始了语音情感研究,并取得了一定的成果。国内对语音情感研究还处于一个起步阶段,针对汉语语音情感的研究还需结合我国汉语语言学特征、民族特征及情感表达方式,进行进一步深入研究。
语音情感的正确识别对于航空航天、E-Learning教学[5]、医疗、通信服务等行业的相关人员更好地开展工作具有重大的实际意义。同时可以使目前基于逻辑推理系统的计算机感知人类的情感变化,减少人与计算机之间的隔阂,形成一种真正意义上的人机交互系统。
1 情感语音库的选择
1.1 语音情感分类
语音情感分类在心理学或工程研究中都没有一个统一的分类标准[6]。根据Scherer的观点,人类声音中蕴含的情感信息,受到无意识的心理状态变化的影响,以及社会文化导致的有意识的说话习惯的控制[7]。要进行语音情感分析,首先需要对人类情感类型进行划分。目前从心理学的角度研究情感分类,主要有基本情绪论和维度空间论两种[8]。美国当代著名情绪心理学家普卢契克根据大量的研究提出了情绪理论。他认为有八种基本情绪(primary-motion):恐惧(fear)、惊讶(surprise)、悲痛(sadness)、厌恶(disgust)、愤怒(anger)、期待 (anticipation)、快乐 (joy)和接受(acceptance);并指出基本情绪可以由两种或三种混合产生复合情绪。如,忌妒是由接受、愤怒和恐惧混合而成的情绪,焦虑是由恐惧、悲痛和愤怒组合而成的情绪。
维度空间论主要分为三维理论和四维理论。德国心理学家冯特提出的三维理论认为情绪是由三个维度组成的,即愉快-不愉快;激动-平静;紧张-松弛。每一种具体情绪分布在三个维度两极之间不同的位置上。他的这种看法为情绪划分的维度理论奠定了基础。20世纪50年代,施洛伯格根据面部表情的研究提出由愉快-不愉快;注意-拒绝和激活水平三个维度建立的三维模式图,其三维模式图长轴为快乐维度,短轴为注意维度,垂直于椭圆面的轴则是激活水平的强度维度,三个不同水平的整合可以得到各种情绪。20世纪60年代末,普拉切克提出,情绪具有强度、相似性和两极性等三个维度,并用一个倒锥体来说明三个维度之间的关系。顶部是八种最强烈的基本情绪:悲痛、恐惧、惊奇、接受、狂喜、狂怒、警惕、憎恨,每一类情绪中都有一些性质相似、强度依次递减的情绪,如厌恶、厌烦,哀伤、忧郁。美国心理学家伊扎德提出情绪四维理论,他认为情绪有愉快、紧张、激动、确信等四个维度。
西南大学黄希庭认为若抛开情绪所指的具体对象,仅就情绪体验的性质来看,可从以下四方面进行分析:强度、紧张度、快感度、复杂度。四种基本情绪,也就是原始情绪分为喜、怒、哀、惧。在语音情感分析过程中,若提取的语音情感特征信息反映的情感维数越多,就越能更好地区分说话者的内心情感。
1.2 情感语音数据库
对于情感语音的研究都是基于特定的语音库,比如英语、俄语、丹麦语等[9]。情感语音数据库是语音情感识别模型的建立和语音情感识别过程的基础。只有建立了真实、有效、完整的情感语音数据库,才可能得到确实可靠的数据基础,以此构建语音情感识别模型。
到目前为止,国内外还没有统一的标准的语音情感数据库可用[10]。大多数的研究者都是自建符合自己研究要求的情感语音库。目前,自建情感语音库主要采用自然录音法、引导录音法或音像剪辑法三种。
(1)自然录音法。主要是指语音信号采集者在日常生活中对说话人的语音进行采集。由于该方法是在说话人不知情的情况下进行,所以说话人的情感特征相对会更真实有效。但该方法也存在一定的缺点,例如采集环境不同,背景声音有可能对说话人的语音信号产生干扰;说话人的语句不能完全和样本语句匹配;说话人的情感变化及确定是由语音信号采集者单方判断,与说话人的真实情感有一定的误差。
(2)引导录音法。要事先确定所研究的语音情感分类、录制语音所采用的脚本语句、情感语音说话人的选择、情感语音的各种情感引导环境及方式等。其中情感语音对象的选择应考虑性别、年龄、说话标准程度、情绪是否容易被引导、语言表现能力等因素。
(3)音像剪辑法。主要是对现有的音像制品根据研究需要截取部分语句组成情感语音数据库。但由于截取语句来源于不同的音像制品,截取的语音信号大多包含着不同的背景音乐及其他声音,这使情感语音信号的后期具有较大的工作量。
本文采用的情感语音数据库来源于北京航空航天大学电子信息工程学院毛峡教授课程组所建立的情感语音数据库[11]。
该情感语音数据库主要采用录音法、剪辑法两种方法相结合建立[12]。数据库中包含样本语句类别20种,主要采用情感中性的语句作为样本语句,例如:“今天是星期天”,“他就快来了”,“明天我要搬家了”,“昨天晚上我做了一个梦”等。情感语音数据库共包含悲伤、愤怒、惊奇、恐惧、喜悦、厌恶、平静七种情感,录音人选择男、女各1名用不同情感对样本语句进行录音。该语音数据库为双声道的wav格式文件,样本语句采样频率为11.025 kHz,量化精度为16 bit,适合于对特定人的基本语音情感分析研究。
2 语音信号的特征分析
2.1 语音特征分类
语音是由人的发声器官发出的一种声波,它具有音色、音调、音强和音长四个特征。
(1)音色。音色又叫“音质”。指的是声音的特色,是一种声音区别于另一种声音的基本特征。音色的差别主要决定于物体振动所形成的声波波纹的曲线形式不同。具体来说,音色的类型是由振源的特性和共振峰的形状共同决定的。
(2)音调。音调也叫音高。指的是声音的高低,主要取决于声源振动的频率,同时也与声音强度有关。对一定强度的纯音,音调随频率的升降而升降;对一定频率的纯音、低频纯音的音调随声强增加而下降,高频纯音的音调却随强度增加而上升。成年男人的声带长而厚,所以音调低;成年女人的声带短而薄,所以音调高。老人语音的音调低,小孩语音的音调高。
(3)音强。音强是指声音的强弱,它由声波的振动幅度决定。
(4)音长。音长是指声音的长短,它取决于发音时间的长短。
2.2 语音信号的特征
语音信号的特征主要分为韵律特征和音质特征。韵律特征是指语音中除音质特征外的音高、音长和音强方面的变化。韵律特征又叫“超音质特征”或“超音段特征”,指的是语音中除音质特征之外的音高、音长和音强方面的变化。语音的韵律和音质特征均表现出良好的情感区分能力[13],如何选取有效的语音特征是情感识别过程中的重要环节[14]。
语音的韵律特征主要有基音频率、短时能量、短时平均能量、短时自相关、短时平均幅度差、短时过零率等。
语音的音质特征主要有共振峰、长时平均频谱、谐波噪声比、频谱中心矩、语谱等。
(1)基音频率。是声门脉冲的间隔,是元音语音的特性。从语音的时间波型中可观察到一些语音信号具有明显的周期,这些周期对应的即为声带振动频率,称之为基音频率。
(2)短时能量。是一个度量语音信号幅度值变化的函数。函数表达式为:
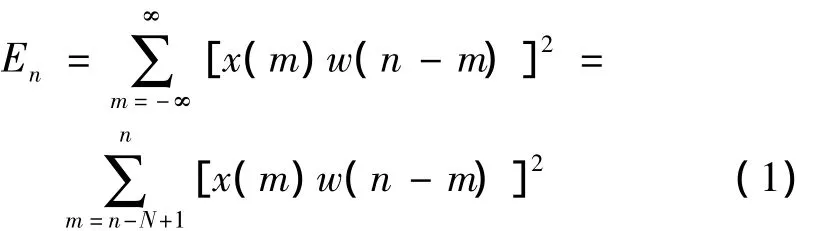
式中:x(m)为某一帧语音波形时域信号;w为窗口函数;N为窗长。加窗可采用矩形窗或汉明窗进行处理,得出语音信号的每一帧。当采用矩形窗时,公式(1)可简化为:
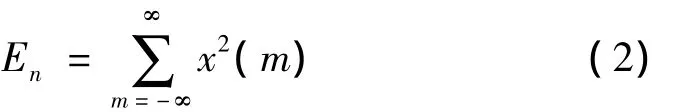
(3)短时平均能量。也是一帧语音信号能量大小的表征,它避免了短时能量对于高电平非常敏感的问题。短时平均能量的表达式为:
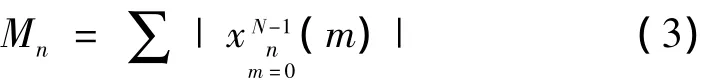
(4)短时自相关。可用于求解语音波形序列的基音周期。其计算公式如下:
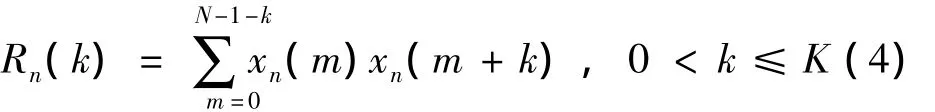
(5)短时平均幅度差(AMDF)。能代替自相关函数做语音分析,如果信号是完全的周期信号,则相距为周期整数倍的采样点上的幅值是相等的,差值为零[15]。其公式如下:
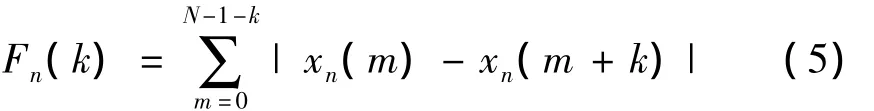
(6)短时过零率。主要用来反映信号的频谱特性。当离散时间信号相邻两个样点的正负号相异时,信号的时间波形穿过了零电平的横轴。定义公式如下:
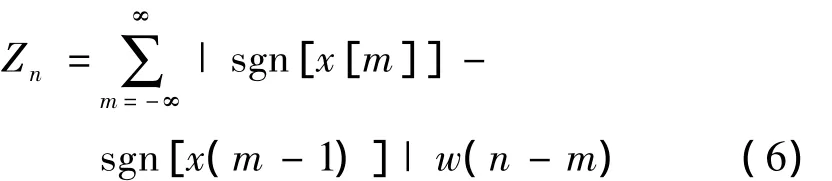
(7)共振峰。是指在声音的频谱中能量相对集中的一些区域,共振峰不但是音质的决定因素,而且反映了声道(共振腔)的物理特征。声音在经过共振腔时,受到腔体的滤波作用,使得频域中不同频率的能量重新分配,一部分因为共振腔的共振作用得到强化,另一部分则受到衰减,得到强化的那些频率在时频分析的语图上表现为浓重的黑色条纹。由于能量分布不均匀,强的部分犹如山峰一般,故而称之为共振峰。
(8)长时平均频谱。是利用快速傅立叶变换FFT方法算出的每帧的短时频谱的长时平均值。FFT功率谱中可以直观反映出基音周期以及各谐波能量、频率、形态和它们相互组合关系,同时能反映出谐波能量较高的尖峰所对应的声道共振峰[16]。
3 语音情感特征分析
说话人的情感特征在其语音信号中会有所体现,而不同的情感变化会在不同的语音特征值中表现出来,可以是一种典型的语音特征值,也可以是特征值组合,语音特征值对于语音情感识别的贡献均不相同。
由于受声门激励等影响,对于频率为800 Hz以上的语音信号其振幅有所下降,一般对于语音信号进行分析时需要进行预加重处理。在Matlab中主要采用filter([1 -0.937 5],1,x)函数调用一维数字滤波器对语音信号进行高频增强处理。
对于预处理后的语音信号需要进行加窗分帧处理,这里采用Matlab中的Hamming(N)函数进行汉明窗加窗处理,其中N为窗口长度。
3.1 能量分析
语音信号的能量特征主要表现在声音的大小上。实验以“啊,你可真伟大呀”语句为样本,从情感语音数据库中女性语音文件中选择悲伤、愤怒、惊奇、恐惧、平静、喜悦、厌恶七种情感语音数据,经预处理后进行短时平均能量分析,结果如图1所示,对应的七种情感短时平均能量的均值变化如图2所示。可见人在喜悦、厌恶及愤怒时讲话声音较高,声音振幅较大,其平均能量值较大,而悲伤时声音较低,声音振幅较小,平均能量值也相对较低,平静时平均能量值略高于悲伤平均能量。但对于惊奇,恐惧等情感的区别不是很明显。因此短时平均能量可用于悲伤、平静与喜悦、厌恶情感的判断因素之一。
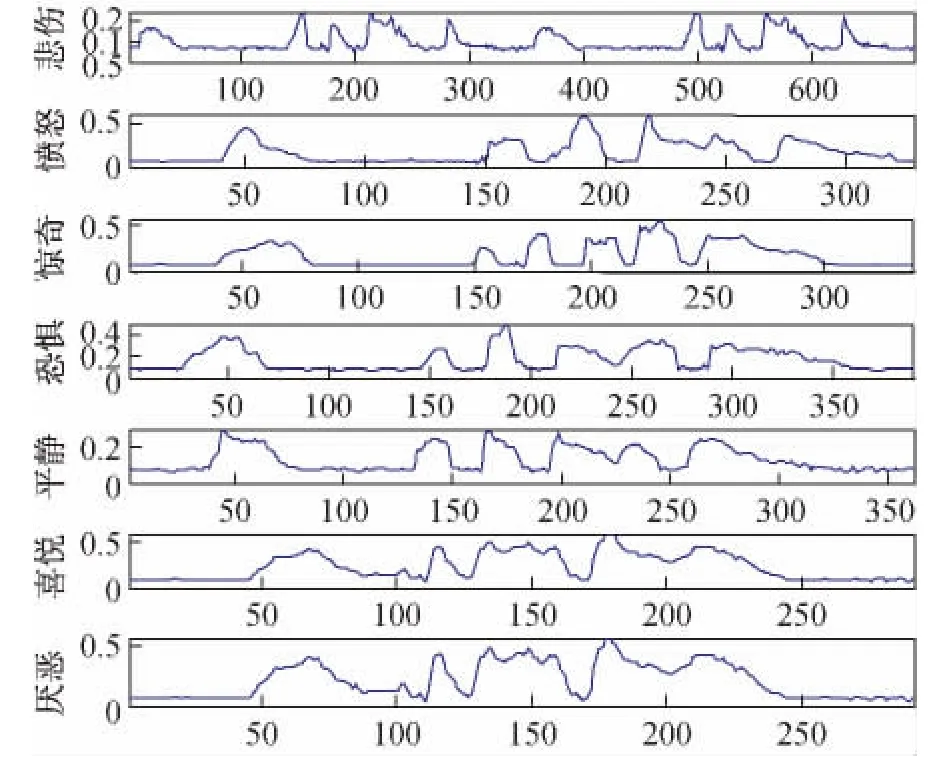
图1 短时能量图
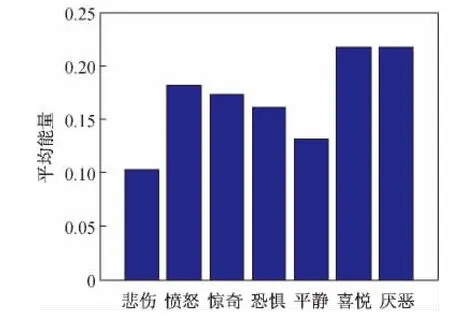
图2 短时能量平均值对比图
3.2 基频分析
基频即为基音频率,也是反映语音情感信息的重要特征之一。基频分析可以包括基频范围、基频平均值、基频包络等内容。由于语音信号中存在着抖动点,所以实验利用倒谱方法逐帧求出基频后,进行了中值滤波和线性平滑处理,而且基频平均值为情感识别的常用特征值之一。实验结果表明当说话人情感处于悲伤状态时,语音基频均值是最低。平静状态时,基频均值居中。惊奇、喜悦、愤怒时,基频均值是较高,而愤怒时,基频均值为最高。这些均值的变化主要是由于说话人在这些情感状态下,多采用重音或声音上扬方式发音,基频在重音处或声音上扬处易发生突变。
3.3 共振峰分析
不同情感状态下,说话人的发音共振峰位置是不同的,所以将共振峰作为识别语音情感是有必要的。为了很好地反映出说话人语音共振峰特征,可以采用线性预测倒谱系数(LPCC)。LPCC的主要优点是提取出了语音产生过程的激励信息,该信息主要反映声道特性[17]。实验采用七种不同情感的同一样本语句进行共振峰分析,喜悦、愤怒的共振峰值有所升高,而悲伤情感状态下其共振峰值是呈明显下降趋势的。
4 结语
从悲伤、愤怒、惊奇、恐惧、平静、喜悦、厌恶七种情感语音数据出发,提取能够反映情感语音的能量特征、基频特征与共振峰特征参数进行比对分析,实验结果表明这三种特征值对于悲伤、平静情感与喜悦、愤怒、惊奇、恐惧、喜悦、厌恶情感的区分是较为明显的,但对于悲伤与平静情感的区分、愤怒与惊奇等情感的区分还需要多个特征参数不同的贡献值来确定。同时,不同说话人在不同环境下用自己语音情感表达情感的方式不同,而且人的情感也是动态连续变化的,在同一语音样本中,会承载着说话人多种情感变化的情感语音特征。让计算机能真正识别说话人的实时情感变化还需要一个较为漫长的研究过程。
[1] 胡 航.语音信号处理[M],哈尔滨:哈尔滨工业大学出版社,2000.
[2] 刘卫东,孟晓静,王艳芬.语音信号处理实验教学研究探索[J],实验室研究与探索,2008,27(04):72-74.
[3] 赵腊生,张 强,魏小鹏.语音情感识别研究进展[J],计算机应用研究,2009,26(2):428-432.
[4] 王海鹤,陆捷荣,詹永照,等.基于增量流形学习的语音情感特征降维方法[J],计算机工程,2011,37(12):144-146.
[5] 张 利,张永皋.基于语音情感分析的E-Learning研究[J],软件导刊,2011,10(6):148-150.
[6] 曾光菊.基于粗神经网络的语音情感识别[J],四川理工学院学报(自然科学版),2011,24(4):472-476.
[7] 黄程韦,赵 艳.实用语音情感的特征分析与识别的研究[J],电子与信息学报,2011,33(1):112-116.
[8] 章国宝,宋清华,费树岷,等.语音情感识别研究[J],计算机技术与发展,2009,19(1):92-96.
[9] 张立华,杨莹春.情感语音变化规律的特征分析[J],清华大学学报(自然科学版),2008,48(S1):652-657.
[10] 张石清,赵知劲,雷必成,等.结合音质特征和韵律特征的语音情感识别[J],电路与系统学报,2009,14(4):120-123.
[11] 毛 峡,陈立江.语音情感信息的提取及建模方法[P],中国专利:CN101261832,2008-4-21.
[12] Xiao Mao,Lijiang Chen.Speech Emotion Recognition Based on Parametric Filter and Fractal Dimensional[J],IEICE TRANSACTIONSON INFORMATION AND SYSTEMS(SCIE Index,IF:0.396),2010,E93-D(8):2324-2326.
[13] 韩文静,李海峰.基于韵律语段的语音情感识别方法研究[J],清华大学学报(自然科学版),2009,49(S1):1363-1368.
[14] 罗宪华,杨大利,徐明星.面向非特定人的语音情感识别特征研究[J].北京住处科技大学学报,2011,26(2):72-76.
[15] 赵 力.语音信号处理[M].2版.北京:机械工业出版社,2009.
[16] 庄 琳.利用长时平均FFT功率谱进行话者识别[J].山西警官高等专科学校学报,2011,19(1):80-82.
[17] 胡 洋,蒲南红,吴黎慧,等.基于HMM和ANN的语音情感识别研究[J].电子测试,2011(8):33-35.
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27
山东交通科技(2020年2期)2020-08-13
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
知识经济·中国直销(2018年12期)2018-12-29
小说界(2018年5期)2018-11-26
当代陕西(2018年12期)2018-08-04
纺织科学研究(2017年4期)2017-05-17
