
基于相似度聚类分析的动态背景建模与减除
2013-08-16 07:26张国家左敦稳黎向锋史晨红
机械设计与制造工程 2013年8期
张国家,左敦稳,黎向锋,史晨红
(南京航空航天大学机电学院,江苏南京 210016)
据报道[1],手势识别技术在军事上的应用已取得突破性进展,美国科学家研究的手势识别技术已能让无人机识别76%的航空母舰上工作人员的手势,通过手势控制无人机已成为趋势。良好的前景检测是精确手势识别的基础,已有众多学者在该领域付出辛勤劳动。目前,前景检测主要采用背景建模的方法,其中又以基于区域技术和基于像素技术为主。Marko Heikkila和 Shengping Zhang等人[2-3]采用基于区域技术,依据像素的邻域、纹理、时空结构等特征进行前景目标检测,取得了较好的效果,但阴影问题并未得到很好的解决。与基于区域技术相比,Stauffer和Grimson提出的高斯混合模型(GMM)是典型的基于像素技术,其在算法鲁棒性和约束条件之间做了很好的折中。自GMM模型被提出后,已有众多学者对其进行了改进,例如TLGMM[4]、SKMGM[5]、SEMGMM[6]和 ADGMM[7]等。这些改进策略主要是为了改善检测效果,降低算法的时间和空间复杂度。发展至今,高斯混合模型已成为背景建模最常用的一个标准算法,但其仍然难以满足实时性要求。基于像素技术常见的还有核密度估计等[8-10],其检测的准确度虽较高,但时间和空间上的复杂度也较高[11]。为了获得一种准确度好、时间和空间上复杂度低的背景建模技术,受码本技术(CodeBook)的启发,本文首先基于像素的色度和亮度信息,提出一种融合像素色度和亮度信息的相似度理论。然后应用该相似度理论建立相似像素评价标准。最后在此评价标准基础上对像素时间序列进行聚类分析,建立贴合实际的背景模型。
1 融合亮度和色度信息的相似度理论
1.1 YCbCr色彩空间分层分析
YCbCr是数字视频中常用的色彩模型,在该模型中,亮度信息被单独存储在Y中,色度信息被存储在Cb和Cr中,Cb表示绿色分量相对参考值,Cr表示红色分量相对参考值。因为亮度和色度信息相互独立,本文将YCbCr模型下的像素通道信息分成两层,对亮度和色度信息分别进行处理。如果用 Pt-1(xi,t-1,yj,t-1) = (Yt-1,Cbt-1,Crt-1) 和Pt(xi,t,yj,t)=(Yt,Cbt,Crt) 分别表示在同一像素位置(i,j)处,连续相邻时刻(t-1)和t时的像素各通道值,则ΔY=|Yt-Yt-1|表示不同时刻像素亮度差异。为了建立融合亮度信息的相似度理论,需要对ΔY值进行归一化处理。YCbCr模型数据可以是双精度类型,也可以是无符号整型。对于不同的数据类型的ΔY的最大差值ΔYmax不同,归一化所乘的权值也不同。对于8位3通道类型图像,YCbCr数据为无符号整形,Y值的范围是[16,235],对 ΔY 进行归一化处理得 Y= ΔY/ΔYmax,即Y=ΔY/219。

在YCbCr色彩模型中,由于亮度和色度信息相互独立,所以cosθ值不随亮度的变化而变化,因此对光照变化具有较强的抑制作用。
如用 colt=(Cbt,Crt)和 colt-1=(Cbt-1,Crt-1)分别表示t和(t-1)时刻同一像素点的色度向量,则根据余弦相似度理论,向量colt和colt-1的夹角余弦值即为两个像素值的色度差异。余弦相似度的计算式表示为:
1.2 建立融合亮度和色度信息的相似度理论
相似度主要有皮尔森相似度、欧氏距离相似度、余弦相似度和曼哈顿距离相似度等多种计算方法。YCbCr模型下的图像各通道信息可以理解为亮度信息和色度向量的集合。应用欧式距离相似度检测图像的方法,通常将欧氏距离解释为两像素的亮度差值,并将亮度值相近的两个像素归为一类。因为没有包含色度信息的影响,这将引起大量的误检测,如图1中的Ⅱ区域所示,图中θ为像素色度向量夹角阈值,ΔIs为像素亮度差值阈值,圆心点为参考像素。在Ⅱ区域中,新像素相对参考像素的亮度差值ΔI在阈值ΔIs范围内,仅参考欧式距离相似度时,应该将两者归为一类,但两者的色度差异很大,并不是相似像素,不能将两者归为一类,因而引起了误检测。这种误检测通常是由于亮度均匀的不同色彩区域引起的。应用余弦相似度检测图像的方法将图像像素的各通道值理解为向量的各个坐标,通过计算两个像素向量的夹角余弦值来衡量两者的相似度。该方法未包含像素亮度的影响,如图1中Ⅲ区域中的部分区域所示,两个像素向量的夹角可能小于色度向量夹角阈值θ。根据余弦相似度理论应该将其归为一类,但两者的亮度差值ΔI可能很大,如将两者归为一类,则会引起误检测,这种误检测通常是由于光照变化而引起的。为了解决上述两种问题,本文提出融合亮度和色度信息的相似度计算方法,并给出如下像素的相似度定义。
定义1:将亮度和色度信息均相似的两个(两片区域)像素称为相似像素。
如图1中阴影区域所示,该区域内两个像素的色度向量夹角比较小,色彩相似,同时亮度差值也在阈值范围内,亮度相似。相对于参考像素,该区域内的像素均为相似像素,应该归为一类。利用归一化的亮度信息和式(1),建立融合色度和亮度信息的相似度计算公式:
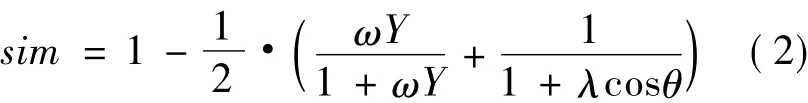
式中:0≤sim≤1;ω与λ均为平衡参数,分别用于平衡亮度与色度变化对相似度值的影响程度,也可以根据不同的场景、亮度和色彩的影响程度不同作适当的调整,一般10≤ω≤30,1≤λ≤3。
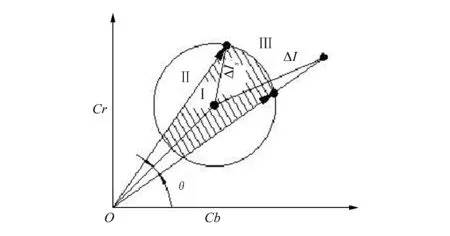
图1 YCbCr模型下相似像素分布
2 基于相似度的动态背景聚类模型
2.1 建立动态背景模型
为了建立动态背景模型,以式(2)为测量标准为每个像素位置自适应建立多个聚类中心,在背景建模阶段对各像素的时间序列值进行聚类分析。
为了评价像素的相似度,设定背景训练相似度阈值 Tb,针对式(2),Tb通常取0.5 ~0.7。因为式(2)是以相互独立的亮度和色度信息为基础建立的,所以本文算法主要应用在YCbCr色彩空间,需要将每一帧图像转换为YCbCr色彩模型。当时间t=1时,取各像素通道值作为各像素位置的第一个聚类中心。读入新的帧后,计算其与聚类中心的相似度值sim,若sim≥Tb,则新像素与聚类中心相似,更新当前聚类中心,这通常是由于背景场景的轻微扰动引起的;若sim <Tb,则新像素与聚类中心不相似,用新像素值建立新的聚类中心,这通常是因为捕捉到背景中动态物体或突变而引起的,如:摇动的树叶、喷泉、飞鸟等。设定背景刷新时间(如30帧),经过刷新时间后删除长期不更新的聚类中心,因为这通常是由于背景突变引起的,如飞鸟等。一段时间后,便对每个像素点建立了一系列的聚类中心,即完成了动态背景模型的建立。背景聚类的过程如图2所示,图中Tb为相似度阈值,圆心为聚类中心。
2.2 前景目标检测
建立动态背景模型后,就可以对前景目标进行检测。首先设定背景减除阈值Tf,且0<Tf<Tb。各像素点采集到当前像素值后,计算其与各聚类中心的相似度Gsim,并判断是否存在满足相似条件,即Gsim>Tf的聚类中心。如果存在,则该新像素为背景,同时更新该聚类中心值;如果不存在相似聚类中心,则该像素为前景目标。
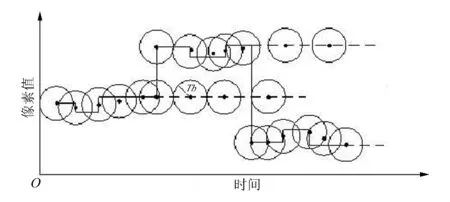
图2 背景聚类过程
2.3 背景更新
背景更新是将新的背景值不断加入背景模型,以适应背景中因光照、摇动的树叶、雨点等引起的背景变化,同时将长久不更新、陈旧的聚类中心删除的过程。定义背景学习率为ρ=Tb/Tf,通常1<ρ<1.5。ρ值越大,表示两个聚类中心的距离值越小,对相同的背景状态将产生更多的聚类中心,背景学习速度快,能迅速接近背景实际状态,误检测率越低,内存消耗越多。ρ值越小,表示两个聚类中心距离值越大,内存消耗少,学习速度慢,误检测率也会随着ρ值的减小而升高。在前景目标提取结束后将新的背景值加入背景模型,让背景模型学习当前背景状态,同时,删除长久不更新的聚类中心。
3 实验结果与讨论
3.1 背景学习率的选取
为了研究背景学习率对本文算法性能的影响,下面通过实验分析误检测率、内存消耗和单帧处理时间与ρ的关系。误检测率定义如下:
定义2:误检测率为单帧图像中误检测的像素数与前景目标像素数的比值。
针对IBM人类视觉研究中心提供的视频PetsD2TeC1.avi,在一台 2.3GHz、2G 内存的 PC 和VC6.0软件平台的测试环境下,测试结果如图3所示。由图3(a)可以看出,随着ρ值的增大,误检测率迅速降低并趋于平缓。由图3(b)可以看出,随着ρ值的增大内存消耗总体呈迅速上升趋势。当ρ<1.25时,内存消耗与背景学习率呈线性关系;当ρ>1.25时,随ρ值增大,算法消耗的内存迅速增加。图3(c)中单帧处理时间随ρ值的变化趋势与图3(b)的变化趋势相似,这是因为对于相同的背景状态,随着背景学习率的增大,聚类中心的数目增加,新建聚类中心既要消耗大量的内存,也要花费较多的时间。
综合考虑图像处理的效果、内存消耗、实时性等因素,本文算法、背景学习率取值范围在1.2~1.3之间较为合适。
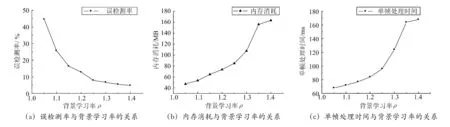
图3 误检测率、内存消耗和单帧处理时间与背景学习率的关系测试结果
3.2 实验效果比对
为了验证本文算法的有效性,对摇动的树叶和喷泉等动态场景进行了测试,并与高斯混合模型(GMM)、码本模型(CodeBook)进行了性能比较。图4为背景学习率ρ=1.25时对IBM人类视觉研究中心提供的视频PetsD2TeC1.avi的前景检测结果。图4(a)组为第305帧检测结果比较图,由图可见,码本模型和高斯混合模型在背景中存在摇动的树叶时,运动的树叶并不能被当作背景完全去除,仍有少部分像素点被误检测,而本文算法提取的前景目标能够极大地去除背景中摇动的树叶。由此可见,本文算法在前景检测方面不仅具有比较完整的检测效果,而且对动态背景具有较强的适应能力。图4(b)组为第573帧检测结果,图中红圈标出的是原图中被风吹动的树所在的区域。当树周围出现运动的前景目标时将引起该区域局部光照变化,与图4(a)组图片所示的检测结果对比可见,码本模型受光照变化的影响大,局部光照变化时,出现大量误检测点,而高斯混合模型和本文算法对光照变化均有较强的抑制作用。高斯混合模型的检测结果仍然存在少量的误检测点,本文算法的误检测点却极少,可以忽略。
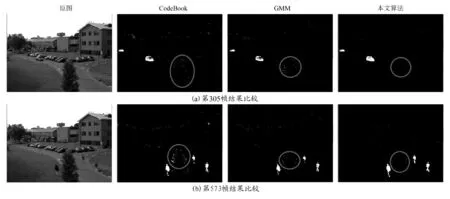
图4 室外摇动的树叶前景检测结果对比
前景检测算法的有效性不仅体现在算法的检测效果,还有算法的空间和时间上的复杂度。过多地消耗内存或者过多耗时的算法均会限制其自身的应用场合。下面针对PetsD2TeC1.avi视频对本文算法、高斯混合模型和码本模型进行时间和空间上的复杂度比较分析,分析结果见表1。
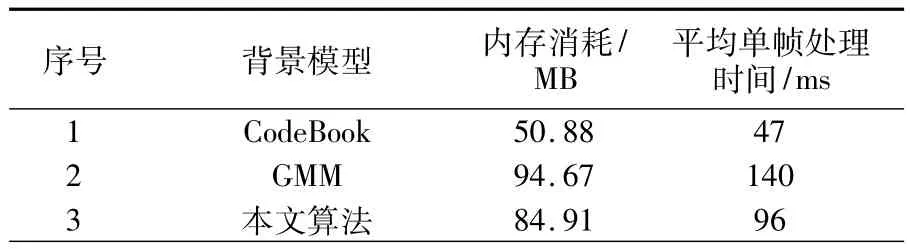
表1 算法的内存消耗和单帧处理时间性能对比
由表1可以看出,与高斯混合模型相比,本文算法在时间和空间上的复杂度方面均有较好的表现。虽然与码本模型相比还是有些欠佳,但综合考虑算法的前景检测效果、内存消耗以及单帧处理时间等性能,本文算法具有比较好的应用前景。
图5为ρ=1.25时对自己采集的带轻微摄像头抖动的实验视频DSC_0013的前景检测结果的比较。视频中存在摇动的树叶、光照变化和轻微的摄像头抖动等。由图5的3组图片比较可以看出:(1)由于图像中不仅存在摇动的树叶,还有轻微的摄像头抖动,CodeBook模型的检测结果中出现了更多的误检测点。(2)高斯混合模型和本文算法对轻微的摄像头抖动和摇动的树叶具有较好的抑制作用。(3)与高斯混合模型相比,本文算法的前景检测结果具有更好的完整性。


图5 带轻微摄像头抖动的前景检测结果比较
4 结束语
本文提出了一种基于像素相似度聚类分析的动态背景建模算法。该算法以融合色度和亮度信息的相似度理论为标准,对图像时间序列进行聚类分析,建立完整的背景模型。多场景对比实验表明,对于背景中只有较少运动物体的场景,本文算法不仅在前景检测效果、时间和空间复杂度方面有较好的表现,而且对轻微的摄像头抖动还具有一定的抑制作用。当背景图像中存在大量运动物体时,虽然本文算法的检测效果较好,但实时性将会大幅度降低。本文算法为动态背景建模技术提供了新的解决思路,且在具有少量运动物体的视频监控、前景检测等方面具有广阔的应用前景。
[1] 知远,蓝山.美国研究用手势指挥无人机七成多手势已能识别[DB/OL].(2012-03-28)[2012-12-20].http://www.china.com.cn/military/txt/2012-03 /28/content_25007237.htm.
[2] Heikkila M,Pietikainen M.A texture-based method for modeling the background and detecting moving objects[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(4):657-662.
[3] Shengping Zhang,Hongxun Yao,Shaohui Liu.Dynamic Background Modeling and Subtraction Using Spatio-temporal Local Binary Patterns[C]//IEEE International Conference on Image Processing.San Diego,CA:Curran Associates Incorporated,2008:1556-1559.
[4] Yang H,Tan Y,Tian J,et al.Accurate Dynamic Scene Model for Moving Object Detection[C]//International Conference on Image Processing(ICIP).San Antonio,TX:Institute of Electrical and Electronics Engineers,2007:157-160.
[5] Tang P,Gao L,Liu Z.Salient Moving Object Detection Using Stochastic Approach Filtering[C]//Fourth International Conference on Image and Graphics(ICIG).Chengdu,China:IEEE Computer Society,2007:530-535.
[6] Hasan B A S,Gan Q J.Sequential EM for Unsupervised Adaptive Gaussian Mixture Model Based Classifier[C]//6th International Conference Machine Learning and Data Mining in Pattern Recognition.Leipzig,Germany:Springer Berlin Heidelberg,2009:96-106.
[7] 齐玉娟,王延江,索鹏.一种基于混合高斯的双空间自适应背景建模方法[J].中国石油大学学报:自然科学版,2012,36(5):175-183.
[8] 孙剑芬,陈莹,继志成.基于关键帧的核密度估计背景建模方法[J].光学技术,2008,34(5):699-701.
[9] Yun Yang,Yunyi Liu.An Improved Background and Foreground Modeling Using Kernel Density Estimation in Moving Object Detection[C] //International Conference on Computer Science and Network Technology(ICCSNT).Harbin,China:Institute of E-lectrical and Electronics Engineers,2011:1050-1054.
[10]Jeisung Lee,Mignon Park.An adaptive background subtraction method based on kernel density estimation[J].Sensors,2012,12(9):12279-12300.
[11]薛如,宋焕生,张环.基于像素的背景建模方法综述[J].电视技术,2012,36(13):39-43.
猜你喜欢
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
中国外汇(2019年11期)2019-08-27
摄影之友(影像视觉)(2019年3期)2019-03-30
小天使·六年级语数英综合(2017年5期)2017-05-27
中国生物医学工程学报(2017年6期)2017-02-10
太空探索(2016年10期)2016-07-10
现代工业经济和信息化(2016年19期)2016-05-17
文物保护与考古科学(2016年4期)2016-05-17
公民与法治(2016年23期)2016-05-17
