
基于GPS数据的周期性行为挖掘*
2013-08-10 03:42方滨兴
电信科学 2013年7期
方滨兴,刘 威
(哈尔滨工业大学计算机网络与信息安全研究中心 哈尔滨150001)
1 引言
在现在的生活里智能手机越来越普及,智能手机以其强大的功能正在逐渐改变人们上网的方式。此外几乎每个人都有手机,并且大部分时间都会将手机带在身边,用户可以很方便地通过智能手机的GPS功能获取用户当前的位置信息。这些位置信息能够帮助用户获得周围的信息并且引导用户到达感兴趣的地方,同时还可以将这些位置信息分享给好友。
最近几年,越来越多的公司和组织提供关于GPS数据的服务。对于一些简单的服务,网络公司通过向用户提供位于用户附近的用户列表,帮助用户认识更多的朋友;或者用户可以直接将自己的位置信息分享给其他人。当然也有一些复杂的服务。人们的运动轨迹往往能够反映他们的兴趣爱好,比如经常去体育馆或者篮球场的人可以判定为喜欢做运动;而对于那些经常在自然景观附近徘徊的人们,可以认为喜欢旅行。因此,可以认为具有相似的运动轨迹数据的人们具有相同的兴趣。基于这项服务,可以实现好友推荐功能。可以将具有相同爱好的人推荐给用户,这样用户就可以很容易地找到志同道合的朋友。另外,还可以从GPS数据中挖掘出运动模式[1]。运动模式是描述人们行为的重要属性,通常运动模式包括步行、自行车、公交车、小汽车等。有了运动模式这个概念,可以把GPS数据划分为不同的运动模式,然后根据用户的需要向用户提供更好的建议。比如系统可以通过对运动模式为小汽车的GPS数据进行挖掘,如果用户想开车到某个地方,这时系统可以根据挖掘出来的结果向用户提供一条合理的行车路线。另外通过对运动模式的挖掘,可以发现其他人都采用什么方式到达同一个地点,帮助用户做出更好的选择。
通过智能手机以及其他能够提供GPS功能的设备,可以收集海量的GPS数据。然而,大多数情况下,应用并不能直接地使用这些数据。这是因为GPS数据的数据量非常巨大,而且一个GPS孤点对于应用来说并没有太多的意义,因此需要从中挖掘出频繁周期模式。通过分析周期模式,可以发现人的运动以及生活规律。而且周期模式可以看作用户运动轨迹的压缩,可以用它们替换原始数据节省空间。此外,在收集GPS数据的同时,会不可避免地引入噪声,因此应该在挖掘之前进行预处理去除噪声。
在本文中,设计实现了一个基于GPS轨迹发现用户生活规律的系统。系统可以被划分为以下几个模块。
·GPS数据记录模块:利用智能手机实时地感知用户位置信息,产生GPS轨迹,并定时地将轨迹提交给后台周期挖掘服务,因为手机不可能一直在前端运行记录程序,否则会影响用户手机的其他应用,所以GPS数据记录模块应该能够在后台运行。
·通信模块:负责智能手机与后台服务器之间的通信。
·预处理模块:后台接收到手机发来的轨迹数据,由预处理模块进行预处理,预处理模块主要包括去噪以及挖掘停留点两方面内容。
·挖掘模块:通过对停留点序列进行挖掘获得频繁周期模式,最后挖掘出来的模式是异步的[2,3]。这里异步的概念指的是周期模式并不一定是连续发生的。也就是说容许一定程度的噪声,这样更符合实际情况。
·服务模块:根据获得的周期模式提供服务。这方面内容不是讨论的重点,所以主要服务就是向用户提供挖掘出来的周期模式。系统的模块如图1所示。
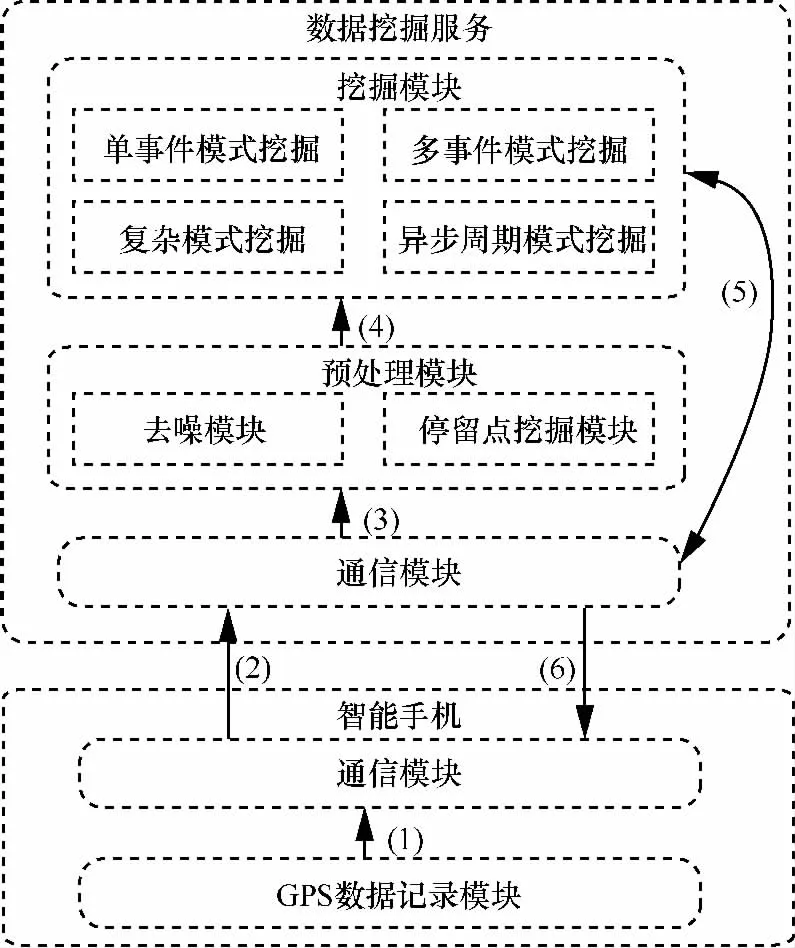
图1 系统的模块
GPS数据记录模块将记录的GPS轨迹发送到通信模块,通信模块再将轨迹数据发送到后台服务器,轨迹序列经过预处理模块处理之后,就会得到停留点序列。系统的挖掘模块通过对停留点序列进行挖掘,最后获得异步频繁周期模式。挖掘出来的周期模式可以通过通信模块发送到智能手机。
2 系统设计与实现
下面介绍系统中GPS数据记录模块、预处理模块、挖掘模块的设计以及具体实现。
2.1 GPS数据记录模块
由于智能手机的强大功能,可以很简单地记录GPS数据,但是仍有很多问题需要解决。GPS数据记录模块实际上就是运行在智能手机的应用程序。当模块开始运行的时候,应该首先检查GPS功能是否可用,如果不可用,应该提醒用户打开GPS,否则模块将无法正常工作。此外应该保证手机在运行GPS数据记录模块时不影响手机的其他应用,否则会严重影响系统的用户体验。所以GPS数据记录模块应该能在后台运行,当然在后台运行并不代表会失去对模块的控制,必要的时候,仍能够恢复到前端进行操作。Android开发中activity生命周期和service生命周期[4,5]能够帮助实现这个功能。在模块开始记录数据过程中,按照5 s的时间间隔记录GPS数据,并且将数据保存在data.xml中。这些数据应该按照表1的格式进行保存。之后按照固定的时间周期将这些数据发送到服务器。
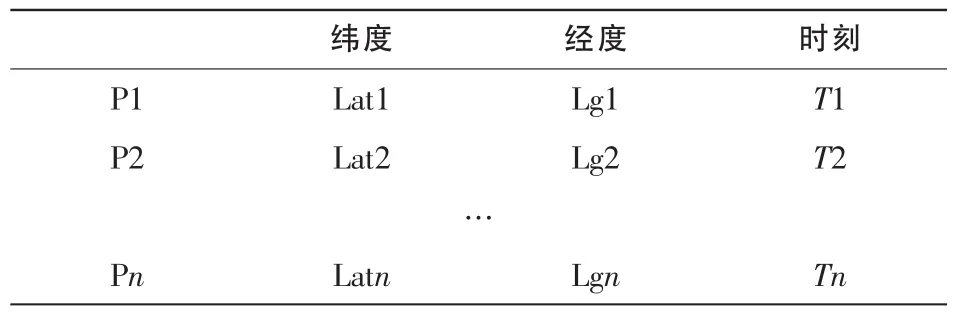
表1 收集的GPS数据的格式
2.2 预处理模块
预处理模块的主要功能是去噪以及挖掘获取停留点序列。因此,将预处理模块划分为两个部分:去噪模块以及停留点挖掘模块。
2.2.1 去噪模块
由于GPS系统本身精确度的限制,收集到的GPS数据会包含很多离群点。这些离群点大部分是因为GPS信号偏移导致的,尤其是在室内,信号偏移的概率是很高的;就算用户在户外,仍然有可能接收到偏移的信号。因此对GPS数据进行过滤是很重要的。这里将介绍两种过滤器,具体如下。
(1)速度过滤器
用户的移动速度是有一定区间范围的。这里认为,对于一个用户来说合理的速度为0~120 km/h。速度过滤器计算用户在两个连续GPS点之间的速度,如果速度没有处于这个合理的范围,就会判定该点是离群点,并将这个点去除掉。这些离群点通常就是信号偏移造成的。
(2)加速度过滤器
速度过滤器是计算两个连续GPS点之间的速度,而加速度过滤器是利用这些计算出来的速度,计算3个连续的位置点之间的加速度。同样的,个人运动的加速度也有一定的合理范围。这里认为,合理的加速度应该小于15 m/s2,如果检测到不合理的加速度,加速度过滤器将过滤掉后一个位置点。GPS接收器接收到漂移数据,也会造成异常的运动加速度。
2.2.2 停留点挖掘模块
停留点通常与用户的行为关联。如果用户停留在球场,他很有可能是在打篮球;如果用户长时间停留在建筑物中,那很有可能代表用户生活或者工作在这里。一些算法仅仅考虑空间信息,并且停留点被定义为包含GPS点大于临界值的区域,也就是说停留点包含的GPS点多于其他区域。这个算法存在错误和偏差,因为很有可能会把一些毫不关联的点包括进来,用户仅仅可能是经常路过这里。而且很有可能会漏掉一些停留点,因为如果在室内,GPS是接收不到卫星信号的,但是这个建筑物很有可能是与用户行为相联系的停留点。因此,不仅需要考虑空间信息,还需要考虑时间信息。主要关注的是停留时间超过一定临界值的物理区域。用这个物理区域的中心来表示它,也就是停留点。
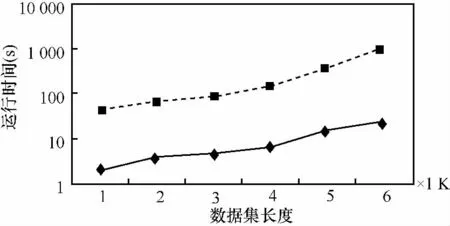
停留点的挖掘依赖两个参数,一是时间临界值Tthresh,一是空间临界值Dthresh,P={pm,pm+1,…,pn}是GPS点序列的一组连续的 GPS 点。对于坌i,其中 m 使用式(1)计算停留点的纬度,式(2)计算停留点的经度,式(3)计算进入停留点的时间,式(4)计算离开停留点的时间。 通常地,这些停留点会出现在两种情形中。一种是连续两个GPS点的间隔时间超过时间临界值的情形。这种情形大多发生在用户进入建筑物内时,因为室内没有GPS信号,所以看上去就好像用户这段时间一直保持不动。另一种情形是用户徘徊在一个小区域的时间超过了时间的临界值。这种情形一般发生在用户被周围的风景所吸引或者在户外参加打篮球等活动。和GPS数据相比,停留点包含更多的语义。 之后,还需要对停留点进行聚类,因为不同时间用户徘徊在同一地点计算出来的停留点会有偏差,结果并不完全一样,因此需要把实际上位于同一地点的停留点进行聚类,并用聚类后的结果表示停留点,得到新的序列。 这里将预处理模块运行在后台服务器,随着智能手机的计算能力越来越强,也可以将预处理模块放在手机上进行处理,这样可以大大减少与服务器通信的开销。 发送到后台的GPS轨迹序列经过预处理模块处理之后,就会得到停留点序列。系统的挖掘模块对停留点序列进行挖掘,最后获得异步频繁周期模式。异步周期模式可以用来反映用户的生活规律。模式P={p1,p2,…,pl}是一个周期长度为 L的模式,其中每一个元素 pi哿E∪*,pi≠覫(1≤i≤L),E代表事件集,这里采用的事件集就是挖掘出来的停留点聚类后的集合。*代表一个任意事件的集合,能够符合任意事件的要求。D0=d1,d2,…,dl是时序性数据集D中的连续子序列,对于周期模式P={p1,p2,…,pl},当pi哿di或pi=*,(1≤i≤L),称 P 符合 D。 这里引入 3 个变量 min_rep、max_dis和 total_rep[4,5]描述频繁周期模式。min_rep代表模式连续发生的最小次数。如果有一个连续的D=D1,D2,…,Dj,对于坌i,其中1 挖掘模块总共分为如下4个阶段: ·挖掘单事件模式; ·挖掘多事件模式; ·挖掘复杂模式; ·挖掘异步周期模式。 前3个阶挖掘出来的模式对应显著分割对应的模式,第4个阶段挖掘出来的模式对应显著子序列对应的模式。 2.3.1 挖掘单事件模式 模式P={p1,p2,…,pl}是一个周期长度为L的模式,其中一个元素p1哿E,其余的pi为*,称这样的模式为单一模式。其中p1是一个集合,当p1只包含一个事件,称该模式为单事件模式,如果p1包含多个事件,称其为多事件模式。这个阶段就是挖掘出所有的单事件模式。 在挖掘之前,应该对序列进行一步处理,将其转换为垂直格式,这样处理之后挖掘会更加高效[6],处理后的结果如表2所示,之后挖掘单事件模式,只需考虑该事件发生时间的序列。 表2 序列的垂直格式 挖掘单事件模块可以分为两个阶段:第一个阶段就是利用滑动窗口找到所有可能的周期;第二个阶段就是基于散列验证所有可能的周期并得到单事件模式。所谓滑动窗口就是每一次只考虑落入固定窗口的点。设定一个参数Lmax代表最长可能的周期,这样将不会考虑大于Lmax的周期。因此,需要将滑动窗口的长度设为Lmax。对于每一个时间点,仅仅考虑落入以该点为起始的滑动窗口的时间点,并分别计算时间间隔,这样随着滑动窗口向前滑动,就能统计每个时间间隔发生的次数。 对于第二阶段,首先检查第一阶段统计的结果,找到发生次数大于min_rep的时间间隔作为该事件可能的周期,这样做可以缩小查找范围,提高查找效率。这里还利用了一个比较重要的数据结构Seg,这个数据结构包含两个参数:rep和last,分别代表一个可能周期的重复次数和上一个周期发生的时间点。给定可能的周期p,定义一个结构体数组Seg[p]。将任意的时间点通过散列算法映射到Seg[p]中的某一项,这里使用的散列算法是除留余数法:取时间点t被p除后的余数为散列地址。通过这种散列就可以找到所有的周期模式,比如Seg[1]代表起点除以周期p等于1的周期模式,因此结构体数组Seg[p]就包含起点从0到p-1所有可能的情况。在进行遍历的过程中,对于一个时间点t,首先将其映射到Seg[t%p],并将时间点与Seg[t%p].last相减,并将 Seg[t%p].last的值设为 t,如果结果等于p,则将Seg[t%p].rep加1并继续遍历。如果不等于p,则比较Seg[t%p].rep是否大于min_rep,如果大于则代表是显著分割并输出结果,最后将Seg[t%p].rep设为1并继续遍历。遍历结束后最后统计一下Seg[p],找出剩余的显著分割。挖掘出来的显著分割应该具有标准化的格式:(segment,rep,p,start),其中 segment代表包含的事件集,rep代表这个显著分割重复发生的次数,p代表周期,start代表显著分割的起始位置。 2.3.2 挖掘多事件模式 这个阶段接收的输入为上一个阶段的输出,也就是挖掘出来的单事件模式。通过定义知道多事件模式实际上由单事件模式构成,因此这个阶段需要做的工作就是按照定义合并单事件模式。这里引入偏移的概念。合并具有相同周期以及相同偏移的显著分割。通过式(5)计算偏移。合并后的模式重复发生次数通过式(6)得到。如果重复发生次数大于min_rep,那么合并就是合理的。 合并的过程实际上就是一个深度优先遍历的过程。尽管深度优先匹配效率很低,时间复杂度呈指数增长,但是可以在合并之前对单事件模式按照start进行排序,这样遍历不会太深就会结束,从而大大提高了效率。 2.3.3 挖掘复杂模式 模式P={p1,p2,…,pl}是一个周期长度为L的模式,其中至少两个元素pi,pj哿E,其余的p为*,称这样的模式为复杂模式。这个阶段接收的输入为前两个阶段输出的并集,因此这个阶段所需要做的工作就是将前两个阶段挖掘出来的单一模式合并为复杂模式。 合并的过程,仍需利用偏移这个概念。将具有不同偏移但是周期相同的显著分割进行合并。复杂模式可能是(A,*,B,C)、(B,C,A,*)或者(C,A,*,B)中的一种,但是并不是说可以任意选择一个,如果任意选择一个,那么可能造成重复的问题。这里采用具有最大的重复次数模式来代表合并后的复杂模式,具体来说就是选择结束位置最小的元素作为模式的第一个元素,结束位置可以通过式(7)得到。可以通过式(8)得到合并后的复杂模式重复发生的次数。 挖掘复杂模式和挖掘多事件模式在实现上很相似,所以可以将其合并到一起。 2.3.4 挖掘异步周期模式 这个阶段的输入是前3个阶段输出的结果,这一阶段所需要做的工作就是将前3个阶段得到的显著分割合并为显著子序列。合并的过程需要判断两个相邻的显著分割之间的杂讯长度是否小于max_dis,如果小于max_dis,则将两个显著分割合并为一个子序列。通过递归,将所有可以合并的显著分割合并。最后验证所有的子序列对应模式重复发生次数是否大于total_rep,如果成立,则该子序列为显著子序列,其对应的模式就是要挖掘的异步周期模式。 2.3.5 相关算法比较 这里将挖掘模块的挖掘算法和LSI[3]算法进行比较。LSI算法可以分为两个阶段,LSI的第一阶段用来挖掘异步的单事件模式,按照时间顺序可以分为3个部分执行:模式确认(A)、模式生长(B)、模式扩展(C),其中 A 和 B 两个部分的功能与第2.3.1节所提到的挖掘单事件模式的功能类似,C部分的功能和第2.3.4节所提到的挖掘异步周期模式的功能类似。LSI的第二个阶段用于计算异步的复杂周期模式,可以大致地看作第2.3.3节所提到的挖掘复杂模式的功能。和挖掘模块的挖掘算法相比,LSI中没有第 2.3.2节的内容。 对于挖掘单事件模式,LSI第一阶段的A和B部分的时间复杂度为k×M×Lmax。这里k可以通过min_rep+max_dis+Lmax获得[3],M是数据的大小,M=D×T,D 代表时间点个数,T代表每个时间点事件个数。而根据第2.3.1节的分析,单事件挖掘模块的时间复杂度为M×Lmax。LSI的第二个阶段采用分层搜索的方法来挖掘复杂模式,即通过周期相同较短的复杂模式构造更长的复杂模式。这个算法扫描数据集的次数约等于候选个数,所以在分割个数不是特别高的情况下,第2.3.3节提供的算法拥有更好的表现。 实验可以分为两个部分,第一个部分主要就是验证系统各个模块的输出是否符合当初设计的要求,而对于第二个部分,要验证不同的输入对系统的影响。 设定 min_rep为 5,max_dis为 3,total_rep为 30。通过对整个系统进行测试,证明系统能够正常地收集GPS数据并且将数据发送到服务器。根据收集来的GPS数据,能够挖掘出关联地点。最后能够通过挖掘模块挖掘出异步周期模式。结果如图2所示。 图2 挖掘的结果 因为GPS数据并不能按照要求进行构造,所以对于第二部分,需要根据不同实验的需求测试数据。在构造数据的过程中,首先组合出C个可能的显著模式候选,每个显著模式候选的周期长度服从正态分布;起始位置服从均匀分布。之后就要将这些显著模式候选放进每一个时间点内,而每一个模式所形成的划分及划分之间的杂讯由几何分布决定。按照这样的原则,产生所有显著的划分,直到时间轴的最末点,以形成一条显著的时间序列。另外,将显著模式插入时间点后,需要检查每个时间点发生的事件数至少服从泊松分布。 因为滑动窗口的原因,对于输入数据集的每一个时间点,都必须进行循序的检查,也就是说,系统在寻找重复发生模式的时候,时间轴上的每一个时间点都不能够被忽略,所以输入的资料集长度越长,系统寻找周期性模式的时间也应该跟着增加,如图3所示,当min_rep=15、Lmax=20时,时序性数据集长度对挖掘单事件模式运行的影响。图3中实线代表提出算法的结果,虚线代表LSI(A+B)的结果。通过观察可知处理相同的数据,提出的算法性能更好。 图3 数据集长度对单事件模式挖掘的影响 因为挖掘多事件模式和挖掘复杂模式的过程非常相似,所以在这里只讨论挖掘复杂模式的过程。其时间复杂度和显著分割的数目相关,模式的平均长度对显著分割数目的影响是呈指数增长的,但是通过图4看出,运行时间并不是随模式平均长度指数增长,而是近似于线性增长,这是因为之前将数据集按照start进行排序,这样没有重叠部分的显著分割之间的比较能够得到避免。 图4 模式平均长度对复杂模式挖掘的影响 本文提出的基于GPS轨迹发现用户的生活规律的系统共分为3个模块:第1个模块为GPS数据记录模块,利用GPS提供定位信息,从精度上保证了挖掘异步周期模式的可行性;第2个模块为预处理模块,用于过滤GPS漂移点与停留点的挖掘;第3个模块挖掘模块,是整个系统的核心,对挖掘出来的停留点t点进行异步周期模式挖掘。在挖掘算法方面,采用的是一个4阶段算法,包括挖掘单事件模式、挖掘多事件模式、挖掘复杂模式以及挖掘异步周期模式。在整个挖掘过程中,系统利用 min_rep、max_dis、total_rep这3个参数作为判断异步周期模式的约束条件。 根据实验的结果,系统是稳定而高效的。但是在未来的研究和开发中,这个系统还有很大的拓展和应用空间,比如提供根据挖掘的周期模式对用户行为进行预测,并且利用推测出的用户的行为对用户进行推荐等基于位置的服务。 1 Liu B.Web Data Mining,2nd Edition.Germany:Springer,2006 2 Felker D.Android Application Development for Dummies.Indiana:Wiley Publishing,2011 3 Yang J,Yu P S,Wang W.Mining asynchronous periodic patterns in time series data.IEEE Transanctions on Knowledge and DataEng,2003,15(3):613~628 4 Wang W,Yang J,Yu P S.Mining patterns in long sequential datawith noise.ACMSIGKDDExplorations Newsletter,2003,2(2):28~33 5 Yang J,Yu P S,Wang W.Meta-patterns:revealing hidden periodic patterns. International Conference on Knowledge Discovering and Data Mining,San Jose,California,USA,2001 6 Zaki M J.Spade:an efficient algorithm for mining frequent sequences.Machine Learning,2001,42(2):31~60 7 Li Q,Zheng Y,Chen Y.Understand transportation mode based on GPS data for Web applications.ACM Transactions on the Web(TWEB),2010,4(1):247~256 8 Meier R.Professional Android 2 Application Development.Indiana:Wiley Publishing,2010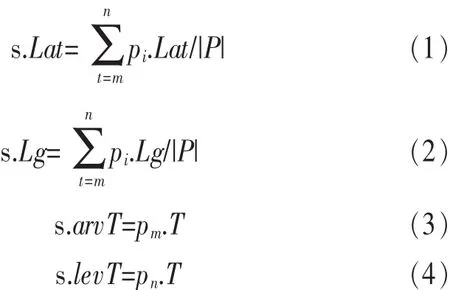
2.3 挖掘模块

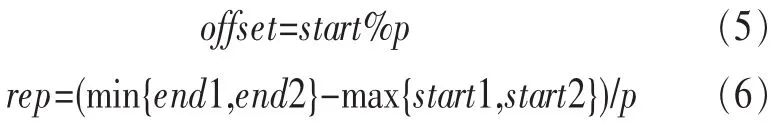

3 仿真实验

4 结束语
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21中学生数理化(高中版.高考理化)(2022年5期)2022-06-01温州大学学报(自然科学版)(2022年2期)2022-05-30科学与社会(2022年1期)2022-04-19莫愁(2019年36期)2019-11-13制导与引信(2017年3期)2017-11-02工业设计(2016年11期)2016-04-16营销界(2015年22期)2015-02-28海峡姐妹(2015年6期)2015-02-27汽车与新动力(2012年1期)2012-03-25
