
基于保护缓存的x86系统仿真优化
2013-07-25 02:28董卫宇王立新蒋烈辉郭玉东
计算机工程与设计 2013年2期
董卫宇,王立新,蒋烈辉,郭玉东
(国家数字交换系统系统工程技术研究中心,河南郑州450002)
0 引言
系统仿真 (system emulation)是指对某个计算机的指令集体系结构 (instruction set architecture,ISA)进行尽可能精确的仿真,以构建与该计算机等价的虚拟机。x86是一种主流的但十分复杂的指令集体系结构,得到了多数系统仿真器的支持,所得到的x86系统虚拟机被广泛应用于跨平台操作系统透明移植[1,2]、动态二进制分析[3,4]等领域。利用系统仿真器得到的x86虚拟机相比真实的计算机在效率上会有一定的下降,如何提高x86仿真效率一直是系统仿真器的重要研究内容之一。目前虽然已有一些工作通过优化动态二进制翻译引擎来提高仿真效率[5-8],但未见有工作针对x86的保护检查机制进行仿真优化。
本文提出了一种基于保护缓存 (protection cache,PCache)的x86系统仿真的优化机制,可在不损失兼容性的前提下,有效降低仿真x86保护机制的开销。测试表明,启动保护缓存后,涉及保护检查的x86指令或操作的仿真效率,以及虚拟机中运行的频繁使用这些指令或操作的应用程序的性能均得到了稳定的提升。
在系统仿真器中设置保护缓存的观点建立在以下两点观察之上。首先,x86处理器针对某些指令或操作进行的保护检查比较复杂,而且,由于保护检查的复杂性,很难将需要进行保护检查的x86指令或操作翻译为对应的宿主平台指令序列,而是采用C函数来模拟它们的行为,这进一步降低了仿真的效率。其次,某些涉及保护检查的x86指令或操作可能被频繁执行,在执行环境未发生变化的情况下,重复模拟保护检查的动作是不必要的,可以将此前保护检查的结果缓存起来,供后续的执行使用。因此,采用保护缓存将有可能降低仿真x86处理器保护机制所带来的开销,提高系统仿真器的整体效率。
1 x86保护机制的仿真开销
我们以Linux系统调用为例说明x86处理器保护机制的复杂性,并分析仿真开销的来源。Linux系统调用由软中断指令INT 0x80发起,中断描述符表IDT中索引为0x80的描述符被设置为陷阱门,用以给出该软中断服务程序的入口。Linux系统调用不涉及x86的一致代码段、虚拟8086模式等机制,为方便叙述,我们这里忽略了有关这些机制的保护检查,实际的保护检查过程还要复杂一些。
执行INT 0x80指令时处理器主要执行以下动作:以0x80为索引,从IDT中取得门描述符,记为GateDesc,并检查中断类型号0x80所引用的描述符是否超出IDT的界限、GateDesc的P位是否为1、GateDesc的类型是否为中断门、陷阱门、任务门之一、GateDesc中的段选择子引用的描述符是否为空等;以GateDesc中的段选择子为索引,从全局描述符表GDT中取得代码段描述符,记为Code-Desc,并检查GateDesc中的段选择子引用的描述符是否超出GDT或LDT的界限、CodeDesc的类型是否是代码段、CodeDesc的P为是否为1等;进行堆栈切换。从当前任务状态段TSS中取得特权级0对应的堆栈地址,并根据堆栈段选择子从GDT或LDT中取得堆栈段描述符,记为Stack-Desc,并检查堆栈段选择子引用的是否是空描述符、该描述符地址是否超出GDT或LDT的界限、StackDesc的类型是否是可写的数据段、StackDesc的DPL是否等于Code-Desc的DPL、StackDesc的P为是否为1等。最后,向堆栈中压入返回地址、标志寄存器,装载寄存器SS和ESP完成切换堆栈,装载寄存器CS和EIP完成控制转移。
从上例可见,仿真x86的保护机制的开销主要来自两个方面。一是从内存中取得各种描述符所带来的访存开销。系统仿真器一般使用一块进程地址空间模拟虚拟机的物理内存,并利用软件模拟x86 MMU和 TLB的动作,访存操作包括查询虚拟TLB将描述符客户线性地址GVA转换为客户物理地址GPA进而转换成宿主虚拟地址HVA,以及可能的由于虚拟TLB缺失导致的查询客户操作系统页表并填充TLB的操作。上述访问描述符的操作会带来很大的开销。二是针对描述符进行的各种检查操作,在对这些操作进行精确仿真时,将有大量的分支语句用于判断是否违反保护规则,可能对宿主处理器流水线性能产生较大的影响。
2 保护缓存
我们认为,x86处理器在保护检查操作上呈现出某种局部性,即对于x86上的操作系统来说,描述符表的设置一般是正确的且很少变化,某个指令或操作通过保护检查往往意味着以后执行该指令或操作时也可以通过保护检查。因此,可为虚拟x86处理器维护一块缓存区域,缓存最近访问过的描述符,以及使用该描述符的指令或操作的保护检查结果,当再次执行该指令或操作时,可从保护缓存中获取需要的描述符及保护检查结果,从而避免对虚拟机内存的访问和繁琐的保护检查操作。我们称这种机制为保护缓存。
考虑到实效性,我们对保护缓存的内容进行了若干限定。首先,多数x86上的操作系统很少使用LDT,因此保护缓存中只保存来自GDT和IDT的描述符。其次,x86的保护机制分为段级保护和页级保护,由于TLB中缓存了页级保护的结果,因此文章的保护缓存主要涉及段级保护机制。
通过对x86指令集的分析,总结出两类比较复杂的段级保护检查:一是确定中断服务程序入口时,需要对中断类型号索引到的IDT中的门描述符进行保护检查,涉及这类检查的指令或操作均与中断相关,包括INT n/INTO/INT 3、硬件中断、异常等;二是加载段寄存器时,需要对段选择子索引到的GDT中的段描述符进行保护检查,涉及这类检查的指令包括IRET、以段寄存器为目的操作数的MOV/POP、LSS/LDS/LES/LFS/LGS、LCALL、LRET、LJMP 等。注意,INT n/INTO/INT 3、硬件中断、异常等指令或操作由于需要进行段间转移或堆栈切换,需要加载段寄存器,因此也需要进行第二类检查。
根据保护检查所需描述符的来源,我们将保护缓存分为两部分,分别称为INTR P-Cache(P-Cache for INTeRrupt)和 SRL P-Cache(P-Cache for Segment Register Loa-ding),两者分别缓存来自IDT和GDT的描述符以及处理器对使用这些描述符的指令或操作的保护检查结果。
INTR P-Cache和SRL P-Cache的缓存项的个数与IDT和GDT中描述符的个数保持相等,且缓存项与描述符间一一对应,给出中断类型号或段选择子,就可以在P-Cache中索引到对应的缓存项,这也使得缓存淘汰算法不再必要。IDT最多包含256个描述符,GDT虽可以包含8K个描述符,但操作系统一般只设置很小的GDT,因此P-Cache不会消耗很大的内存。
Intr P-Cache和SRL P-Cache具有类似的逻辑结构,如图1所示。每个缓存项由两部分组成,第一部分记作Descriptor(8字节),用于缓存来自描述符表的描述符;第二部分记作Checking Result,用于缓存保护检查的结果。
给定描述符,不同的指令或操作对应的保护检查内容也不同,不同的特权级下执行同样的指令或操作所得的保护检查结果也不同。例如,若选择子SEL索引GDT中的一个DPL为0的只读数据段描述符,在CPL为0时,MOV DS,SEL将把该描述符加载到DS中,但MOV SS,SEL将无法通过保护检查 (堆栈段必须可写),当CPL为3时,指令MOV DS,SEL也无法通过保护检查 (权限不够)。为此,我们将前述指令或操作划分为7类,如表1所示。相应地,缓存项的Checking Result字段被组织成一个位图,如图2所示,每类指令或操作对应位图中的4位,位n(n=0,1,2,3)指示在特权级为n时执行该指令或操作是否通过保护检查。给定指令或操作类别m以及特权级n(特权级一般指CPL,某些情况下,为CPL和RPL的最大值),位图中的第m*4+n位为缓存的保护检查结果。由于仅表1中的第1类指令或操作引用Intr P-Cache,因此Checking Result的低4位有意义,SRL P-Cache则使用Checking Result的低28位。
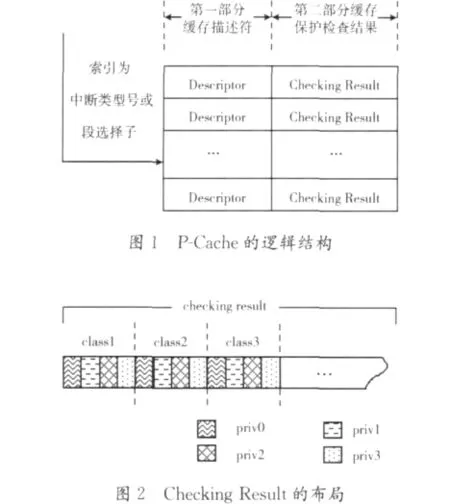
给定指令或操作及其参数,若索引到的缓存项的Checking Result位图中的相应位为1,则称为缓存命中,否则称为缓存缺失。缓存命中意味着系统仿真器可直接从缓存项的Descriptor部分获取描述符供后续使用,也无需再对指令或操作进行保护检查。缓存缺失的原因可能是P-Cache被刷新、初次执行该指令或操作等,此时系统仿真器需要从虚拟机内存读取描述符并进行保护检查操作,若通过保护检查,则将描述符保存在缓存项的Descriptor部分,并将Checking Result的相应位置1,即缓存装入。在某些时机,如系统初始化或检测到IDT或GDT发生变化时,将执行缓存刷新,将所有的缓存项清0。
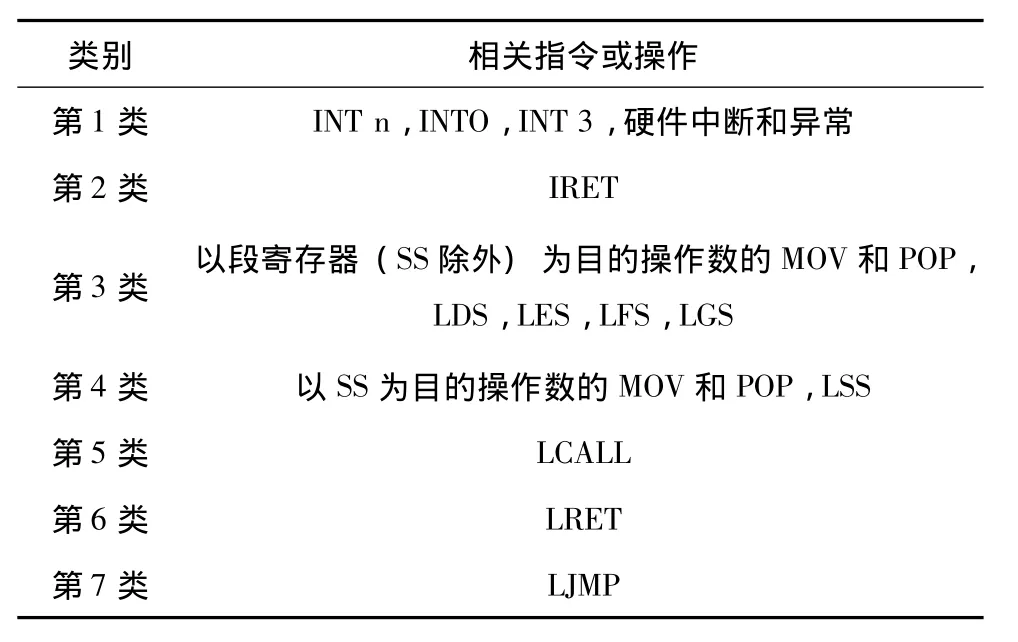
表1 具有不同段级保护检查方式的7类指令或操作
以上述Linux系统调用为例,若第一次执行INT 0x80通过了全部保护检查,则很可能再次执行INT 0x80所需的描述符和保护检查结果都已经缓存在了INTR P-Cache和SRL P-Cache中,如此可以省去3次访问虚拟机内存获取描述符的操作,以及3次保护检查的操作。因此保护缓存是一种有效的提高系统仿真效率的方式。
3 实现
文章基于QEMU[9]对保护缓存机制进行了实现,主要包括两个方面的工作。第一方面的工作是在虚拟CPU的状态结构中增加保护缓存相关的数据结构,并修改表1中指令或操作的仿真方法,使得系统仿真器在访问描述符或进行保护检查之前,先查询保护缓存,仅当缓存缺失时才访问描述符表并进行保护检查。
第二方面的工作是维护P-Cache的一致性,即监测描述符表的变化,确定P-Cache中的内容是否有效。下面以IDT例说明文章采用的做法。对SRL P-Cache的一致性维护方法类似。
当IDT的线性地址GVA、尺寸、物理地址GPA、内容四者之一发生变化时,可认为INTR P-Cache的内容失效。对IDT的前两种变化的监测相对简单,IDT的线性地址和尺寸保存在IDTR中,并通过指令LIDT来设置,因此可通过对LIDT指令插桩来监测IDT的线性地址和尺寸,并在发现变化时刷新INTR P-Cache。对IDT的后两种变化的监测稍微复杂。为监测IDT内容的变化必须获取IDT对应的物理地址,在获取IDT的物理地址并对其进行写保护之前,INTR P-Cache中的内容是无效的。
我们先来讨论对IDT物理地址的获取。当x86未启动分页时,线性地址即物理地址,通过IDTR的内容就可以判断IDT的GPA。但当虚拟机启动分页时,理论上讲 (虽然可能性很小),对于不同的进程上下文,IDT可能处于不同的物理地址,也不能通过查询虚拟机的页表的方法来确定IDT的GPA(IDT可能不在物理内存中)。文章通过截获虚拟CPU的TLB填充 (TLB-FILL)事件来发现IDT的GPA,具体做法是:对 INTR P-Cache中的缓存项分组,称为PCEG(P-Cache Entry Group),属于同一PCEG的缓存项的描述符来自同一物理页面。使用数据结构pceg_desc_t在PCEG、描述符表虚拟页面以及物理页面间建立联系,如图3所示,其中的cache字段指向缓存项,va和pa字段分别记录PCEG对应的IDT页面的线性地址和物理地址。当虚拟CPU访问IDT时 (如对某个指令或操作进行保护检查而读取相关描述符),若TLB中不存在相关虚拟地址到物理地址的映射,将导致TLB-FILL事件,截获该事件,从将要装入的TLB表项中得到PCEG所对应的物理页面基址并将其记录在pceg_desc_t.pa中。事实上,可将pceg_desc_t看做是TLB的扩展,其中记录了IDT线性地址和物理地址间的映射关系,该映射关系不受TLB表项淘汰机制的影响,但若虚拟机重新加载CR3或针对IDT执行INVLPG指令,该映射关系将失效。
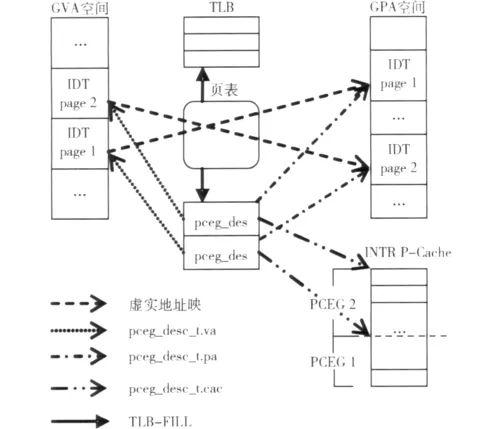
图3 相关数据结构间的关系
在获得PCEG所对应的IDT物理页面地址后就可以对IDT的内容变化进行监测。通过截获QEMU的虚拟机物理内存写操作 (stl_kernel、__stl_mmu等)实现对INTR P-Cache一致性的维护,在QEMU写虚拟机物理内存前,判断地址是否落入检测到的IDT的物理地址范围内,若是则刷新相应的P-Cache缓存项。
为维护P-Cache的一致性,需修改QEMU的如下指令或操作的仿真代码,包括:LIDT和LGDT指令 (检测IDT和GDT线性地址或尺寸变化)、CR0写指令 (检测保护模式的启动和关闭、检测分页机制的启动和关闭)、CR3写指令和INVLPG指令 (检测IDT和GDT的物理地址变化)、虚拟TLB操作 (获得IDT或GDT的物理地址)、物理内存写操作 (检测IDT或GDT的内容变化)。
4 性能测试及分析
文章对启动保护缓存前后的QEMU虚拟机的系统效率进行了测试,宿主机为运行Fedora操作系统的x86平台,虚拟机为运行Debian操作系统x86平台。
QEMU以用户态进程的方式运行,执行过程受宿主机操作系统噪声的影响较大,因此不易精确测量虚拟机的某个指令或操作的执行时间。文章通过测量保护模式下执行指令或操作所耗费的平均时钟周期来评估保护缓存机制对系统仿真效率的影响,时钟周期的计量可采用读取宿主机时间戳计数器 (如x86的Time Stamp Counter,TSC)的方法确定。图4给出了引入保护缓存前后各指令或操作的平均时钟周期。结果表明,引入保护缓存后,与保护检查相关的指令或操作的效率最少提升了约11%(中断或异常处理),最大提升约24.5%(加载段寄存器)。
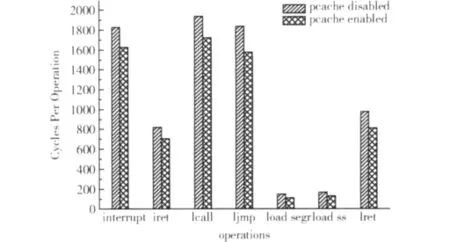
图4 启动保护缓存前后指令或操作的平均时钟周期
保护缓存主要提升中断操作和段操作指令的效率,那些频繁进行系统调用、内存局部性不好 (频繁产生页面异常)或I/O密集型的应用将从中获益。

图5 启动pcache前后系统调用和mtouch的执行时间
为测试保护缓存对系统调用效率及页面异常的影响,我们构造了scgen(System Call Generator)和mtouch(memory touch)两个测试程序,前者循环调用一定次数的gettimeofday(选择gettimeofday的主要原因在于该系统调用的工作很少,可以认为模式切换在其执行时间中占有很大比例),后者对一大块内存进行随机访问。图5给出了启动保护缓存前后,执行 2000,000~10,000,000次 gettimeofday系统调用或内存访问所耗费的时间。结果表明,启动保护缓存后,系统调用的效率有9%~27%的提升,内存访问的效率有7%~14%的提升。
我们选取tiobench[10]测试保护缓存对I/O密集型应用的影响,后者需频繁进行系统调用 (read/write)并产生磁盘中断。图6给出了在启动和关闭保护缓存的情况下在虚拟机中利用tiobench进行5次1GB磁盘读写操作的平均带宽和延迟。测试结果表明,引入保护缓存后,tiobench写操作和读操作的带宽分别最多提升了约12%和13%,读操作和写操作的延时分别最多降低了约9%和12%。
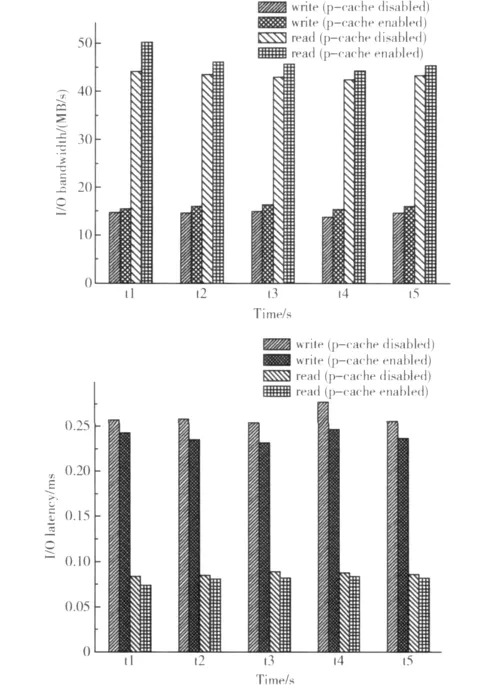
图6 启动保护缓存前后的I/O带宽和延迟
保护缓存的开销主要来自三方面,即在处理TLB-FILL事件时检测描述符表的物理地址、在写虚拟机物理内存时检测对描述符表的修改、以及修改描述符表时所导致的缓存项刷新。前两种开销仅是在原有代码基础上增加少量判断语句,几乎可以忽略。对于第三种开销,观测表明,操作系统对描述符表的修改次数相比保护检查来说频率很低,以Linux为例,对IDT的修改一般仅在系统引导以及加载驱动程序时进行,对GDT的修改仅发生在线程切换时 (GDT中第6~8号描述符用于线程本地存储)。通过运行nbench[11]测试集 (其中的大多数程序为计算密集型应用)测试保护缓存对普通应用程序的影响,结果如表2所示,表明保护缓存不会对普通应用程序的性能造成负面影响。
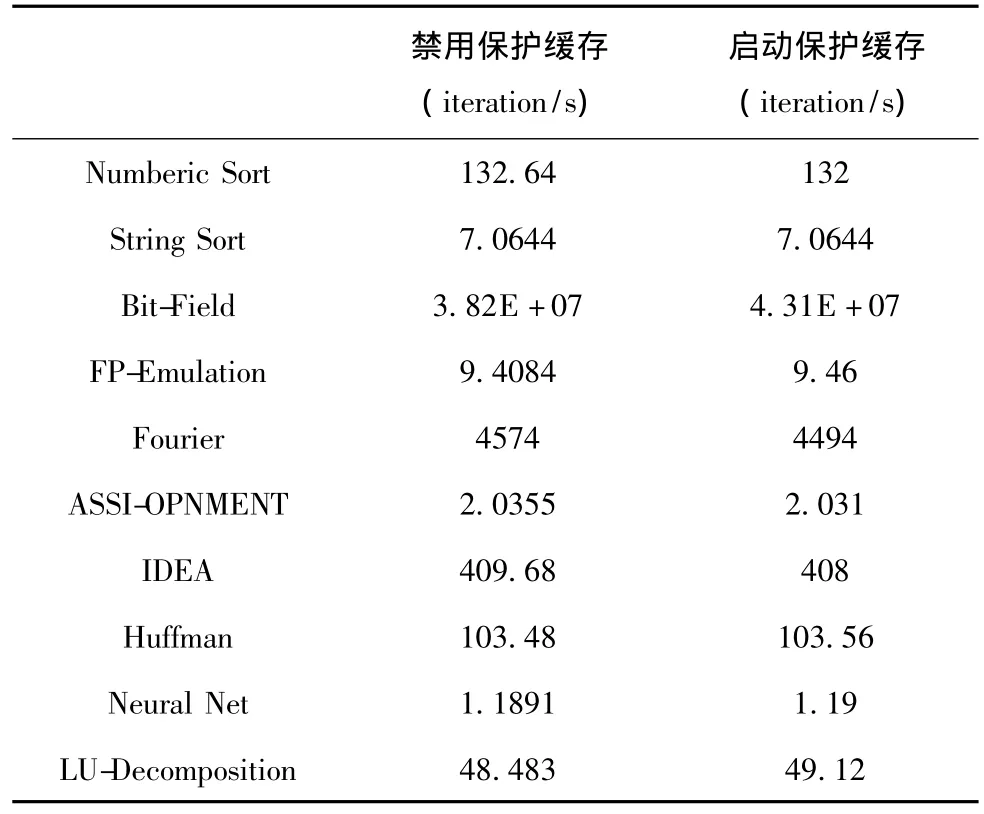
表2 启动保护缓存前后的nbench性能
5 结束语
本文提出了一种新颖的针对x86保护机制的系统仿真优化方法,测试表明,引入保护缓存后涉及保护检查的x86指令或操作的仿真效率提升了11%~24.5%,并且,使用这些指令或操作的系统调用、页面故障处理和I/O密集型应用的性能均得到了稳定的提升。
受环境限制,文章仅在同构条件下 (即在x86平台上仿真x86虚拟机)对保护缓存机制进行了验证,但本文的方法同样适用于在异构平台。另外,通过在处理器核心利用硬件实现保护缓存并增加若干指令,文章的思想也适用于软硬件协同系统仿真系统。
[1]HU Weiwu,WANG Jian,GAOXiang,et al,GODSON-3:A scalable multicore RISC process with x86 emulation [J].IEEE Micro,2009,29(2):17-29.
[2]CAO Hongjia.Research on micro-processor designing oriented dynamic binary translation technology[D].Changsha:Philosophy Doctor Dissertation of National University of Defense Technology(in Chinese).[曹宏嘉.面向微处理器设计的动态二进制翻译技术研究[D].长沙:国防科技大学,2005.]
[3]Prashanth P Bungale,Chi-Keung Luk,PinOS:A programmable framework for whole-system dynamic instrumentation[C]//Proceedings of the3rd international conference on Virtual execution environments.New York,ACM,2006:137-147.
[4]HENG Yin,Dawn Song,TEMU-binary code analysis via wholesystem layered annotative execution[R].Berkeley:UC Berkeley,2010.
[5]CAI Songsong,LIU Qi.Optimization of binary translator based on GODSON CPU [J].Computer Engineering,2009,35(7):280-282(in Chinese).[蔡嵩松,刘奇,基于龙芯处理器的二进制翻译器优化 [J].计算机工程,2009,35(7):280-282.]
[6]LI Jun,GUAN Haibing.Optimization of basic block overlapped redundancy in dynamic binary translation[J].Computer Engineering,2007,33(22):60-62(in Chinese).[李骏,管海兵.动态二级制翻译中基本块重叠冗余的优化[J].计算机工程,2007,33(22):60-62.]
[7]LONG Kaiwen,FU Yuzhuo.Interrupt handling strategy in systemlevel dynamic binary translator[J].Computer Engineering,2008,34(22):245-246(in Chinese).[龙开文,付宇卓,系统级动态二进制翻译器的中断处理策略 [J].计算机工程,2008,34(22):245-246.]
[8]XING Chong,FU Yuzhuo.Code cache index in system-level dynamic binary translation [J].Computer Engineering,2008,34(22):253-255(in Chinese).[邢冲,付宇卓,系统级动态二进制翻译中的代码 cache索引 [J].计算机工程,2008,34(22):253-255.]
[9]Fabrice Bellard,QEMU:A fast and portable dynamic translator[C]//Proceedings of the annual conference on USENIX Annual Technical Conference, Berkeley:USENIX Association, 2005:41-46.
[10]James Manning,Mika Kuoppala,Threaded I/O tester[CP/OL].[2012-05-10].http://sourceforge.net/projects/tiobench/.
[11]Nbench [CP/OL].[2012-05-10].http://en.wikipedia.org/wiki/NBench.
猜你喜欢
测绘学报(2022年12期)2022-02-13
计算机应用与软件(2020年6期)2020-06-16
中国计算机报(2020年9期)2020-03-25
商品与质量(2019年34期)2019-11-29
计算机系统应用(2019年3期)2019-03-11
电子制作(2019年2期)2019-02-14
铁路计算机应用(2018年4期)2018-05-03
自动化学报(2016年4期)2016-11-08
通信电源技术(2016年5期)2016-03-22
中国信息化·学术版(2013年1期)2013-05-28
