
集成桌面搜索引擎的内容检测系统设计
2013-07-25 02:28贾默,陈梅
计算机工程与设计 2013年2期
贾 默,陈 梅
(贵州大学计算机科学与信息学院,贵州贵阳550025)
0 引言
PC机的大量使用以及磁盘存储能力的增强,使得单个桌面机所能包含的信息量也随之增大。特别是对于一些企业和机构,使用人员所接触的文件、电子材料等信息与日俱增,那么难以保证每个终端所存储的信息都能达到企业的规定标准。因此,对于这种能够达到TB级别的桌面内容的监控和检测成为了即网络内容检测之后的下一个关注点,企业对于掌握其内部PC的桌面内容的详细情况的需求也越来越迫切。由此我们将内容检测的范围深入到了与用户粘性更大的桌面机上。所谓针对的对象不同,那么解决问题的策略也需要因地制宜。针对所要研究的对象是桌面内容来说,本文将桌面搜索引擎[1]集成到系统中。桌面搜索引擎则成为本文设计的主要关注点,而传统桌面搜索引擎在初次建立全文索引时用时较长,且由于它为所有内容片断均建立索引导致索引文件较大,并随着用户的使用不断增大,占用了用户较大的磁盘空间,通常达到了GB级别[2]。针对以上弊端以及系统的实际用户需求,本文对传统桌面搜索引擎的一些设计思路进行了相应的修改,使得设计既要能够保证系统拥有完备的功能,并且还能够高效的运行,从而带来较好的用户体验。
1 系统设计模型与功能
1.1 系统总体设计模型
本文设计的内容检测系统需要管理桌面搜索引擎的平台和桌面搜索引擎两部分组成。将管理平台部署在服务器上,使检查终端可以仅通过浏览器便完成了对桌面搜索引擎的流程管理。检查代理端则通过安装桌面搜索引擎,接受检查终端发送的相关参数,完成检测工作并报告给检查终端最终的结果。系统总体模型图如图1所示[3]。
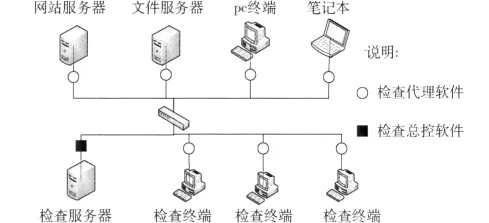
图1 系统总体模型
检测总控端通过制定计划、目录设置、任务类型3个模块设置搜索任务所需要的搜索内容、搜索对象等搜索条件,而检查代理端的PC机只要处于开机状态,那么这个代理端的桌面搜索引擎会及时监听到总控端所发布的这些搜索条件,根据这些条件,对磁盘内容进行扫描和检测的工作将自动开始,搜索完成后把符合条件的文件信息的集合报告给检测总控端。总控端则会通过查看报告模块对代理端上报的疑似文件的详细信息进行查看,同时还可以提取文件全文对相关信息进行深入了解。
由于处于代理端的桌面搜索引擎是作为系统的集成模块,因此它为了配合控制端的调度,设计思路也做了相应的调整。集成的桌面搜索引擎不采用全文索引的方式,因为总控端会提供表达式作为搜索的内容,因此,本文设计的桌面搜索引擎将抽取表达式中的关键字作为磁盘搜索的内容并且仅为它们建立索引,这样的设计不仅节省了传统桌面搜索引擎首次建立全文索引时所需要花费的大量时间,可能会达到10个小时以上,并且,内容检测系统的用户与传统桌面搜索引擎的用户的使用范围以及使用需求不同。传统桌面搜索引擎的用户更多的是搜索正常的文件内容,较之需要搜索的关键字来说,其搜索内容更广、搜索范围更大[3]。内容检测系统只针对被提供的关键字进行检测,而相对于一般文件内容来说,需要搜索的关键字的存在比例总是较小的,因此,本文设计的系统中所集成的桌面搜索引擎改变了全文索引的策略,它在首次遍历过程中采用转换技术将文件进行转换,而不是对所有片段建立索引,并且转换所花费的时间比建立全文索引的时间更短,在此基础上,系统执行每一次新的搜索任务时,通过抓取转换文档中的内容来确定文件命中的情况,据此为且仅为当次关键字建立索引,虽然为当次关键字建立索引的时间要比建立好全文索引的响应时间长,但是在用户可接受的范围内,重要的是这样的设计方法省掉了为许多不会搜索到的文件片段建立的索引所花费的空间以及时间[4]。
1.2 检查总控端功能模块
根据以上的总体设计,总控端由5个功能模块组成,即制定计划、查看报告、设置目录、任务类型。
对于制定计划来说,主要分为3个部分,第一部分是对于逻辑表达式的管理,即扫描任务中需要搜索的内容,由于逻辑表达式的更新频率快且累计数量较大,因此采用主题树对逻辑表达式进行合理的分类,用户可以直接在主题树上进行更新、编辑等操作来维护表达式以及其所属主题,然后选中本次搜索需要的表达式之后就可以进行第二部分的操作;第二部分是对搜索对象的设置,即哪些终端机需要执行该计划。由于大多数机构都将人员以部门来进行分配,此处仿照上述主题树建立了部门树,用户可以在部门树结构上对部门名称以及部门下属各PC机的IP信息进行编辑,更重要的是通过树结构选中需要执行计划的部门或者PC机。第三部分只需要用户选择搜索的时间,如立即搜索或者是周期性的进行搜索等。这时计划需要的基本条件已经设置完成,它会根据执行时间将本次设置的信息发送到检查代理端,代理端由此开始执行搜索计划。
当代理端完成了搜索任务之后,它会把符合搜索条件的文件信息上报到控制端,这时用户可以通过查看报告模块查看扫描结果。查看报告模块同样提供了主题树、部门树来管理所有报告,用户通过选中某些条件选项就可以查看相应的报告信息。当然,如果对某个文件比较关注,可以查看该报告的详细信息,如其匹配的逻辑表达式是哪些、扫描该文件的日期和时间等,特别是用户还可以要求下载文件的全文进行查看,确定是否存在不合乎规范的因素。
为了避免桌面搜索引擎影响到用户的正常使用,设计了设置目录模块让用户设置白目录,扫描时将会忽略这些目录。任务类型模块主要是为了辅助制定计划模块,它提供了设置和编辑任务类型的功能。
1.3 检查代理端功能模块
代理端的桌面搜索引擎由表达式解析、内容扫描、通信服务、文档转换四大模块构成。
表达式解析模块主要工作是获取总控端发送的该次扫描的逻辑表达式并对逻辑表达式进行语法解析,从中获取新的关键字,然后为它们建立索引。内容扫描模块则需要负责两方面的工作,第一部分是遍历各磁盘目录,搜索除了白目录之外的所有目录中的电子文档,借助匹配算法对解析出来的关键字和文本进行匹配,同时统计符合每个关键字的文件的基本信息,如关键字出现在该文件中的次数等,由此进一步得到匹配关键字所属表达式的文件信息;第二部分是捕捉磁盘上的电子文档的变化,如果代理端用户有新增文件、删除文件、更新文件等操作,那么将根据不同操作修改、更新文件与表达式之间的映射关系。
内容扫描模块的匹配过程需要关键字与文件内容进行匹配,但是如果每次匹配都要打开各种格式的电子文档,那么将消耗大量的内存空间,这样的策略会带来比较大的性能问题。因此,设计了文档转换模块,把.doc、.xls、.pdf等格式的电子文档全部转换成文本文件,然后再抽取其中的文本内容进行匹配。当内容扫描模块捕捉到文档发生改动时,会重新请求转换模块转换该文件并且重建文件和关键字之间的映射关系,从而保证向总控端报告的结果的准确性和及时性,这样可以大大减少内存开销,确保系统的整体性能。
通信服务模块则为其他3个模块进行服务,例如当代理端与服务器进行通信、内容扫描模块与文档转换模块的通信、总控端请求全文查看时上传文件所需要的FTP通信等等,都需要该模块的支持。
结合工程实际情况,本次大坝除险加固设计拟采用砂岩压重上游坝坡的方式,提高上游坝坡的稳定性。上游坝坡加固设计方案为:压重体顶宽5m,迎水面坡比1∶2,高度3m,如图1。
文档转换模块则不断接收通信服务模块发出的转换指令,然后通过分解指令内容获得需要进行转换的文档的所在位置,然后依照文档的后缀内容进行相关格式的处理。其中,不仅要考虑到转换是否成功的问题,同时,转换频率也成为首当其冲的重点问题,当需要转换的内容不断涌入队列,如果程序不加以控制,转换频率过快将会导致内存满溢的现象出现,因此,本文设计的检测系统将考虑转换过程中cpu的使用率,如果使用率超过了70%,那么将暂停转换程序的运行,稍事停歇,等待cpu使用率下降到不紧张状态时再重新启动转换程序,防止内存溢出以及cpu使用率过高而影响用户使用其他应用的良好体验。
2 主要算法介绍
根据关键字对文件进行匹配的算法设计成为影响整个系统性能的重点。
模式匹配算法主要分为单模式匹配算法和多模式匹配算法。单模式匹配算法即遍历文本一遍只能匹配一个模式串。单模式匹配的经典算法是BM算法和KMP算法。多模式匹配算法则在一次文本遍历过程中查找所有模式串。它的经典算法包括Wu-Manber算法和AC算法。其中,Wu-Manber算法是由BM算法延伸出来的多模式匹配算法,它的时间复杂度由三部分来计算。首先算法将模式串分隔成一定长度的块并计算滑动距离,设其为B;设需要匹配的文本长度为N;取多模式串中的最短模式串的长度为M,由此可以计算其时间复杂度为O(BN/M)。可见,当其有比较短的模式串的时候,那么M值将随着该最短模式串的长度而取值,则移位的值将受到极大的限制,从而匹配过程的加速也将受限。而根据本文的系统需求,不仅需要数量较大的关键字同时进行匹配,而且系统的关键字由用户提供,短的关键字也不乏其中,如果采用单模式匹配算法或者Wu-Manber算法,那么匹配过程的效率和速度不能够得到保证,因此系统设计采用多模式匹配算法中的AC算法来实现匹配功能。
2.1 AC算法原理分析
Aho-Corasick算法[5],简称AC自动机,1975年产生于贝尔实验室,其应用有限自动机将字符比较转化为了状态转移。算法的主要结构是在预处理阶段,自动机将创建3个函数,转向函数goto,失效函数failure和输出函数output,三者生成了树形有限自动机。状态树如图2所示。
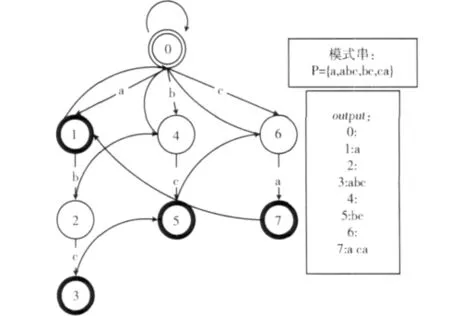
图2 状态树
算法主要原理为:第一步,构造树状状态转移图。设节点集合为T={n|n∈Z*,0≤n≤7},设t1≠t2and t1,t2,t3∈T,边的集合为 V={a,b,c},设 v1≠v2and v1,v2,v3∈V,模式串的集合为P={a,abc,bc,ca},设p1≠p2and p1,p2∈P;其中T代表自动机的状态集合,P代表所有模式串的集合,V代表组成P的所有单个元素的集合。转向函数goto将根据P组建树状结构,由初始状态t0开始,根据输入的p1中的每个v1创建t1,如果t1已经存在,那么循环该过程建立剩下的树结构[6]。
第二步,建立失效函数failure,提高匹配效率。失效函数failure则将在goto函数的基础上为每个t1建立失效指针,失效指针将指向在匹配v1失败的时候最节省后续匹配次数的t2。而初始状态的失效指针指向自己,初始状态的孩子节点的失效指针也将指向初始状态,即回到终点。相对于KMP算法,失效函数成为了一项重要改进,其不再浪费已经匹配过的所有信息,而是利用所有已匹配信息为后续的匹配工作提供再利用的机会。
第三步,p1与文本进行匹配,如果v1匹配成功,那么沿着树结构继续完成整个过程,直到达到某个终结节点v2;如果v1匹配失败,那么沿着v1的失效指针所指向的v3继续匹配过程,直到回到初始状态。
而output函数将通过判断t1来记录p1形成的信息,如果是终结状态则记录p1,否则为空,并且在建立failure函数的过程中也会动态修改output函数。
AC算法的时间复杂度为O(N),其中N为需要匹配的文本长度。由此可见,其时间复杂度与模式串的多少和长度均无关,比较适合应用于本系统中。与其他算法相比,其能够较大的提高匹配的效率,且较少的依赖其他因素的干扰。
2.2 算法应用
AC算法主要应用于桌面搜索引擎的内容扫描模块中。桌面搜索引擎所处的检查代理端收到总控端提供的新的逻辑表达式并且将它们进行了语法解析后,它将调用算法对解析出来的关键字进行有效的组织和应用。首先把关键字作为模式串用来初始化状态树,即完成goto函数的构建,然后为树结构中的每个节点建立失效指针,创建失效函数failure,完成算法原理的前两步。根据算法的第三步,内容扫描模块会逐个获取已转换文档队列中等待的文本文件,抽取它们的内容作为文本,然后与状态树中的每个模式串进行匹配,这个过程中累加每个关键字在文件中匹配成功的次数,根据这个数值决定是否将文件作为疑似文件报告给总控端。
当本次搜索任务结束后,系统会收集出现的新关键字,然后清除这棵树,减少每次保存树结构所带来的系统负担。
3 实现综述
通过使用python语言以及多线程、AJAX等技术对本文的设计加以实现。用户可以登录网站使用制定任务计划、设置白名单和任务类型等功能制定搜索计划,同时也可以查看已经搜索的结果。
一旦计划发布后,代理端的桌面搜索引擎将启动main进程和converter进程,main进程主要负责调度多个线程同步启动,包括磁盘遍历walker、磁盘监测watcher、任务搜索scan、关键字处理index、通信服务udp等线程。scan负责接收总控端发送的有关搜索需要的所有条件,包括逻辑表达式、白名单等,然后对逻辑表达式进行语法处理获取关键字并且保存在线程共享的字典keyword中。walker线程会根据白名单对磁盘进行扫描,它会把需要转换的文件放入转换队列中等待converter进程对它进行转换,不需要转换的文件放入已转换队列queue中等待index对它的提取。converter进程监听到队列中有需要转换的文件时,它会把相应格式的电子文档全部转换成文本文件,并且把这个文件放入已转换队列中等待index的提取。index线程从共享字典keyword中获取关键字之后,根据AC算法为它们建立树形结构,同时它会从已转换队列queue中不断获取文本进行匹配,统计关键字在文件中的匹配信息。完成整个搜索过程后,通过udp线程的支持,scan会将搜索结果报告给总控端。实验证明系统能够高效的完成检测桌面内容的功能。
4 系统验证
4.1 验证环境
PC机个数为6台,每台PC机的配置如下:
Core 2 E7500 2.93,2GB内存,320GB硬盘,所使用的操作系统范围是:WINDOWS 7WINDOWS VISTAWINDOWS 8WINDOWSXP。
4.2 验证数据
在每个PC上除了C盘之外的每个磁盘中放置一个测试文件夹,其中包含.doc、.docx、.xls、.xlsx、.rtf、.pdf、.txt格式的文件各1000个,并且每个文件夹中设定了500个包含关键字的命中文件,每个机器上除了C盘之外,共有3个磁盘,因此每个机器上有测试文件共21000个,其中包含关键字的命中文件共有1500个。
6台机器上的测试数据大小各为:11.19GB、16.74GB、10.53GB、10.41GB、14.43GB、16.50GB。
4.3 验证方法及结果
4.3.1 功能验证
对于检查总控端,管理员可以登录远程服务器端,打开网站链接,选择搜索关键字若干,然后可以针对包含关键字的特定代理端PC下发相应搜索任务,并能查看指令下发后代理端提交的搜索结果。
对于代理端的六台PC机,它们必须处于开机状态同时已经启动了代理端检测软件,启动后右下角出现软件图标,并且图标处于待搜索状态。指令下发之后,首先是图标变成正在搜索状态,然后弹出搜索页面,证明代理端软件能够正常接收到下发指令,并自动开始搜索。搜索开始后,页面会不断显示当前更新到的遍历文件、它的路径和类型、搜索用时以及索引情况,遍历结束后将显示正在转换的文档个数。与此同时,在遍历以及转换过程中对测试文件夹中包含关键字的文件进行复制、新建、修改等操作,右下角的图标能够正常显示监控变化,提示有新的监控信息。在整个搜索过程中,只要索引到目标文件,即该文件已经被遍历到并且转换成功,那么页面会显示命中文件路径、时间、以及在文件中命中了关键字的片段。通过点击文件路径可以查看原文,然后确定是否排除或者确定该文件是否是想要的文件,页面也将记录该条文件记录。
4.3.2 性能验证
本文所设计的内容检测系统主要集成了桌面搜索引擎,因此系统性能的主要监测点落在桌面搜索引擎的部分,而同类型的桌面搜索软件众多,本文选择了GoogleDesktop作为参考对象。
GoogleDesktop[8]是利用系统空闲时间对用户设置的文件范围和类型建立全文索引,即使用户可能不会搜索到的内容,这样便于用户今后搜索内容的便捷。
4.3.2.1 全文索引和文档转换用时验证
基于上述机制的描述,进行以下测试,让本文设计的软件和Googledesktop在每个测试PC上同时启动开始工作。表1列出GoogleDesktop对磁盘上的所有内容进行全文索引的用时和本文系统在首次进行全盘遍历、转换的用时,其中所有磁盘内容包括测试文件夹在内。测试尽量在无操作的基础上进行,这样可以保证速度达到最快。[9]
如表1所示,本文系统的遍历和转换过程的用时相对更短,有效避免了Google建立全文索引用时过长的弊端。
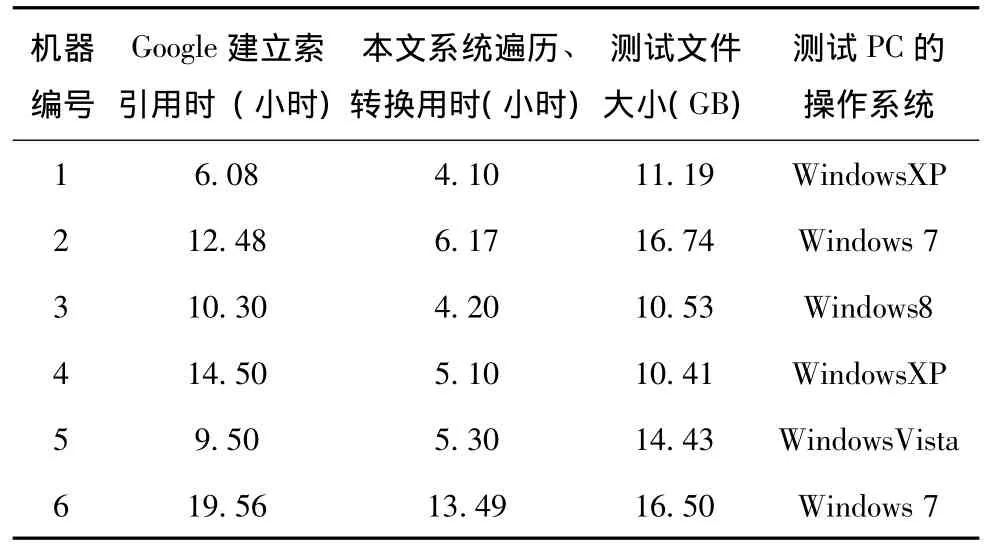
表1 全文索引和文档转换用时对比
4.3.2.2 效率验证
在其中一台测试PC上搜索预设的100个较特殊的关键字对两款系统进行测试,然后对这100组查全率和查准率取平均值,以此验证软件的效率。[10]对比情况如图3所示,本文设计的内容检测系统与GoogleDesktop相比,查全率与查准率相差甚微,因此可以说明本文系统的高效性。
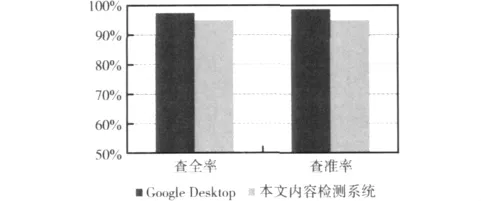
图3 效率对比
5 结束语
实验表明,本文所设计的内容扫描与检测系统的查询效率、查询准确率较高,它将改进后的桌面搜索引擎集成在被检测终端来避免建立全文索引用时过长的问题,同时,通过只为被搜索关键字建立索引提高了建立索引的针对性,避免了索引文件过大的问题。企业管理人员可以根据自己的实际规则或规范实时、高效的通过系统管理平台对处于网络中的内部PC机的桌面内容加以监督和检查,不仅实现了企业管理中的监控需求,并且为确保和追溯PC的桌面内容达到企业要求提供了自动化的辅助。
[1]LI Xiaoxin.Design of a desktop search engine [J].Computer Knowledge and Technology,2011,7(20):4949-4951(in Chinese).[李晓鑫.桌面搜索引擎设计[J].电脑知识与技术,2011,7(20):4949-4951.]
[2]MENGMeihua.Design and implementation of desktop search engine[D].Dalian:Dalian University of Technology,2009(in Chinese).[孟美华.桌面搜索引擎的设计与实现 [D].大连:大连理工大学系统工程,2009.]
[3]Clay Shields, Ophir Frieder.A system for the proactive,continuous,and efficient collection of digital forensic evidence[J].Digital investigation,2011,8(s1):3-13.
[4]Cohen M I,Bilby D.Distributed forensics and incident response in the enterprise[J].Digital investigation,2011,8(s1):101-110.
[5]CONG Lei.Research and implement of desktop search engine[D].Beijing:Beijing University of Chemical Technology,2006(in Chinese).[丛磊.桌面搜索引擎的研究与实现[D].北京:北京化工大学,2006.]
[6]WANG Peifeng,LI Xiaoli.Research on multi-pattern matching algorithms based on Aho-Corasick algorithm [J].Application Research of Computers,2011,28(4):1251-1254(in Chinese).[王培凤,李莉晓.基于Aho-Corasick算法的多模式匹配算法研究 [J].计算机应用研究,2011,28(4):1251-1259.]
[7]LI Weinan,E Yuepeng,GE Jingguo,et al.Multi-pattern matching algorithms and hardware based implementation[J].Journal of software,2006,17(12):2403-2415(in Chinese).[李伟男,鄂跃鹏,葛敬国,等.多模式匹配算法及硬件实现[J].软件学报,2006,17(12):2403-2415.]
[8]Benjamin Turnbull,DBarry Blundell.Google desktop as a source of digital evidence [J].International Journal of Digital Evidence,2006,5(1):1-12.
[9]LI Weichao.Evaluation of desktop search engine [J].Journal of Modern Information,2007(12):211-213(in Chinese).[李伟超.桌面搜索引擎评析 [J].现代情报,2007(12):211-213.]
[10]XIE Haichao.The research and implementation of mobile search engine[D].Dalian:Dalian University of Technology,2009(in Chinese).[谢海潮.手机桌面搜索引擎的研究与实现[D].大连:大连理工大学,2009.]
猜你喜欢
华人时刊(2022年1期)2022-04-26
疯狂英语·新阅版(2020年11期)2020-12-21
装备制造技术(2020年12期)2020-05-22
铁道通信信号(2020年12期)2020-03-29
动漫界·幼教365(大班)(2019年10期)2019-10-28
党的生活(黑龙江)(2017年10期)2017-11-09
中国卫生(2015年12期)2015-11-10
上海文化(新批评)(2014年5期)2014-02-12
科学导报·学术论坛(2013年5期)2013-06-26
微型计算机·Geek(2009年1期)2009-12-15
