
辅助成本估算系统化调研的自动化方法
2013-07-25 02:28孙悦明
计算机工程与设计 2013年2期
孙悦明,杨 叶,张 文
(1.中国科学院软件研究所互联网软件技术实验室,北京100190;2.中国科学院研究生院,北京100049)
0 引言
系统化调研 (systematic literature review,SLR)旨在对于某一特定研究问题,查找、评估、分析与其相关的所有文献资料[1],通过文献调研和阅读的方法以求解这一特定问题的答案。它主要包含5个步骤:寻找初始文献集合,筛选文献,评估筛选出的文献质量,相关数据抽取,综合调研结论。一般来说,传统SLR的工作量会远多于普通的调研方法[1]。系统化调研时,研究人员需要从多种多样的资源中收集整理信息,包括电子数据库,技术文档,专家咨询等等。因此,亟需一种能够帮助减少工作量开销并保证质量的辅助SLR的方法,本文针对该问题开展研究。
1 方法介绍
本文提出了一个基于句法分析的软件估算本体分析方法。通过该方法帮助降低SLR过程中“筛选文献”步骤所需要的人力开销。从摘要入手,对摘要进行结构化分析,抽取出概念与知识信息,并构建软件估算本体 (COSt estimation ONTology,COSONT),应用于软件估算系统化调研。通过对比实验,本文证明了应用此方法辅助SLR的有效性。同时,本文所提出的Ontology可以用来辅助研究人员在软件估算领域众多其他的经验研究。方法详细的结构见图1。
如图1所示,本文所使用的数据集由347篇软件估算论文的摘要组成。利用摘要的内在结构化特点,我们使用句法分析工具分析摘要特定句子的结构,总结出一套句法规则。通过结构化分析摘要提取出摘要的主体部分。接着从该部分抽取概念知识,得到名词词组。最后用这些名词词组建立软件估算Ontology,COSONT,用以组织这些概念知识以及他们之间的关系。通过使用COSONT,可以大幅度的减少SLR第二步骤,也即筛选文献所需要的工作量。
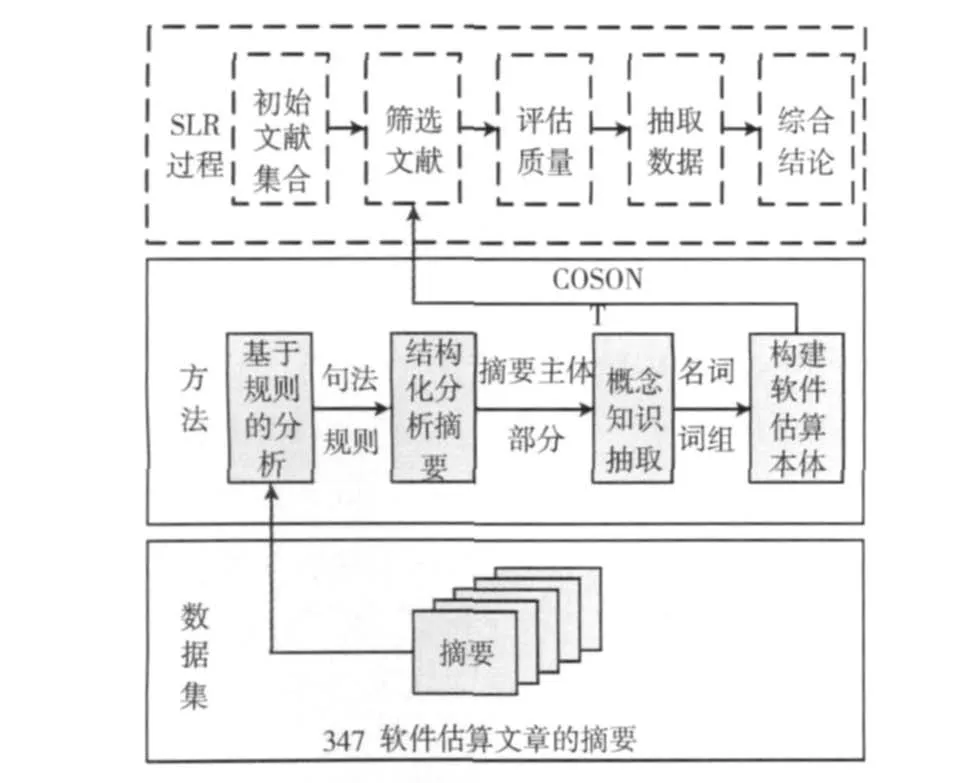
图1 方法结构
1.1 基于规则的分析
1.1.1 数据集合
本文收集了软件工作量估算领域相关的论文。文献收集按照如下步骤执行:①使用“effort prediction”作为原始的查询字符串。②在4个常用电子数据库中查找文献,这4个数据库是:IEEE Explorer,ACM Digital Library,Springer and Science Direct。我们得到了645篇论文。③人工检查所有论文的摘要,题目,关键字部分,判断是否真的是软件估算领域的论文。④对于那些通过如上检查仍不能确定的论文,通过进一步阅读全文来判断是否相关。⑤在整个过程中,本文邀请了领域专家进行监督,以保证最终结果的质量与公正性。通过认真的筛选,最终挑选出来了347篇文章,构成了最终数据集。
1.1.2 摘要结构分析
论文的各个部分中,摘要是最重要的部分。一篇组织良好的摘要能够清楚的概括文章内容,帮助相关研究人员快速找到所需内容。通过仔细分析了大量的摘要之后发现,绝大部分摘要都包括背景,主体,结论3个部分。其中的主体部分会清晰的概括文章“具体做了哪些工作”,包含相对来说最重要的信息。因此本文需要提取出摘要的主体部分。首先做出如下定义:
定义1 Background:背景部分。
Main part:主体部分。
Conclusion:结论部分。
MAINSEN:主体部分的第一个句子。
CONCLU:结论部分的第一个句子。
则一篇摘要可以表示成背景,主体,结论三部分的集合。
Abstract=(Background,Main part,Conclusion)
主体部分可以表示为首句MAINSEN与其余句子的集合。
Main part=(MAINSEN,…,…)
结论部分可以表示为首句CONCLU与其余句子的集合。
Conclusion=(CONCLU,…,…)
如果能定位出MAINSEN与CONCLU,那么这两句中间的内容就是摘要的主体部分。基于这一分析,本文提出了一种基于句法规则的方法定位摘要的主体部分。
1.2 语法和句法规则
本文根据句子分析的统计信息制定规则。这里使用了Stanford Parser[2]。这个工具可以解析出句子的语法结构。比如,那些词形成了词组,哪个词组是句子的主语或是宾语等。具体的,首先人工标注MAINSEN和CONCLU的集合。然后使用该工具解析这个集合中的每个句子。这些句子的语法成分 (如介词短语等)包含了一些特定的词组。比如“In this paper”就经常出现在MAINSEN句子的句首介词短语中。如果用PP表示介词短语,NP和VP分别表示句子的主语结构和动宾结构。那么句法规则可以定义如下。
1.2.1 MAINSEN规则:
定义2 mainsen-x1:出现在MAINSEN的PP结构中的词组。
mainsen-x2:出现在MAINSEN的NP结构中的词组。
mainsen-x3:出现在MAINSEN的VP结构中的词组。
R1:S=PP,NPVP
R2:S=NP VP
那么一个MAINSEN句子应该匹配R1、R2正则表达式所表示的规则。其中R1规则需要匹配PP与VP;R2规则需要匹配NP与VP。
为了定位一篇摘要的MAINSEN,从前往后的检查摘要中的每个句子。如果找到了一个句子匹配R1,接下来继续检查它的PP与VP部分是否也包含 mainsen-x1与 mainsen-x3中所定义的词汇,如果包含,那么它就是该摘要的MAINSEN。如果匹配了R2,还要继续检查它的NP与VP部分是否也包含mainsen-x2与mainsen-x3中定义的词汇。如果包含,那么它也是该摘要的MAINSEN。如果既不匹配R1也不匹配R2,则这个句子不可能是MAINSEN,继续检查下一个句子,直到全部句子都检查完为止。
举个具体的例子,如下的句子分别匹配R1,并且在相应的PP,NP或VP里面包含相应的标示性短语 (以粗体字显示)。
In this paper,we propose an approach that converts cost estimation into a classification problem and that classifies new software projects in one of the effort classes,each of which corresponds to an effort interval.
1.2.2 CONCLU规则
定义3 conclu-x1:出现在CONCLU的PP结构中的词组。
conclu-x2:出现在CONCLU的NP结构中的词组。
conclu-x3:出现在CONCLU的VP结构中的词组。
Conclu-extra:能够直接表示一个句子是CONCLU的词组集合。
R3:S=(PP)+NP VP
CONCLU应该按照如下步骤寻找:
(1)它的位置必须出现在MAINSEN以后
(2)匹配规则R3,并且在PP,NP,VP结构中分别包含 conclu-x1,conclu-x2,conclu-x3。
(3)如果不匹配R3,那么它必须包含conclu-extra中特定的词组。
(4)如果都不满足,那么它不是CONCLU,继续向后寻找,直到全部句子都检查完为止。
值得一提的是,由于一些作者更喜欢在正文里面详细的描述他们的实验结果与结论,或者结论过于复杂而在摘要中很难说清楚等原因,一篇摘要中没有结论的情况也比较常见。
下面的句子匹配R3,并且在相应的语法结构里面包含相应的标示性短语 (以粗体字显示)。
Results of the study show a significant correlation between the software development effort and all three models.
1.2.3 使用规则分隔摘要
有了这些规则,定位时从前往后的扫描摘要中的每一个句子。当遇到一个句子匹配MAINSEN的规则,则把它标为MAINSEN。继续向后扫描,如果接着碰到一个句子匹配CONCLU,则两个分隔句都找到了。那么在MAINSEN(含)和CONCLU之间的部分就是摘要的主体部分。如果一个摘要只有MAINSEN而没定位到CONCLU,那么所有MAINSEN(含)后面直到摘要末尾的句子都是摘要的主体部分。
本文手工的标识了347篇文章摘要的MAINSEN与CONCLU,作为标准集合。然后使用上面定义的句法规则自动的寻找MAINSEN与CONCLU。最后的结果见表1。
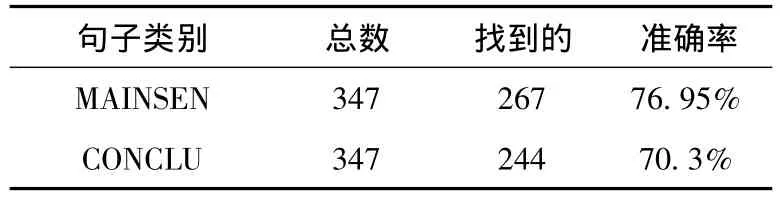
表1 自动找到的句子
总的摘要数是347个。正确定位的MAINSEN句子有267句,准确率达到了76.95%。CONCLU的准确率也达到了70.5%。在这个验证中,准确率是等于召回率的。结果显示我们基于规则的方法效果很好。
1.3 概念知识抽取
接下来从摘要的特定部分中抽取概念知识。由于名词词组通常都包含了一句话的主要信息,因此首先在摘要的主体部分抽取出所有的名词短语。但是并不是所有的名词短语都有意义,我们同时还制定了规则删除掉一些没有实际意义的词组,比如“a method”或“model”等。剩下的名词短语就是表示“这篇文章真正讲了什么”的概念知识。
通过一个实验验证是否从主体部分抽取出来的名词词组能够比较好的代表文章中的内容。本文邀请了4位专家从摘要中人工抽取出他们认为有意义的概念知识作为标准集合,再自动的从摘要中抽取概念知识,验证结果见表2。
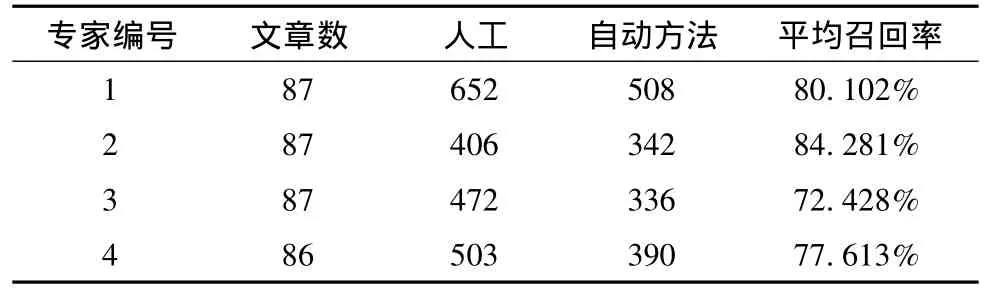
表2 验证结果
经过统计,自动抽取的词组的召回率达到了72.428%到84.281%。结果显示,该方法能够比较准确的从摘要中抽取出概念知识。下面介绍如何使用这些概念知识构建COSONT。
1.4 构建COSONT
为了构建COSONT,需要定义软件估算领域的Ontology结构。现在的软件估算研究中,广泛采用了许多经典的机器学习与数据挖掘的算法。基于在该领域多年的研究经验,本文总结出,通常研究人员比较感兴趣的问题是:文章中使用了哪些方法;使用了哪些度量元;以及文章涉及到了哪些软件工程知识。我们通过对软件估算领域文章作者给出的关键词进行分析,并把这些关键词分成了三大类别:模型词汇,度量元词汇,软件工程词汇。
定义4 模型词汇:文章中所使用的模型或方法,比如KNN;
度量元词汇:文章方法中所涉及到的度量元,比如准确率,方差等;
软件工程特征词汇:软件估算或软件工程领域词汇,比如COCOMO。
本 文 使 用 Protégé[3]构 建 COSt estimation ONTology(COSONT)。首先建立本体的类结构[4]。我们建立 Cost Knowledge类结构表示软件估算文章。通过对软件估算论文作者给出的关键词进行分类分析,我们建立了模型,度量元,软件工程特征词汇3个类结构以及他们内在的关系。用这三类词表示每篇文章摘要中所包含的概念知识信息。图2是实际的类结构。
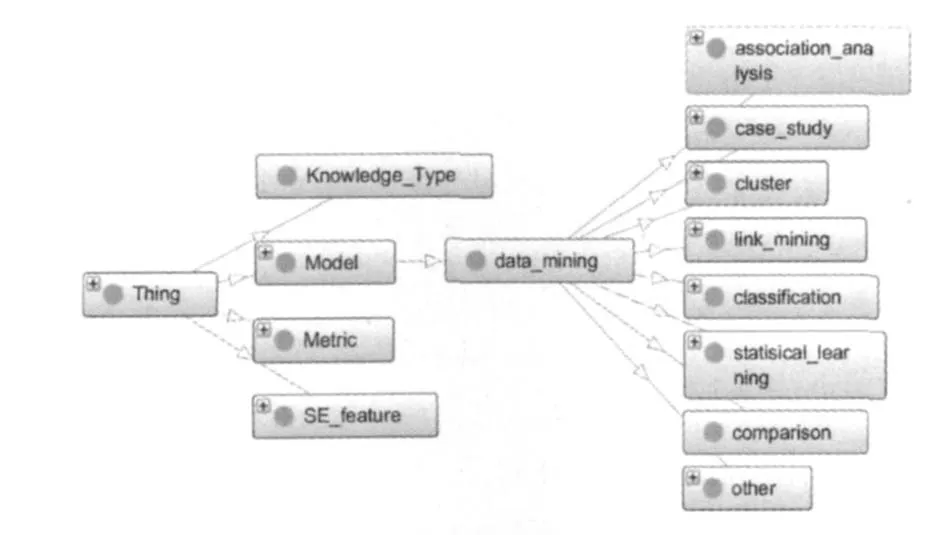
图2 COSONT结构
以模型词汇为例,首先建立一个名为Model的父类。他的子类包含链接挖掘方法,分类方法,统计学习方法,基于比较的方法,聚类方法以及关联规则分析方法。
接着把从文章中抽取出来的相关概念知识一一添加到这个结构当中。每篇文章都作为Cost Knowledge类的一个实例。从摘要主体部分抽取出来的名词短语则作为模型词汇,度量元词汇,软件工程词汇3种类结构的实例,分别加入到相应的类结构中。当所有的内容都添加到COSONT中以后,COSONT就建立好了。
2 方法评估
下面详细介绍使用COSONT自动化辅助SLR与手工SLR的对比实验。实验结果将从准确程度与工作量两个方面进行衡量。
由于回归与神经网络是软件估算中最常用的两种方法,所以SLR的主要目的就是比较这两种方法哪一个在软件估算领域效果更好。该实验邀请了四位拥有在估算方面SLR经验的专家。首先给这些专家每个人安排合适的培训,使得他们对整体任务有所了解。然后针对“筛选文献”步骤进行实验。
在实验中,四位专家需要在文献集中找到同SLR问题相关的文章。每个人分析347篇中的87篇左右的文章。主要的筛选准则是,摘要中必须同时提到回归与神经网络两种方法。那些纯粹的讨论与观点类型的文章则予以删除。本文使用COSONT来分析摘要的主体部分,找到符合筛选要求的论文。作为对照,几位专家需要认真阅读摘要内容,并根据他们个人的经验判断排除那些不相关的文章。同时他们还需要记录各自的工作量 (人时)。手工方法的统计结果见表3。
正如表3所示,一共有11篇文章被筛选了出来。从工作量统计可以看出,手工筛选确实是一项很费人力的工作。4位专家总的工作量是35个人时。然而,相对于手工方法,使用COSONT花费的总的时间可以忽略不计。并且,两种方法所确定的最终论文集合是相同的。
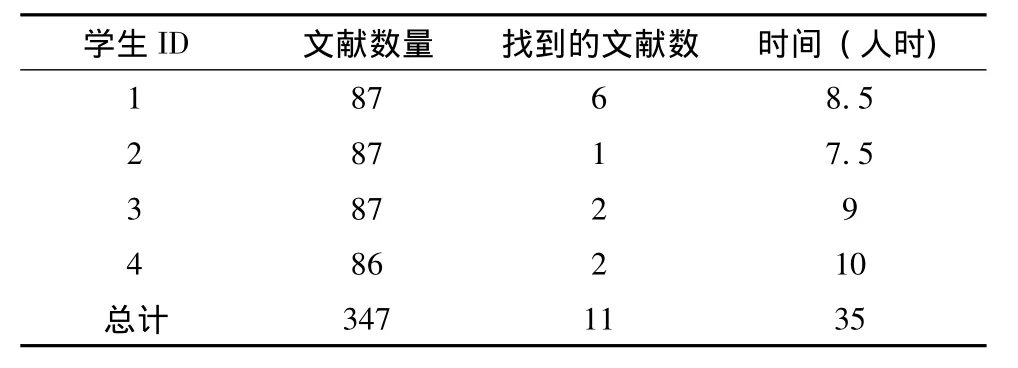
表3 手工筛选文献
3 讨论
从实验结果可以看出,使用COSONT既能得到不错的SLR效果,又能节省大量的时间。本文的工作利用了摘要自身的结构化信息。主要的依据是从结构化信息当中获得的概念知识信息一定会比由普通的关键字匹配得到的信息质量要高。并且建立了软件估算Ontology COSONT组织文献中的概念知识以及它们之间的关系。
然而本文的工作也存在着一些问题。首先,文献的正文部分也可以被用来进行概念知识抽取。虽然可能会给实验带来很多噪声,但同时也可能会遗漏很多重要的信息。在将来的工作中,我们将会尝试分析文献更多的部分,比如讨论部分、结论部分等。其次,本文建立的Ontology仅仅适用于软件估算。将来需要建立更加普适的软件工程Ontology结构,以辅助软件工程不同领域的SLR。
4 相关工作
系统化调研 (systematic literature review,SLR)在软件工程领域得到了广泛的使用[1]。通过调研大量相关文献,SLR可以全面准确的回答某个特定的研究问题。其中,第二步骤“筛选文献”需要几位评审人员制定严格的筛选规则,并审查大量的文献,以判断哪些文献是同研究问题真正紧密相关的。审查的内容主要包括文献的标题,关键字,摘要等部分。这部分工作需要非常大的工作量。
因此,很多研究都致力于怎样减轻SLR所需要的工作量。比如,He Zhang[5]等人使用了一个系统化的基于证据的方法来建立一个最优的SLR搜索策略。又如El Emam[6]等人使用EDC(electronic data capture)工具来自动化SLR的数据收集与查询优化过程。这些研究都没有从试图理解文献内容的角度来开展研究。而试图理解文献正是SLR过程中大量人工判断工作的基本目的。考虑到这方面因素,我们从试图理解文献的角度提出了辅助SLR过程的自动化方法。
Ontology在多个领域都受到了广泛的应用。首先,它是语义网的重要组成部分[7]。软件工程各个领域都可以用Ontology来辅助[8]。其次,知识管理领域也使用Ontology来自动的翻译数据模型[9]。Ontology也被广泛的应用于软件工程领域。比如,Yonggang Zhang等人[10]使用Ontology研究软件工程的安全性。Ontology能够很好的组织知识,表示知识,并能够支持机器推理。所以,本文使用Ontology作为研究工作的基础。
5 结束语
本文提出了一种利用语法与句法分析技术从摘要中自动化的抽取概念知识的方法,利用此方法减轻SLR过程所需要的大量的工作量。首先对摘要进行了结构化划分。通过基于规则的方法,摘要可以被划分成三部分。然后我们从摘要的主体部分抽取概念知识。最后建立了软件估算Ontology——COSONT自动化的支持SLR过程。本文还通过对比实验证明了该方法能够有效的辅助SLR。尤其是降低“筛选文献”步骤所需要的工作量,同时还保证了与手工SLR近似的效果。基于此,本文的贡献包括:①结构化分析文章的摘要部分,并从其中抽取概念知识。②在抽取出的概念知识基础上,建立了软件估算领域的Ontology结构,并以此来辅助SLR。
[1]Kitchenham B A,Emilia Mendes,Guilherme Horta Travassos.Cross versus within-company cost estimation studies:A systematic review[J].IEEE Trans Software Eng,2007,33(5):316-329.
[2]Marie-Catherine de Marneffe,Bill MacCartney,Christopher D Manning.Generating typed dependency parses from phrase structure parses[C]//Genoa,Italy:LREC,2006.
[3]Tania Tudorache,Natasha Noy Jennifer Vendetti,Timothy Redmond.Collaborative ontology development with protégé[R].Amsterdam,2009.
[4]Michel V,En Bossche,Peter Ross,et al.Ontology driven software engineering for real life applications[C]//Innsbruck,Austria:SWESE,2007.
[5]He Zhang,Muhammad Ali Babar,Paolo Tell.Identifying relevant studies in software engineering[J].Information and Software Technology,2010,53(6):625-637.
[6]Khaled El Emam,Elizabeth Jonker,Margaret Sampson,et al.The use of electronic datacapture tools in clinical trials:Web-survey of 259 Canadian trials[J].Journal of Medical Internet Research,2009,11(1):e8
[7]Zhao Yajing,Dong Jing,Tu Peng.Ontology classification for semantic-web-based software engineering[J].IEEE Transactions on Services Computing,2009,2(4):303-317.
[8]Hans-Jorg Happel,Stefan Seedorf.Applica-tions of ontologies in software engineering[C]//SWESE,held at ISWC,2006.
[9]Kurt Schneider.Experience and knowledge management in software engineering[M].Springer,2009:99-109.
[10]Zhang Yonggang,Juergen Rilling,Volker haarslev.An ontologybased approach to software comprehension-reasoning about security concerns[C]//Computer Software and Applications Conference,2006:333-342.
