
基于改进遗传算法的网络零售企业逆向物流网络规划
2013-07-09 03:08计三有敖弟维
武汉理工大学学报(交通科学与工程版) 2013年3期
计三有 敖弟维 王 勇
(武汉理工大学物流工程学院 武汉 430063)
网络零售企业是在网上做零售销售的企业,主要以B2C(商家对客户)进行网上销售为主要的经营模式.据中国电子商务研究中心监测数据显示,2011第一季度中国网络零售市场交易规模达到1 700亿元,同比增长提速.其中B2C企业网络零售市场交易规模有470亿元.对于B2C购物网站而言,B2C巨头京东商城、当当网、麦考林纷纷进一步完善自己的物流配送,以提高整个网络零售行业中的竞争[1].国内学者对于逆向物流网络的研究,主要集中在:(1)当环境不确定的时候,产品可拆卸和重新制造的物流网络模型;(2)在不确定环境下,通过整合正向物流和逆向物流来构建的物流网络模型.以及在混合整数规划模型的基础上建立了一种单产品、有能力限制的产品回收逆向物流网络优化设计模型等方面[2-6].事实上,对于不同的逆向物流网络其网络设计方法和重点各有不同,一个好的逆向物流网络在很大程度上决定了其逆向物流的运作效率.
1 逆向物流网络模型
本文根据逆向物流面临的物品的种类的不同,可将逆向物流网络结构分为,例如再利用物流包 装 (reusing)、产 品 的 再 制 造 (remanufacturing)、产品的回收(recycling)以及商业客户退货(commercial re-turn)等[7-8].
1)可重新使用物流包装型 在日常识生活当中啤酒和饮料等企业里使用的可重新利用物的物流包装,包括玻璃瓶、铁罐、塑料箱和标准托盘等.此类问题要考虑保管、收集设备的定位、物流包装的数目和规模及需要运输配送的费用等因素,由于再利用和原始利用之间不存在区别,所以闭环状结构就很适应这种类型,该网络多用于多种类型包装的回收.在配送的时候不用考虑重新构建逆向物流,直接在正向物流的流程上作业相反流程即可;车辆的运输费用是这类逆向网络结构的主要的成本考虑要素,因此联结点选择上,以靠近服务的顾客群为的原则来进行设置.
2)再利用部件制造型 常见的重新制造物品包括贵重机械的部件,例如汽车的发动机、踏板、结构材料等.收集完这些物品后,然后通过逆向物流的检测和拆分,再通过制造部门进行重新制造,成为为新的产品,供再次销售.对于此种网络结构,重新制造设施规模、定位、使用所需要的回收物流成本是考虑的重点.在决策计算时,必须考虑投资、运输、处理和库存的费用等;目前,此类网络,大多是在正向物流基础上进行展开,来构建分层闭环的供应链网络结构.
3)以回收物品为目的型 此类型包括纸箱、玻璃、金属、地毯、塑料等.然而却要求先进的处理技术和设备,故投资费用很高,这就意味着该类型的网络,需要大批量的处理,形成规模经济,才会使得回收有意义、有价值.
4)商业客户退货逆型 商业退货指的是:从零售业到制造业.企业当中常见的:超额库存导致的退货,合同折价退货,发送不良货物导致的退货等.退回的产品的质量好,将被送到正常的销售仓库等待销售;出现质量问题不影响商品功能的,可以作为特价商品销售;如果退回商品不能满足客户的使用功能,那么就通过维修来处理,再进行销售;客户退货是发生在消费者到零售业.例如产品期望不符导致的退货,消费者产品损坏导致的退货等.其处理方式和商业退货相似.网络流程的合理设计以及合同的有效管理是该逆向物流网络设计的重点[9-12].对于网络零售企业合理的网络设计主要体现在路径的优化合理上,以及合理的安排配送车辆等问题上.
本文研究网络零售企业的逆向物流网络模型,根据网络零售企业特性,采取商业客户退货逆向物流网络模型,图1是这种逆向物流系统的网络结构.
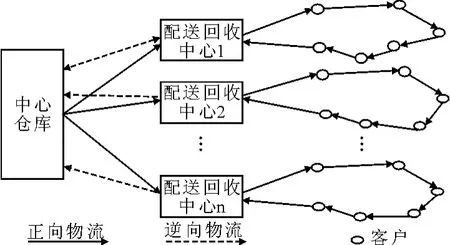
图1 商业客户退货逆向物流网络结构示意图
2 改进的遗传算法
鉴于本文研究对象的特性,对传统的遗传算法里面一些因素作出了如下改进[13]:(1)不采用二进制编码,直接采取自然数编码,因为对于本论文的特点,采取二进制编码容易导致频繁生成无效的解,给算法带来一定的复杂性;(2)在构建适应度函数的时候,本文改进了应适度函数,采取了适应度归一化的函数,因为对于此类问题,直接加入问题中的最大、最小路径,可以使得选择算子更加有效,能判断出较好的个体.适应度归一化函数如下.
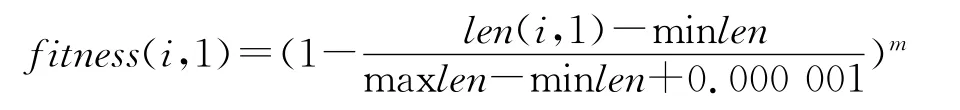
式中:len(i,1)为所有个体的路径长度;minlen为所有个体路径长度中的最小值;maxlen为所有个体路径长度中的最大值.当fitness(i,1)=1时说明i是当前最优的个体;(3 在选择算子的时候,取其fitness(i,1)≥alpha×rand作为选择算子的条件.因为加上alpha可以避免较好的个体不被淘汰,从而保留较好的值.alpha为淘汰保护指数,可取为0~1之间任意小数,取1时关闭保护功.
根据上述改进的遗传算法,给出了如图2的流程图.
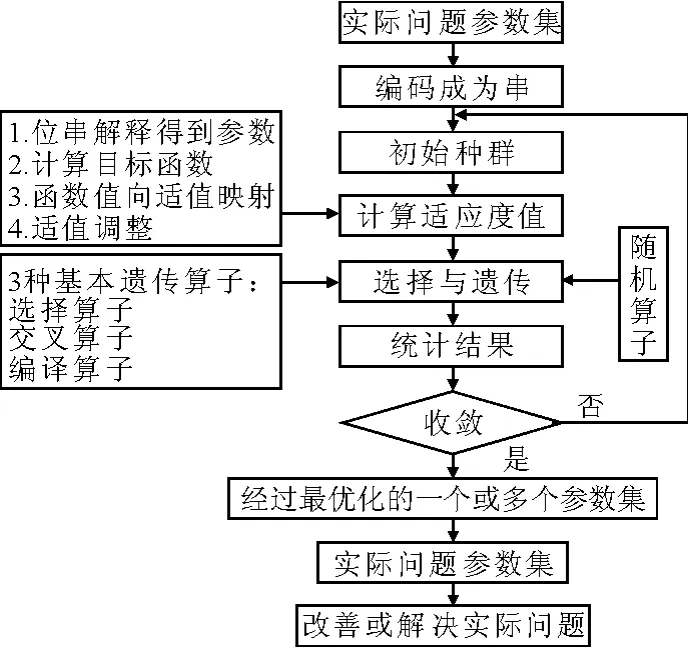
图2 遗传算法流程图
3 网络零售企业逆向物流网络问题求解
3.1 网络零售企业逆向物流网络数学模型建立
建立模型的基本思路是在原有正向物流网络的基础上,结合每个车的载重限制,构建逆向物流网络,使其结合正向配送的时候,所经过的路径最短,总的运输费用最低.

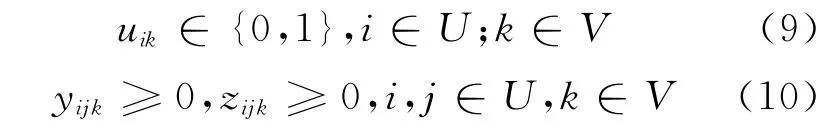
式中:U为所有点的集合;R为配送回收中心的集合;V为每个阶段不同类型的车的集合;Lk为第k辆车的运输能力;cij为节点i到节点j之间的相对距离;C为各点的相对距离矩阵;di为客户i点的配送量;Pi为客户i点的退货量;xijk为车从点i到点j时,是否由第k辆车访问;yijk为车辆从节点i到节点j时车k上的配送量;zijk为车辆从节点i到节点j时车k上的退货量;wik为车辆离开节点i时车辆k的承重量;uik为点i是否由车k服务M,一个非常大的值.
目标函数式(1)为该逆向物流网络最小化的运输距离;约束式(2)为每个点只被访问一次,每条配送路线为同一个车配送回收;约束式(3)为配送回收中心被每条配送路线的车访问,每个客户点只有一个车访问;约束式(4)为送货量均衡约束;约束式(5)为退货量均衡约束;约束式(6)为在配送过程当中,所有的车都能满足最大的载重能力;约束式(7)为限制每个车都不会超载;约束式(8),(9)为0-1规划整数.
3.2 算例分析
本文选用一个网络零售企业配送中心为例,该配送中心负责8个客户的送货与退货业务,客户的配送量和退货量给出,客户配送中心的相对距离给出,具体见表1.
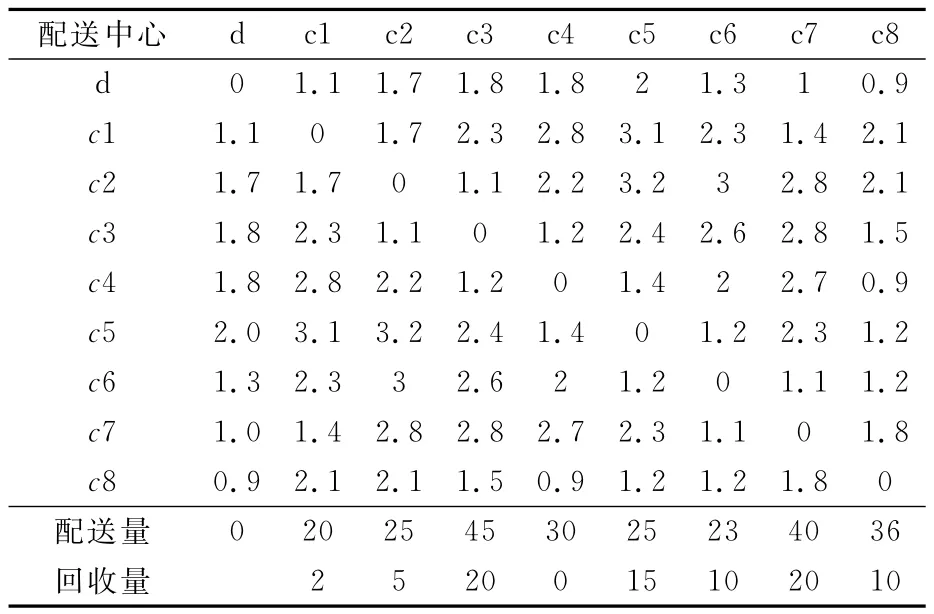
表1 配送中心d到各客户点的相对距离及配送回收量表
改进遗传算法参数设定分别为:定参数种群个数n=20,对于此类问题建议取为配送点个数的1~2倍,停止迭代次数c=300,一般按视问题的大小和花费的时间而定;适应值归一化淘汰加速指数取m=2,可以从1,2,3,4,不宜太大;淘汰保护指数alpha=0.9,可取为0~1之间任意小数,取1时关闭保护功能,最好取为0.8~0.9.
通过Matlab编程计算,改进遗传算法的主程
式如下.

运算得出最优解,见表2.
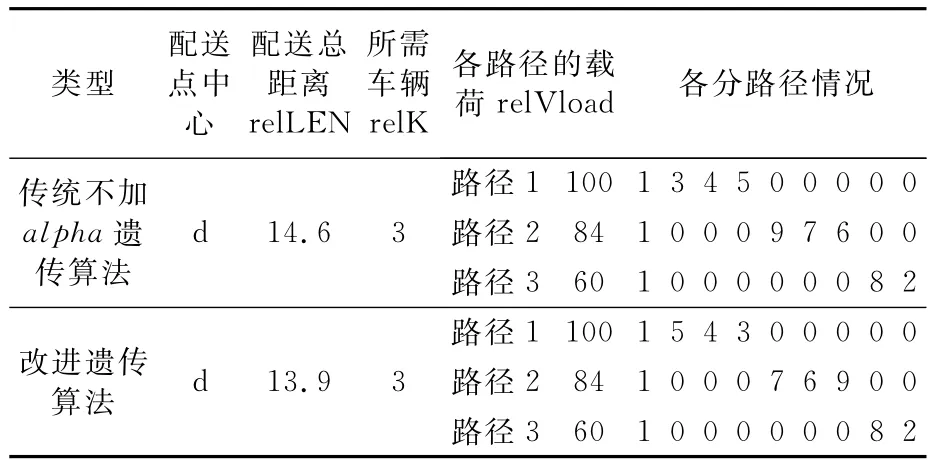
表2 优化结果
图3为改进遗传算法通过Matlab编程绘制会的路径优化图.结果表明利用此种遗传算法解决网络逆向物流网络规划问题是可行有效的,并且优越性体现在:通过结果直接可以看出路径情况,不需要转化编码方式;配送总距离上,加上了alpha指数使得改进的遗传算法能够把较好的个体保留下来.
4 结束语

图3 路径优化图
网络零售企业的逆向物流网络规划问题是一种新兴的问题,其研究领域需要进一步的拓宽,本文选取改进的遗传算法决绝此类NP难问题,说明了该算法的可行性.网络零售企业逆向物流网络规划的问题随着约束条件的增多,会产生许多新的问题,如考虑客户有时间约束限制的情况,客户退货的时间不确定,以及考虑其他算法求解,是下一步研究工作的重点.
[1]曹 磊,张周平.2011年度中国电子商务市场数据监测报告[R].杭州:中国电子商务研究中心,2012.
[2]米 宁.第三方逆向物流决策与网络构建[D].成都:西南交通大学,2004.
[3]马丹祥.逆向物流网络设计优化模型研究[D].成都:西南交通大学,2005.
[4]ROGERS D STibben-Lembke R SGoing backwards:reverse logistics trends and practices[J].Reverse Logistics Executive Council Press,2004,11(12):15-16.
[5]夏伟依,杨明华.逆向物流理论研究综述[J].物流科技,2006,29(1):14-17.
[6]达庆利,黄 祖庆,张 钦.逆向物流系统结构研究的现状及展望[J].中国管理科学,2004,12(1):131-137.
[7]翟春娟,李勇建.B2C模式下的在线零售商退货策略研究[J].管理工程学报,2011,25(1):62-64.
[8]张 敏,朱道立.退货管理系统设计[J].物流技术,2003(11):58-61.
[9]马祖军,代 颖,张殿业.逆向物流网络结构与设计[J].物流技术,2004(4):13-15.
[10]马祖军,代 颖.产品回收逆向物流网络优化设计模型[J].管理工程学报,2005(4):114-1170.
[11]朱大海,李宗平.基于逆向物流管理的产品回收网络规划模型[J].交通标准化,2005(12):110-112.
[12]姜启源,谢金星,叶 俊.数学模型[M].3版.北京:高等教育出版社,2003.
[13]李敏强,寇纪淞,李 丹,等.遗传算法的基本理论与应用[M].北京:科学出版社,2002.
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
现代计算机(2016年34期)2016-02-28
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
智能系统学报(2015年4期)2015-12-27
应用技术学报(2014年3期)2014-02-28

- 武汉理工大学学报(交通科学与工程版)的其它文章
- Research on Transverse Ultimate Strength for High Speed Trimaran*