
一种新的时间序列组合预测模型及其应用
2013-06-27 05:51马亮亮
大庆师范学院学报 2013年6期
马亮亮,陈 龙
(攀枝花学院数学与计算机学院,四川攀枝花617000)
一种新的时间序列组合预测模型及其应用
马亮亮,陈 龙
(攀枝花学院数学与计算机学院,四川攀枝花617000)
提出了一种新的时间序列组合预测模型(PCA-BPNN模型),即先利用主成分分析方法对原输入变量的空间进行重构,然后借助于各主成分对总体样本的贡献率来确定网络结构。最后利用1999年1月至2005年12月甘肃省天水市胆结石发病率的资料验证了该方法的有效性。
多层前馈网络;时间序列;主成分分析;预测模型
通常时间序列由于受到多种影响因素的综合影响,往往呈现出非线性变化规律,导致基于线性建模的ARIMA预测模型的建模结果不理想[1-6]。神经网络预测算法当样本数据较大时预测结果较好,而当样本数据较小时,算法的预测性能则不理想[6-8]。为了有效的充分利用各种预测模型的优点,克服单一模型本身所固有的缺陷和不足,一些专家学者基于著名的M-竞争理论提出了组合预测模型。大量试验结果表明,组合预测模型能够较大限度地充分利用预测样本的样本信息,可大幅度地提高模型的预测精度[9-10]。
本文考虑将主成分分析(Principal Component Analysis,PCA)和BPNN相融合,构造出一种新的时间序列组合预测模型(PCA-BPNN),并通过胆结石发病率对PCA-BPNN预测性能进行验证。
1 主成分分析基础理论
1.1 主成分分析基本原理
主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法,是一种降维处理技术[11-12]。主成分分析的基本思路是:对于多要素的复杂系统利用原变量之间的相关关系,用较少的新变量代替原来的较多变量,并使其尽可能的多保留原来的较多变量所反应的信息。
主成分分析的基本原理是:假定有n个分析样本,每个分析样本共有p个变量(p<n),构成n×p的阶数据矩阵如下:

记原变量指标分别为x1,x2,…,xp,新变量指标分别为z1,z2,L,zm(m≤p),则

主成分分析的实质就是确定原来变量xj(j=1,2,…,p)在诸成分zi(i=1,2,…,m)上的荷载lij(i=1,2,…,m;j=1,2,…,p)。从数学上可以证明,它们分别是相关矩阵m个较大的特征值所对应的特征向量[13-14]。
1.2 主成分分析的计算步骤
1)计算相关系数矩阵

其中rij(i,j=1,2,…,p)为原变量xi与xj的相关系数,且rij=rji,其计算公式为

2)计算特征值与特征向量

3)计算主成分贡献率及累计贡献率
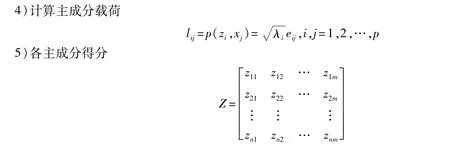
2 多层前馈网络与BP学习算法
80年代中期,以Rumelhart和McClelland为首提出了多层前馈网络(MFNN-Multilayer Feedforward Neural Networks)的反向传播(BP-Back Propagation)学习算法,简称BP算法,其是有导师的学习,是梯度下降法在多层前馈网络中的应用[15-16]。
2.1 网络结构
多层前馈网络的结构见图1所示,u、y是网络的输入、输出向量,每一神经元用一个节点表示,网络由输入层、隐层和输出层节点组成,隐层可一层,也可以多层(图1中是单隐层),前层至后层节点通过权联接。由于用BP学习算法,所以常称BP神经网络。

图1 BP神经网络
2.2 BP学习算法
已知网络的输入/输出样本,即导师信号。BP学习算法由正向传播和反向传播组成。正向传播是输入信号从输入层经隐层传向输出层,若输出层得到了期望的输出,则学习算法结束;否则,转向反向传播。反向传播就是将误差信号(样本输出与网络输出之差)按原联接通路反向计算,由梯度下降法调整各层神经元的权值和阀值,使误差信号减小。
算法步骤:
1)设置初始权系W(0)为较小的随机非零值。
2)给定输入/输出样本对,计算网络的输出:
设第p组样本输入、输出分别为

节点i在第p组样本输入时,输出为:

其中Ijp表示在第p组样本输入时,节点i的第j个输入。
3)计算网络的目标函数J。
设Ep为在第p组样本输入时网络的目标函数,取L2范数,则

其中ykp表示在第p组样本输入时,经t次权值调整,网络的输出;k是输出层第k个节点。网络的总目标函数为J(t)=∑pEp(t),作为对网络学习状况的评价。4)判别
若J(t)≤ε,则算法结束;否则,至步骤5)。其中ε为预先确定的,且ε>0。5)反向传播计算
由输出层,依据J,按“梯度下降法”反向计算,逐层调整权值。
取步长为常值,可得到神经元j到神经元i的联接权t+1次调整算式:

3 PCA-BPNN模型预测原理
PCA-BPNN模型的预测原理为:首先利用PCA对时间序列的影响因子进行降维筛选,保留对系统影响较大的影响因子,然后再采用BPNN模型进行建模。PCA-BPNN具体的预测流程如图2所示。
4 评价指标和参比模型
为了清楚地解释PCA-BPNN组合预测模型的性能优劣,选择PCA-MLR、ARIMA、BPNN模型作为参比模型,其中PCA-MLR模型表示先借助于PCA方法进行影响因子筛选,然后采用MLR(Multiple Linear Regression)模型进行建模和预测;ARIMA表示直接采用ARIMA模型进行建模和预测;BPNN表示直接采用BPNN(Back Propagation Neural Network Model)模型进行模型建立、预测。文中将分别采用均方误差(Mean Square Error,MSE)、平均相对误差(Mean Absolute Percentage Error,MAPE)作为参比模型的评价指标,其中MSE和MAPE分别定义如下:
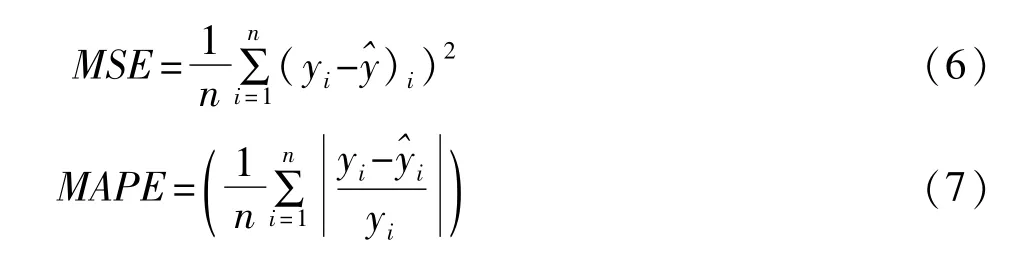

图2 PCA-BPNN组合预测模型的预测流程图
其中yi为实际值,^yi为预测值,n为样本数。
5 实证研究
5.1 数据来源
数据资料来源于甘肃省天水市疾病预防控制中心提供的1999年1月至2005年12月胆结石发病率(y)。文中考虑的胆结石发病率的气象影响因子主要有:月平均气压x1(pha),月平均气温x2(℃),月平均相对湿度x3(%),月平均风速x4(m/s),月降水量x5(mm)。
5.2 主成分分析(PCA)
利用主要的5种气象影响因子:月平均气压x1,月平均气温x2,月平均相对湿度x3,月平均风速x4和月降水量x5做主成分分析,结果如表1所示。

表1 主成分统计分析
从主成分分析结果可知,第1主成分的特征根为2.664,它解释了总变异的52.883%;第2主成分的特征根为1.500,它解释了总变异的30.003%;前两个特征根均大于1,累计贡献率82.886%.由于第3个主成分的特征根较接近于1,故宜取前3个主成分,此时累计贡献率达93.698%。
前3个主成分与各个变量x1,x2,x3,x4,x5的关系如下:

5.3 因子筛选
从主成分分析结果可知,影响胆结石发病率变化的因子有很多,而这些因子之间可能存在多重共线性,特别是当各个解释变量之间存在着高度的相互依赖关系时,就会给回归系数的估计带来不合理的解释[17]。
为了得到一个可靠的预测模型,需要从众多影响因子中挑选出对胆结石发病率变化贡献率达的影响因子,本文采用PCA对影响因子进行筛选。采用SPSS11.5对胆结石发病率进行主成分分析,表明前三个主成分包含了原有5个指标93.698%的信息,故可用前3个主成分(z1,z2,z3)代替原先的5个变量(x1,x2,x3,x4,x5)进行建模和预测。
5.4 结果与分析
5.4.1 MLR拟合
运用PCA筛选的对胆结石发病率影响显著的前三个主成分:z1,z2,z3,采用MLR进行预测,并用SPSS11.5实现,得到的线性回归方程为:

将式(8)~(10)中的z1,z2,z3表达式分别代入式(16),得到因变量y与标准自变量stdx1妊stdx5的线性回归方程为:
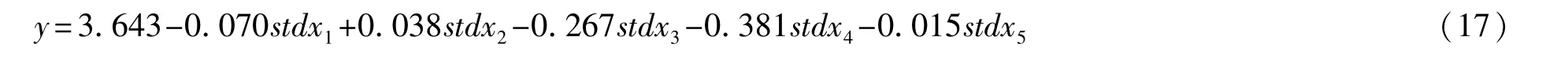
将标准自变量还原为原自变量,得到因变量y与原自变量x1妊x5的线性回归方程为:
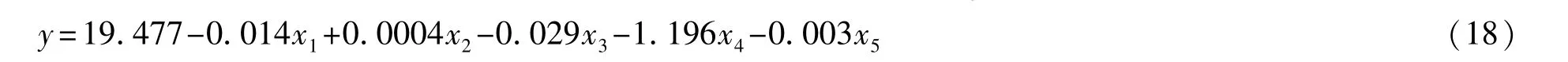
模型(18)的主要参数分别为:相关系数R=0.925;F=1.561;显著水平p=0.0391<0.05,由此可知建立的线性方程已达到显著性要求,可进行预测应用。
5.4.2 ARIMA拟合
利用胆结石发病率(y)序列建立ARIMA模型,其对应的方程为:

其中随机项εt是相互独立的白噪声序列,且服从均值为0,方差为σ2的正态分布。
5.4.3 PCA-BPNN拟合
用PCA确定BP网络的输入层节点数为u=2,网络的输出节点数q=1,隐层由72组2维输入向量和1维输出向量构成的训练样本矩阵组成;采用newrb函数建立满足精度要求的BP网络;用sim函数对时间序列进行预测。以上3个步骤可构成胆结石发病率时间序列的PCA-BPNN预测模型。
各种预测模型拟合的MSE和MAPE见表2。

表2 各模型的拟合性能比较
从表2的对比结果可知,在参比模型中,PCA-BPNN组合预测模型的拟合性能最好,因此采用PCA方法对胆结石发病率序列的影响因子进行主成分分析,然后采用BPNN进行序列建模,能更加准确描述胆结石发病率的变化规律,有效地提高了胆结石发病率的拟合精度。
5.5 几种模型预测结果对比
分别采用PCA-MLR、ARIMA、BPNN、PCA-BPNN模型进行独立预测,将数据分为两部分:1999年1月至2004年12月的数据作为训练集;2005年1月至12月的数据作为测试集,然后进行实际胆结石发病率建模精度与预测能力的评定。几种预测模型对胆结石发病率的预测结果如表3所示。
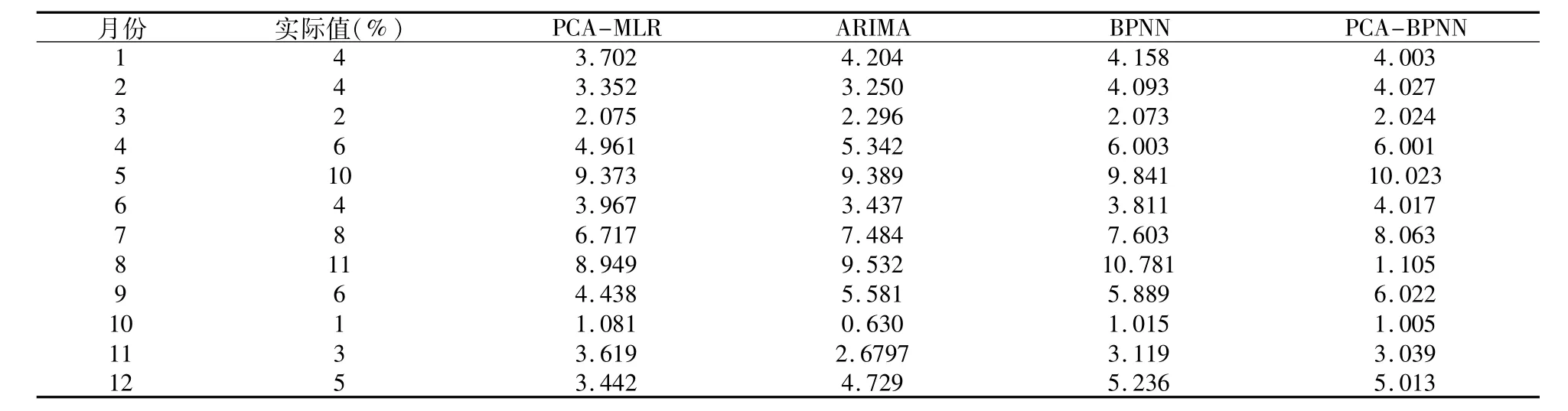
表3 2005年胆结石发病率预测结果
从表3可知,线性MLR模型、ARIMA模型和BPNN模型三种模型由于仅反映了胆结石发病率序列的片段信息,不能充分捕捉到胆结石发病率序列的动态变化规律,因此模型的预测效果较差;而组合预测模型PCA-BPNN与MLR、ARIMA和BPNN相比,预测精度有了较大的提高,这主要是由于组合预测模型能够充分利用原时间序列中的数据信息,且可对胆结石发病率序列变化规律进行比较深入挖掘和剖析,间接地避免了单一预测模型本身所固有的局限性,因此较大程度的提高了胆结石发病率的预测精度。
6 结语
通常时间序列由于受到外界众多影响变量的影响,往往呈现出高度非线性变化规律,因此难以用一般的数学模型进行建模。利用BPNN模型本身的优点,将PCA引入到时间序列建模中,建立一种时间序列组合模型PCA-BPNN,并应用于胆结石压预测中。实例结果表明,PCA-BPNN模型具有算法简单、容易操作和实现、算法运行速度快等特点,同时较为明显的提高了胆结石发病率的预测精度,因此较好地揭示了胆结石发病率的变化规律[5,18-20]。
[1]马亮亮,田富鹏.基于非对称ARCH模型的海西州地区胆结石发病情况研究[J].科技导报,2009,27(24):51-55.
[2]马亮亮,田富鹏.ARMA模型在胆结石发病率预测中的应用[J].军事医学科学院院刊,2010,34(5):1-4.
[3]马亮亮,田富鹏.时间序列分析方法在胆囊炎发病率预测中的应用[J].中华实验外科杂志,2010,27(6):779.
[4]马亮亮,田富鹏.不同时间序列分析方法在胆结石发病率预测中的应用[J].中国老年学杂志,2010,30(13):1777-1780.
[5]向昌盛.基于支持向量机的时间序列组合预测模型[D].长沙:湖南农业大学博士学位论文,2011:23-32.
[6]马亮亮,田富鹏.基于因子RBF神经网络预测模型的脑梗塞发病率预测[J].统计与决策,2010,10:200-201.
[7]马亮亮,田富鹏.基于人工神经网络的非稳态心肌病发病率预测模型研究[J].中国老年学杂志,2011,31(24):4877-4878.
[8]罗盛健.基于人工神经网络的刚竹毒蛾发生面积的预测模型[J].华东昆虫学报,2006,15(1):37-39.
[9]Salgdo R M,Pereira JJF,Ohishi T.A hybrid ensemblemodel applied to the short-term load forecasting problem[C].International Joint Conference on Neural Networks,Vancouver,B C Canada,2006,10:2627-2634.
[10]Vila JP,Wagner V,Neveu P.Bayesian nonlinearmodel selection and neural network:A conjugate prior approach[J].IEEE Trans on Neural Networks,2000,11(2):265-278.
[11]向东进.实用多元统计分析[M].武汉:中国地质大学出版社,2005:120-184.
[12]朱建平,殷瑞飞.SPSS在统计分析中的应用[M].北京:清华大学出版社,2007:171-178.
[13]马亮亮,田富鹏.主成分分析与因子分析在肺心病发病情况分析中的应用[J].四川文理学院学报,2010,20(2):65-69.
[14]马亮亮,田富鹏.基于糖尿病相关因素的主成分分析[J].长春大学学报,2009,19(4):61-63.
[15]Boddy A,Bentz E,Thomas M D A,et al.An overview and sensitivity study of amultimechanistic chloride transportmodel[J].Cementand Concrete Research,1999,29(6):827-837.
[16]焦李成.神经网络计算[M].西安:西安电子科技大学出版社,1993:85-102.
[17]马亮亮,田富鹏.逐步回归分析在糖尿病发病情况中的应用[J].渤海大学学报,2009,30(4):321-324.
[18]马亮亮.基于因子BP神经网络预测模型的胃溃疡发病率预测[J].北京联合大学学报,2012,26(3):73-76.
[19]马亮亮.基于粗糙集和RBF神经网络的脑梗塞发病率预测[J].西北民族大学学报,2012,33(3):17-21.
[20]马亮亮.基于PCA-ARIMA模型的高血压发病率预测[J].河北北方学院学报,2013,29(2):26-29.
New K ind of Time Series Combined Prediction M odel and Its Application
MA Liang-liang,Chen Long
(College of Mathematics and Computer,Panzhihua University,Panzhihua 617000,China)
A new kind of time series combined prediction model(PCA-BPNN model)is proposed,which the principal component analysis is used to reconstruct the original input space,and the network structure is determined based on the contribution rate of allmain components.Finally,the incidence rate of gall-stone from January 1999 to December 2005 of Tianshui,Gansu province is used to validate themethod.
multilayer feed-forward neural networks;time series;principal component analysis;prediction model
马亮亮(1986-),男,甘肃天水人,攀枝花学院数学与计算机学院教师,从事模型优化和微分方程研究。
国家自然科学基金资助项目(60673192);四川省科技厅资助项目(2013JY0125);攀枝花学院校级培育项目(2012PY08);攀枝花学院校级科研项目(2012YB21);攀枝花学院院级科研创新项目(Y2013-04)。
TP183
A
2095-0063(2013)06-0059-06
2013-08-12
猜你喜欢
健康护理(2022年3期)2022-05-26
中老年保健(2021年8期)2021-08-24
中老年保健(2021年9期)2021-08-24
中学生数理化·高一版(2021年2期)2021-03-19
中华养生保健(2020年2期)2020-11-16
医学新知(2019年4期)2020-01-02
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
中国卫生标准管理(2015年17期)2016-01-20
