
A Parallel Platform for Web Text Mining
2013-05-23 03:01:40PingLuZhenjiangDongShengmeiLuoLixiaLiuShanshanGuanShengyuLiuandQingcaiChen
ZTE Communications 2013年3期
Ping Lu,Zhenjiang Dong,Shengmei Luo,Lixia Liu,Shanshan Guan,Shengyu Liu,and Qingcai Chen
(1.ZTECorporation,Nanjing210000,China;
2.Shenzhen Graduate School,Harbin Instituteof Technology,Shenzhen 518055,China)
Abstract With user-generated content,anyone can be a content creator.This phenomenon has infinitely increased the amount of infor⁃mation circulated online,and it is becoming harder to efficient⁃ly obtain required information.In this paper,we describe how natural language processing and text mining can be parallelized using Hadoop and Message Passing Interface.We propose a parallel web text mining platform that processes massive amounts of dataquickly and efficiently.Our web knowledgeser⁃vice platform is designed to collect information about the ITand telecommunications industriesfromthe web and process this in⁃formation using natural language processing and data-mining techniques.
Keyw ordsnatural language processing;text mining;massive data;paral⁃lel;web knowledgeservice
1 Introduction
W ith the rapid development of Web 2.0 and social networks,more and more information is being created.New technologies allow anyone to cre⁃ate all kinds of user-generated content(UGC),and this has spawned millions of new search results.As a re⁃sult,seeking information has become more difficult and trou⁃blesome.Increasingly,people have less time to acquire infor⁃mation,and knowledgeserviceshavebecomemoreimportant.
Natural language processing and text mining have matured;however,they still need to be made more efficient for mass text engineering.Cloud computing has been very successful for large internet companies,who have used large numbers of cheap PCs to construct computer clusters that provide distrib⁃uted storage and simple,efficient distributed processing of massive amounts of information.Cloud computing platforms have uncomplicated programming and high fault tolerance,and they can be conveniently expanded.They use the open-source Hadoop file system and Message Passing Inter⁃face(MPI)to parallelize many common text-mining tech⁃niques.This allows for fast,more efficient information process⁃ing.
1.1 Hadoop Platform
Apache Hadoop is an open-source software framework that allows large data sets to be processed in a distributed way across clusters of computers with simple programming models.Hadoop is designed to scale from a single server to thousands of machines,each of which is capable of local computation and storage.Rather than rely on hardwaretoprovide high availabil⁃ity,the Hadoop library is designed to detect and handle fail⁃uresat theapplication layer.Hadoop can deliver ahighly avail⁃able service on a cluster of computers,each of which may be prone to failure.The Hadoop kernel is Hadoop Distributed File System(HDFS)(Fig.1).
1.2 Message Passing Interface
MPI is a library specification for message-passing and has been proposed as a standard by a committee of vendors,imple⁃menters,and users.The MPI standard defines the syntax and semantics of a core of library routines that is very useful to a wide range of users writing portable message-passing pro⁃gramsin Fortran 77 or C.MPIis alanguage-independent com⁃munication protocol used to program parallel computers.Both point-to-point and collective communication are supported.In[1],MPI is defined as“a message-passing application pro⁃grammer interface together with protocol and semantic specifi⁃cations for how its features must behave in any implementa⁃tion.”MPI is designed for high performance,scalability,and portability,and it remains the dominant model for high-perfor⁃mance computing today[2].

▲Figure1.Thestructureof Hadoop Distributed File System.
The MPI interface provides a virtual topology,synchroniza⁃tion,and communication functionality in a set of processes that have been mapped to nodes,servers,and computer instances.These processes are mapped in a language-independent way and have language-specific syntaxes(bindings)and a few lan⁃guage-specific features.
2 Design of a Parallel Text-Mining Platform
A platform based on HDFSand MPI comprises several par⁃allel modules,including web crawler,Chinese word segmenta⁃tion,text categorization,text clustering,topic detection and tracking(TDT),automatic summarization,semantic computing,and sentiment analysis(Fig.2).Experiments show that all the modules operating together are much more effective than a sin⁃glenodeoperatingby itself.
2.1 Web Crawler
A web crawler is a program for parsing web pages.It down⁃loads internet pages for the search engine(SE)and is an impor⁃tant part of the SE.A traditional crawler starts with initial URLs and parses other pages through the links on the pages given by the initial URLs.While parsing,the crawler extracts URLs from the current page until reaching some end condi⁃tions.The crawler alwaysprocesses a large number of web pag⁃es.A crawler run on a single computer cannot properly parse and update pages for the SE.However,a distributed crawler draws on the computing ability of multiple computers and can improveparsingspeed and systemthroughput.
In our system,thecrawler sendsand receivesmessagein dif⁃ferent computers by MPI.We use HDFSto store the files,and we eliminate repeated URLs by using BerkeleyDB.The crawl⁃er has three processes:start-up,data download and handing out URLs,and writingdatato HDFS.
2.2 Chinese Word Segmentation
ELUS is a natural language processing(NLP)application that comprises Chinese word segmentation,part-of-speech tag⁃ging,and named entity recognition.
Word segmentation technology isbased on the n-gram mod⁃el.In statistical language models such as n-gram,natural lan⁃guage is a random process,and each natural-language sen⁃tence comprises minimum structure units(words).An n-gram model is also called an n-1 Markov model.They use an abso⁃lute discount smoothing algorithm.The whole process involves searching words in a rapid-indexing dictionary,combining two algorithms,and making the word segmentation.
Part-of-speech tagging uses a conditional random fields(CRF)model.For a given observed value sequence,the model uses index calculation to calculate the conditional probability of the whole label sequence.CRFis a type of undirected graph model or Markov Random Field model.
In a series of input random variables X,the conditional prob⁃ability of the outputs random variable is Y.The inverse ratio versus the potential function of each clique is P(Y|X).This model can solvelabel bias.
Named entity recognition combines the maximum entropy(ME)model(a probability model)with Chinese named entity rules.Thiscombination achieves better results.
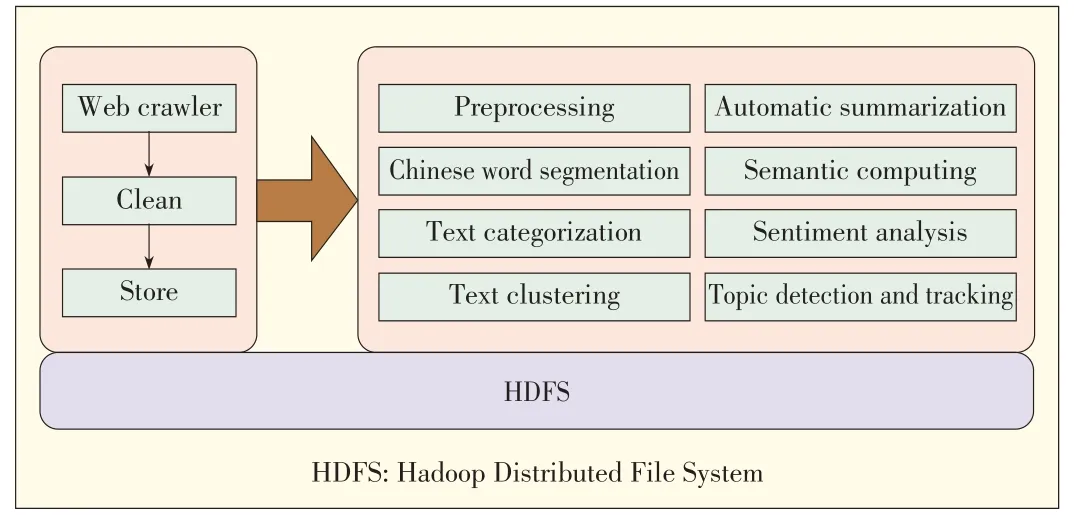
▲Figure2.Architecturefor aplatform based on HDFSand MPI.
2.3 Text Classification
Text classification is based on text content and is used to classify a certain text into one or more predefined classes.Text classification involves five stages:preprocessing,feature selec⁃tion,text representation,classifier design,and assessment of results[3].For this platform,we use 10 feature selection meth⁃ods,including document feature(DF),information gain(IG),expected cross entropy(ECE),mutual information(MI),and chi-square(CHI).We also implement six classifiers,including support vector machine(SVM),k-nearest neighbor(k-NN),and Bayes′.
Text classification is a supervised learning process in which classifier models are learned according to the training data set.Then,the generated classifier model isused topredict thecate⁃gory of the input document.However,for mass data,stand⁃alone training and prediction is very inefficient,and a parallel model needs to be used.The program inputs and outputs in HDFS.At the same time,multiprocess operation is achieved with MPI.One process trains data,and the rest of the process divides the files on HDFSinto smaller files and makes predic⁃tions.
2.4 Text Clustering
Text clustering involves dividing the entire text set into clus⁃tersso that documentsin thesamecluster areassimilar aspos⁃sible and different from documents in other clusters.A typical division-based clustering algorithm is k-means[4].This algo⁃rithm is efficient and fast and is often preferred for clustering large data sets.The k-means algorithm also has good parallel⁃ism.In this paper,we develop the k-means algorithm by using MPI to incorporate it into HDFSand interprocess communica⁃tion.
The agglomerative hierarchical clustering(AHC)algorithm reflects the hierarchical relationships between documents.AHC is better than a division-based clustering algorithm in terms of retrieving relevant documents,detecting topics,and tracking[6].However,it is complex,and there are too many clusters in the results.We propose a secondary hierarchical clustering algorithm called DAHC.The affinity propagation(AP)algorithm can be used to filter the“noise”outlier data and can detect clusters with an arbitrary shape[7],[8].Howev⁃er,when the text vector dimension is too high,data sparseness becomes a serious problem.In this case,the number of clus⁃ters is often greater than the number of predefined categories.The average scale of clusters is also too small,and each cluster is more pure.Therefore,we propose an APAHCalgorithm that combines APalgorithm and AHCalgorithm.
2.5 Topic Detection and Tracking
A TDTevent is a certain thing that occursin a specific loca⁃tion at a certain time.The TDT research task comprises story segmentation,new event detection,story link detection,topic detection,and topic tracking[9].
Often-used TDT methods include methods based on the in⁃cremental TF-IDF model[10],improved vector space model[11],clustering[12],or named entity[13].The popularity of an event depends on related news stories,blogs,bulletin boards,and other commentary.The TDT module focuses on recalling and organizing hot events.It also implements MPI paralleliza⁃tion at a document level.Large documents that are stored in Hadoop are divided into several parts,each of which is clus⁃tered independently to generate topics.This clustering is per⁃formed by a clustering algorithm designed specifically for TDT.Descriptive words are produced for each topic,and top⁃ics generated by all of the parts are clustered using sin⁃gle-pass clusteringon theparallelization platform.
2.6 Automatic Summarization
In automatic summarization,the most important information in the original text is extracted and output in the form of con⁃cise,fluent language.Most existing automatic summarization methods analyze the structure of an article and use word syn⁃tax and statistics to determine the subject.Some automatic summarization methods have been successful,but accuracy can be improved.Semantic analysis is very important in deter⁃mining the main idea of an article,but most existing automatic summarization methods lack this.We propose combining se⁃mantic analysis,structural analysis,statistical methods,and natural language processing to develop an automatic summari⁃zation system that meets practical requirements.In a parallel⁃ized system,Hadoop is used to split the document collection,and MPIisused toparallelizetheprogram.
2.7 Semantic Computing
The purpose of semantic computing is to explain the natural language statement and the meaning of each part of it.There are many difficulties with semantic calculation.There are many ambiguities,such as synonymy and polysemy,in natural language.A sentence may mean different things in different contexts.Theories and methods of semantic computing are not mature.
In semantic computing,semantic similarity iscommonly cal⁃culated using word distance.There are two kinds of word simi⁃larity calculation:one based on ontology or taxonomy and an⁃other based on statisticsderived from a large corpus.
In our system,the computation of semantic similarity is based on HowNet.First,we determine word similarity by mak⁃ing an inquiring through HowNet.If two words are both in HowNet,the semantic similarity can be directly obtained.If one of the words is not in HowNet,the semantic similarity can be obtained from the distance between the two words in the synonym tree.If both words are not in HowNet,fuzzy string matchingisused tocalculatethesemantic similarity.
2.8 Sentiment Analysis
Sentiment analysis is used to determine how to recognize,classify,label,and extract opinion text and its sentiment.Rec⁃ognizing sentiment words and judging the semantic polarity of the sentiment words are fundamental to sentiment analysis.Each sentiment word may contain one or more polarities,such as positive,negative,and neutral polarity.We roughly classi⁃fied text sentiment by using sentiment-dictionary methods and machine-learning methods.
The sentiment-dictionary method involves directly classify⁃ing the text according to a sentiment dictionary that we com⁃piled ourselves.We use this method in conjunction with other related heuristic language rules.The machine-learning meth⁃od involves extracting features and using them to train a classi⁃fier.The obtained model is then used to classify the sentiment of thetext.
We use both methods to classify the documents on Hadoop.After making many necessary modifications for the LIBSVM,theinterfacecan run in parallel usingan MPIlibrary.
3 Performance Testing
In our experiment,we used an HP Elite 7100 Microtower PCwith an Intel(R)Core(TM)i5 2.80 GHz processor and 4 GB RAM.The software environment included SUSE Enterprise 11,MPICH2-1.4,and Hadoop-0.20.2-cdh3u0.
We take advantage of recall and precision in our evalua⁃tions;however,to only use one of these would be one-sided.The F-measure is one an index that includes both recall and precision.It isdefined as

Examining the speedup ratio is important when evaluating parallelization.We scanned the running time of the programs,which wererunningon between onetosix nodes.
3.1 Chinese Word Segmentation
We use the public evaluation corpuses of Peking University(PKU),Microsoft Research Asia(MSRA),City University of Hong Kong(CITYU),and Academia Sinica,Taiwan(AS).In this public evaluation corpuses,F values range from 97.7%to 99.1%.
We used 6930 documents(about 92 MB)to evaluate the speedup ratio(Table1).

▼Table1.Thespeedup ratiofrom our examination of Chineseword segmentation
3.2 Text Categorization
In our examination of the English corpus,called Reutor,we used SVM and ECE with micro-Fof 0.91985 and macro-F of 0.86547.
When examining speedup ratio,we used a 1.7 MB standard corpus.The running results of the examination are shown in able2.

▼Table2.Speedup ratiosfrom our examination of text categorization
3.3 Text Clustering
We examined the labeled standard corpus with a purity of 0.84509,and the F-value was 0.69492.Table 3 shows the speedup ratios.

▼Table3.Speedup ratiosfrom our examination of text clustering
3.4 Topic Detection and Tracking
We used two test corpuses,one of which was an event cor⁃pus of news topics and the other of which only included blog webpages.In the former corpus,the precision was 95.04%and the F-value was 90.17%.In the latter corpus,the precision was92.18%.
Table4 showsthespeedup ratios.

▼Table4.Speedup ratiosfrom our examination of topic detection and tracking
3.5 Automatic Summarization
The test corpus comprised 100 news articles that were of⁃fered by the project group.The precision was 64.44%,and the recall was 66.38%.The F-measure was65.4%.
In our examination of speedup ratio,we used a 42 MB stan⁃dard corpus.Theresultsareshown in Table5.

▼Table5.Speedup ratiosfrom our examination of automatic summarization
3.6 Semantic Computing
We used an NTCIR 2009 test corpus that comprised 409 similar statement pairs,and the precision was 68.05%.Howev⁃er,parallelization failed in thisexamination.
3.7 Sentiment Analysis
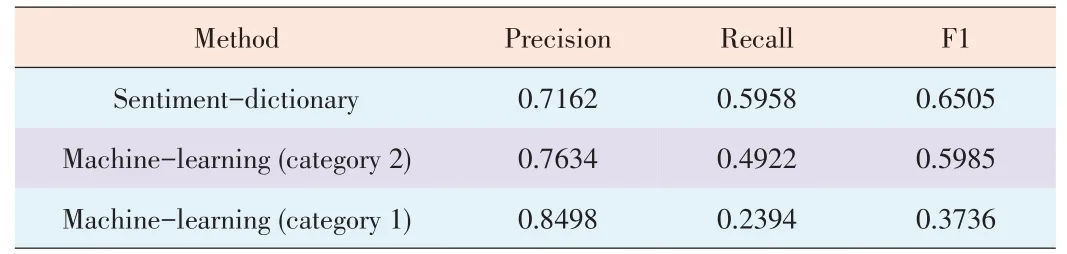
▼Table6.Resultsof sentiment analysiswhen NTCIR-7 MOAT multilanguageanalysisisused
Finally,the results of the whole performance test are shown in Table7.
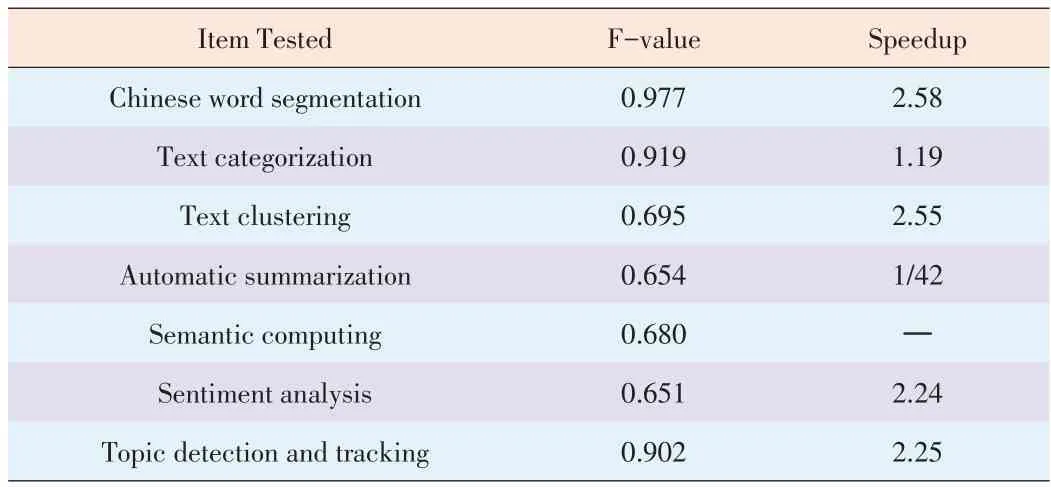
▼Table7.Resultsof thewholeperformancetest
4 Application System Design
We build a web knowledge service system according to the demands of users from the IT and telecommunications fields.This knowledge service system is based on the parallel web text mining platform.
4.1 Physical Architectureof Proposed Platform
In Fig.3,PageServer provides the page display function,and all web pagesauser visitsareprovided by thisserver.Pag⁃eServer is used to show and recommend information resources of the IT and telecommunications industries.It allows the user tomanually submit information resources.
MidServer provides the interface to access the database.Pages on PageSever access the database through MidServer.
Table 6 shows the results of the sentiment analysis when NTCIR-7 MOATmultilanguage analysis was performed.
Theserver providestheinterfacetoaccessthedatabase.
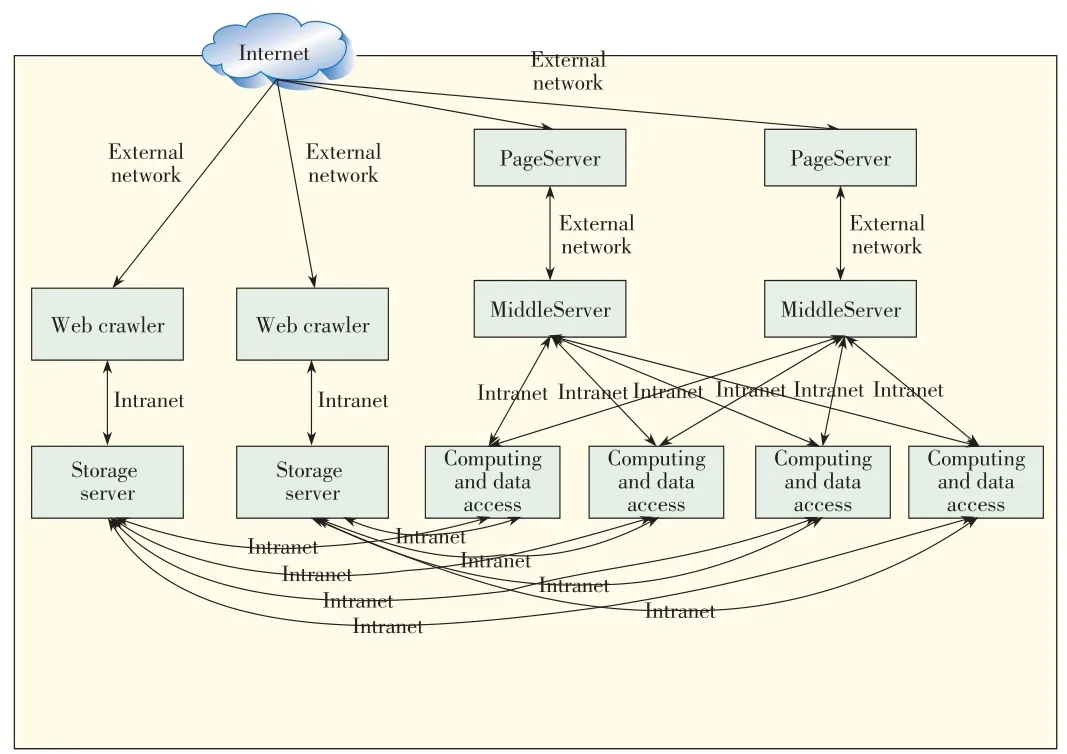
▲Figure3.Physical architectureof proposed platform.
Computing and data access is used to calculate and access data,analyzethecollected data,and minedata.
The storage server is used for database management and Ha⁃doop-based parallel storage.The web crawler supports parallel data acquisition as well as parallel data reading and writing.The web crawler also supports incremental crawling,for which therunningenvironment must remain unchanged.
4.2 System Functions
The web knowledge service system comprises the following modules:information,blog,journals,conference,and universi⁃ty.
The information module located hot information in technical fields such as cloud computing,new media and the internet.It displays this information in different categories,and we give this information a value.The blog module locates hot informa⁃tion in technical fields such as cloud computing,new media and theinternet.It displaysthisinformation in different catego⁃ries.As well as displaying the blog articles,it can also show rankings and bloggers.The journals module collects articles from mainstream journals from home and abroad.It is updated regularly to obtain the most recent scientific and technological developments in specific fields.The conference module is de⁃signed to collect and organize information of well-known,top-level conferences.The content includes the name,place,and time of the conference;paper submission deadline;and other details(the entire contents of the original page).The con⁃ference module collects information from various conferences with unstructured information;it formats and stores this infor⁃mation in the database;and it displays this information in the foreground.The module imports the conference name and builds the programautomatically.In this way,the user can eas⁃ily locate the relevant conference information.The university module extracts and displays information from researchers in every field.It extracts the name,gender,job title,work units,research direction,personal web pages,office telephone,pageof theinformation servicesystem.email,and other details.The system can provide global search⁃es as well as subfield searches to users.Fig.4 shows the index
▲Figure4.Index pageof theinformation servicesystem.
5 Conclusion
To solve the problem of slow,inefficient text mining of big data,we have proposed a parallel web text mining platform and built a web knowledge services system for the IT and telecom⁃municationsindustries.Theseserve as referencesfor thedevel⁃opment of subsequent products.

- ZTE Communications的其它文章
- ZTEUSAAnnounces Its First Corporate Partnership and Consumer Marketing Push in Conjunction with the Houston Rockets
- Powering Next-Generation Broadband Networks:ZTE's World-First Flexible,Configurable Router
- ZTELaunchesthe World's Largest Capacity Data Center Switches
- ZTEto Provide Disaster Recovery Solution to UMobile Malaysia
- IVI/MAP-T/MAP-E:Unified IPv4/IPv6 Stateless Translation and Encapsulation Technologies
- Optimal Ratefor Constant-Fidelity Entanglement in Quantum Communication Networks