
基于OMAP3530的视频监控客户端设计与实现
2013-04-29 00:04:27常娟
无线互联科技 2013年5期
关键词:视频监控
常娟
摘 要:本设计基于OMAP3530处理器的开发平台设计视频监控客户端。该客户端通过SIP协议和服务器端通信。视频监控客户端在OMAP3530开发板实现,其ARM端完成客户端呼叫,建立与视频服务器连接,音视频数据流接收、播放和存储等功能,其DSP端完成解码器实时实现。设计重点为客户端oRTP和eXosip库的移植、监控界面的设计和H.264解码器实时实现。
关键词:OMAP3530;视频监控;SIP;达芬奇技术
1 引言
OMAP3530开平台能够提供最优级别的视频图像图形处理,它包含有MPU子系统,IVA2.2子系统,片内内存,外部存储器接口,DMA控制器,多媒体加速系统,安全系统,综合的电源管理系统,以及丰富的外设,能够充分的满足处理视频流,2D/3D移动游戏,视频会议,高清图像,视频捕捉的需求,支持高级嵌入式操作系统如WindowsCE,Linux等系统[1]。本设计基于OMAP3530开发平台实现,通过SIP协议和服务器端通信,接收到视频流后进行解码输出到监视器端显示。
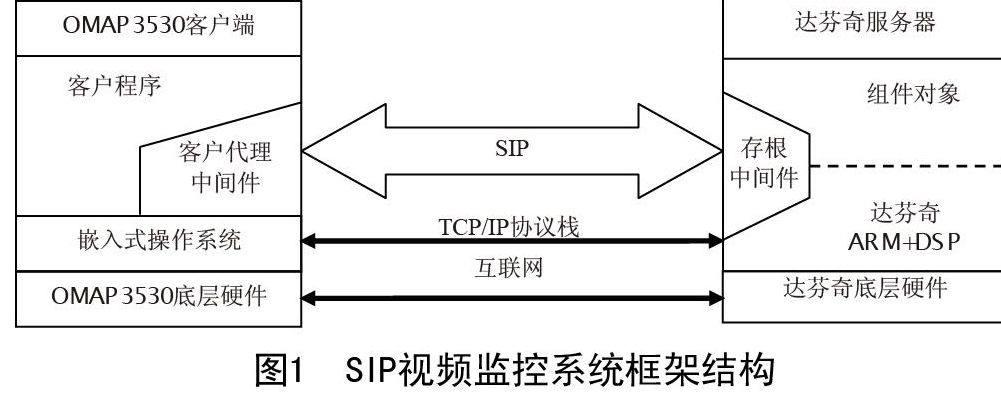
2 监控系统整体实现方案
整个视频监控系统包括服务器端和客户端,服务器端采用达芬奇开发平台TMS320DM6446,其功能实现视频采集、压缩和传输等功能;客户端OMAP3530平台完成音视频数据的解码、存储、回放、检索等功能。
达芬奇服务器端功能模块包含:ARM端系统控制模块,DSP端编码模块,SIP信令控制模块和RTP/RTCP实时数据传输控制模块。客户端功能模块包含:ARM端系统控制模块,SIP信令控制模块,RTP/RTCP接收模块,DSP端解码模块和播放显示模块。
3 监控客户端设计
本监控系统中,双向TCP控制通道使用SIP协议,UDP流的封装使用RTP协议。服务器和客户端相互交互采用SIP协议完成,具体使用SIP协议的UAS模块。RTP实现通过调用ORTP库,服务器端需要使用RTP发送功能,将服务器端DSP编码数据打包处理后发送到网络;客户端需要使用RTP接收功能,将接收到的数据传给OMAP3530 DSP端解码显示。
3.1 SIP实现
SIP会话协议主要包含以下四个主要组件:SIP用户代理组件、SIP注册服务器组件、SIP代理服务器组件和SIP重定向服务器组件[2]。
SIP的实现主要通过链接oSip库实现。oSip库实现效率高,主要功能是对SIP/SDP消息的API和事务处理的状态机进行解析,高层的SIP会话控制API通过调用底层API实现。SIP对于客户端处理事件包含以下三种情况:EXOSIP_REGISTRATION_SUCCESS事件、EXOSIP_CALL_CLOSED事件、EXOSIP_CALL_ANSWERED事件。EXOSIP_REGISTRATION_SUCCESS为表明用户是否注册成功; EXOSIP_CALL_CLOSED表明会话关闭,置picked、calling为假,呼叫结束;EXOSIP_CALL_ANSWERED用于获取UAS的SDP消息,并开始接受RTP包,将RTP包解包后,传输到OMAP3530 DSP端使其解码显示。
3.2 RTP实现
RTP用来网络上传输音频、视频、模拟数据等实时数据的传输协议[3]。本系统由RTP和UDP协议共同完成视频数据传输。
OMAP3530客户端实现:(1)初始化RTP协议,相关参数设置;(2)打开端口,RTP数据包开始接收;(3)RTP包接收成功后,解析RTP包头,解析得到多媒体数据;(4)RTP包接收结束,释放RTP信息。在这里不用考虑RTCP的信息接收与发送,通过调用ORTP库来完成。
3.3 解码器的实时实现
本系统采用的视频编码标准为H.264,H.264与以往的视频编码标准相比具有更好的压缩性能。H.264 具有优秀的压缩性能是多种新技术所产生效果的积累所致[4]。这些新技术包括:多模式帧内预测、可变尺寸块的运动补偿、多参考帧的运动补偿、4×4整数变换、高效的熵编码、环路滤波等。这些新技术大大增加了解码器实时实现的复杂度。为了解码器在OMAP3530 DSP端实时实现,结合OMAP3530 DSP硬件特性,本文主要使用Cache优化,EDMA传输和汇编及指令优化技术完成H.264解码器实时实现。
Cache优化最主要方法是尽可能提高Cache lines的重复使用效率,一般通过合理安排数据和代码内存位置,以及调整CPU的内存访问顺序来达到此目的,尽量减少Cache miss,增加Cache的命中率。Cache的优化包括程序Cache优化和数据Cache优化[5]。
H.264整个解码算法代码总结起来可以分成两部分:关键执行代码和生僻事件代码。代码进行Cache优化时,安排频繁调用的代码只包括关键执行代码,去除其中的生僻事件,从而减小动态存储区域的大小,减小L1P的冲突失效。对H.264解码的关键执行函数进行分析,调整其执行顺序,将调用频繁的代码放置在一起,可以使代码分配在连续的存储空间,从而提高指令Cache的命中率。对于比较大的函数代码段,可以通过将其分成几个大小适合程序Cache尺寸的小段来消除L1P中的容量失效。
DSP端内部存储器存储速度快,但容量太小,外部存储器容量大,但存储速度慢。解决办法是根据程序特性合理分配内存空间。数据分配的一个原则是尽量将数据放入片内存储器,由于图像分辨率很大,无法将数据全部放入片内存储器,但可以想办法保证当DSP需要数据时这部分数据已经存放在内部存储器中[6]。借助DMA的后台运行能力可以实现此目标。编码器的编码过程是固定的,其数据处理按一定顺序流程,因此可以通过操作DMA控制器完成内存和DDR2存储器的数据交换,大大提高了处理效率。本系统帧内预测和帧间预测使用DMA技术将需要的宏块数据提前放到内部存储器中。
对于比较耗时的H.264解码器模块采用DSP汇编指令进行优化。本文使用超长指令字(VLIW)[7]和打包数据处理技术[8]。(1)帧内预测残差模块:因当前数据和预测数据均为8位的无符号数需要使用UNPKHU4和UNPKLU4扩展为16为无符号数;然后采用打包数据处理指令SUB2一次完成两个数据相减。每取一次数据有五个指令周期延迟,故取数据是比较耗时部分,C64x+打包数据处理指令支持双字操作,故采用LDDW双字取数据指令,一次完成读取4个需处理数据。C64+有两个可进行数据处理的数据通路A和B,两个数据通路A和B完全可以并行执行,故一次取8个需处理数据,完成对一行数据的处理,分八次循环完成。(2)模式选择代价值计算:因预测数据未必满足32位字对齐的要求,故不能使用LDDW双字取值指令,使用LDNDW指令,当前块数据满足32位字对齐的要求,使用LDDW双字取值。利用SUBABS4指令一次完成4个打包的8位值间的差的绝对值。为了计算绝对值求和,构造常数0x01010101,利用DOTPU4指令一次将SUBABS4所求结果与0x01010101相乘,然后把4个乘积相加得到绝对值求和结果。由于C64x+ DSP中有两组寄存器A和B,两条数据通道,两组寄存器可以完全并行的执行,使A、B两组寄存器分别处理一行数据。
本文利用以上优化技术完成CIF分辨率H.264实时解码显示。
4 结论
本设计在OMAP3530开发板端实现视频监控客户端,其ARM端完成客户端呼叫,建立与视频服务器连接,音视频数据流接收、播放和存储等功能,其DSP端完成解码器实时实现。该客户端可以随时访问服务器和监控设备,界面友好,软件运行流畅稳定,该系统能够在局域网和广域网范围内运行。
[参考文献]
[1]Texas Instruments Incorporated.OMAP3530(SPRS504B)[Z],2010.
[2]刘勇,陈延雄.SIP协议的研究及呼叫控制实现[J].微处理器,2008(3):54-56.
[3]任泰明.TCP/IP协议与网络编程[M].西安电子科技大学出版社,2004.4.
[4]Richardson E G.H.264 and MPEG-4 Video Compression:Video Coding for Next Generation Multimedia [M].John Wiley & Sons, 12 August,2003.
[5]Texas Instruments Incorporated.TMS320C64x+ DSP Cache Users Guide (SPRU862).2006.10.
[6]Texas Instruments Incorporated.TMS320DM644x DMSoC DDR2 Memory Controller User's Guide(SPRUE22C).2007.11.
[7]Texas Instruments Incorporated.TMS320C64x+ DSP Megamodule Reference Guide(SPRU871K)[Z],2010.
[8]Texas Instruments Incorporated.TMS320C64x/C64x+ DSP CPU and Instruction Set Reference Guide(SPRU732J)[Z],2010.
猜你喜欢
软件导刊(2016年12期)2017-01-21 15:22:59
现代电子技术(2016年24期)2017-01-19 15:14:08
中国新通信(2016年21期)2017-01-06 12:28:19
电脑知识与技术(2016年28期)2016-12-21 12:05:36
电子技术与软件工程(2016年20期)2016-12-21 09:35:38
科技创新与应用(2016年33期)2016-12-17 14:59:01
中国科技博览(2016年23期)2016-12-09 17:08:48
电脑知识与技术(2016年26期)2016-11-24 18:19:53
电脑知识与技术(2016年24期)2016-11-14 01:59:47
数字技术与应用(2016年9期)2016-11-09 23:10:41
