
常见错字特征量化分析软件的研究与实现
2013-04-24 15:24:08李震
中国刑警学院学报 2013年3期
李震
(中国刑警学院 辽宁 沈阳 110035)
常见错字特征量化分析软件的研究与实现
李震
(中国刑警学院 辽宁 沈阳 110035)
通过计算机对错别字出现率及其影响因素进行研究,对常见错字出现率及其影响因素进行数据统计,为错字特征的实际应用及其特征价值的评断提供相对客观的依据,并在笔迹检验与鉴定工作中,方便鉴定人员能够更好地对错字特征进行把握。同时也为错字出现率的统计研究及错字特征价值评断的深入研究探索科学的研究方法。
笔迹 笔迹检验 错别字特征
错别字特征是笔迹检验中的一类重要特征,由于它具有很强的特殊性和稳定性,在笔迹检验中拥有重要的地位。在笔迹检验中,一般把错字和别字归为错别字特征,主要用于对书写人的同一认定。目前在文件检验领域,大多都是对如何正确使用错别字特征进行定性的讨论,并未见对错别字特征进行系统的量化研究,对错别字特征价值的评估也大都来自于检验鉴定人员的经验,主观性极强,据此做出的鉴定结论也缺乏说服力。通过计算机对错别字出现率及其影响因素进行研究,可以使我们更好地把握错别字特征,准确地评断其特征价值。在分析统计错别字出现率的基础上,判断其在笔迹检验中应用价值的高低,将对笔迹检验工作起重要的指导意义。同时在一定条件下,通过人机结合,还可以通过某些错字所表现出来的特点及规律,为判断书写人的个人情况提供参考,从而为侦查破案提供线索和依据。
1 错别字特征量化分析的理论研究
1.1 错别字的含义及产生原因
通常所说的错别字包括错字和别字。错字是指书写人对字的正确写法和结构不了解或掌握不够准确而写错的字。错字是文字系统中根本不存在的字,主要表现为把笔画写错,或是增减笔画,或是排错偏旁的位置等。别字与错字不同,是指该写甲字时写成了乙字。
汉字笔画结构复杂,汉字中笔画繁多的为数不少,这些字在书写时稍有马虎,或记得不准确,很容易出现多笔少画的现象以及错写为其他字。汉字形体结构相似,汉字是由点、横、竖、撇、捺、折等几种笔画结构组成。由于笔画形式不多,在组字结构上势必会出现许多相似的地方,加之书写技能的迁移,导致人们在学习和使用汉字过程中,很容易把字的某一部分记混。汉字属于表义体系的文字,汉字的字形和字义有着非常密切的联系。有许多汉字,只有了解它们当初的本义,才能加深印象。仅仅记住字形,只能得到表面的、浮浅的印象,在书写时难免要出现错别字。
1.2 确定常见错别字
易错样品字的选取是理论研究的重要环节。样品字的选取经历了初选和确定两个阶段。样品字的初选参考《错别字辨析手册》(杜维东著)、《常见错字的分类及其更正的理据分析》(彭志雄著)及平时案件鉴定中常遇到的错别字,初步选择了157个易错样品字,并设计了错字调查表确定样品字的组合,即把它们分别编入常见的词组,在词组中省略样品字,下画横线,在横线前的括号内用拼音把样品字标注出来,以保证书写人正常填写样品字。在不同年龄段、不同性别、不同文化程度、不同职业以及不同地区范围内选择500名调查对象,发放并回收《汉字调查表》。对有效的456份调查表中的157个样品字的出错率进行了人工统计,按错字出现率从高到低排列,对157个字的错字出现情况进行研究,剔除其中空字现象严重和部分未出现错写的字,同时又增加个别实际案件中易出现的错字后,最终形成了143个字的样品字调查表。
2 错别字库的建立
实现计算机对错别字出现率的量化分析,首先要建立计算机可识别的错别字库,建立计算机能识别的错别字库有两种方法,一是利用造字程序,造出所发现的每个错字并保存在计算机的字库中;二是将各种错字手写出来,通过扫描图像存储在数据库系统。经分析研究,第一种方法造字过程本身比较繁琐,要使用查询软件其他计算机也必须先安装此字库,同时造字程序也会影响本软件的推广和使用。最终决定采用扫描手写文字图片的形式建立相应的数据库。
2.1 错别字库的来源
为了保证错字库的丰富性和有效性,对收集的1400余份调查表和前期收集的400余份调查表逐份逐字进行分析,将发现的每个字的各种错写、别字、空字等信息记录在《143个字情况一览》表中。然后将每个人的记录表汇总,形成了错字库内容的原始记录。
2.2 错别字库的制作
经过计算机技术人员的测试,确定书写样品字的规格为15mm×15mm。首先利用计算机制作并打印出相应规格的方格纸;再由专人在方格纸上用楷书书写经过汇总的字库内容(即错字原始记录表中的所有错字);然后利用计算机photoshop软件对写完的字样进行扫描,调整色阶后保存;最后,利用photoshop软件将已保存的字样按单字进行切分,并保存在按不同样品字形成的相应字库中(见图1)。

图1 “步”的错写字库
2.3 错字库中错字的编码
要实现错字库中各种信息的综合查询,首先必须按照一定的规则建立关键字,由此对字库中的每个错写图片进行编码,每个错字采用8位编码,1-3位代表所研究的143个字。数值与调查表中的顺序一致,不足三位时在前方用0补齐,如第一个字“步”编为001,第21个字“庆”编为021;4-5位代表该字按偏旁划分,出现错别字的类别。正字、空白和其他为00。在本错别字字库中先以与正字的相似度划分,然后以不同偏旁错别字多少划分,分为01、02……,目的是便于数据录入和查询,如“隙”出现的27个错字中,“耳刀旁出现14个,最多,此类错别字编为01”“绞丝旁出现6个,第二多,则此类错别字编为02”,其他依此类推;第6位代表按照错字原因划分,错字类型。正字、空白和其他为0,多笔画(只多一笔)为1,少笔画(只少一笔)为2,结构错误为3,受上下字影响为4,其他类型错字为5,别字为6,“空白”(未填)为7;7-8位代表各类别错字的具体内容。正字为00,空白为01,其他为02按错别字笔画数和相似度依次编为01、02,并据此对字库中所有的信息进行了编码。
3 分析软件的开发与设计
本软件共分为系统管理模块、数据录入模块、数据查询模块和本库信息模块四部分。
系统管理模块将本软件系统划分为系统管理、查询使用、数据录入三种权限。其中系统管理权限是使系统管理员对系统进行综合维护和管理,该权限可以使用本软件系统中的所有功能,即数据录入功能、数据查询功能、数据管理功能和人员管理功能。查询使用权限授予最终用户使用,可以通过本系统对数据库中的数据进行查询和分析,仅具有数据查询功能和部分人员管理功能(仅能对用户本身的用户名和密码进行修改)。数据录入权限是将汉字调查表中的错字信息录入后台数据库的用户使用。
数据录入模块是由错别字录入和调查表录入两个子模块构成。其中错别字录入子模块具有两部分功能,一是由系统管理员将汉字调查表中的143个易错字和利用易错字构成的词组添加到数据库中,另外一个功能是系统管理员对每一个易错字的各种错写、正确写法、空白添加至数据库中,每个易错字的各种错写主要来源于汉字调查表中可能出现的各种错写和办案实践中所发现的错写。系统管理员录入完毕后,调查表录入子模块就会将原来纸质调查表中所有词组显示在界面上,其中填空部分是由每个易错字的所有错写、空白和正确写法绑定在下拉框组成。汉字调查表录入时系统默认的字是正字。用户录入时,只需对照汉字调查表录入出现错写的易错字即可,录入速度快,可维护性极强。
数据查询模块是由易错字和错别字查询、条件和分组查询以及高级查询三个子模块构成。其中易错字和错别字查询子模块可以查询数据库中的易错字及各种错写查询、每个易错字的总出现率和每个易错字中各个错写的出现率;条件和分组查询子模块是由易错字条件查询、错写条件查询、分组查询和高级分组查询四部分构成。易错字条件查询可以查询数据库中满足各种特定条件的人群且易错字总出现率在特定范围的具体易错字。错写条件查询用来查询数据库中满足各种特定条件的人群且各种错写总出现率在特定范围的具体易错字错写情况。分组查询的功能是按数据库中自然人的各种属性(年龄段、性别、职业、文化程度、书法爱好)查询写错别字的比例。高级分组查询可以按数据库中自然人的各种属性(年龄段、性别、职业、文化程度、书法爱好)对每一易错字写错别字的比例;高级查询子模块是由某易错字出现率查询、多个易错字错写人群查询、错字种类查询和按种类查询易错字错写情况四部分构成。某易错字出现率查询可以查询数据库中满足各种特定条件的人群中每个易错字各种错写的出现率。多个易错字错写人群查询用来查询数据库同时具备多种易错字错写情况的人群自然情况。错字种类查询的功能是查询数据库中每个易错字各种错误类型的错写情况。按种类查询易错字错写情况是通过输入音序查询易错字再查询选中易错字的各种错误类型的错写。
本库信息模块是由人员信息和易错字信息两个子模块构成。其中人员信息子模块主要反映数据库中所包含所有人的自然情况(年龄段、性别、职业、文化程度、书法爱好)。易错字信息子模块主要反映数据库中所包含所有易错字各种易错类型的数据统计。
4 数据录入与查询结果分析
系统后台数据库采用SQL Server数据库服务器,可以有效利用局域网同时满足多人进行实时数据录入,将1400余份调查表中的全部信息逐一录入系统数据库中,节约大量数据录入时间,提高数据录入的准确性,也为本软件系统后期大量数据录入工作积累宝贵经验。启动软件,进入登陆界面,输入录入权限的用户名和密码,进入软件界面,点击“数据录入”下的“汉字调查表录入”进入调查表录入界面,界面结构友好,完全按照汉字调查表设计,用户只需选取易错字即可,默认为正字,完成汉字调查表的数据录入工作(见图2)。

图2 汉字调查表录入界面
数据录入完毕,编制的143个易错字查询分析软件实现了143个易错字出现率的量化查询。通过本软件可以实现多种查询功能,可以查询143个易错字在录入的数据库中的出错率并按照降序或升序排列及每个易错字出现各种错写的出错率(见表1,表2),也可以结合一份笔迹材料中出现的若干个错字,分析经查询出现这些错字的人是否具有共同特点等。

表1 易错字出错率情况表(前10字)
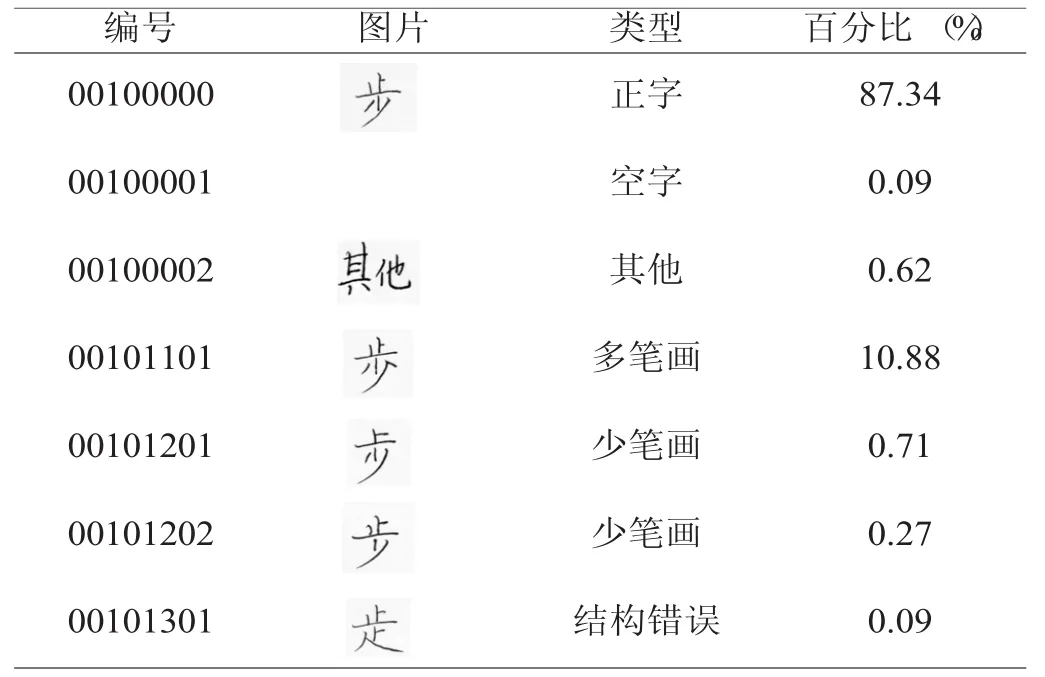
表2 “步”字各种错写的出错率
5 结论
开发143个易错字查询分析软件,实现了143个易错字出现率的量化查询。通过该软件的查询功能可以分析各类人群的自然情况、常见错写的出错率等,针对笔迹中错别字的研究思路和方法同样适用于其他各类笔迹特征,也为各类笔迹特征的量化分析系统的研制奠定良好的基础。
1.贾玉文,邹明理.中国刑事科学技术大全文件检验[M].北京:中国公安大学出版社,2002
2.贾玉文.笔迹检验[M].北京:警官教育出版社,1999
3.Christian Nagel,Bill Evjen,Jay Glynn,等.C#高级编程[M].第七版.北京:清华大学出版社,2010
4.王小科,王军作,等.C#开发实战1200例[M].北京:清华大学出版社,2011
猜你喜欢
科技信息·学术版(2021年9期)2021-08-22 02:29:20
中国管理信息化(2021年4期)2021-03-16 02:47:24
销售与市场(营销版)(2020年9期)2020-11-25 13:38:24
学生天地(2020年24期)2020-06-09 03:08:56
意林·少年版(2019年19期)2019-11-13 15:56:58
趣味(语文)(2018年9期)2018-12-23 02:19:58
趣味(语文)(2018年7期)2018-06-26 08:13:54
电子世界(2018年7期)2018-04-26 08:51:35
科学与技术(2018年6期)2018-01-07 11:02:02
警察技术(2015年4期)2015-02-27 15:37:36
