
拓展历史认知语言学研究新视野的工具
——美语历史语料库(COHA)的应用*
2013-03-11 01:06李华勇
重庆工商大学学报(社会科学版) 2013年6期
李华勇
(四川文理学院 外语学院,四川 达州 635006)
一、历史认知语言学
历史认知语言学(Historical Cognitive Linguistics:简称HCL)是历史语言学和认知语言相互渗透和相互融合的一门交差学科;二十世纪九十年代,历史语言学开始关注认知语言学,(通过相关国际会议)两者开始携手合作,开启两者融合之路;2010年《历史认知语言学》的出版标志着HCL的正式诞生(王寅,2012:927)。历史语言学(Historical Linguistics:简称HL)是研究语言演变历史的学科 (徐通锵,1991:1),它以历史文献为基础,以时间为主线来研究语言在不同时间段的状态、结构、渗透和变异过程与规律的语言学分支学科;它作为一门正式的学科约有200多年的历史。由于历史文献无法直接被感知,同时其间的证据还有可能缺失或不连贯,因此,历史语言学的研究者们不得不对这些有限的文献采用相关理论和方法进行“推演和重构”,如徐通锵(1991)提出的“历史比较发、结构分析法”。
随着认知科学的发展,认知语言学(Cognitive Linguistics,简称CL)近几十年来发展迅速,它不断拓展研究范围和方法,早已走了出了“认知语义学和认知语法”的视野,近年来先后出现了认知语音学、认知词汇学、认知辞书学、 认知语篇学、认知语用学、认知诗学和认知社会语言学等。其中,语言研究者们自然也不会忽视HL和CL的融合:HL从1990s年代开始关注CL,借用其理论和方法来解释语言变化的一般理论、方法和原则。1990年和1996年在德国召开了由认知语言学家和历史语言学家参与的以“共时与历史:语言历史与认知”和“历史语义学和认知”为主题的国际研讨会。2007年8月召开的第10届国际认知语言学大会,学者们开始主张在CL理论框架下审视HL的相关问题,积极推动HL和CL的研究相互渗透和融合,主张HCL的研究思路,以挖掘边缘学科的潜在优势。Wintersetal.(2010)主编的HistoricalCognitiveLinguistics(《历史认知语言学》)的出版,标志着历史语言学(HCL)这门学科正式问世。王演 (2012:928)对HCL作了如下定义:它是以认知语言学为理论框架,追寻语言各层面演变的原因和过程,探寻其中的认知规律,分析其间的各种关系,重构扩散和变异的路径,从共时和历史两个维度深入研究语言诸方面的问题。
二、历史认知语言学与语料库的结合
HL重视分析和解释历史文献资料,从中获取有用信息,追源语言变化发展规律。CL也是很重视这一研究方法,并推动其继续向前发展——进一步在理论上构建了“基于用法的理论”(Usage-based Theory,简称UBT),这是后现代语言研究的一条重要指导原则,也使HL获得更坚实的理论依据。融合了HL和CL的HCL必然重视对大量真实语料的分析,对“频率”产生浓厚的兴趣;随着计算机和互联网的发展,各种界面友好和检索功能强大的语料库随之创建起来,为历史认知语言学与语料库的进一步结合提供了坚实的工具基础和技术基础;在语料库中,通过计算机对其中大量语料的自动检索,很容易获得语言中的各类结构(如词、短语、句法结构、语义结构)的频率。以语料库为基础获得的语言结构的这些频率数据,为解释和说明相应语言结构历史变化规律提供了坚持实证据,避免了依靠以语言研者的直觉为基础的内省式推理的缺陷。Taylor (2012)指出,整个语系统都是具有“频率效应”(frequency effects)的——同类结构中,有些结构比其它结构出现的频率高;在同一结构中,有些词语比其它词语使用频率高。语言结构的使用频率对语言变化和发展起着重要作用,高频使用可以促进某些语言结构在个体心智中的固化 (entrenchment)和促使其在整个语言使用社团中逐渐规约化(conventionalization),也可以促使其迅速传播,从而引起语音、词汇、句法、语义等方面的变化。总之,频率效应是贯穿整个语言历史变化和发展。对语言的历史研究和考查最终都应该落脚在“频率”上来。桂诗春(2004)在《以概率为基础的语言研究》一文中,从语言事实和语言理论的角度对语言学中的理性主义及其内省式研究方法提出了质疑,介绍了作为相反潮流的概率语言学、语料库语言学等最新发展。认知语言学日益重视用“基于用法的模式”来研究语言事实背后的理据性,而语料库里检索到的大量语料实事能客观地呈现出语言结构的“用法模式”,因此语料库是认知语言学和历史认知语言学相关研究的有力工具,越来越多的历史认知语言学家重视语料库在其研究中的作用、促进两者的融合、开启认历史知语言学研究的新视野。
三、COHA扩展历史认知语言学研究新视野
美语历史语料库(Corpus of Historical American English,简称COHA)于2010年晚期由美国的Mark Davies教授建成并发布在国际互联网上供语言研究者免费使用。COHA是一个具有4亿词每隔10年为一个时刻度,时间跨度为1810s~2000s近200年的篇型平衡(genre-balanced)的历史语料库,它包括了小说、杂志、报纸和非小说四大类篇型,并且做到词类标注详细和准确,保持了每年每种篇型的平衡性和均等性,能尽量反映出近200年以来美语的词汇、形态、句法和语义的历史发展和变化情况(Mark Davies 2012:122)。COHA的建成和发布,为HCL的研究提供了一个功能强大的研究平台,进一步推动了HCL和语料库的渗透与融合,极大地拓展了HCL研究的新视野。
由于COHA对其中的语料进行了详细的词类标注(tagging POS)、独特的相对数据架构设计(architecture of relational databases)和多功能的检索界面(interface),COHA能迅速完成对近200年以来美语中的词汇、形态、句法、语义、语用和语篇等方面的研究。Davies (2012:125)指出对COHA进行词类标注的工具是CLAWS tagger,这一标注工具是BNC,COCA和其它主流语料库的标注工具,其准确性相当高。Davies (2009:164)指出他自己设计的这几大语语料(COHA, COCA, BYU-BNC和Time Magazine Corpus)采用的都是关系数据库,认为采用这一数据库结构的好处是检索速度更快和使语料库库容够更大,对4亿词的COHA进行任何复杂检索都是在1-3秒完成;同时关系数据库还可以使语料库中存在“分子”结构(Davies 2009:166),它能让其它附加特征集(additional feature sets)很容易整合到COHA这种语料库中去,进一步拓展其检索功能的多样性。COHA准确的词类标注和关系数据库架构保证了其网页检索界面功能多样性和友好性。下面分别举例说明COHA在对美语中的词汇、形态、句法、语义和社会文化等方面历史研究方面的独特功能,以展示其在拓展HCL研究新视野的优势。
(一)COHA对词汇历史变化的研究
COHA的架构方式和检索界面,最基本的功能是能检索到任何一个词或短语由1810s至2000s近200年每隔10年的频率变化情况。例如,在COHA检索界面的WORD(S)处输入单词“research”,同时显示方式(DISPLAY)选择图表(CHART),就可以得到单词“research”的历史频率变化情况的图标显示,如图1。

图1 research 在1810s—2000s中每隔10年的历史频率变化情况
从图1,我们可以一目了然地观察到单词research在1810s~1910s频率波动变化不大,而1910s~2000s频率变化经历了迅速上升的过程,说明该词的使用日益频繁。
让我们再来看看短语[be]going to在COHA中的历史变化情况:在COHA检索界面的WORD(S)处输入短语“[be]going to”,同时显示方式选择图表,得到“[be]going to”的历史频率变化情况图标显示,如图2。

图2 [be]going to 在1810s—2000s中每隔10年的历史频率变化情况
图2表明动词短语[be]going to的使用频率经历了由少到多逐渐上升的历史过程,于1990s其使用频率达到最高峰。
由于COHA独特的架构设计和数据存取方式存储了每一个相匹配被检索字符串的每隔10年的频数,这使其能显示所特定词类词或短语在一个特定时间段与另一个特定时间段使用频率高低的排序变化情况,这样我们就很容易跟踪到特定时间段特定词类的词或短语哪些词或短语在这个时间段出现频率最高或最高低,同时进行相关词或短语在另一特定时间段的比较。例如,我们可以比较1880s~1910s期间出现的高频形容词和1970s~2000s其间出现的高频有什么变化。只要在COHA的检索入口WORD(S)处输入[j*],在SECTIONS1选定时间1810s~1910s,在SECTIONS2处选定时间1970s~2000s,同时显示方式选列表(LIST),然后运行搜索引擎,就得到结果如表1所示。
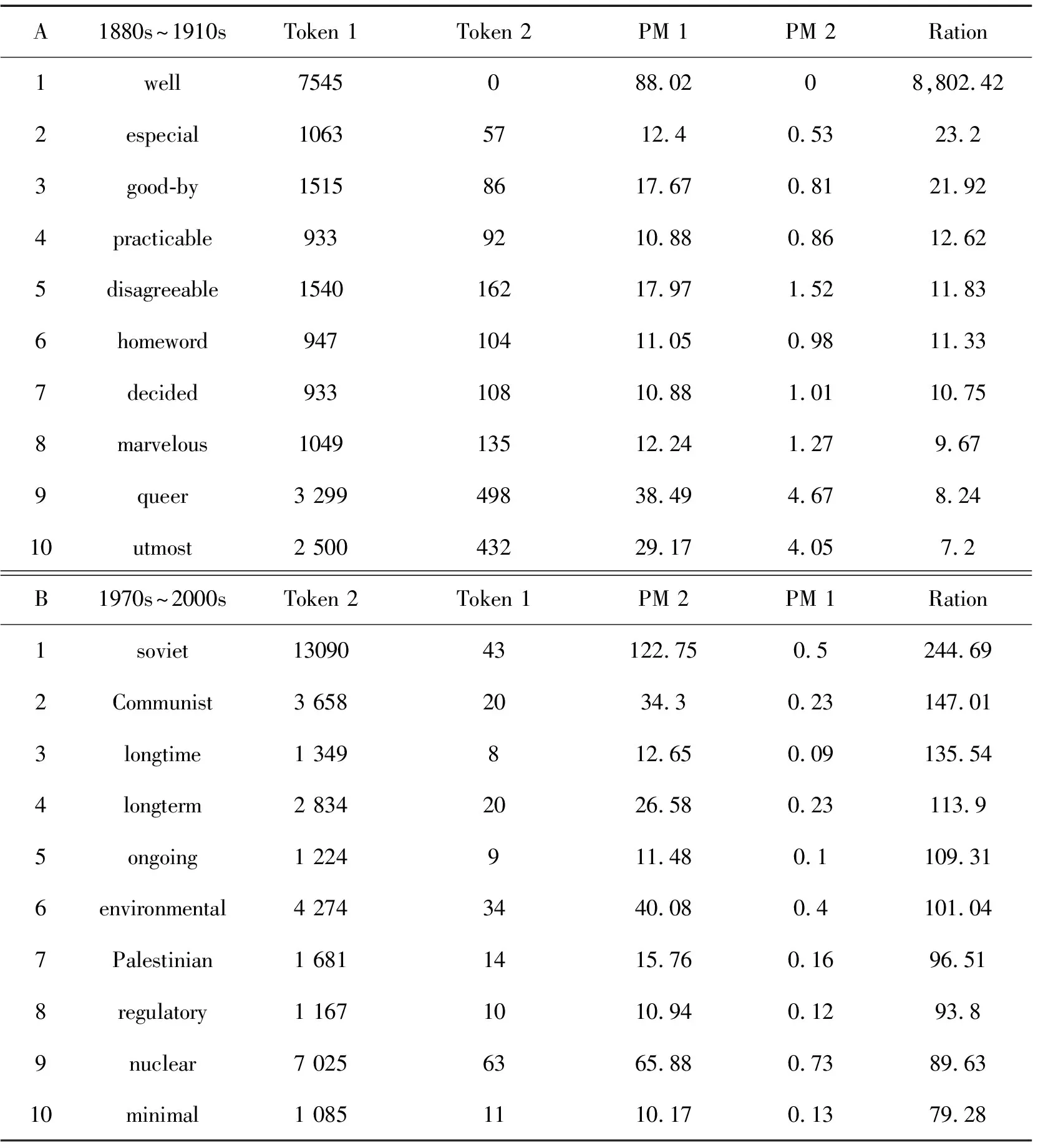
表1 1880s~1910s使用的高频率形容词与1970s~2000s使用的高频率形容词比较[注]表1中的数据说明如下:例如表1B中的第6个形容词environmental,它在1970s~2000s期间(Token2)共出现4274次,而在1880s~1910s(Token 1)仅出现34次。PM1和PM2分别是Token1和Token2对应词的每百万词的标准化频率(Normalized frequency per Million)。表中的Ration是PM1和PM2的比值,在计算Ration时,如果token 2出现的次数为0,即PM2为0,要对要对其进行平滑(smooth)处理,以避免分母为0。Environmental的ration为101.04表明它在1970s~2000s时间段出现的频率是其在1880s~1910s时间段出现频率的101.04倍,表1A和B是以Ration的大小进行排序的,这些数据都是系统自动计算生成的。后面的类似表格数据含义与此相同。
表1显示,1880s~1910s使用的高频率形容词与1970s~2000s使用的高频形容是不同的:表1A表明1880s~1910s使用最多的形容词为well, especial, practicable这些都是极常用的形容;表1B中的形容词Soviet,Palestinian, environmental, nuclear是对这一时间段的国际社会背景、社会思潮和社会文化的一种的反映:苏联剧变、巴勒斯坦问题、日益引起关注的环境问题、核能问题。通过检索COHA中特定时间段的特定词类也能很好地从语言视角窥视当时社会背景、社会文化或社会思潮,据此能更好认识和解释某些词和短语的历史演化过程的社会背景。
(二)COHA对词的形态历史变化研究
COHA也能提供关于词的形态(morphological)方面的历史演变情况。我们在COHA的检索界面的入口WORD(S)处输入[*cracy],显示方式处选列表,SECTION1处的时间选1810s~2000s,运行搜索引擎得到结果例如表2。它就是我们在COHA中检索过去200年以来以-cracy结尾的前10个词的每隔10年一个时间刻度的历史演变情况。由表2我们可以看到有些词的使用频率在历史发展中是在增加的:如democracy,在1810s~1930s;bureaucracy在1830s~1990s;而有些词的使用频率是在减少的:如aristocracy在1850s~1990s由最初的317次减少到1990s的53次,差不多减少了83.3%;还可以看到有些词语比如technocracy是随着时代的进步而产生的,随着社会对某些观念(科技)的重视而使用频率逐渐增加。从COHA获取的这些关于词的形态方面的信息,为我们深入窥视、了解和认识美国的社会和文化方面的变化有着重要的意义。
COHA除了可以观察词的形态历史频率变化情况外,还可以比较特定时间段词的形态使用情况的变化,如表3。观察美语中词的形态方面的这些变化情况可以更好的理解美国文化和社会的总体变化情况。由表3中B表可以看出:meritocracy,marketocarcy,technocracy这些词只在1970s~2000s期间有分布,是这阶段美国“精英管理的社会”“市场经济”“技术主导”的社会、文化和主流意识形态的反映;而表3A表中:plantocracy,plutocracy,aristocracy这些词语频繁使用在1870s~1910s期间,很少使用在1970s~2000s期间,集中反映了美国这一时期的“大庄园主阶级”“富豪统治”和“贵族”社会背景和文化状况。
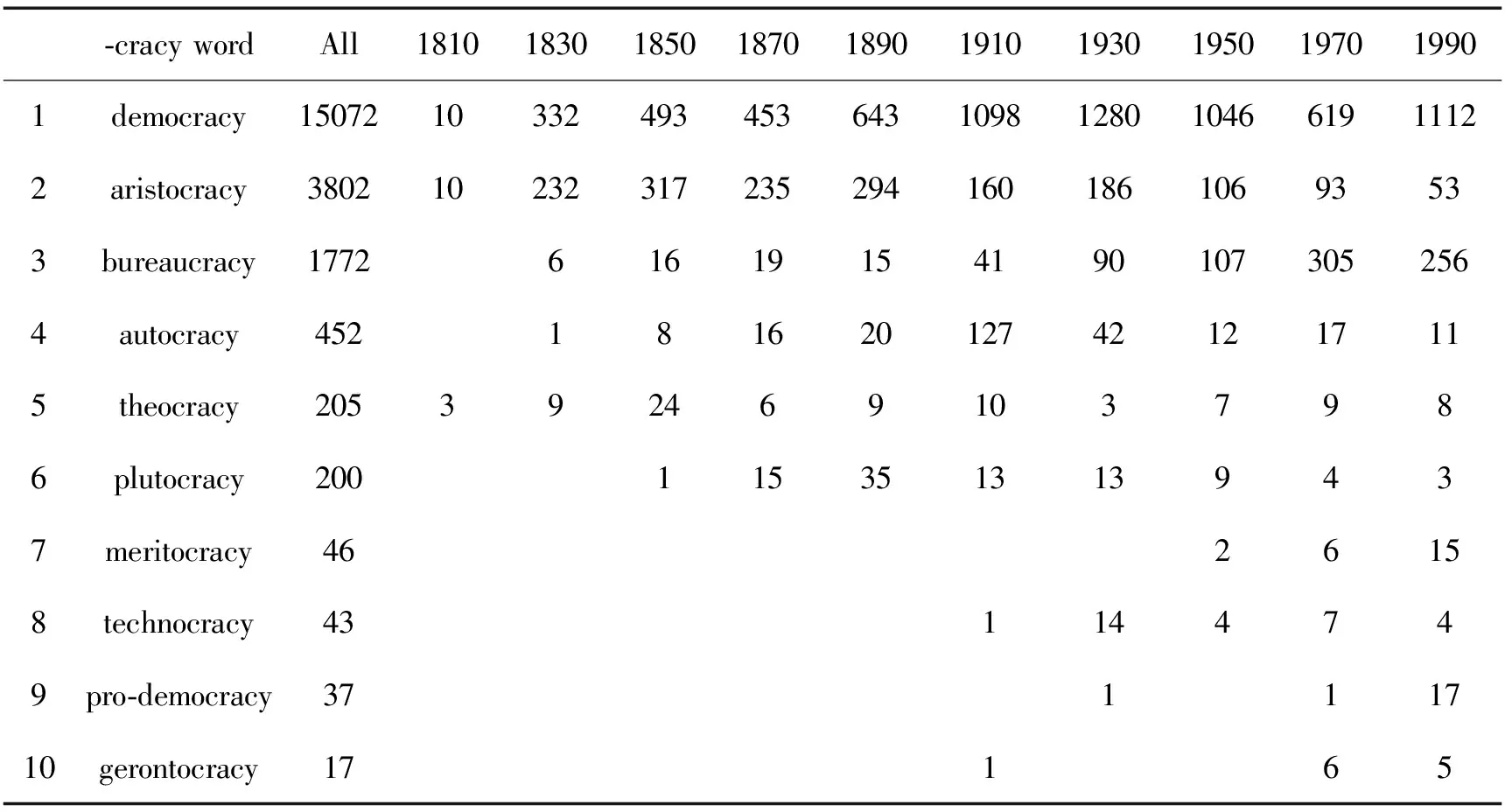
表2 以-cracy结尾的词历史频率变化情况[注]表2中,为了结约版面空间,这里选取1810s~2000s中每隔20年为一个时间刻度来展现这前10个词的历史频率变化情况,显示的也只是原频率数(raw frequency)。在COHA中的实际检索结果是按10年为一个时间刻度显示,同时不同频率频率而用不同的颜色突显出来,频率数据可以用原始频数显示也可用标准化(normalized)了的频率显示,检索的结果也不只限这10个词,COHA能检索到所有的以-cracy结尾的词并全部显示出来(我们检索到的-cracy共有192个)。
(三)COHA对句法历史变化的研究
由于COHA中的语料进行了按屈折变化形式进行归类标记(lemmatized)和词类标注,我们可以用它对美语句法变化(syntactic change)进行深入历史研究。例如,我们可以利用COHA观察分裂不定式(split infinitive)和非分裂不定式(non-split infinitive)在1810s~2000s近200年使用频率的历史变化情况,分裂不定式是指“to+ADV-ly +do”,非分裂不定式是指“to +do+ ADV-ly”;表4只列出了按照检索句法“to *ly.[r*][v*]”(如,to seriously take)和“to[v*]*ly.[r*]”(如,to take seriously)输入到COHA中的检索入口WORD(S)处,同时分类和限定(SORTING AND LIMITS)处设定为1,在COHA中检索到的结果在1940s~2000s年的各自使用频率变化情况,尽管在COHA的检索结果界面有1810s~1930s数据,但本表的篇幅不允许将其能完整显示出来,我们只选取了1840s~2000s这段时间出现的频数变化结果。
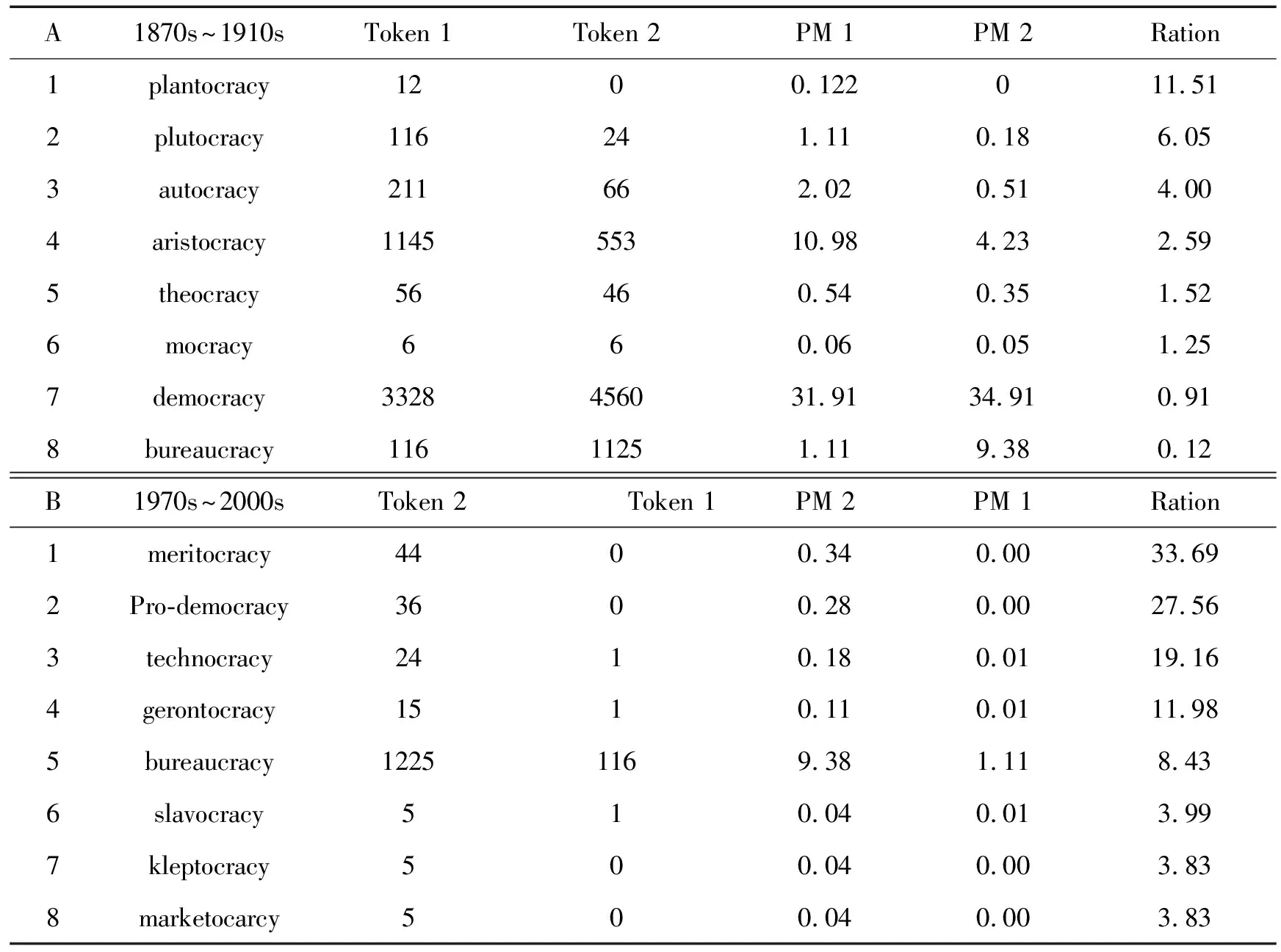
表3 1870s~1910s年以-cracy结尾的词与1960s~2000s年以-cracy结尾词的比较
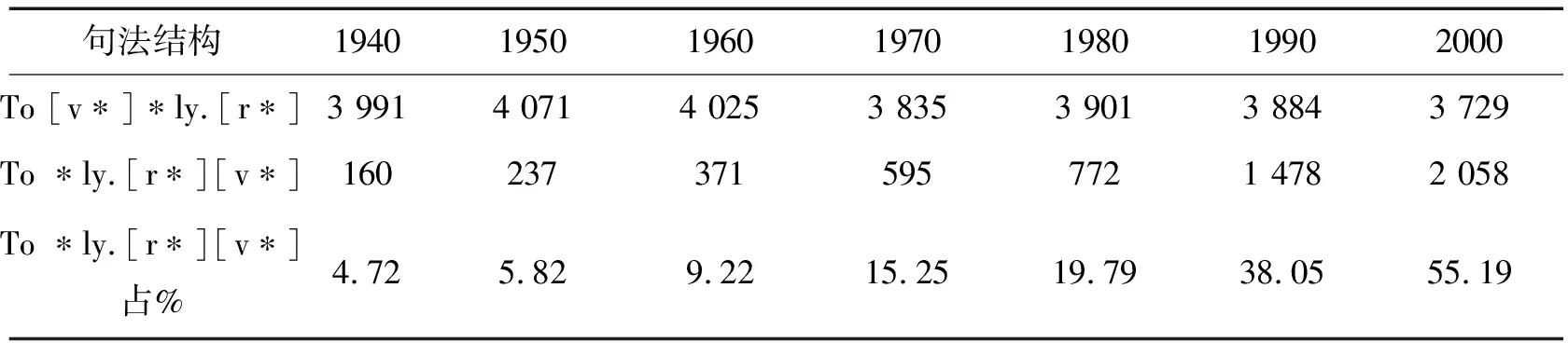
表4 “to +ADV-ly +do”和“to +do +ADV-ly”在1940s~2000s年使用频率变化情况
从表4,我们可以看到分裂不定式结构“to + ADV-ly + do”在940s~2000s期间的使用频率是在大幅增加的,从最初的4.72%到2000s年55.19%,增加11.7倍;因此,相应的非分裂不定式结构“to+do+ADV-ly”使用频率自然是在大幅减少。在以前的规定语法(prescriptive grammar)中,认为分裂式不定式是属于不符合语法表达规范的,是错误的表达。而基于COHA检索到的语料结果来看,分裂不定式被日益频繁地使用在美语各类文体的表达中,并有取代非分裂式表达正统地位的趋势;显然规定语法中关于分裂不定式的这一条说明该过时了,因为其与美语日常真实使用分裂不定式之事实严重不符。
我们还可以得用COHA进行更复杂句法结构历史研究。比如说,我们可以很容易利用COHA的相关检索规则,观察be-passive和get-passive这两类被动语态的使用频率在1810s~2000s年历史变化情况:在COHA的检索入口WORD(S)处输入“[be][vvn]”就可以检索到be+V-ed形式的被动语态,即be-passive;在检索入口处的WORD(S)处输入“[get][vvn]”就可以检索到get+V-ed形式的所有被动结构,即get-passive,显式方式选里面的“图表”显示,检索结果如表5所示。

表5 get-passive和be-passive在COHA中使用频率历史变化情况
从表5我们可以看到get-passive的使用频率随着时间的发展是在逐渐的缓慢增加,由最初的不到0.13%发展到2000s年的3.25%,显示这一表达已经在美语中某些文体中大量使用。
(四)COHA对语义历史变化的研究
通过语料库观察词的语义历史变化趋势的传统方法通过是检索出该词的所有形符(token)或随机抽样(randomized)形符,然后研究其用法模式以考察其语意变化,耗时费力(Davies,2012:142)。但是如果用架构合理的语料库,就能简明和迅度实现对词语语义历史变化情况进行观察。语料库语言学中的一个核心观念是“我们可以通过一个词的伴随词知其语义”(Firth,1957:179)。如果我们检索找到一个词的所有搭配(collocates)的历史变化情况,这些搭配就能表明其语义的历史变化情况。比如在COHA中,我们检索与queer一词搭配使用词的形容词历史变化情况——在COHA的检索入口WORD(S)处输入单词queer,在COLLOCATES处输入[j*],设定前后4个字符距,SECTION1时间选1870s~1910s,SECTION2时间选1960s~2000s,然后运行索引擎。我们发现,在1870s~1910s期间与queer搭配的形容词主要有little,young,awful,old,再观察这些词的所在索引行(concordance lines),发现queer主要的语义是“strange (奇怪的)”;而在1960 s~2000 s期间与queer搭配的形容词主要有cultural,straight,gay,再观察这些词所在索引行,发现queer主要语义是“gay (同性恋)”的含义,其语义发生了明显的变化。
Davies(2012:143)指出直接比较一个词在两个特定时间段的搭配词能够为其语义和用法的历史演变提供更清晰的证据。例如,我们检索web这个词在COHA中的1870s~1910s期间与之搭配的形容和web在COHA中的1970s~2000s期间与之搭配的形容词,结果如表6所示。
从表6A我们可以看到:在1870s~1910s与web搭配最多最密切的是bright, shinning, golden等,结合考察这些词所在索引行,可知这一时期web的主要语义是“网状之物”;而在1970s~2000s与web搭配最多的最密切的是wide,available,personal,corporate等,这些搭配词在1870s~1910s几乎没有出现过,结合考察这些词所在的索引行,可知这一时期web的浮现(emergent)出了新语义“网络(因特网)”。
除了上面介绍通过搭配来考察词的语义历史演变外,COHA还提供了具有30000多词条的同义词集合(synsets)子库,通过这一工具能考察到词的整个语义历史演变情况。在COHA的检索入口WORD(S)处输入“[=WORD]”,就可以看到与之相配的同义词每隔10年的频率分布变化情况;比如输入“[=beautiful]”,就可以找到与beautiful同义的所有形容词,并按10年一个刻度显示出来,同时可显示这些同义词的原始频数和标准了的频率(每百万词出现的次数),同时还用不同的颜色来标示频率的高低,使检索者一目了然,如图3。
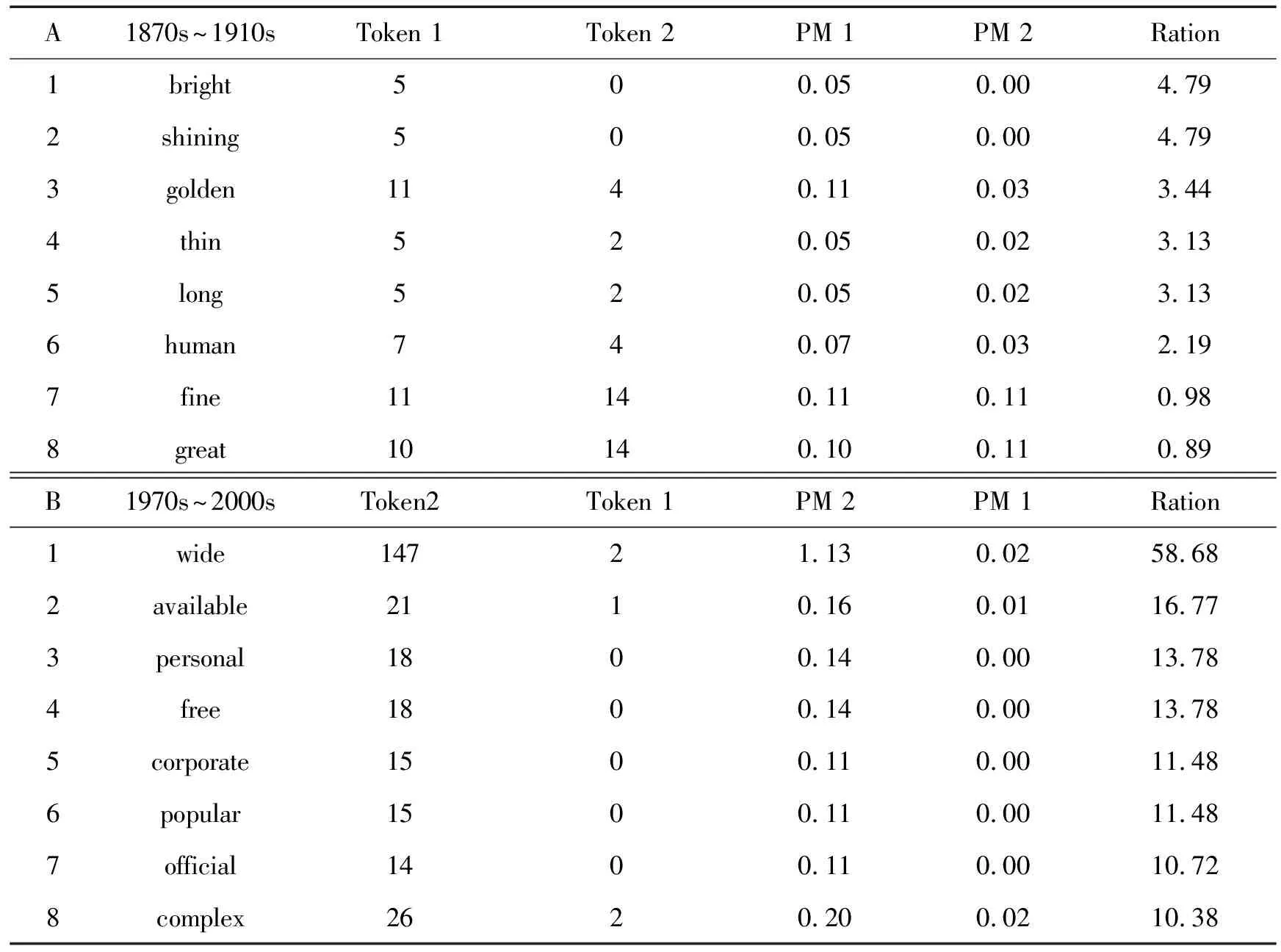
表6 1870s~1910s与web搭配的形容词和1970s~2000s与web搭配的形容词比较
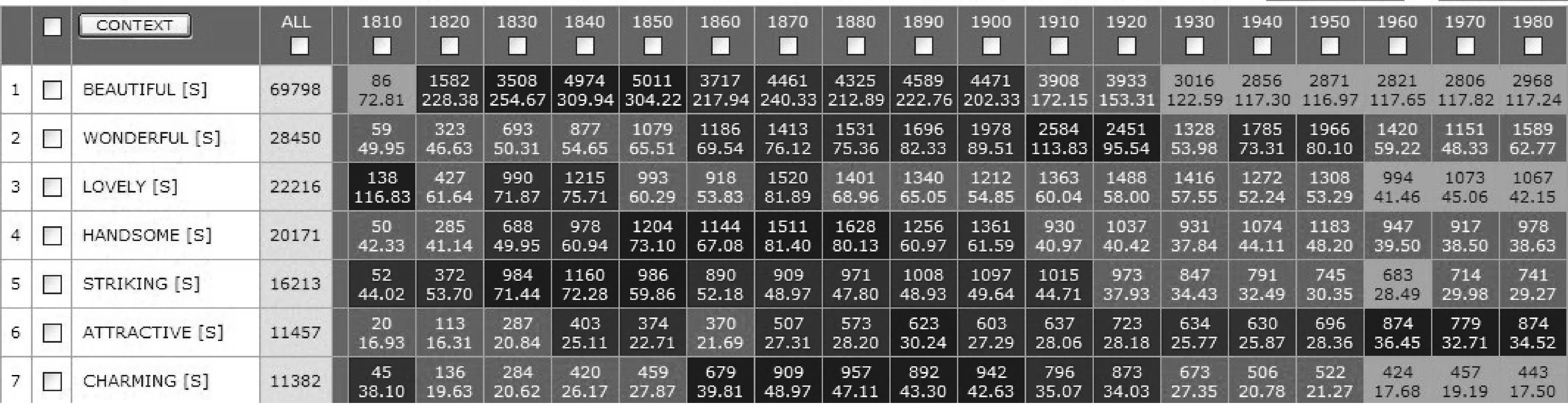
图3 在COHA中输入“[=beautiful]”检索到的beautiful同义词截图(部分)
图3可让COHA的检索者,看到与“beautiful”同义的整个同义语历史变化情况——这些词中,一些词的使用频率随着时间的发展在特定时间增加了,而一些词的使用频率随着时间的发展减少了。从图3我们可以看到:随着时间的发展beautiful在1820s~1980s年使用频率总体上是呈逐渐减少的趋势,由最初1820s的频率每百万词228.38次减少到1980s的117.24次。而作为beautiful的同义词attractive确是随着时间的发展,其使用频率呈逐渐增加的趋势,由1810s的16.93次每百万词增加到1900s年的27.29次,再增加到1980年的34.52次,可见,美语中人们越来越更喜欢用attractive这个beautiful的同义词。图3上的数据信息,对观察不同的词是怎样为各自的“语义空间竞争”的过程非常有用(Davies, 2012:143)。
(五)COHA对社会、文化和历史变化的历史研究
COHA能提供让我们深入观察词语语义历史演变情况的相关检索。如果把COHA这一检索特征扩展到超越纯语言为核心的检索(linguistically orientated retrieves),那以就可以通过检索相关词语语义的变化情况来窥视、了解和认识美国的社会、文化和历史变迁情况。比如,我们可以在COHA的检索入口WORD(S)处输入sex一词,然后在COLLOCATES输入[j*],把SECTION1的时间限定在1810s~1870s,SECTION2的时间限定在1940s~2000s;这样就能检索到这两个时间段与sex搭配的形容词历史变化情况,如表7。
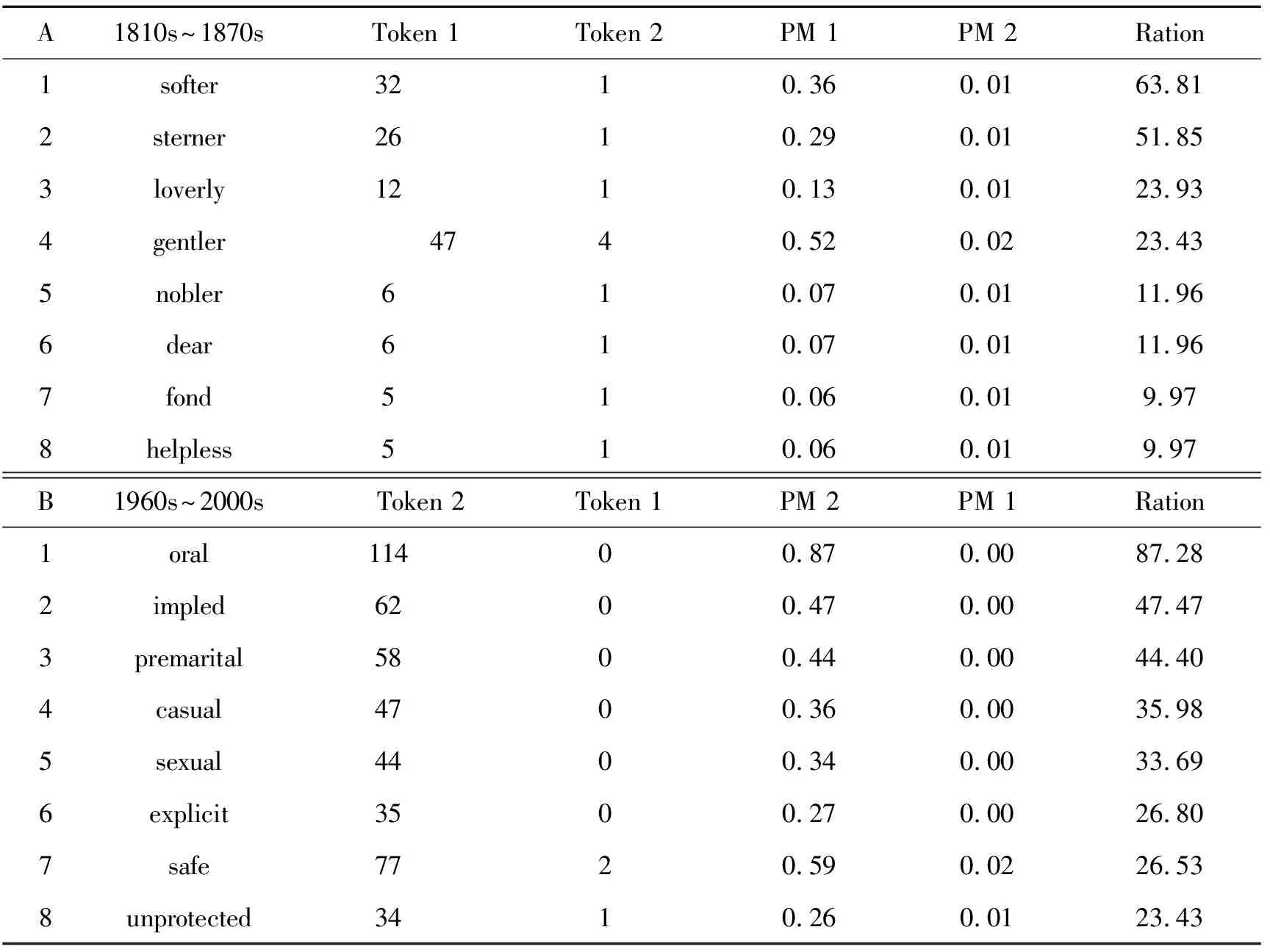
表7 1810s~1870s期间与sex搭配的形容和1840s~2000s期间与sex搭配的形容比较
从表7可见:在1810s~1870s与sex搭配最多最常见的形容是:softer,sterner,nobler,gentle,这些强调“道德”“保守”和“神圣”语义的词语,这反映出当时美国社会的主流意识对“sex”(性)的态度是保守、严格受道德约束和神圣的。而到1960s~2000s时期,特别上世纪60年代,“性解放”在美国风行一时,美国青年男女大都喜欢同居而不结婚,并不断变换同居伙伴。性解放:在性行为上完全抛弃传统道德观念约束的主张和实践。这从表7B部分检索到的与sex搭配的形容主要有:oral(口交的),premarital(婚前的),casual(随意的), unprotected(无保护的),这些与sex搭配的形容词是对美国这一“性解放”时代社会中的国民对性的态度在语言上的反映,通过这些形容我们可以更深的入窥视和认识美国的“性解放”这一社会背景中对性的态度和相关文化。可见,我们可以利用COHA进行与此类似的对相关词语的检索来了解和认识美国社会、文化和历史方面的历史变化,就这方面而言,COHA这大大地拓展了HCL的研究范围和提高了获取相关研究语料的检索速度。
四、结束语
近20多年来,200多年前开创的历史语言学和现代认知语言学逐渐融合诞生了历史认知语言学。历史认知语言学吸收了历史语言学和认知语言学的优势,不但分别推动这两个语言学分支学科的发展,而且使历史认知语言成为目前研究的一个热点。认知语言学日益重视用“基于用法的模式”来研究语言事实背后的理据性,因此认知语言学就有与语料库语言学结合的天然优势,历史认知语言学自然可以而且需要用语料库里的相关语料来观察相关语言现象的历史变化过程和追源历史变化事实背后的理据性。COHA的建成为历史认知语言学研究免费提供了1810s~2000s长达200多年,库容达4亿词的相关历史语料检索,COHA具有独特的语料库架构模式和数据存储模式,极好的篇型平衡性,准确的词类标注,这些保证了COHA能实现对美语从其词汇、形态、句法、语义到文化等方面的历史研究。在文中3.1~3.5部分,我们以具体的实例分别详细说明了COHA在对美语词汇、形态、句法、语义到文化等方面的作用。从这些实例使我们看到COHA极地大拓展了历史认知语言学研究的新视野和为历史认知语言学研究提供了强有力的工具保证。
[参考文献]
[1]Davies, M.The 385+ million word Corpus of Contemporary American English (1990-2008+)[J].InternationalJournalofCorpusLinguistics14:2,2008:159-190.
[2]Davies, M.Expanding horizons in historical linguistics with the 400-million word Corpus of.
[3]Historical American English[J].Corpora, 2012, 7 (2):121-157.
[4]Firth, J.R.PapersinLinguistics1934-1951[C].Oxford: Oxford University Press, 1957.
[5]Taylor, J.The Mental Corpus: how Language is represented in the Mind[M].Oxford: OUP, 2012.
[6]Winters, M.,H.Tissari & K.Allan (eds.).HistoricalCognitiveLinguistics[C].Berlin: Mouton de Gruyter, 2010.
[7]桂诗春.以概率为基础的语言研究[J].外语教学与研究,2004(1):3-8.
[8]徐通锵.历史语言学[M].北京:北京商务印书馆,1991.
[9]王寅.认知语言学和历史语言学的最新发展——历史认知语言学[J].外语教学与研究.2012(6):925-934.
[10]唐健禾.翻译行为的限制性与创造性的文化透视[J].四川理工学报(社会科学版),2012(3):60-64.
猜你喜欢
小学生学习指导(低年级)(2021年4期)2021-07-21
天津外国语大学学报(2021年1期)2021-03-29
天津外国语大学学报(2020年4期)2020-08-24
天津外国语大学学报(2020年1期)2020-03-25
海外华文教育(2016年1期)2017-01-20
湖南工业职业技术学院学报(2016年6期)2016-04-17
语言与翻译(2015年4期)2015-07-18
高中生学习·高三版(2014年3期)2014-04-29
中国科技术语(2012年3期)2012-03-20
