
图解析方式的复合本体映射策略研究
2013-03-07 01:20凌仕勇龚锦红
华东交通大学学报 2013年3期
凌仕勇,龚锦红
(华东交通大学1.软件学院;2.电子与电气工程学院,江西南昌 330013)
本体映射在许多应用领域都起到重要的作用,如模式集成、语义WEB、数据仓库、电子商务、智能体通信、WEB服务组合、目录映射等。很多前期研究往往侧重于本体的概念、属性、实例等特定模式,而忽视本体上下文结构的分析。近来,出现了大量基于英文语料库Wordnet和中文语料库Hownet的词汇相似研究,这些研究语料的词汇相似度计算是构成本体概念相似度计算的基础。但是,对于本体本身的研究主要集中于单纯的概念、属性以及实例,如QOM[1],ASMOM[2],RiMOM[3]。COMA是由德国莱比锡大学开发的一套集本体解析,匹配,测试和评估的开源映射系统(http://sourceforge.net/projects/coma-ce/),COMA解析各种格式输入文件(XML,RDF,OWL)成一种内部结构,通过这种结构与匹配算法,输入输出,数据库(默认mysql,可以自定义算法接入系统接口)进行交互。提供一套工作流用于定义输入文本的格式,匹配算法,相似度计算的算法(外部接口库align-4.2-ontowrap.jar),输出文件的格式(xm l,htm l)。新版COMA++[4]支持不同的输入如XMLSchema,RDF,OWL,引入了概念间的关系,但本身没有引入基于语料库的词汇计算,不支持本体结构的相似度传播,并且在映射时为了顾及一般化的多对多映射而采用单向或双向完全遍历的方法,使得复杂度大为增加。S-Match[5]是由意大利特伦托大学Fausto Giunchiglia教授主持开发的一套开源语义映射算法(http://sourceforge.net/apps/trac/s-match/wiki/),S-Match将待映射的两个文件解析成树形结构,然后计算两个树节点之间的语义关系,进而找出映射关系。其语义计算分2个步骤:首先解析两树的标签属性,类似于本体的概念名称,通过元素级别的匹配库计算标签概念的语义关系;其次解析两树的节点,类似于本体的概念属性,通过节点级别的匹配库计算节点间的语义关系。其词汇计算的核心是通过WordNet词汇库进行语义相似度的计算。S-Match充分考虑了语义库的支持和计算方法,但对应本体结构和映射策略并没有给予过多的支持。
对于输入模式的解析上,除了需要考虑本体的概念,属性外,还需要考虑本体之间的上下文结构关系,本体所拥有的实例。本文将本体或其它的输入模式解析成一种图描述的结构,这种结构不依赖于任何特定的语义,可以接受其它类型的输入模式如XML,文本结构,数据库模式等等。并从3个层次上对输入进行描述:节点层次上的图定位,用于解析图的顶点描述;概念关系层次上的结构图分析,用于解析图的边描述;语义上的结构图比较,用于节点的概念相似度计算。
对于本体结构的分析,本文从概念结构和概念所拥有的实例两个级别引入了相似度传播,将相似度通过结构算法传递到邻近节点,提高了系统识别的准确度。并通过引入HopcroftKarp算法对二分图进行快速匹配达到本体快速映射的目的。最后结合输入模式的多层解析,设计重用基础上的复合映射策略,构建迭代本体映射系统,用于快速准确的对本体进行映射。
对于映射系统,一般从效率和效能上进行分析。从效率上,主要考虑时空复杂度,从效能上,则是考虑系统对本体映射的评估效果。本文通过引入快速匹配算法,降低了映射的算法复杂度;通过多层关系结构的复合映射,提高了映射的评估效果。最后通过算法复杂度的分析和一些对比测试证明了这一点。
1 基于解析图的复合本体映射
首先将输入模式从3个层次角度解析成图描述结构:节点层次上的图定位,概念关系层次上的结构图分析,语义层次上的结构图比较。从概念结构和实例两个级别引入了相似度传播,将相似度通过结构算法传递到邻近节点。引入HopcroftKarp算法对二分图进行快速匹配达到本体快速映射。最后,设计复合映射策略,在兼顾系统性能基础上对本体进行高质量映射。
1.1 本体图解析
在考虑节点的基本概念特征基础上,将本体中的概念表示成图的节点,概念间的关系表示成图的边。并对本体解析图的图概念进行拓展,将节点对象属性,节点数据属性、节点的实例特征以及它们之间的结构关系嵌入到图中的顶点和边。这样拓展后的本体解析图中的节点分为两个部分,第一部分为节点元素的内容特征,包括元素的名称,数据类型,注释,实例特征等。第二部分为节点元素的结构特征,包括节点的邻居节点如子孙节点、叶子节点、双亲节点、兄弟节点、后代节点、前辈节点等等。前一部分关注节点的静态信息,用于节点信息的匹配;后一部分关注节点的动态信息,用于上下文结构关系的分析。例如,针对图1中的节点2,得到如表1所示的结果集合。
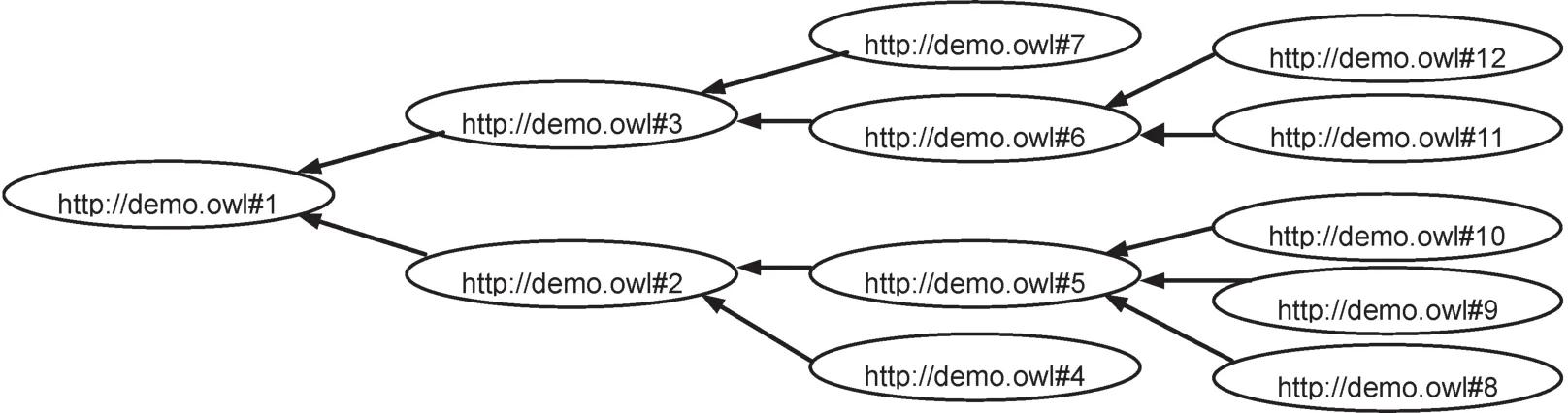
图1 本体概念图Fig.1 Ontology conceptgraph

表1 本体图解析结构Tab.1 Parsing structureofontology graph
1.2 相似度传播
相似度传播的核心思想是,基于概念特征的父类或子类的相似度会传播到概念本身,进而在一定程度影响概念本身的相似程度。文献[6]提出了Simialrity Flooding算法,对概念的邻居节点进行传播,给出一个固定比例的相似度传播值。GMO[7]则考虑全局的相似度传播。两者都没有考虑概念间传播度的差异性,如图1中的节点1和节点5,节点1的概念空间比节点5大,所以对于节点1的子类相似的可能性要远小于节点5的子类相似的可能性,所以不同概念的相似度传播是有差异的。本文采用文献[8]提出的语义传播因子SF的方法,由定义1的语义传播因子SF所示,C(c)为节点c的子节点集合,P(c)为节点c的父节点集合。当节点对的父节点对的信息量越大,节点对匹配的可能性越大,其相似度传播因子也越大;当节点对的子节点对的信息量越小,节点对匹配的可能性越大,其相似度传播因子也越大。
定义1 语义传播因子SF
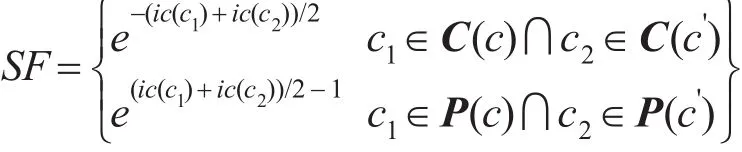
另外,考虑到概念图中的节点,一般来说,概念的实例主要集中在叶子节点,非叶节点很少拥有大量的实例,所以在拥有大量实例的本体中,可以通过对概念实例的评估来增强概念相似度匹配的准确性。应用到相似度传播中,采用“向上传播”的方法[4],将概念实例相似度从叶子节点传播到父节点。如定义2所示,利用e1所有实例的相似度最大值和e2所有实例的相似度最大值来计算实例相似度传播值,其中n和m分别为e1和e2实例的个数。
定义2 实例相似度传播
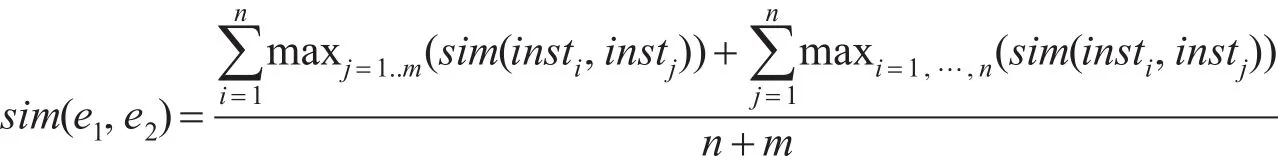
1.3 快速稳定匹配
在COMA[9]中,采用Selection算子对模式S1和S2匹配的结果集进行单向LargeSmall(|S1|>|S2|),单向SmallLarge(|S1|≤|S2|)或双向选择(Both)。对于Selection算子的选择策略,提供了选择最大N个记录的MaxN操作,选择最大几率的MaxDelta操作和阀值Threshold的操作。这些策略都需要对模式S1和S2进行遍历,其算法复杂度为ri(单向),或2ri(双向)。
本体1:1映射实际上可以看作是对二分图的最大匹配[10-11],二分图指的是这样一种图:其所有的顶点分成两个集合M和N,其中M或N中任意两个在同一集合中的点都不相连。二分图匹配是指求出一组边,其中的顶点分别在两个集合中,并且任意两条边都没有相同的顶点,这组边叫做二分图的匹配,而所能得到的最大的边的个数,叫做最大匹配。为了解决二分图的最大匹配,采用HopcroftKarp[12]算法。在增加匹配集合M时,每次寻找多条增广路,这样迭代次数最多为2V0.5,所以,时间复杂度就降到了O(V0.5×E),V为解析图顶点数;E为解析图边数。
二分图匹配本质上一种稳定匹配,在后面的迭代映射算法中的收敛条件中,采用稳定匹配均值作为迭代收敛条件。例如,有概念Old1,Old2,New1,New2,sim(Old1,New1)=0.9,sim(Old1,New2)=0.8,sim(Old2,New1)=0.6,sim(Old2,New2)=0.2,按稳定匹配算法,有匹配[Old1,New1],[Old2,New2],其匹配值为0.9+0.2=1.1,而非稳定匹配[Old1,New2],[Old2,New1]的匹配值0.8+0.6=1.4。尽管后者匹配值大,但前者是稳定匹配。
1.4 复合映射策略
1.4.1 复合映射路径
基于前述的本体图解析,从3个层次和两个特征对异构本体进行映射分析。对于给定的本体,首先根据本体各节点元素及其上下文结构关系构建顶点和边,进而构建本体解析图;根据一定的策略注入本体的节点元素,对各节点元素进行遍历,得到节点的上下文关系,即图的结构特征;然后依据节点内容特征和相似度传播特征对各节点元素进行相似度的计算;最后是建立基于重用思想上的迭代映射。
1.4.2 复合映射框架
如图2所示,Matcher是最底层的匹配,采用基于词汇路径距离和基于wordnet的语义相似度的叠加值,完成节点内容特征层次上的相似度计算。MultiMatcher是多个Matcher的聚合,MultiMatcher基于某个节点进行遍历,针对遍历后的节点内容特征进行相似度计算,完成结构层次上的概念计算。Strategy是多个MultiMatcher的聚合,对解析图节点进行树遍历,基于多个MultiMatcher完成某个策略的映射。最终,多个MultiMatcher和多个Matcher共同完成本体解析图的结构特征和内容特征的多级映射策略,IterStrategy基于集合的交,并,差重用思想,对多个策略进行稳定匹配迭代映射。

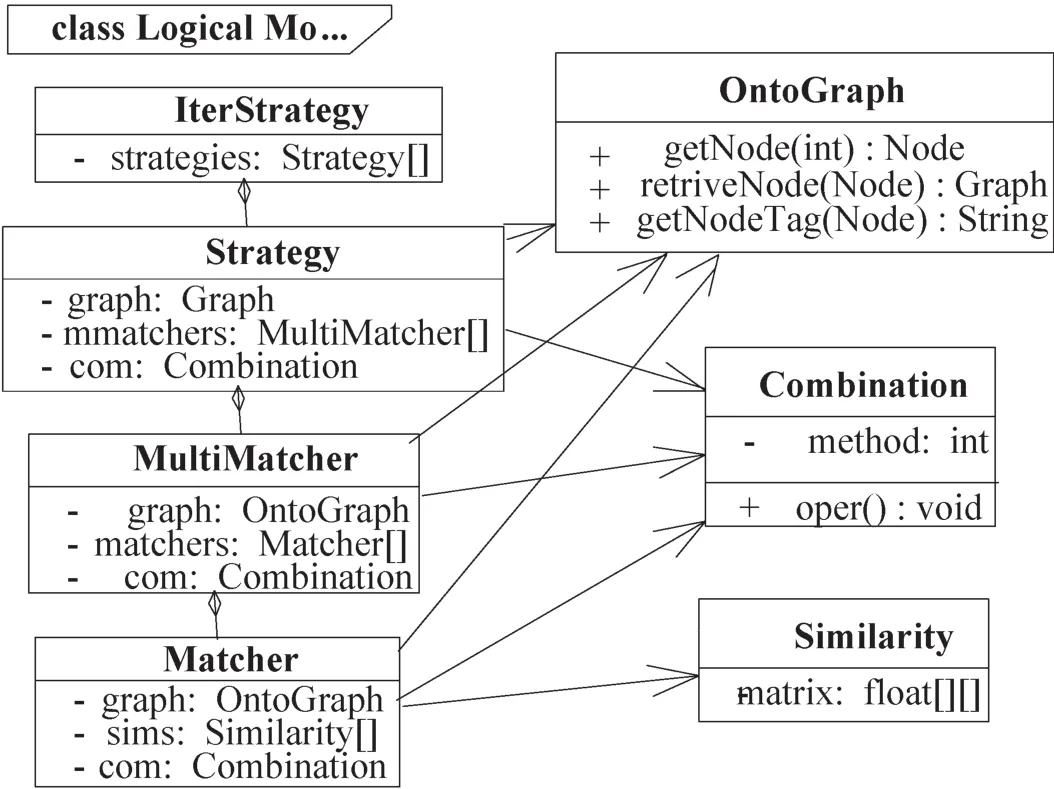
图2 复合映射策略Fig.2 Com positemapping strategy
1.4.3 结果重用
在策略迭代IterStrategy中,我们引入了重用算子∩一∪,分别代表集合的交,差,并操作,用于迭代映射的结果集重用。∩操作intersect返回两个不同结果集的共同映射对。一操作Diff返回映射对出现在一个结果集而没有出现在另外一个结果集中。∪操作Union则合并两个结果集的映射对。
1.4.4 收敛条件
对于每一种复合策略的映射,都可以得到一个映射结果集合。考虑到映射算法本身属于二分图匹配的稳定算法,故将两次映射结果集合中的相似度均值误差作为迭代收敛条件。
2 复杂度分析
整个映射系统包括本体解析图构建,多个Strategy,每个Strategy包括多个MultiMatcher,以及每个Mulit⁃Matcher包括多个Matcher。在此定义:整个映射系统复杂度cis,本体解析图构建复杂度cg;Strategy复杂度cs,MultiMatcher复杂度cmm,Matcher复杂度cm,以及结果集的合并操作复杂度cc,相似度计算复杂度cs和结果集匹配复杂度ch。
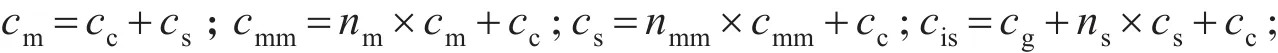
其中:nm,nmm,ns分别表示为每个MultiMatcher包括的Matcher个数,每个Strategy包括的MultiMatcher个数,整个系统包括的Strategy个数。故有:cis=cg+ns×{nmm×[(nm×(cc+cs)+cc)]}+cc+ch。
对于本体图的解析,采用对图进行树遍历的方法,故本体图解析的复杂度为树的遍历复杂度O(nlog(n))。基于字符串距离的依赖于字符串的长度l,为O(l)。而基于wordnet的语义距离则是基于语义词典,其计算复杂度为O(1)。在计算相似度传播时,考虑到传播的深度带来的复杂性,一般只考虑节点的直接父节点,直接子节点和直接兄弟节点。故复杂度为这些节点集合的计算复杂度,设节点集合大小为s,结构相似度的计算复杂度为O(s2)。Hopcroft Karp快速匹配算法的复杂度为O(V^0.5 E),合并操作实际是集合的操作,故为O(s2)。
综合以上,系统复杂度
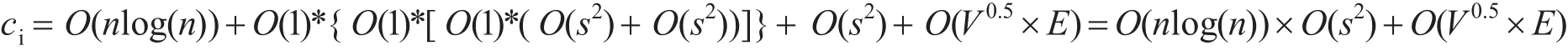
考虑到一般结构集大小s一般远小于节点数,故系统复杂度为O(nlog(n))+O(V0.5×E)。相对于一般系统如GLUE系统的复杂度O(n2),系统运行复杂度大大降低,其主要原因在于首先采用了基于树的解析图结构,而不是对本体概念的遍历(其复杂度为O(n2);其次采用了快速匹配算法HopcroftKarp,将算法复杂度将为O(V0.5×E);最后,尽管经过了多次迭代和多种策略,但正是由于应用了多种策略,使得迭代相当少就可以达到很好的精度。
3 测试分析
本系统分为系统性能对比测试和实验评估。系统性能考虑对两个本体映射的解析特征结构,映射对个数以及映射时间进行比较,并在同一型号PC机和主流系统进行对比。实验评估考虑的是对本体映射的质量进行比较。
3.1 系统性能测试
系统性能测试将采用OAEI2010[13]作为测试集,其中101#为基准集,分别选用103#,203#,224#,233#,246#,265#,301#为测试集。表2给出了一部分测试结果,包括本体的类,对象属性,数据属性以及实例个数、构建解析图后的顶点和边的个数、以及测试集相对于基准集的映射时间。相对来说,由概念及概念间关系解析出的顶点和边数越少,解析时间越少,相应映射时间也少。233#解析后的边数为0说明概念间没有任何相对关系如继承关系,ISA关系,属性关系等等,概念为孤立的节点。
另外,本系统和另外两个映射系统COMA[9],S-Match[5]进行映射时间对比,从对比可以看出,本系统在性能上得到一定的提升。
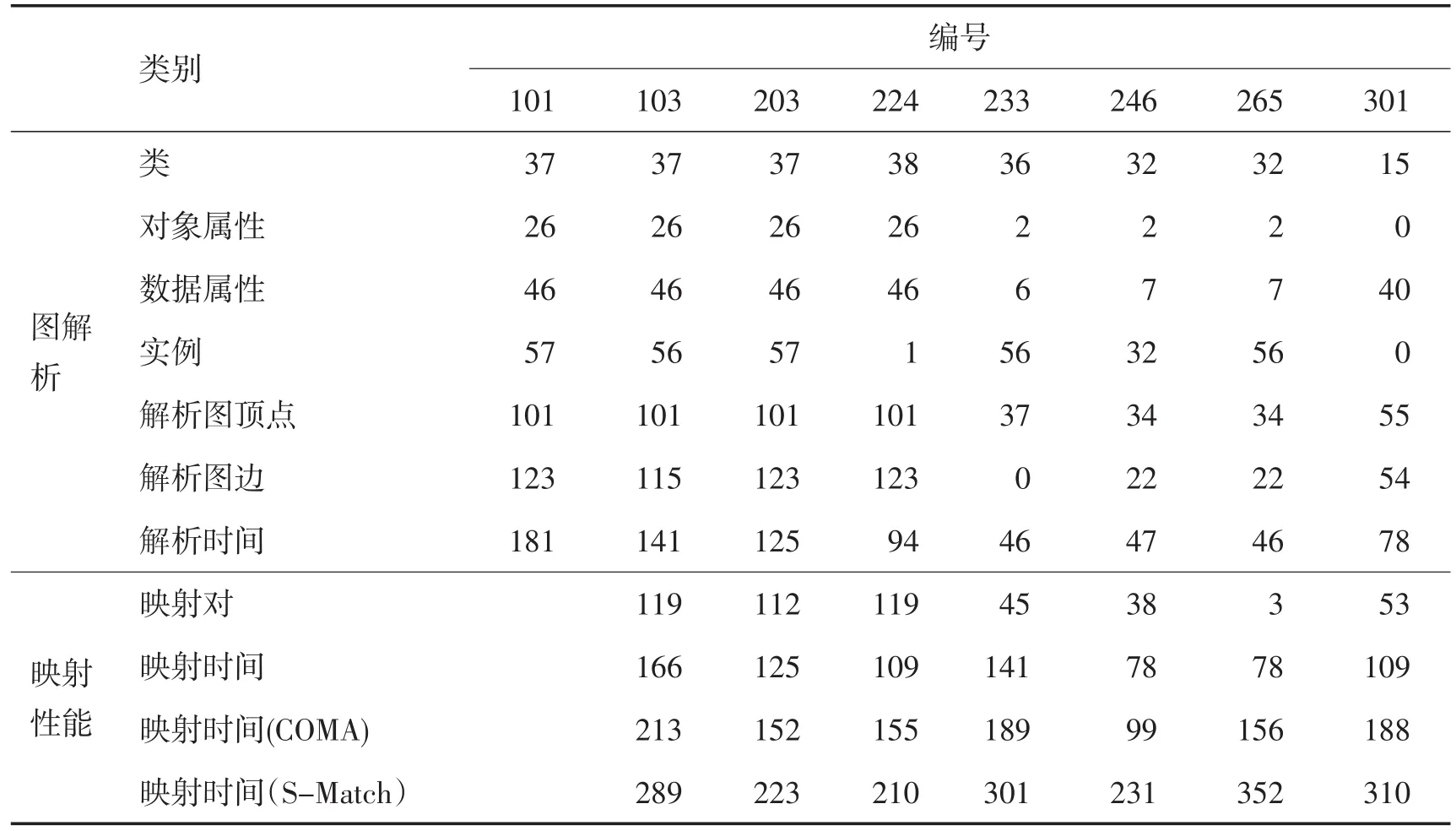
表2 本体图解析和映射性能Tab.2 Ontology graph parsing andmapping performance
3.2 实验评估测试
实验评估采用OAEI2010作为测试集,从编号101到304共50个数据集。F-Measure=(b2+1)PR/(b2P+R)[14],设当b=1 时,F-Measure=2PR/(P+R)作为评估指标。其中:P为查准率Precision=发现的正确映射数/发现映射数;R为查全率或称召回率Recall=发现的正确映射数/实际存在的映射数[15];F-Measure指标综合了信息检索中的准确率和召回率。图3比较了F-Measure在本文的测试系统IOMBF(iterative ontologymapping based figure),COMA++以及S-Match的曲线图,可以看出,本文的测试效果优于COMA++,与S-Match不相上下。
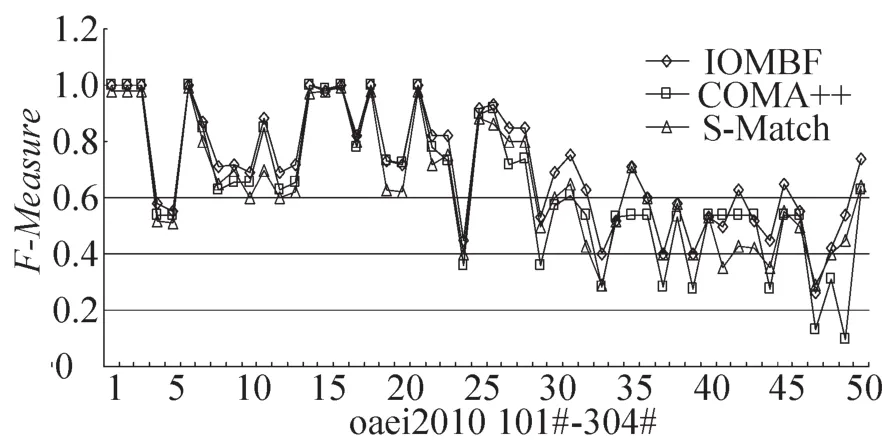
图3 F-Measure实验比较Fig.3 F-measure experiment com parison
4 结束语
本文通过对本体映射的分析,构建了一种基于多层解析的图描述结构,并在此基础上通过分析本体上下文结构,引入结构和实例相似度传播和快速匹配算法,设计一种复合匹配策略,用于本体映射。算法分析和实验证明,本系统能在保证性能基础上提高一定映射的质量。本文侧重于充分挖掘本体本身的内在结构,进而提出了相应的策略,对于不同的复合策略,将影响迭代算法的收敛次数,进而影响映射性能映射效果,因此,对于复合策略的研究有待于做进一步的工作。
[1]EHRIGM,STAABS.Quick ontologymapping[C]//Rome Proc of the ISWC‘04,Italy:Proc of VLDB’01,2004:683-697.
[2]YVESR,MANSUR R.ASMOV results for OAEI 2007[C]//Bexco Proc of the ISWC'07,Korea:Morgan Kaufmann Publishers,2007:141-151.
[3]唐杰,梁邦勇,李涓子,等.语义Web中的本体自动映射[J].计算机学报,2006,29(11):1956-1976.
[4] DENGLLLAN N,SMASSMAN N.Instancematching w ith COMA++[J].Model Managementand Metadaten-Verwaltung,2007,35(7):56-63.
[5] GIUNCHIGLIA F,SHVAIKO P,YATSKEVICH M.S-match:an algorithm and an implementation of semanticmatching[J].Proceeding of ESWS,2004,23(5):61-75.
[6] DONG X,HALEVY A,MADHAVAN J.Reference reconciliation in complex information spaces[C]//Tomah in Proc of the 2005ACM SIGMOD IntConference on Managementof Data,New York :ACM Press,2005:85-96.
[7]Muhlenbein H,Mahnig T.Convergence theory and application of the factorized distribution algorithm[J].Journalof Computing and Information Technology,1999,7(1):19-32.
[8]李熙,徐德智,王建新.本体映射中结构策略改进算法[J].计算机工程与应用,2010,46(8):24-28.
[9] HH DO,RAHM E.COMA-a system for flexible combination of schemamatching approaches[J].in Proceedingsof VLDB,2001,62(2):610-621.
[10] GUSFIELD D,IRVING RW.The stablemarriage problem:structure and algorithms[J].M IT Press Cambridge,1989,10(3):23-35.
[11]LOVASZ L.Matching theory[D].New York:Elsevier Science Ltd,1996:233-235.
[12] Blum N.A simplified realization of the hopocroftkarp approach tomaximum matching in genenalgraphs[J].Inst fur Infromatik on Computing,1999,2(4):225-231.
[13]宋岚,雷莉霞,王洪.基于本体的智能化语义信息处理系统研究[J].华东交通大学学报,2009,10(5):31-34.
[14] CJVAN RIJSBERGEN.Information retrieval[D].2nd edition.Glasgow:Dept.of Computer Science University of Glasgow,1999:98-105.
[15] HDOSM,E.Comparison of schemamatching evaluations[J].workshop onWeb Databases,2002,6(1):12-18.
猜你喜欢
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
制造业自动化(2017年2期)2017-03-20
文学教育(2016年27期)2016-02-28
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
