
先秦汉语排比句自动识别研究
——以《孟子》《论语》中的排比句自动识别为例
2013-02-22 08:18梁社会陈小荷
计算机工程与应用 2013年19期
梁社会,陈小荷,刘 浏
1.南京师范大学 国际文化教育学院,南京210097
2.南京师范大学 文学院,南京210097
1 引言
作为儒家经典的《孟子》,能广为流传,在一定程度上来说和它大量使用修辞格是有关的。据研究,《孟子》中出现较多、较为典型的修辞格有比喻、对偶、排比、对比、夸张、引用、反复等[1-6]。
《孟子》是一部政论性的著作[7],它很突出的一个特点是论述性的语言占有很大篇幅,而排比句是其中最具有特色的一类句型。《孟子》中很多重要的论述都是通过排比句的形式表达的。
通过排比来说明道理,显得条理清晰,而且气势宏大,有说服力,使得孟子能更有力地向梁惠王等人阐述自己的政治主张。《孟子》中类似的使用排比句表达自己政治意见的语句有许多,摘录这些排比句并做专门研究,可以从一个新的角度去理解和学习《孟子》中的有关内容。
现在,关于修辞格自动识别的文献还不多见,其中,关于《孟子》中的修辞格和《孟子》中排比句自动识别的文献还暂没看到。本文研究旨在探讨通过计算机来自动获取《孟子》中的排比句,这样不仅可以提供一个《孟子》排比句的可信数据库,而且在处理其他体裁相同或相似文本时,也能够提供一种有效的自动获取排比句的方法,为以后更多的修辞格的自动识别提供参考。
2 排比句自动识别的算法设计
如前所述,目前针对《孟子》或其他先秦文献的排比句的自动识别或获取的相关研究还没有看到,现代汉语方面的相关研究也不多见。因此考虑自行设计一种有效的算法来获取《孟子》中的排比句,并将在其他相关的先秦文献中进行测试实验,以检验该算法的可靠性和效率。
《孟子》全书总字数约为三万五千字[8]。这个字数表明《孟子》规模较小,不适合使用统计的方法,因此,将采用规则的方法来自动识别排比句。
2.1 “断句”的分类
排比句中“句”的边界并不严格,分隔排比句各个子句的标点符号可能是逗号、分号或者是句号(这里所谓的句号包含问号和感叹号)。这几种标点所分隔的子句长度,一般而言是从逗号到分号到句号依次递增的,但是各个子句之间的长度一般是相当的,因此不影响对由这几种标点分隔的子句采用同一种算法从中查找排比句。
为了保证查找的完整和准确,首先将经过分词和词性标注处理并经过人工校对后的《孟子》语料进行自动断句处理,断句的标准分为3 种,分别是对逗号、分号、句号断句,对逗号、分号断句和只对句号断句。将从3 种标准断句后得到的语料中,分别查找其中的排比句,最后合并得到的便是《孟子》中所查找到的全部排比句。
2.2 排比句识别的算法
一般认为,排比是一种修辞手法,利用3 个或3 个以上意义相关或相近,结构相同或相似,语气相同的词组或句子并列排在一起,用以达到加强语势的效果[9]。
于志忠[10]认为,用排比来说理,可收到条理分明的效果;用排比来抒情,节奏和谐,显得感情洋溢……总之,排比的行文琅琅上口,有极强的说服力,能增强文章的表达效果。
概括起来,排比句的特征一般有以下3 点:
(1)各子句相连;
(2)结构相同或类似;
(3)各子句中部分词语重复。
本文考虑从排比句所具有的这3 种特征分别入手,来设计查找排比句的算法。
2.2.1 最长公共子序列的求解
由于排比句自动识别算法中需要用到最长公共子序列,因此先简单介绍一下最长公共子序列的求解。最长公共子序列的求解目前已有许多成熟高效的算法,其中最有效的是动态规划算法[11]。动态规划算法的思想是将待求解问题分解成若干子问题,通过自底向上地解决子问题来最终获得所求问题的最优解。由于将已解决的子问题的结果保存下来,这样就能够在再次遇到这些问题时避免重复计算,节约了大量的时间,提高了算法的效率。
动态规划算法一般有以下4 个步骤[12]:找出最优解的性质,并描述其结构特征;递归地定义最优值;以自底向上的方式计算出最优值;根据计算最优值时得到的信息,构造最优解。
由于用动态规划算法求最长公共子序列只是实验中一个较小的部分,这里不再赘述。
2.2.2 相连
排比句中的各个子句是前后相连的,因此须按顺序依次查找各子句。根据已有的断句语料,设计了一种简单的遍历算法。
算法1排比句的遍历识别
i=0,j=0,P=null;
while(i+2 <resource.num){
if(P==null)P=Si+Si+1+Si+2;
elseP=P+Si;
if(functionP(Si,Si+1)!=null||functionP(Si,Si+2)!=null)i++ ;
elseResult=P,P=null,j++,i++ ;return result;
}
根据算法1,遍历3 种标准得到的语料合并后,即可自动获得需要的排比句。算法1 是进行排比句自动识别的核心算法。算法1 中包含有一个重要的子算法P(X,Y),用以判断子句X、Y能否构成排比句的一部分,也就是说子句X和Y能否达到一定的相似程度,以满足这两个子句有可能是某一个排比句的一部分,该子算法请参见算法4。算法4 的实现,即运用到了排比句另外两个重要的性质,结构类似和部分词语重复。
2.2.3 结构类似
结构类似说明排比句中各个子句在结构上具有相同或相近的结构关系,在无法对《孟子》全文做完全的句法结构分析的前提下,只能将句子结构的类似简化为句子词性序列的类似。词性序列也就是句子中每个词的词性依次排列构成的一组序列,通过比较两个子句词性序列的相似程度来替代比较两个子句的词语结构的相似程度,这可以大大简化算法的复杂程度,并提高算法的效率。以下是结构类似性算法的具体描述。
算法2结构类似性的计算
i=0,Score=0,POSi[t],POSj[n];
m=functionM(X,Y);
while(i<m.length){
if (t-POSi.Indexof(m.substr(i,1))<4&&n-
POSj.Indexof(m.substr(i,1))<4){
Score=Score+1;i++;
}
算法2 中有以下几点值得注意:
算法最终得到一个Score评分,Score评分是用数值表示的两个串S1、S2结构相似性的程度,这个值将用于算法1中P(X,Y)的求解,见算法4;M(X,Y)便是上文介绍的用动态规划算法求解两串X、Y的最长公共子序列;第四步中用于判断的距离,是距串尾而不是串首的距离。其原因是在大部分的排比句中,子句靠右的部分(也就是靠近串尾的部分)相似程度要大于靠左的部分(也就是靠近串首的部分);第五步针对的是较长的词性串,长度较大的词性串之间的最长公共子串容易偏大,如果在此基础上训练算法,将会忽略掉大多数长度较小的词性串,这是不希望看到的。因此对长度之和大于60 的情况进行评分的削减,以平衡长串和短串之间的差异。
2.2.4 部分词语重复
结构类似是从词性的角度模拟排比句结构类似的特征,部分词语重复的特征则可以直接通过字符序列的比较来得到检验。以下是有关部分词语重复程度计算算法的描述:
算法3部分词语重复程度的计算
i=0,Score=0,Chari[t],Charj[n];
m=functionM(X,Y);
if(m.contain(”,”)||m.contain(”;”))
Score=Score+1;
else if(m.contain(”,”)||m.contain(”。”))
Score=Score+1;
while(i<m.length){
if(t-POSi.Indexof(m.substr(i,1))<4&&n-POSj.Indexof(m.substr(i,1))<4){
Score=Score+1;i++;
}
returnm-n>60:score=score-10?score;
算法3 与算法2 非常相似(实际上,算法2 是从子句词性串的角度入手,而算法3 是从子句字串的角度入手)。有一点特殊的就是,字串中包含标点,因此,第三步的m中若同时包含逗号和分号,或同时包含逗号和句号,那么S1、S2结构相似的程度就会大一些,因此对score评分加1。
2.2.5 排比句的识别
上面介绍的算法1 中,有个重要的子算法P(X,Y)用以判断子句X、Y能够构成一个排比句的一部分,以下是这个算法的具体实现:
算法4P(S1,S2)判断S1、S2能否构造一个排比句
score1=functionS(S1,S2),score2=functionW(S1,S2);
L1=S1.Length,L2=S2.Length;
if (L1<15||L2<15) return false;
if (L1>2*L2||L2>2*L1) return false;
if (S1.findlastof(“。!?”)==S1.Length-1 &&
S2.findlastof(“,;”)==S2.Length-1) return false;
if (score1*P1+score2*P2>=P3) return true;
算法4 中,第四步到第六步均是可以排除S1、S2构成排比句可能性的特殊情况。通过调节P1、P2、P3参数,可以调整判断S1、S2能否构造一个排比句的标准,以调整最终识别获取排比句的正确率和召回率。通过以上几种算法的结合,就可以实现一个完整的用以识别《孟子》中所有排比句的算法。
算法5《孟子》排比句的自动识别
P1=0.1,P2=0.1,P3=0.2,R=0;
While(Read(file)){
functionFirst(file.lines);}
Calculate(p,r,f);
if (r>R)R=r;
if (P2<1){P2=P2+0.1,FuntionFive(P2);}
elseP2=0.1;
if (P1<1){P1=P1+0.1,FuntionFive(P1);}
elseP1=0.1,P2=0.1;
if (P3<1){P3=P3+0.1,FuntionFive(P3);}
else Output(parallelism sentences);
算法5 是对之前几种算法的整合,并且对几个参数进行了遍历,以寻找出最优的排比句识别效果。由于该算法较多地注重了召回率,所以找到的结果正确率稍低了一些。为改进这种情况,在算法5 之后又增加了一个过滤查找结果的过程。
根据排比句的特点,并仔细分析研究了自动识别结果中错误的句子,归纳、整理了以下7 条规则:
(1)如果某结果中有两个句号、一个问号,则该结果不算排比句,删除之。
(2)如果某结果中有两个句号、一个分号,则该结果不算排比句,删除之。
(3)如果某结果中只有两个句号,也就是说,如果该结果只有两句话,则该结果不算排比句,删除之。
(4)如果某结果中有一个句号、两个问号,则该结果不算排比句,删除之。
(5)如果某结果中有前后两个分号,中间一句为句号,则该结果不算排比句,删除之。
(6)如果该结果只有一句话(以句号、问号或感叹句结尾的为一句话),且前面的分句以逗号或分号结尾,最后一个标点为问号的,则该结果不算排比句,删除之。
(7)如果某结果中只有逗号,没有别的句号或问号,则该结果不算排比句,删除之。
根据这些规则对算法5 找到的排比句进行筛选之后,就基本解决了正确率稍低的问题。
3 实验及结果分析
3.1 人工标注结果
在《孟子》分词和词性标注的基础上,花费了较多的精力进行了排比句的人工标注,来作为排比句自动获取实验的标准答案。
经过人工标注后的《孟子》各篇的排比句共有74 个,分布情况如表1 所示。从这些数据可以看出,排比句的分布并不是很均匀,排比句最多的一篇比最少的要多出4 倍。
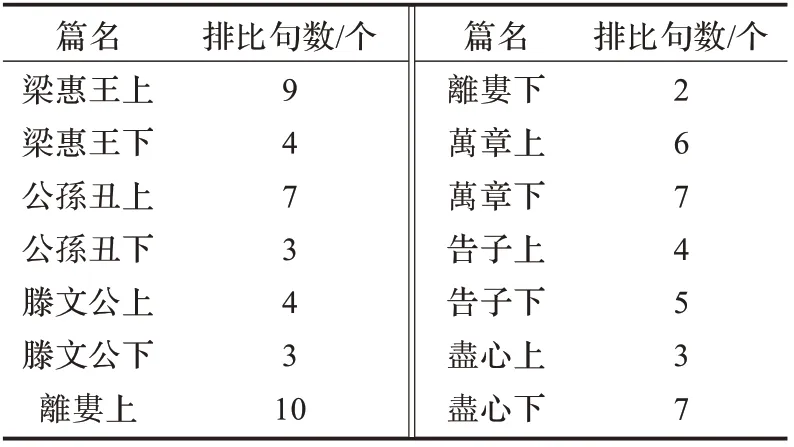
表1 《孟子》排比句分布情况
3.2 《孟子》排比句自动识别结果及分析
将《孟子》共14 篇文本按6∶4∶4 的比例分成训练集、开发集和测试集,分别进行封闭测试和开放测试。其中,训练集各篇分别为:梁惠王上、梁惠王下、公孙丑上、公孙丑下、滕文公上、滕文公下;开发集的各篇分别为:离娄上、离娄下、万章上、万章下;测试集的各篇分别为:告子上、告子下、尽心上、尽心下。
根据算法5 的参数调试以及排比句结果筛选规则的筛选,得到了比较理想的排比句实验结果。实验得到的最优参数分别为:P1=0.1,P2=0.1,P3=0.5,最优结果的具体性能详见表2、表3、表4。
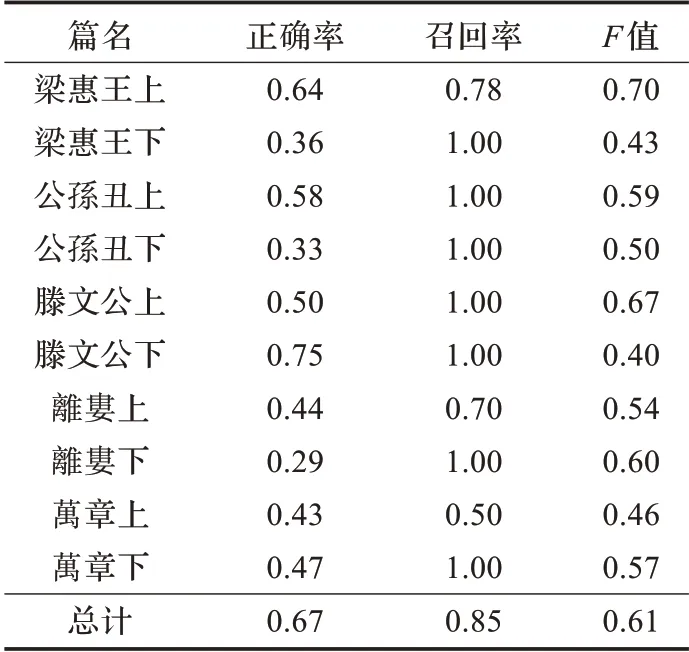
表2 《孟子》排比句自动识别封闭测试结果

表3 《孟子》排比句自动识别开放测试结果

表4 《孟子》排比句自动识别封闭、开放测试结果比较
根据以上各表中得到的统计结果可以发现,《孟子》排比句识别的召回率总体来说还是很高的,大部分章节甚至达到了百分之百。正确率尽管经过规则筛选,但仍难以达到更好的性能,原因可能有以下几点:
首先,篇幅限制。《孟子》中人工标注的答案一共只有74处,自动识别的排比句一共也只有127处,规模过小,统计意义上容易产生较大的误差,比如《萬章上》一共只有6处排比句,找到了3 处,召回率就只有0.5 了,正确率也会比较低。
其次,算法限制。本文算法主要基于排比句形式上的特点,并主要根据标点符号的规则加以筛选,这样有可能会产生一些问题。一个是有些排比句各子句虽然形式上关联程度不大,但意义上联系十分紧密,如《離婁上》中有一句排比如下:
得天下有道:得其民,斯得天下矣;
得其民有道:得其心,斯得民矣;
得其心有道:所欲與之聚之,所惡勿施,爾也。
其中第三个子句与前两个子句在形式上的差别是远大于相似之处的。因此,希望仅通过建立形式规则算法,是难以有效找全或找到这类排比句的。
另外,语料本身可能的错误也会造成结果的偏差,如《萬章上》有如下一个排比句:
天下之士悅之,人之所欲也,而不足以解憂;
好色、人之所欲,妻帝之二女,而不足以解憂,
富、人之所欲,富有天下,而不足以解憂;
貴、人之所欲,貴為天子,而不足以解憂。
通过观察可以发现第二个子句的句末标点是逗号,与第一和第三个子句不同,根据本文算法,这种情况将被排除在排比句之外。当然通过修改这类错误,提高语料的质量可以有效改进这类错误造成的性能损失,但这也体现了本文方法对语料形式的依赖性较大。
当然,《孟子》中各个小句之间形式上非常相似,各小句的字数不太多且相差不大,干扰性较大,也是造成识别正确率相对较低的原因之一。
尽管识别结果尚有一些不太完善的地方,但提出的方法已经很有效地做到了对《孟子》中排比句的自动识别,对先秦文献排比句的自动识别进行了积极的探索。
3.3 《论语》排比句自动识别结果及分析
为了测试该方法在其他类似文本中的通用性,又选取了先秦文献《论语》[13],使用同样的方法进行了排比句的识别实验。值得注意的是,《论语》训练并遍历参数后,最终得到的最优参数依然是:P1=0.1,P2=0.1,P3=0.5,具体性能见表5。

表5 《论语》排比句自动识别结果
《论语》中人工标注的排比句答案共有42 个,其中《论语》有4 篇是没有人工标注的排比句答案的,也就是说,暂时认为这4 篇中是没有符合所界定的排比句的。这4 篇分别为:里仁、先进、微子、子张,在表5 中,它们的正确率、召回率和F值显示的均为0。
观察可以发现,《论语》排比句自动识别的效果稍微好于《孟子》中排比句的识别效果,这里认为可能是以下原因造成的:
(1)《论语》中的句子长度相比较《孟子》而言,不是很长,也比较适合查找。《孟子》全篇的平均句子句长为21.8,平均小句句长为7.0,《论语》全篇的平均句子句长为11.4,平均小句句长为5.2。《孟子》、《论语》中具体各篇的平均句子长度和平均小句句长统计数据请见表6、表7。从表中可以看出,无论是平均句长,还是平均小句句长,《孟子》中的统计数据都远高于《论语》中的统计数据,这在一定程度上为《孟子》的排比句自动识别增加了难度。
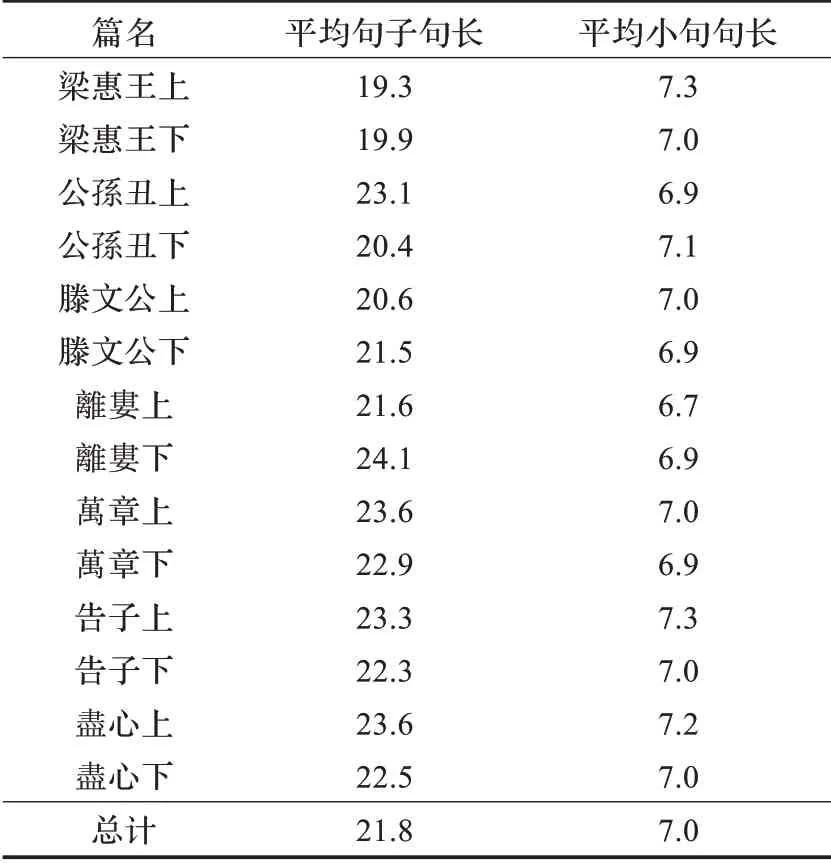
表6 《孟子》各篇平均句长、平均小句句长统计数据
(2)《孟子》中的排比句类型较多,各排比句之间差异过大。《孟子》中的排比句有句中排比、句间排比,甚至段与段间的排比,而《论语》中的排比则相对比较单纯。另外,《论语》中有4 篇是没有排比句的。
可以看出,尽管是面对比较陌生且写作风格不太相同的《论语》,本文的排比句自动识别算法依然保持了较好的性能。
4 结束语
从《孟子》单部文本出发,通过总结《孟子》中排比句的特点,制定规则,设计算法,提出了一种有效的自动识别排比句的方法。将该方法用于先秦文献中另一部重要文献《论语》,进行了排比句的自动识别,同样取得了较理想的效果。
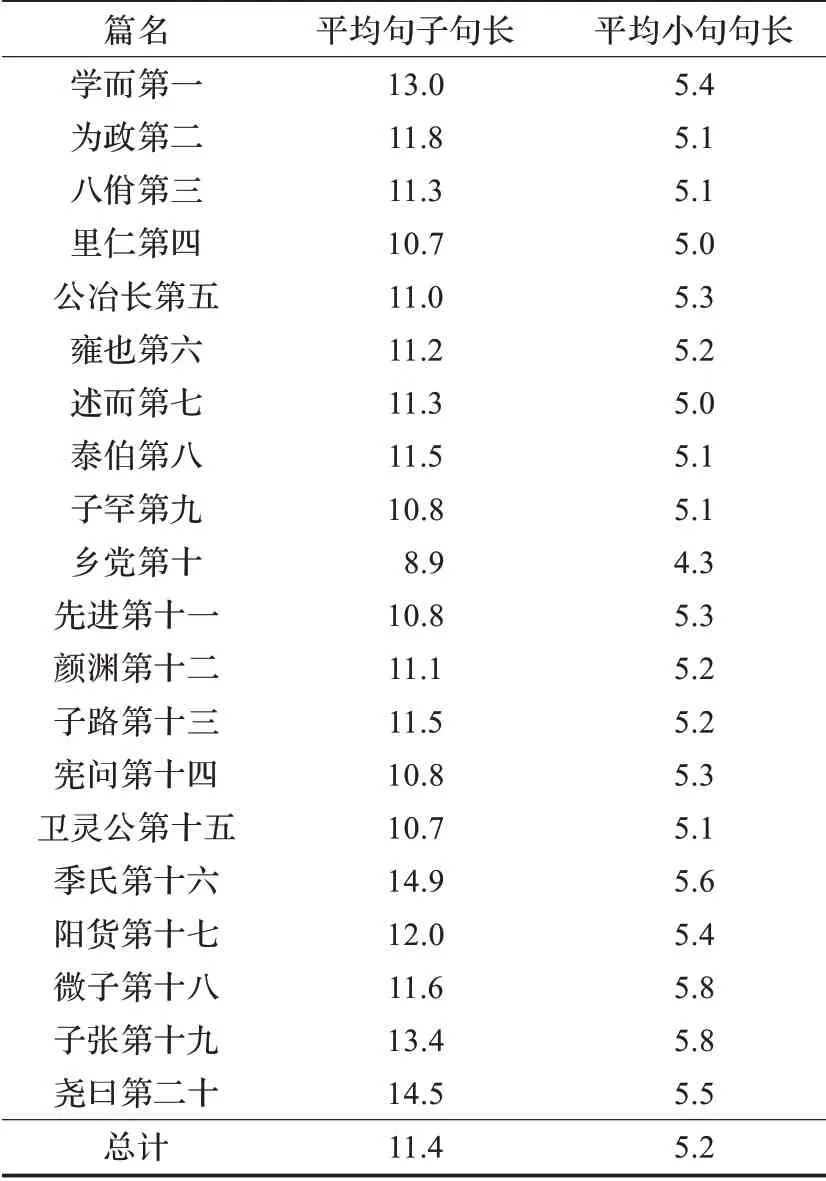
表7 《论语》各篇平均句长、平均小句句长统计数据
但是本文方法也有不足之处,比如对语料的质量有较高的依赖性,忽视了语句的意义因素等。今后的工作重心将放在如何弥补这些问题,并在更大规模的语料中提供更可靠的统计信息。自动识别排比句的方法不仅要能适应先秦文献的需求,还应该能有效地应用到其他古代汉语文献,甚至现代汉语的语料中。
[1] 丁秀菊.先秦儒家修辞研究[D].济南:山东大学,2007.
[2] 杜鹃.孟子辩论的语言艺术[J].新闻爱好者,2009(9):38-39.
[3] 黄必庄.孟子论辩的修辞艺术[J].广西师范大学学报:哲学社会科学版,1992(S1):11-15.
[4] 刘斌.历代《孟子》研究概观[J].齐鲁学刊,1987(2):8-15.
[5] 孔亚飞.《孟子》修辞研究[D].山东曲阜:曲阜师范大学,2011.
[6] 郑子瑜.论先秦诸子的修辞技巧[J].社会科学战线,1980(4):290-295.
[7] 董洪利.孟子研究[M].南京:江苏古籍出版社,1997.
[8] 周文德,杨晓莲.《孟子》数据库[M].成都:巴蜀书社,2002.
[9] 李胜梅.排比的篇章特点[J].南昌大学学报:人文社会科学版,2005(5):127-133.
[10] 于志忠.苏辙“记体散文”研究[D].内蒙古通辽:内蒙古民族大学,2011.
[11] 郑翠玲.最长公共子序列算法的分析与实现[J].武夷学院学报,2010(2):44-48.
[12] 王军祥.动态规划算法原理及应用研究[J].电脑知识与技术,2006,36:150-151.
[13] 杨伯峻.论语译注[M].北京:中华书局,1980.
猜你喜欢
四川师范大学学报(自然科学版)(2023年1期)2023-03-12
红蜻蜓·低年级(2022年9期)2022-10-14
作文周刊·小学一年级版(2021年32期)2021-01-04
小天使·一年级语数英综合(2020年11期)2020-12-16
计算机集成制造系统(2020年8期)2020-09-11
作文周刊·小学四年级版(2020年24期)2020-07-17
快乐语文(2020年18期)2020-07-17
西夏学(2018年2期)2018-05-15
小学生作文(低年级适用)(2017年3期)2017-07-06
现代语文(2016年21期)2016-05-25