
辨证认识话者自动识别系统
2013-01-15 05:21:48杨俊杰
中国司法鉴定 2013年2期
杨俊杰
(山西大学,山西 太原030006;山西警官高等专科学校,山西 太原 030021)
辨证认识话者自动识别系统
杨俊杰
(山西大学,山西 太原030006;山西警官高等专科学校,山西 太原 030021)
为了警示近年来我国司法话者识别领域中出现的一些崇外、盲目追求快速与省事的苗头,结合话者自动识别系统的研究、应用状况,从语音的共性与个性、话者识别结果的相对性与绝对性出发,通过分析比对话者自动识别与语音识别所用的特征参数及实现过程,辨证分析了制约话者自动识别系统准确率的根本原因。指出了话者自动识别系统尚无法达到人们对其的期望,以及适合于司法诉讼领域的话者自动识别系统的发展方向。
话者自动识别;语音识别;司法诉讼;特征参数
由于案件逐年增多,从事话者识别的司法鉴定部门从2000年左右的几家猛增到上百家。随着国外一些话者自动识别系统的引进,应用领域中出现了一些崇外、盲目追求快速与省事的苗头。部分应用部门不管话者自动识别系统的成熟程度、也不管本部门的实际需要,更不顾今后跨地区数据库建设及数据共享的实际需要,只要财政给钱,就买国外的、买贵的。岂不知,贵的未必就比便宜的好用,国外的话者识别系统未必就能适应中国语言的“水土环境”。本文结合话者自动识别系统的研究、应用状况,从语音的共性与个性、话者识别结果的相对性与绝对性出发,通过对比话者自动识别与语音识别所用的特征参数及实现过程,来辨证分析制约话者自动识别系统准确率的根本原因,以期能对我国司法诉讼领域辨证认识话者自动识别系统起到一定的推动作用,并提出了适合于司法诉讼领域的话者自动识别系统的发展方向。
1 话者自动识别系统的研究状况
1.1 话者自动识别系统的发展
话者自动识别的研究始于20世纪60年代。到20世纪70年代,语音信号研究进一步走向深入,线性预测技术、动态时间规整技术基本成熟。20世纪80年代,语音信号处理领域取得了新的突破,其标志之一就是概率统计模型在语音识别和话者识别中的成功应用,最典型的就是隐马尔可夫模型(Hidden Markov Model,HMM)和高斯混合模型(Gaussian Mixture Model,GMM)。其中,高斯混合模型是目前最为流行的与文本无关的话者识别模型。80年代后期,人工神经网络以其较强的模式识别能力、自学习、自组织能力给话者识别研究带来了新的思想和方法[1]。
当前,国外开展话者自动识别的主要是世界上经济比较发达的国家,如美国、俄罗斯、日本、英国、法国、德国、澳大利亚、西班牙等。国内开展话者自动识别的研究单位有清华大学、北京大学、中科院声学所、中科院自动化所、北京阳宸电子技术公司、科大讯飞公司等,并先后得到了国家自然科学基金重大和重点项目、攀登计划等基金的支持,取得了丰硕的研究成果。产品主要有北京阳宸电子技术公司的VS-99话者自动识别系统、科大讯飞的InterVeri系列、广东省公安厅王英利等开发的话者自动识别系统等。其中,清华大学智能技术与系统国家重点实验室和北京得意音通技术公司开发的“基于声纹识别技术的身份认证系统引擎”已经成功应用于出入境证件的防伪等领域,能够有效地应对变造和伪造护照等出入境证件的难题。该系统已于2007年1月通过了由公安部科技局主持的项目验收及科技成果鉴定,成果“达到国际先进水平”[1]。
1.2 话者自动识别系统中特征参数的研究状况
当前,话者自动识别系统的研究主要集中在特征参数提取与模式识别两个方面。其中,特征参数提取就是对语音信号进行分析处理,去除与话者识别无关的冗余信息,获得语音信号中表征人的基本特征的信息,它是实现话者自动识别最为关键的一步。
人之所以能够根据语音信号将话者识别出来,是因为语音信号中包含了与说话人身份(是谁)有关的个体特定信息。有人认为,“语音信号中包含了与说话人有关的一些高级信息,如方言、遣词用句特点、说话的习惯风格等。这些高级信息是话者识别系统最理想的特征参数。只是由于目前的技术水平还不能模仿人的这种能力,也找不出这些高级信息同语音参量之间的定量关系,所以它们还不能在自动话者识别系统中得到应用。除了上述高级信息外,还有一些低级信息。……这种能够表征说话人的信息,是通过共振峰频率及带宽、平均基频、频谱基本形状等这些物理可测量的参数特征表现出来的”[1]。笔者认为这种观点存在两个误解:一是,不应该把语音信息分为高级信息与低级信息。这种划分应该是受英语中supra-segmental feature (超音质特征)的影响。实际上,该supra-的含义应该是“附着在音段之上”的含义而不是“比音段高级”;二是,这些“高级信息”并不是人类区分不同说话人的主要依据,也不是话者识别系统最理想的特征参数。笔者曾对30对双胞胎语音进行过研究,发现声调、音强、时长等超音质特征的人间区别力远没有音质特征的区别力强[3]。这是因为从小到大,双胞胎就一起在相同的语言环境中跟相同的学习对象习得语言,在说话的方言、词汇、语法、风格等超音质方面必然高度一致。即使不是双胞胎,同一地方的一些人在超音质方面也会高度相似。因此,超音段信息并不是区分不同说话人的“高级信息”及主要依据,也不是话者识别系统最理想的特征参数。不过可以肯定的是这些超音段信息在说话人的听觉识别中也具有较大作用。但由于目前的技术水平还不能模仿人的这种能力,也找不出这些“高级信息”同语音参量之间的定量关系,所以它们还不能在自动话者识别系统中得到应用[1]。
目前,话者自动识别中常用的特征参数主要有:
(1)线性预测倒谱系数
线性预测倒谱系数(Linear Predictive Cepstral Coding,LPCC)是一个比较重要的特征参数,它能够比较彻底地去除语音产生过程中的激励信息,能较好描述语音信号的共振峰特性。
(2)Mel频率倒谱系数
Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)表达了一种常用的从语音频率到“感知频率”的对应关系,这更符合人耳的听觉特性。
(3)基音周期
目前的方法主要是基于传统的语音模型,最具代表性的就是自相关法、平均幅度差函数法、线性预测分析法、倒谱法、小波变换法及在四种算法基础上的衍生算法(如小波变换和自相关相结合),这些都属于频域方法的范畴;此外,还有一种更早提出的时域方法,即Gold和Rabiner提出的并行处理方法[3]。
(4)共振峰
共振峰是表征语音信号特征的基本参数之一。传统的共振峰提取采用了倒谱分析和线性预测分析。有学者针对LPC方法中会受到合并共振峰和虚假共振峰干扰的缺点,提出了新的提取方法,即在LPC幅度谱上搜寻最大的极大值点所对应的频率,并将它作为构成声道参数的某一谐振腔所对应的共扼复根的角度,再通过LPC系数相频特性的一次导数和三次导数相结合的方法求出这对共轭复根的幅度,从而确定了该谐振腔,也就得到了该谐振腔的共振峰[4]。虽有一些改善,但效果并不是很好。也有一些学者提出一种基于共振峰增强的共振峰频率估计方法。近年来,还有人提出一些共振峰提取的新方法,例如,基于声道激励信号解卷积的倒谱分析法,基于逆滤波器的共振峰提取方法[5],基于语音非线性模型的共振峰估计方法等。

表1 特征参数比较表
通过表1中四种特征参数的声学特性、提取原理及鲁棒性三方面的分析总结可以发现:杨俊杰等在话者识别的语音学方法中区别力最强的共振峰特征[6],由于易受虚假共振峰的干扰其鲁棒性却变得较弱。因此,自动识别系统中共振峰特征的区别价值是被降低了。笔者认为这与共振峰特征的利用方法有关。在语音学方法中,话者鉴定专家是利用各个音节共振峰的细节特征,而话者自动识别系统是利用一段语音中共振峰的整体特征,正是这种整体性应用掩盖了语音的个体特殊性;同时,话者鉴定专家可以依靠自己丰富的经验综合排除噪音、信道、情绪等因素的干扰,而话者自动识别系统却容易受到这些因素的干扰。
目前,对特征的进一步研究主要包括两个方面:一是对MFCC提取的改进,如基于平滑幅度谱包络的MFCC 的改进参数 SMFCC[7](Smoothing MFCC),鉴别性Mel频率倒谱系数[8](DMFCC)等等。二是寻找非声道参数,如针对传统的特征参数只反映声道的频谱特性,而忽略了声门振动信息以及声门振动对声道的潜在影响,有学者提出了消除声门振动对说话人声道影响的倒谱特征[9];韵律,词汇等超音质特征参数逐渐被应用于话者识别系统中。但截至目前尚未找到简单可靠的可更好应用于话者识别的语音特征参数。
1.3 话者自动识别系统正确识别率的现状
话者识别系统的好坏是由正确识别率、训练时间的长短、识别时间、对参考参量存储量的要求、使用者使用的方便程度等许多因素决定的。
当前,国内外所见话者自动识别系统的正确识别率相差不多。例如,美国国家标准技术署(National Institute of Standard and Technology,简称 NIST) 从1996年开始到2010年一共举行了15次话者识别评测(最大库容约为6 000人[10])。这些测试体现了参测系统在接近真实环境中的实际表现,被认为是国际上水平最高、最严谨、过程最公平、结果最权威的说话人与语音识别系统测试。受邀参加评测的均为世界顶级的专业研究开发机构。我国近年来也有一些专业机构参加。其中,安徽科大讯飞语音技术公司已连续3年成绩优秀,2008年在NIST所有4个总体测试中,科大讯飞系统(iFLY)又获得2项第1名、1项第3名,1项第5名,综合成绩排名第一的成绩[11]。
同时,由清华大学智能技术与系统国家重点实验室和北京得意音通技术公司开发的通用的基于话者自动识别(声纹识别)技术的身份认证系统引擎,是支持跨平台、多信道、实时处理效率高、抗干扰性好、可扩展性强、适用面广的通用说话人身份认证应用系统产品。该系统可以根据语音波形中所蕴涵的说话人信息,自动识别确认话者身份,具有识别精度高、抗干扰能力强、适用范围广、安全性能强等特点。其识别性能为:实际系统的错误拒绝率(漏识率)为3.17%,错误接受率(误识率)为4.93%,均低于5%[2]。但是,如果将两类错误率加起来还是达到大约8.1%的错误率。更为关键的是这才是1200人的库容量。随着库容的增加准确识别率还会下降。
2009年3月,北京软件产品质量检测检验中心对得意音通与公安部三所联合开发的《海量语音文件的目标说话人筛选系统》进行了全面测试,系统的漏识率和误警率分别达到了2.81%和2.81%[12]。其两类错误率加起来约为5.62%。
诚然,近些年来,话者自动识别的研究取得了可喜的进步,但衡量话者自动识别系统性能的一项重要指标是在一定库容量下的等错误率的高低。目前多数系统在解决海量数据、不同信道以及噪声影响等关键技术方面效果还不理想,离实际应用还有一些差距[11]。中国刑事警察学院的崔景旭等曾用西班牙的话者自动识别系统BATVOX对用专家方法鉴定过的案件进行过实际测试,发现当参考数据库里没有能够和待检人嗓音匹配的参考人群时,会出现明显失误[13]。
同时,国内外实验数据证明:
(1)信号通道对识别率影响最大,按照不同通道建立正常发音数据库是必须的。
(2)伪装发音对识别率的计算也会发生较大影响。德国马尔堡大学声学研究所和西班牙马德里大学的技术人员对此做过实验研究。他们发现,当伪装语音没有与之对应的伪装语音的参考模型时,提高音调、降低音调和阻碍鼻腔发音均会出现识别率的明显下降。可见有无与待测语音对应的参考数据库对识别结果的影响也很大[13]。
此外,语言种类(包括方言)、言语方式(对话、独白、朗读、大声、小声、不同情绪等)、性别、话者人数等因素都会对话者自动识别的准确率产生较大的影响。例如,当在汉语方言与普通话之间进行话者自动识别时,虽然现有自动识别系统大多采用与文本无关的方式来进行,但由于方言语音系统与普通话语音系统的差异,其识别准确率要远低于同语言之间的准确率[14]。尤其是当方言中存在嘎裂声、假声等特殊发声态的时候,识别率还会更低。因此,原则上说,应该建立与它们一一对应的多种参考数据库。但现实问题是:
(1)在某些案件中,信道、伪装方式等情况是未知的。在这种情况下,识别时选用哪个参考语音库则会成为主要问题。诸如语言种类、言语方式,即使是已知的,但由于其分类庞杂,要建立一一对应的参考数据库是不现实的。由此就导致了话者自动识别的准确率问题及其结论的应用问题。正是基于上述原因,国外话者识别工作是建立在语音数据库基础上的专家系统,法庭不承认计算机自动识别的单一结果,必须要求有专家的鉴定报告[11]。
(2)中国语言丰富,人口众多。既有丰富的少数民族语言,更有十大方言区及其内差异明显的次方言区,建立一一对应的参考数据库更是难以实现的。同时,中国拥有世界上将近19.85%[15]的人口,其数据库容量也大的难以完成。因此,在诸如西班牙等人口仅有4 702万,并且语音差异明显的外国人占户籍登记人口12.2%[16]的国家中比较好用的话者自动识别系统,则未必能适应中国语言的“水土环境”,“水土不服”导致的准确率下降也在所难免。
2 话者自动识别系统的应用状况及原因分析
2.1 话者自动识别系统的应用现状
由于语音具有不会遗失和忘记、不需记忆、使用方便、经济及可扩展性良好等众多优势,随着技术的发展,话者自动识别逐步被广泛应用到军事、商业、安全防范、司法诉讼、医学等领域。其中,在军事、商业、安全防范等领域上的应用较好,但截至目前,在司法诉讼领域,话者自动识别结论在世界各国均不能单独作为法庭证据使用,仅有一些机构采用话者自动识别与语音专家结论相结合的综合方法,二者结果相互印证(如法国国家宪兵总局话者识别实验室等)。
2.2 话者自动识别系统应用状况的原因分析
话者自动识别系统在军事领域应用较好并不是因为该领域话者自动识别系统的准确率比其他领域的准确率高,而是因为在军事上:
(1)比对人群数量有限(集中在主要指挥人员),数据库库容与司法诉讼的库容相比要小的多;
(2)识别对象来自天南海北,各自的语言差异明显;(3)其使用的原则是“宁可错杀一千也不漏掉一个”。话者自动识别系统在商业、安防领域应用较好是因为可以进行语音与说话人的二重认证,进而增加系统的准确率。但诉讼中话者识别则比军事、安防等领域要严格的多,其原则是“宁可放纵一千也不应冤枉一个”。所以要求话者识别结论要有很高的识别准确率。而目前只有综合听辨、视谱、言语分析等为一体的专家分析方法的鉴定结论能够满足这一要求。但是,从绝对和相对的辩证统一来说,也不是绝对不能在司法诉讼领域应用话者自动识别系统,而是要根据话者自动识别系统目前的研究现状,充分利用其快速、方便、经济及可扩展性良好等众多优势把其应用到重点人口、案件语音等的辨别中,从而为缩小案件侦查范围、串并案件、专家鉴定等工作提供服务。特别是,当需要在一个人数较少的封闭人群中识别某一说话人时,话者自动识别系统则可以充分体现其高效、较为准确的价值。
3 制约话者自动识别系统识别率的原因分析
制约话者自动识别结果在法庭上不能单独作为证据的直接原因是其准确率不高以及容易受到噪音、信道、伪装、情绪、语言种类等因素的影响,而最根本的原因则是实现话者自动识别所依据特征参数的有效性问题。
说到话者自动识别所依据的特征参数则不得不涉及到同样以语音信号为素材,解决机器“听”懂人类语言的语音识别技术。二者之间即有共同点,也存在不同之处。其共同点是:二者都要通过对所接受的语音信号进行处理,提取相应的特征参数,建立相应的匹配模型,然后据此做出判断;其区别在于,话者识别着眼于包含在语音信号中的个性特征,提取说话人的个人信息,以达到识别说话人是谁的目的,它强调不同人之间的语音差别(即虽然说话人说的语音内容相同,但系统能识别出说话人不同);而语音识别侧重于语音信号中的语义内容信息,强调不同语音信号中的共性信息(即要把不同人说的a都识别为a)。
通过对话者自动识别和语音识别实现过程的对比,笔者发现两者的识别系统基本一样,其系统主要包括两个阶段:训练阶段和模式识别阶段[17](见图1)。
从系统框图可以看出,无论是在训练还是识别阶段,都需要对语音信号进行特征提取。因此,特征提取是话者识别系统中的重要组成部分。对此,笔者对话者自动识别和语音识别中所用到的主要特征参数进行了比较、分析[18],结果见表2。
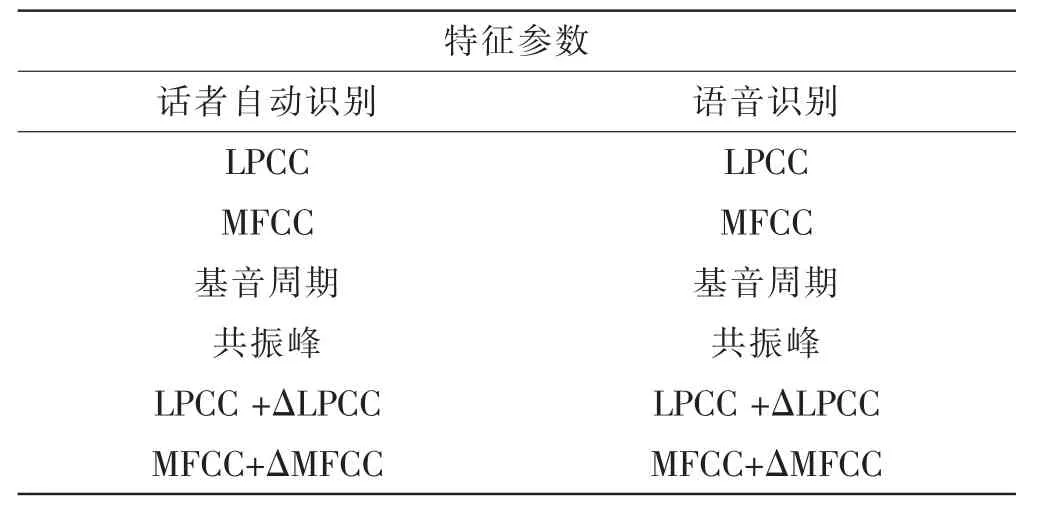
表2 话者自动识别和语音识别所用特征参数对比表
通过以上比较可以发现,识别目的截然不同的话者自动识别和语音识别所采用的特征参数竟然大体相同。由此引出了一个重要问题:对于每一种特征参数,其在话者识别和语音识别中的有效性(或价值)是否相同,即其包含的语义信息和说话人的个性信息是否相同?对此,有学者作了类似的分析,他们提出了一种语音特征参数中语义和个性特征子分量分析与有效性评价的4S方法,对语义和个性特征的成份比例进行分析,并通过量化指标来评判特征参数对语音识别和话者识别的有效性。对常用特征参数LPC、LPCC和MFCC进行的4S分析表明:这些参数表达语义信息比说话人个性特征信息更加充分,即:与话者识别相比较,它们显然更适合于语音识别的应用[19]。因此,如何从语音信号中提取更能体现说话人的个性信息的特征将是今后话者识别应用走向市场的一大关键。
4 结论
经过前面的辨证分析、比较,得到以下认识:
(1)现有话者自动识别所利用的特征参量更适合于进行语音识别,需要继续寻找更能代表个人特定性的语音特征。
(2)我国话者自动识别水平近年来已经接近国外水平,并非国外的产品性能就肯定好。从全局的角度出发,我国更应该建立自己的话者自动识别语音库的标准及语音库,以满足各地犯罪信息共享的需求。
(3)在国外某些国家应用较好的话者识别系统难以适应中国的语言环境,无法达到预期的正识率。
(4)话者自动识别具有广阔的应用前景,但由于其现有的识别水平及影响因素,其应该更多地被应用到军事、安防等领域以及用来缩小侦查范围、串并案件的侦查初期,而不是单独为法庭提供证据。因此,企图只靠话者自动识别系统进行说话人鉴定的追求快速、省事的想法是不现实的。
(5)话者识别工作应该是建立在语音数据库基础上的专家系统。由于话者自动识别的局限性,法庭不承认计算机自动识别的结果,必须要求有专家的鉴定报告。所以专家方法和话者自动识别相结合的半自动综合识别方法,是话者识别的最终发展趋势。
致谢
本文是2012年度国家社会科学青年基金项目(编号:12CYY015)的调研性成果之一,曾在第十届中国语音学学术会议上宣读并得到王英利高级工程师的点评,一并感谢。
[1]于明刚.噪声环境下话者识别研究[D].哈尔滨工程大学硕士论文,2008.
[2]清华大学.通用的基于声纹识别技术的身份认证系统引擎[EB/OL].http://www.tsinghua.e, 2011-11-16/2012-09-10.
[3]NOLL A M.Cepstrum pitch determination[J].Acoust.Soc.Am, 1967,(47): 293-309.
[4]何峰,陈晓清,李国锁,等.一种新的语音信号共振峰提取的算法[J].信号处理,2007,(4):618-621.
[5]Watanabe A.Formant estimation method using inverse-filter control.J.IEEE Transactions on Speech and Audio Processing[J].2001,9(4):317-326.
[6]杨俊杰,崔效义,李敬阳,等.常用语音特性在鉴别双胞胎语中的价值研究[J].中国人民公安大学学报:自然科学版,2006,(3):21-24.
[7]张伟伟,杨鼎才.用于话者识别的MFCC的改进算法[J].电子测量技术,2009,(8):118-121.
[8]王刚,郑方.电话信道下应用DMFCC进行话者识别[J].清华大学学报:自然科学版,2009,(10):1597-1600.
[9]杨璞.基于声门特征的话者识别研究[D].浙江大学硕士学位论文,2005.
[10]National Institute of Standards and Technology.2010 NIST_E-valuation Plan[EB/OL].http://www.itl.nist.gov/iad/mig/tests/sre/2010/index.html,2011-11-16/2012-01-20.
[11]李敬阳.国内外声纹鉴定发展概述 [J].刑事技术,2009,(S2):51-55.
[12]得意音通技术.北京软件产品质量检测检验中心对《海量语音文件的目标说话人筛选系统》进行了全面测试[EB/OL].http://www.d-ear.com/newsview.asp?id=214&sj=2009, 2011-11-22/2012-02-20.
[13]崔景旭,洪韩,王欣,等.话者自动识别系统及其应用[C].第九届中国语音学学术会议论文集,2010.
[14]赵靖,龚卫国,杨利平.基于GMM的普通话和四川方言独立文本的说话人确认[J].计算机应用,2008,(3):792-794.
[15]中国人口占世界人口比重下降[EB/OL].http://news.163.com/11/0712/11/78OPF20U00014AED.html,2012-11-6/2012-02-20.
[16]西班牙人口情况 [EB/0L].http://es.mofcom.gov.cn/aarticle/ddgk/zwrenkou/201111/20111107820876.html,2012-11-6/2012-03-12.
[17]李轶.说话人识别系统研究[D].浙江大学硕士学位论文,2003.
[18]刘雅琴,智爱娟.几种语音识别特征参数的研究[J].计算机技术与发展,2009,(12):67-70.
[19]俞一彪,许允喜,芮贤义.一种语音特征参数子分量分析与有效性评价的新方法[J].信号处理,2007,(2):188-191.
Understand the Automatic Speaker Identification System Dialectically
YANG Jun-jie
(Shanxi University, Taiyuan 030006, China; Shanxi Police College, Taiyuan 030021, China)
To warn the abuse of foreign automatic speaker identification system to pursue speed and convenience in recent years,the status of the study and application of automatic speaker identification system was introduced.Based on the commonness and individuality of the voice and the relativity and absoluteness of speaker identification results,this paper compares automatic speaker identification system and automatic speech recognition system in characteristic parameters and process,and analyzes the fundamental reasons of the restricted accuracy of automatic speaker identification system.As a conclusion,the automatic speaker identification system is still unable to achieve what is desired.The development direction of automatic speaker identification in forensic science was put forward.
automatic speaker identification; speech recognition; forensic science; characteristic parameter.
DF793.2
A
10.3969/j.issn.1671-2072.2013.02.017
1671-2072-(2013)02-0071-05
2012-11-19
2012年度国家社会科学青年基金项目(12CYY015)
杨俊杰(1973—)男,讲师,硕士,主要从声像资料、汉语方言学研究。E-mail:545668179@qq.com。
施少培)
鉴定实践Forensic Practice
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
知识经济·中国直销(2018年12期)2018-12-29 12:22:12
当代陕西(2018年12期)2018-08-04 05:49:22
特别健康(2018年3期)2018-07-04 00:40:18
制造技术与机床(2017年11期)2017-12-18 06:46:39
纺织科学研究(2017年4期)2017-05-17 03:59:56
发明与创新(2016年26期)2016-08-22 03:23:28
电测与仪表(2016年6期)2016-04-11 12:06:38
电测与仪表(2015年7期)2015-04-09 11:40:04
