
Feature combination via importance-inhibition analysis
2013-01-08 08:26:20YangSichunGaoChaoYaoJiaminDaiXinyuChenJiajun
Yang Sichun Gao Chao Yao Jiamin Dai Xinyu Chen Jiajun
(1State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing 210093, China)(2School of Computer Science, Anhui University of Technology, Maanshan 243032, China)(3School of Computer Science and Information Engineering, Chuzhou University, Chuzhou 239000, China)
Automatic question answering (QA)[1]is a hot research direction in the field of natural language processing (NLP) and information retrieval (IR), which allows users to ask questions in natural language, and returns concise and accurate answers. QA systems include three major modules, namely question analysis, paragraph retrieval and answer extraction. As a crucial component of question analysis, question classification classifies questions into several semantic categories which indicate the expected semantic type of answers to questions. The semantic category of a question helps to filter out irrelevant answer candidates, and determine the answer selection strategies.
In current research on question classification, the method based on machine learning is widely used, and features are the key to building an accurate question classifier[2-10]. Li et al.[2-3]presented a hierarchical classifier based on the sparse network of winnows (SNoW) architecture, and made use of rich features, such as words, parts of speech, named entity, chunk, head chunk, and class-specific words. Zhang et al.[4]proposed a tree kernel support vector machine classifier, and took advantage of the structural information of questions. Huang et al.[5-6]extracted head word features and presented two approaches to augment hypernyms of such head words using WordNet. However, when used to train question classifiers, these features were almost combined incrementally via importance analysis (IA) which is based on the importance of individual features. This method is effective when using only a few features, but for very rich features, it may prevent question classification from further improvement due to the problem of ignoring the inhibition among features.
In order to alleviate this problem, this paper proposes a new method for combining features via importance-inhibition analysis (IIA). By taking into account the inhibition among features as well as the importance of individual features, the IIA method more objectively depicts the process of combining features, and can further improve the performance of question classification. Experimental results on the Chinese questions set show that the IIA method performs more effectively than the IA method on the whole, and achieves the same highest accuracy as the one by the exhaustive method.
1 Feature Extraction
We use an open and free available language technology platform (LTP) (http://ir.hit.edu.cn/demo/ltp) which integrates ten key Chinese processing modules on morphology, word sense, syntax, semantics and other document analysis, and take the question “中国哪一条河流经过的省份最多?(Which river flows through most provinces in China?)” as an example. The result of word segmentation, POS tagging, named entity recognition and dependency parsing of the sample question is presented in Fig.1.
We extract bag-of-words (BOW), part-of-speech (POS), word sense (WSD,WSDm), named entity (NE), dependency relation (R) and parent word (P) as basic features. Here, WSD is the 3-layer coding, i.e., coarse, medium and fine grained categories in the semantic dictionary “TongYiCiCiLin”, while WSDm is the 2-layer, i.e., coarse and medium grained word category. Tab.1 gives the features and their values of the sample question.

Fig.1 Analysis result of the sample question with LTP platform
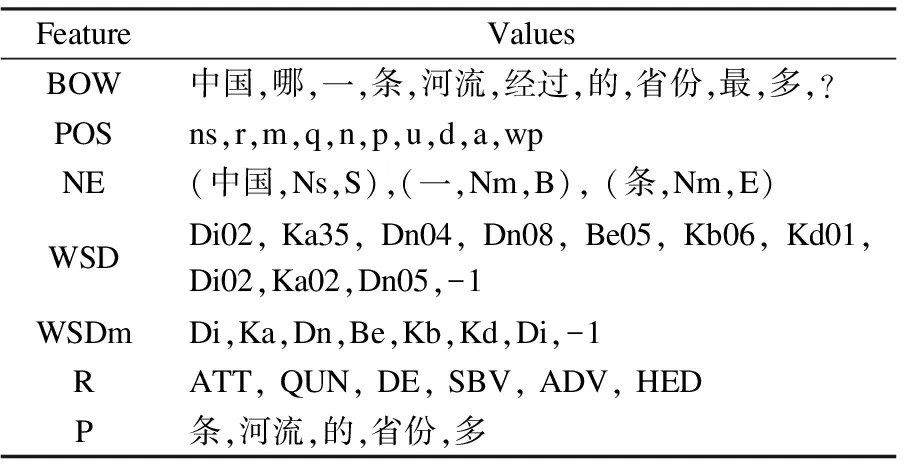
Tab.1 Features and their values of the sample question
2 Combining Features via Importance-inhibition Analysis
The basic features described above belong to different syntactic and semantic categories, and contribute to question classification from various levels of language knowledge. We combine these basic features to further improve the performance of question classification. Since the BOW feature is the basis of other features, it is always combined with other features. For example, the POS feature follows the BOW feature when these two types of features are combined.
With respect to the methods for combining features, the most intuitive one is the exhaustive method which lists all the feature combinations one by one. The exhaustive method is inefficient and not feasible in practical applications. In existing literature, combining features is conducted just on the basis of the importance of the features. However, this method may prevent it from further improvement on question classification due to the problem of ignoring the inhibition among features. For example, the dependency relation feature R and the POS feature belong to the same syntactic category, and they both contribute to question classification. However, since R covers POS to a large extent in syntactic expression, R will inhibit POS when they appear in the same feature combination. Similarly, the word sense features WSD and WSDm belong to the same semantic category, since the difference between WSD and WSDm is not obvious, they will inhibit each other when they are present at the same feature combination. From the above discussions, we find that an effective method for combining features should take into account the inhibition among features as well as the importance of individual features.
In this paper, we propose a new method for combining features via importance-inhibition analysis. Before introducing the IIA method in detail, we should specify some notations. In our importance-inhibition analysis setting, the feature set is a basic concept following the common feature combination.
Now we can give some formal definitions.
Definition1(importance) Given featuresfiandfj,fiis more important thanfjif the accuracy offiis higher than that offj.
Algorithm 1 gives the implement of the IIA method.
Algorithm1Importance-inhibition analysis algorithm
Input:F
1)nfeatures to form feature setF;
4) Fori=2 ton
forj=1 to |F|
F=F-F′;
The IIA method is on the basis of the (k-1)_ary feature combination to obtain the bestk_ary one, so compared with the exhaustive method, it can significantly improve the efficiency of feature combination. In addition, since the IIA method takes into account the inhibition among features as well as the importance of individual features, compared with the IA method, it can more objectively depict the process of combining features and ensure a better performance of question classification.
3 Experimental Results and Analysis
3.1 Data set and evaluation
In our experiments, we use the Chinese questions set provided by IRSC lab of HIT (http://ir.hit.edu. cn), which contains 6 266 questions belonging to 6 categories and 77 classes.
The open and free available Liblinear-1.4(http://www.csie.ntu.edu.tw/~cjlin/liblinear/) which is a linear classifier for data with millions of instances and features which is used to be the classifier. We use 10-fold cross validation on the total question set to evaluate the performance of the question classifications.
3.2 Combining features via IIA
According to the IIA method, we take BOW as the initial feature, and combine POS, NE, WSD, WSDm, R and P features gradually to form feature combinations, such as 2_ary, 3_ary, 4_ary and so on. The accuracies of individual features are presented in Fig.2(a). Figs.2(b) to (d) list all the accuracies of 2_ary, 3_ary and 4_ary feature combinations respectively, where Base1, Base2 and Base3 stand for the corresponding best 1_ary, 2_ary, 3_ary feature combinations.
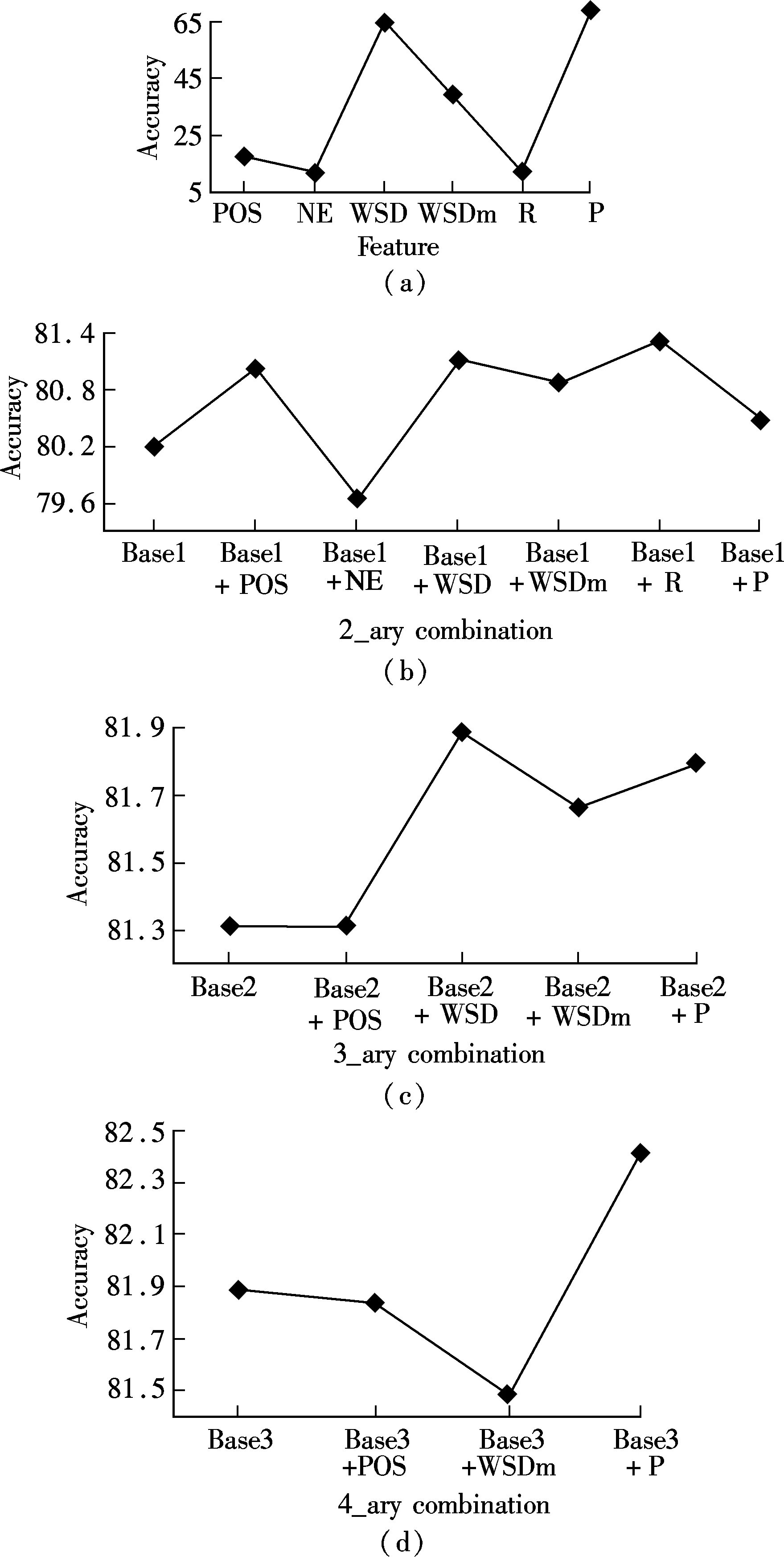
Fig.2 Accuracies of n_ary feature combinations. (a) 1_ary; (b) 2_ary; (c) 3_ary; (d) 4_ary
In Fig.2(b) and Fig.2(c), the P feature has the highest classification accuracy among all the candidates, but the accuracies of Base1+P and Base2+P are not the highest in all the 2_ary and 3_ary feature combinations, respectively. In particular, the accuracy of Base1+P is the last but one in all the 2_ary feature combinations.
In Fig.2(b), the accuracy of Base1+NE is lower than that of Base1, so NE is no longer considered in subsequent rounds. Similarly, in Fig.2(d), the accuracies of Base3+POS and Base3+WSDm are both lower than that of Base3, so POS and WSDm are not considered in subsequent rounds. This is greatly convenient for filtering noise features.
In Fig.2(c) and Fig.2(d), the accuracies of Base1+NE, Base3+POS, Base3+WSDm are lower than those of Base1 and Base3, respectively. The reason is that R covers POS to a large extent in syntactic expression, and the difference between WSD and WSDm is very small. As a result, there exists the inhibition among features when they are in the same feature combination.
3.3 Performance comparison with IA
In order to verify the efficiency and effectiveness of IIA, we conduct performance comparison with IA. Tab.2 shows the accuracies of the feature combinations via IIA and IA, respectively, where the “2_ary” column means 2_ary combinations, the “Base” row denotes the best (n-1)_ary combinations, “+POS” row means the feature combined with its baseline, the accuracy in bold means the maximum ofn_ary combinations, and the one in bold with underline shows the maximum of all the combinations.

Tab.2 Accuracies of feature combinations via IIA and IA %
Fig.3 conducts the comparison of average and maximum accuracies between IIA and IA, where theXaxis denotesn_ary feature combinations, theYaxis denotes classification accuracies.

Fig.3 Performance comparison between IIA and IA
From Fig.3, we can see that IIA shows a gradual increase in average and maximum accuracies in all the feature combinations, while IA shows a slight decline in accuracy at the 4_ary and 7_ary ones. The reason is that IIA is based on the best previous feature combination to obtain the current one. In addition, IIA performs as well as IA in average accuracy at 3_ary feature combinations, and achieves a great improvement over IA in average and maximum accuracies at 2_ary and 4_ary feature combinations. In particular, IIA achieves 0.813 9% and 0.829 9% higher than IA in average and maximum accuracies at 4_ary feature combinations, so we can draw a conclusion that IIA performs significantly better than IA on the whole.
In order to further verify the efficiency and effectiveness of IIA, we conduct performance comparison with the exhaustive method. Experimental results show that the exhaustive method carries on 6 rounds for acquiring 63 feature combinations, while IIA does 3 rounds with 13 feature combinations gained. This demonstrates that IIA is much more efficient and feasible than the exhaustive method in practical applications. Furthermore, IIA gets the accuracy of 82.413% which is the highest one gained by the exhaustive method.
4 Conclusion
In this paper, we propose a new method called IIA to combine features via importance-inhibition analysis. The method takes into account the inhibition among various features as well as the importance of individual features. Experimental results on the Chinese question set show that the IIA method performs more effectively than the IA method on the whole, and achieves the same highest accuracy as the one gained by the exhaustive method.
The IIA method is a heuristic one in nature, and may be faced with the problem of a local optimum. In our further work, we will make great efforts to achieve more efficient and effective optimization for combining features.
AcknowlegementWe would like to thank the IRSC laboratory of Harbin Institute of Technology for their free and available LTP platform.
[1]Zhang Z C, Zhang Y, Liu T, et al. Advances in open-domain question answering [J].ActaElectronicaSinica, 2009,37(5):1058-1069. (in Chinese)
[2]Li X, Roth D. Learning question classifiers[C]//Procofthe19thInternationalConferenceonComputationalLinguistics. Taipei,China, 2002: 1-7.
[3]Li X, Roth D. Learning question classifiers: the role of semantic information[J].JournalofNaturalLanguageEngineering, 2006,12(3): 229-250.
[4]Zhang D, Lee W. Question classification using support vector machines[C]//Procofthe26thAnnualInternationalACMSIGIRConferenceonResearchandDevelopmentinInformationRetrieval. Toronto, Canada, 2003: 26-32.
[5]Huang Z H, Thint M, Qin Z C. Question classification using head words and their hypernyms[C]//Procofthe2008ConferenceonEmpiricalMethodsinNaturalLanguageProcessing. Honolulu, Hawaii, USA, 2008: 927-936.
[6]Huang Z H, Thint M, Celikyilmaz A. Investigation of question classifier in question answering[C]//Procofthe2009ConferenceonEmpiricalMethodsinNaturalLanguageProcessing. Singapore, 2009: 543-550.
[7]Li F T, Zhang X, Yuan J H, et al. Classifying what-type questions by head noun tagging[C]//Procofthe22ndInternationalConferenceonComputationalLinguistics. Manchester,UK, 2008: 481-488.
[8]Li X, Huang X J, Wu L D. Combined multiple classifiers based on TBL algorithm and their application in question classification [J].JournalofComputerResearchandDevelopment, 2008,45(3): 535-541. (in Chinese)
[9]Sun J G, Cai D F, Lu D X, et al. HowNet based Chinese question automatic classification [J].JournalofChineseInformationProcessing, 2007,21(1):90-95. (in Chinese)
[10]Zhang Z C, Zhang Y, Liu T, et al. Chinese question classification based on identification of cue words and extension of training set [J].ChineseHighTechnologyLetters, 2009,19(2): 111-118. (in Chinese)
猜你喜欢
当代水产(2019年11期)2019-12-23 09:03:46
小太阳画报(2019年4期)2019-06-11 10:29:48
中国经济周刊(2018年31期)2018-08-14 03:29:16
散文诗(2018年20期)2018-05-06 08:03:44
散文诗(2017年17期)2018-01-31 02:34:15
散文诗(2017年15期)2018-01-19 03:07:59
决策探索(2017年11期)2017-06-23 18:41:32
少儿科学周刊·少年版(2015年11期)2015-12-17 20:49:15
中国土地科学(2014年4期)2014-03-01 03:25:34
雕塑(2000年2期)2000-06-22 16:13:30
 Journal of Southeast University(English Edition)2013年1期
Journal of Southeast University(English Edition)2013年1期
- Journal of Southeast University(English Edition)的其它文章
- Factors affecting headway regularity on bus routes
- Effects of carbonaceous conductive fillers on electrical and thermal properties of asphalt-matrix conductive composites
- Fatigue behavior of basalt-aramidand basalt-carbon hybrid fiber reinforced polymer sheets
- Effect of chloride salt concentration on unconfined compression strength of cement-treated Lianyungang soft marine clay
- Response mechanism for widened pavement structure subjected to ground differential settlement
- Flexural behaviors of double-reinforced ECC beams