
基于存储资源迭代重用的低成本寄存器重命名方法
2012-12-07 06:04:58鄢传钦孟建熠
传感器与微系统 2012年4期
鄢传钦,孟建熠
(浙江大学超大规模集成电路设计研究所,浙江杭州310027)
0 引言
寄存器重命名是超标量流水线中实现处理器内核指令动态调度的关键技术,解决了指令之间的反相关(WAR)和输出相关(WAW)问题[1]。随着超标量处理器指令级并行性的不断挖掘和流水线进一步加深,指令发射窗口进一步增大[2],停留在流水线中的“飞行”指令也随之增加,因此,必须增加物理寄存器的数量来完成指令的调度[3],然而寄存器资源的增大给处理器带来了寄存器的访问延迟、面积、功耗等一系列问题[4,5]。这些问题的存在使得通过简单地增加物理寄存器的资源来提高处理器的性能变得举步维艰[6],因此,提高物理寄存器的利用效率以达到提高处理器性能的同时节省资源变得尤为重要。
传统的寄存器重命名方法[7]为了降低设计的复杂度,在译码阶段为指令分配物理寄存器,在指令退休写回时释放寄存器资源。其问题在于物理寄存器的使用效率太低,一旦发生物理寄存器的结构冲突,流水线必须停顿直到资源冲突消除。
文献[4,5]提出了一种通过两级映射推迟物理寄存器的分配的重命名方法。这种方法在译码阶段通过第一级映射为指令分配虚拟寄存器。在指令发[5]或执行完成[4]时通过第二级映射为指令分配真实的物理寄存器。两级映射的方法虽然能够通过推迟实际物理寄存器的分配来提高利用效率,却很大程度上增加了硬件设计的复杂度。
本文提出一种迭代重用物理寄存器的方法,增加指令分发时实际可分配的物理寄存器数量,并通过在指令发射队列中引入物理寄存器占用的相关性信息,在发生物理寄存器结构冲突的情况下解除流水线的停顿,有效地提高了流水线的执行效率。该方法不但提高了物理寄存器的利用率,达到节省物理寄存器资源的目的,同时避免了文献[4,5]两级映射方法带来的硬件设计复杂度。
1 物理寄存器性能研究
重命名映射表和用作重命名的物理寄存器共同完成了ISA寄存器[8]的重命名,解决指令之间的数据相关。重命名映射表记录了最新的ISA寄存器到物理寄存器的映射关系,典型的重命名映射表通过译码得到的ISA寄存器号来索引物理寄存器,因此,重命名映射表同ISA寄存器一一对应。而物理寄存器则担负着指令执行结果的缓存,操作数的旁路以及结果的按序回写。为便于对物理寄存器进行独立的研究,本文的研究将基于独立的物理寄存器结构[1]。
为了保证流水线效率的充分发挥,超标量流水线中的物理寄存器的数量必须达到流水线中“飞行”指令的数量。随着流水线的加深和指令发射宽度的增大,物理寄存器的数量也将随之增加。而当物理寄存器的数量受到访问延迟、面积、功耗、读写端口压力各方面的限制时,其数量必将无法满足充分发挥流水线效率的条件,物理寄存器的数量将在很大程度上影响处理器的性能。表1是一个8级流水线四发射超标量嵌入式处理器的IPC(instructions per cycle)与物理寄存器数量变化的关系。实验使用嵌入式powerstone测试程序,测试结果是处理器执行各个程序的IPC平均值。处理器采用保留站和重排序缓存的大小分别为64个,并且保证足够大的指令和数据cache,这样整个执行内核的性能影响将主要来自物理寄存器的结构冲突。表1数据显示,当物理寄存器数量较少时,IPC值随随着物理寄存器数量的增加而线性增长;当物理寄存器数量达到一定数量之后,IPC变化趋于平缓并接近极限性能,处理器性能对物理寄存器数量的依赖性变弱。要使CPU的性能接近极限,物理寄存器的数量需要达到44个以上,这无疑将是一个很大的资源消耗,对处理器的面积、功耗、寄存器访问延迟将会是不小的压力。而反之减少物理寄存器的资源,结构冲突加剧造成的流水线停顿必然将成为处理器性能的瓶颈。本文重点研究一种低硬件成本的寄存器重命名方法。

表1 传统方法寄存器数量与IPC性能分析Tab 1 Number of registers and the IPC performance analysis in traditional method
2 物理寄存器迭代重用方法
传统的寄存器重命名只要发生物理寄存器的资源冲突,流水线即产生停顿,即使指令发射队列仍有空闲表项。因此,如果能够做到即使发生资源冲突时处理器仍然发射指令,那么处理器内核流水线的指令级并行性将进一步得到提升。另一方面,传统的寄存器重命名方法中,物理寄存器被分配时即被占用,而实际有效占用时间应是从指令执行完成到结果写回。当资源发生冲突时,后续的指令刚开始译码,它们实际上并不真正占用物理寄存器的存储空间,此时后续的指令应仍能继续先分配并发射执行。本文的核心思想是将重命名寄存器资源冲突的判断条件从原先的分配即产生占用冲突,变为实际动态结果存储时才算占用冲突,从而降低冲突概率。基于这一原理,本文通过物理寄存器迭代重用的方法,消除处理器因物理寄存器资源冲突导致的流水线停顿。
这种方法通过增加物理寄存器中的指令信息,让每一个物理寄存器被迭代利用为n个物理寄存器,也就是说每一个物理寄存器可以被分配给n条指令。假设物理寄存器的个数为m,物理寄存器迭代使用的次数为n,理论上能够分配到物理寄存器的指令数将为n×m条,只要指令发射队列的容量足够大,这n×m条指令都将被译码并写入指令发射队列等待发射。如图1所示,假设指令x的目的寄存器r0被映射为物理寄存器PR1,随着程序的执行,最后指令z的目的寄存器被映射为PRm。那么当下一条指令y进入译码段时,迭代重用方法因为重用PR1的存储空间,将继续为指令y分配物理寄存器,从而避免了传统方法下的流水线停顿。
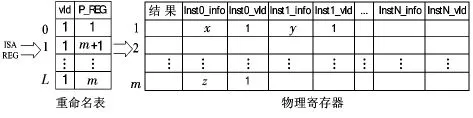
图1 重命名映射表与物理寄存器结构Fig 1 Renaming table and physical register architecture
由于指令的乱序发射和执行,物理寄存器迭代重用的方法还必须解决2个特殊情况。如图表1所示,指令x先于y执行,物理寄存器PR1被分配给指令x和y共用,在一般情况下指令x将在y之前完成并写回ISA寄存器,而当指令y完成时物理寄存器若已经释放,指令x和y的写回都不会出现错误。但是如果x是一条长延迟的指令,那么指令y将有可能先于x完成,将结果写入PR1,并更新指令发射队列中的相关性信息。因此,等到指令x完成时,指令x的执行结果将覆盖同样存储在PR1的指令y的执行结果,而当指令y写回时,写入ISA寄存器的值为指令x的结果,程序执行出现错误。另一种情况是虽然指令x在指令y之前完成,但是,如果在指令x未写回之前指令y也完成了,那么指令x的结果将被指令y所覆盖,于是造成指令x的写回错误。
为了解决这些问题,本文在指令发射队列中增加了物理寄存器共用的相关性信息,在指令分配物理寄存器并写入指令发射队列的同时,检查被分配的物理寄存器是否已经被先前的指令分配,如果存在,则将物理寄存器的相关性信息写入指令队列的表项,表示该指令与之前的指令共用同一个物理寄存器,这个相关性将在指令结果写回时解除。当存在物理寄存器相关性的指令从指令发射队列发射时,指令发射队列将保存该指令的所有信息,直到指令执行完成时再一次检查物理寄存器的相关性信息,如果此时相关性已经解除,指令结果被写入对应的物理寄存器,并将该指令从指令队列中释放。相反如果此时相关性未解除,说明该物理寄存器仍然被更老的指令所占用,因此,指令结果不能写入该物理寄存器,指令必须重新发射执行,这样就保证了所有存储在物理寄存器中的指令结果在写回之前都不会被其他指令覆盖。结合图1和图2分析,指令x和指令y占用的物理寄存器均为PR1,因此,当指令y写入指令发射队列时,将更新PR—dep和PR—RDY域,表示指令 y同指令 x具有物理寄存器的相关性,这个相关性将在指令x写回ISA寄存器时解除。

表2 指令发射队列结构Tab 2 Architecture of instruction issue queue
通过以上的分析知道,只要存在物理寄存器的结构冲突,使用物理寄存器迭代重用方法的性能都将好于传统方法。相对于两级映射的方法,迭代重用方法不需要管理两级映射表,不会增加硬件设计的复杂度。
3 实验结果与分析
本文基于CSKY嵌入式处理器执行内核的模型对物理寄存器迭代重用的方法进行实验分析。为了尽量排除因为处理器其他模块造成的性能影响,整个处理器模型假设所有的指令都取自指令cache,所有的跳转预测都能预测正确,指令发射队列和重排序缓存的资源保证充足,在物理寄存器发生结构冲突之前不会因为其他的资源冲突造成性能损失。
通过对迭代重用方法中迭代次数n的实验研究发现,当迭代次数两次之后,在拥有相同的物理寄存器数量的条件下,处理器的性能不再有大的提升。这是因为虽然可以分配到物理寄存器的指令数量增加了,但是如果迭代次数过大,由于指令发射队列的资源有限,同样会造成指令发射队列的结构冲突,后续的指令即使能分配到物理寄存器却同样会因为指令发射队列已满而停留在指令译码阶段,多次迭代并不能体现出其优势,因此,在实验中选择2次迭代重用。
同时使用powerstone中的8个测试程序(blit,crc,des,engine,g3fax,jpeg,pocsag,ucbqsort)作为基准程序对传统的寄存器重命名方法和物理寄存器迭代重用的方法进行测试,统计出测试程序的指令数和每种方法下执行完测试程序需要的周期数,并计算出处理器执行各个测试程序的IPC值,最后使用IPC的平均值作为处理器性能的评价标准。
通过理论分析可知,当PR—NUM增加到64个时,处理器将不会再由于物理寄存器的结构冲突而造成性能损失,此时2种方法的IPC均达到极限值。从实验结果得到,PR—NUM 为64个时,IPC值为2.07。
图1中,CONV_IPC和REUSE_IPC分别代表传统方法和迭代重用方法的性能。
通过对图3中传统方法性能分析可以看到:对于传统寄存器重命名方法,当物理寄存器的个数达到44个时,IPC值约等于2,已经接近极限性能。在此之后,物理寄存器数量的增加并不能在很大程度上提高处理器的性能,几乎达到瓶颈。因此,综合成本、功耗、面积、性能等方面的考虑,处理器物理寄存器数量的最优解为44个。
对于图2中迭代重用方法性能分析发现,当PR—NUM达到20个之后,处理器的性能提升开始变得平缓。每增加4个寄存器,IPC增量几乎不到 5%。当 PR—NUM达到32个时,IPC值将达到2.0。因此,要达到传统寄存器重命名方法物理寄存器数量最优解时相同的性能,对于迭代重用寄存器重命名方法,其物理寄存器数量则为32个,相对于传统的重命名方法,节省了物理寄存器27.3%的资源,相比两级映射方法节省26%[4]的资源略好。
从2种方法的分析看到:如果物理寄存器的数量未达到最理想时,在具有相同物理寄存器数量的条件下,物理寄存器迭代重用的方法的性能都将优于传统方法,而物理寄存器数量越少,物理寄存器迭代重用方法的优势就越大。这是因为当物理寄存器数量越少时,处理器因为物理寄存器的结构冲突的概率越高,所造成的性能损失也就越大,而物理寄存器迭代重用方法则在很大程度上缓解了这样的结构冲突造成的性能损失。
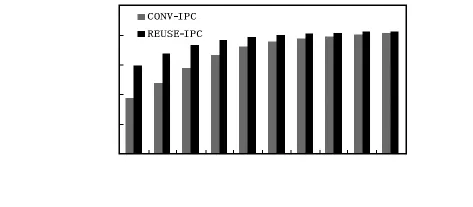
图2 传统方法与迭代重用方法性能比较Fig 2 Performance comparison between the conventional method and the iteratively reuse method
4 结论
本文通过研究传统寄存器重命名方法存在的物理寄存器占用时间过长的缺点,提出了一种物理寄存器迭代重用重命名方法。这种方法将通过缩短物理寄存器使用的时间,通过在物理寄存器中增加有限的指令信息和指令间的物理寄存器共用的相关性信息,迭代重用物理寄存器的存储空间,提高了物理寄存器的利用效率,减小了重命名寄存器的资源冲突。
[1]Sima D.The design space of register renaming techniques[J].IEEE Micro,2000,20(5):70-83.
[2]Farkas K I,Jouppi N P,Chow P.Register file design considerations in dynamically scheduled processors[C]∥The Second International Symposium on High-Performance Computer Architecture,1996:40-51.
[3]Lipasti M H,Mestan B R,Gunadi E.Physical register inlining[C]∥Proceedings of the31st Annual International Symposium on Computer Architecture,2004:325-335.
[4]Monreal T,Gonzalez A,Valero M,et al.Delaying physical register allocation through virtual-physical registers[C]∥Proceedings of the 32nd International Symposium on Microarchitecture,1999:186-192.
[5]Gao Song.Reducing register pressure through LAER algorithm[C]∥27th Australasian Computer Science Conference,2004:55-64.
[6]Balasubramonian R,Dwarkadas S,Albonesi D H.Reducing the compIexity of the register fiIe in dynamic superscalar processors[C]∥ Proceedings of the 34th IEEE/ACM International Symposium on Microarchitecture,Austin,2001:237-248.
[7]Smith JE,Sohi G S.The microarchitecture of superscalar processors[C]∥Proceedings of the IEEE,1995:1609-1624.
[8]Bishop B,Kelliher T P,Irwin M J.The design of a register renaming unit[C]∥Proceedings of the Ninth Great Lakes Symposium on VLSI,1999:34-37.
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
电脑报(2020年20期)2020-06-30 14:33:35
电脑报(2020年11期)2020-06-30 14:32:35
计算机应用(2020年5期)2020-06-07 07:06:44
电脑爱好者(2020年1期)2020-04-28 12:25:29
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
中国资源综合利用(2016年9期)2016-01-22 08:35:22
自动化博览(2014年6期)2014-02-28 22:32:05
电脑迷(2012年16期)2012-04-29 00:44:03
