
基于加权信息熵相似性的协同过滤算法
2012-12-03 01:22:58刘文龙张桂芸朱蔷蔷
郑州大学学报(工学版) 2012年5期
刘文龙,张桂芸,陈 喆,朱蔷蔷
(1.天津师范大学 计算机与信息工程学院,天津300387;2.天津师范大学 城市与环境科学学院,天津300387)
0 引言
互联网技术的快速发展使我们进入了信息爆炸的时代[1],用户需要处理大量毫无意义的信息和垃圾数据.个性化推荐系统是一种解决信息过载问题的工具,而协同过滤技术是推荐系统中最为成功的技术之一,尤其是在电子商务领域里的应用[2].它是基于这样一种假设:兴趣爱好相似的用户对相同项目的评价相似.实现协同过滤技术时,依据所建立模型的种类,可以分为基于用户的协同过滤和基于项目的协同过滤[3].由于在实际应用中,项目数量更加稳定,并往往远低于用户数量,因此,基于项目的协同过滤方法更为常用[4].它的大体步骤如下:①收集项目信息,如用户的浏览购买和评价记录;②根据收集的信息计算项目的K邻近集合;③通过K邻近集合进行分析计算产生对目标用户的推荐.作者选择基于项目的协同过滤算法对实验结果进行分析验证.
由上面介绍的协同过滤技术步骤可以看出,相似性计算是协同过滤技术的核心.传统的相似度计算方法有余弦相似性(Cosine)[5]、Pearson相似相关 系 数[5]、修 正 的 余 弦 相 似 性[5]、Spear man相似性.其中,Pearson相似相关系数是最为常用的相似度计算方法,Pearson相关系数用于衡量两个向量之间的线性关系.设项目i和项目j共同评分的用户集合为Uij,利用Pearson相关系数得到两者相似性为Si m(i,j)
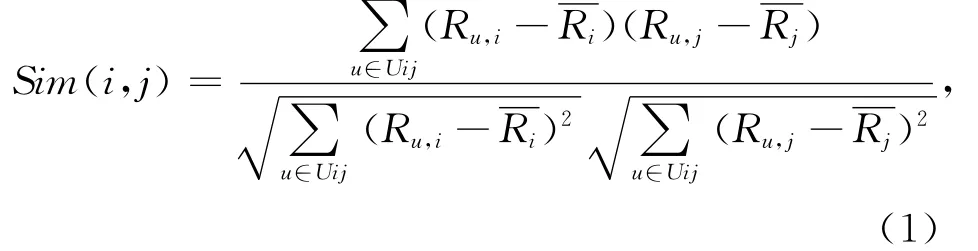
式中:Ru,i,Ru,j分别为用户u 对项目i和j的评
1 基于加权信息熵的相似度计算方法NNWD
1.1 算法的提出
传统的相似度计算方法在协同过滤技术中存在一定弊端,如:①在数据高维稀疏的情况下,用户之间关注圈交集(共同评分项目)的规模大多偏小且不一致,传统的相似性度量方法容易过分地夸大或者缩小用户间的真实相似性[6];②受数据稀疏等影响,推荐精度较低[6];③Pearson相关系数必须满足数据之间的线性关系以及残差相互独立且均值为0等假设[6].当这些条件不满足时,其计算准确度将会降低.
例如对于项目I1和I2,首先找出I1和I2共同评分的用户评分,I1(2,1,2,1)和I2(5,4,5,4),用Pearson相关系数计算I1与I2的相似性Si m(I1,I2)=1,完全正相关,相似度最高,而实际上I1的评分普遍偏低,I2的评分普遍偏高,他们的相似度没有那么高.对于I3(4,5,4,5)和I2(5,4,5,4),Si m(I2,I3)=-1,完全负相关,相似度最低,而I3与I2的普遍评分都比较高,他们的相似度没有那么低.对于判断I1(2,1,2,1)与I4(2,1,2,2),I1(2,1,2,1)与I5(2)谁更相似时,由于I1与I5只有一个项目评分一样,用Pearson相关系数计算Si m(I1,I5)=1,Si m(I1,I4)=0.5774,而I1与I4有3个项目评分一致,它们相似度应该更高.对于某些项目的评分,像I(1,1,1,1)和I(5,5,5,5),用传统的相似度计算方法无法准确计算它们之间的相似度.
1.2 NN WD算法设计
信息熵是信息论中用于度量信息混乱程度的一个概念.信息越混乱,信息熵越大.对于给定的样本集X,它的信息熵公式为

式中:N为X 中分类的数量;p(xi)为X中第i类元素出现的概率.将信息熵用于项目之间相似度的计算,两个项目之间评分差异的信息熵越大,表示两个项目差异越混乱,相似度也就越低.基于信息熵的相似度计算步骤如下:
(1)假设项目I1和I2共同评分的用户集合为U={u1,u2,…,un},I1和I2的共同评分为I1=(Ru1,I1,Ru2,I1,Ru3,I1,…,Run,I1)和 I2= (Ru1,I2,Ru2,I2,Ru3,I2,…,Run,I2),I1和 I2的 评 分 差 异 度D(I1,I2)定义为
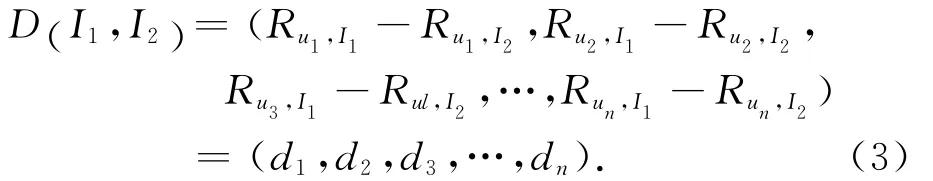
(2)根据公式(2),计算差异度的信息熵为

这里N表示di的种类数,极端情况下若di全都相同,则N=1.考虑到评分差异对相似度的影响,越大,相似度越低.所以计算信息熵时,加入权重更加合理.同时两个项目拥有的共同评价数n也会对相似度产生影响,n越大,相似度越大,所以加入1/n作为权重.新的加权差异信息熵的计算公式为

式中:n为项目I1和I2的共同评分集合大小;di为第i项评分的差值;Ni为di在评分差异度集合D中出现的次数.由公式可知,NWD(I1,I2)取值范围为0到+∞,NWD(I1,I2)越大相似度越低.
(3)将NWD(I1,I2)归一化到 0,[]1由于NWD(I1,I2)越大相似度越低,所以采用如下归一化方法[6]
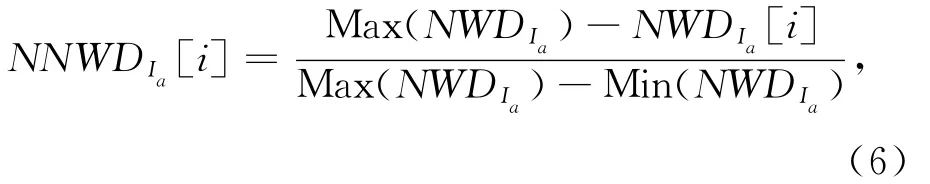
其中 Max(NWDIa)表示NN WDIa集合中最大值;Min(NWDIa)表示NN WDIa集合中最小值;NN WDIa就是归一化之后的相似度,取值范围为0到1,值越大,项目间的相似度越高.
NNWD(Nor malized New Weighted Differences)算法是利用两个项目之间的差异,将项目间共同评分的交集大小和差异大小作为权值加入到差异信息熵公式去,最后进行归一化处理,形成了归一化的新加权差异信息熵(NN WD)算法.
2 数据实验及结果分析
2.1 实验数据集
实 验 采 用 Movie Lens 站 点 (http://movielens.u mn.edu)的实验数据,共汇总了用户943个,项目(影片)1 682个,以及用户对影片产生的100 000条评分记录,数据集稀疏度为1-100 000/(943×1 682)≈0.93 695[7],非常稀疏.用户评分从1到5五个等级.数据集按80%和20%划分成训练集和测试集.
2.2 预测评分和度量方法
将相似性最高的若干项目作为目标项目Ia的邻居集合M={I1,I2,…,Ik},其中Ia∉M,集合M中的项目按照与Ia相似度从高到低排列.根据K个最相似邻居预测目标用户u对项目Ia的评分,公式为[8]:
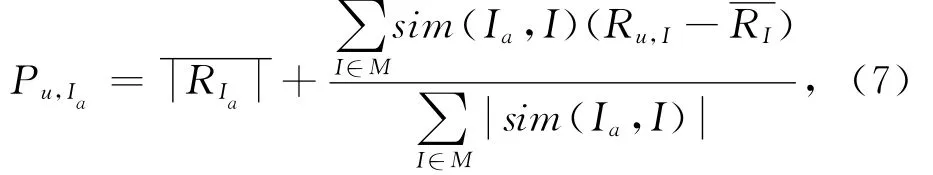
式中:Ru,I为用户u对I的评分;和RI为Ia和I的平均评分;sim(Ia,I)为Ia和I的相似度.
平均绝对误差(MAE)是最常用的用于统计测试集精准度的度量方法[9].设用户u对项目的预测值集合为{p1,p2,…,pn},用户u的实际评分集合为{q1,q2,…,qn},平均绝对误差 MAE 定义为[10]
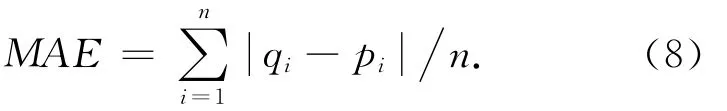
2.3 实验结果及分析
取测试集中10个项目来预测目标用户对它们的评分.分别取最邻近集合大小K为10到60,步长为10,在同一数据环境下,与基于余弦相似性的协同过滤、基于Pearson相似性的协同过滤、基于Spear man相似性的协同过滤进行比较.最终结果如图1所示,可以看出基于信息熵的相似度计算方法一定程度上优于其它方法.

图1 不同的相似度计算方法产生的结果Fig.1 The result of different similarity calculation methods
进而计算当K=70,80,90时,用NN WD方法的 MAE值分别为0.5741,0.5712和0.5665.
3 结论
作者将信息论中的信息熵理论应用到协同过滤算法的相似度计算当中,又考虑到不同的差异度对相似性的影响,对信息熵计算方法进行相应的加权.运用基于项目相似性的协同过滤算法进行试验比较,相对于传统的方法提高了预测精度.
[1] 刘建国,周涛,王秉宏.个性化推荐系统的研究进[J].自然科学进展,2009,19(1):1-14.
[2] 许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[3] 李涛.推荐系统中若干关键问题研究[D].南京:南京航空航天大学,2009.
[4] 罗辛,欧阳元新,熊璋,等.通过相似度支持度优化基于K近邻的协同过滤算法[J].计算机学报,2010,33(8):1437-1445.
[5] PANG Huan-li,ZHOU Lian-zhe,LIU Hai-mei.Personalization Portal System Based on Collaborative Filtering Algorith m[A].Inter national Conference on Co mputer,Mechatronics,Contr ol and Electronic Engineering(CMCE)[C].Changchun,JL,China:IEEE Industrial Electronics Society,2010:383-386.
[6] 夏培勇.个性化推荐技术中的协同过滤算法研究[D].青岛:中国海洋大学,2011.
[7] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[8] 吴月萍,郑建国.协同过滤推荐算法[J].计算机工程与设计,2011,32(09):3019-3021.
[9] 黄国言,李有超,高建培,等.基于项目属性的用户聚类协同过滤推荐算法[J].计算机工程与设计,2010,31(5):1038-1041.
[10]孙小华.协同过滤系统的稀疏性与冷启动问题研究[D].浙江:浙江大学,2005.
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
中学生数理化·八年级物理人教版(2022年5期)2022-06-05 06:57:38
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
河北画报(2020年8期)2020-10-27 02:54:20
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
现代工业经济和信息化(2016年2期)2016-05-17 05:34:16
池州学院学报(2015年3期)2016-01-05 01:13:00
中国医学影像学杂志(2015年9期)2015-12-15 11:03:26
