
基于Unicode编码技术的地名生僻字库研究
2012-11-27 06:57:08江
地理空间信息 2012年3期
江
(福建省基础地理信息中心,福建福州350003)
基于Unicode编码技术的地名生僻字库研究
(福建省基础地理信息中心,福建福州350003)
目前数字线划图及地名数据库内存在着大量未规范表示的生僻汉字,严重影响了地理信息数据开发应用的准确性和规范性。介绍了运用Opentype字体技术和Unicode编码方法制作生僻字库的一种快捷的技术手段,通过该方法整理出一个调用方便、应用效果好的地名生僻字库。
地名;生僻字;Opentype;Unicode

1 技术方法
目前生僻字库的制作方法多种多样,有自主研发字库制作工具的,有利用系统自带造字工具制作单字应用的,也有采集生僻字栅格图片直接应用的,各种方法各有特色。经过对相关资料的收集研究,本文运用Opentype字体技术和Unicode编码方法,利用现有常用字体字库工具制作生僻字库,此种方法具有方法简便、字符编码兼容性好、成果调用便利等特点,能适应现有一般性地理信息数据应用的需要。
1.1 字库及字体
1.1.1 TTF字体存储格式
地名生僻字库采用的是TrueType字体存储格式。TTF(TrueTypeFont)是Apple公司和M icrosoft公司共同推出的字体文件格式,目前已经成为最常用的一种字体文件表示方式。TrueType字库是采用曲线方式描述字体轮廓,因此都可以输出很高质量的字形。TrueType字体是Windows操作系统使用的唯一字体标准。TrueType字体作为一种矢量字体,无论是在屏幕上查看还是打印,都能做到几乎无损使用,质量非常优秀,其特点是由曲线构成字体轮廓,对曲线进行填充,制成各种颜色和效果,可以制作特殊效果字体,字款丰富,因此是适用范围非常广的一种字体。
1.1.2 TTF格式字体的优点
1)TrueType最大的特点就是它是一种由数学模式来进行定义的基于轮廓技术的字体,这使它保证了屏幕与打印输出的一致性。这种字体和矢量字体一样可以随意缩放、旋转而不会出现锯齿,基本避免了点阵字在大字号应用时的缺点。
2)TTF格式的字体安装方便,只需要将制作完成的TTF文件安装到操作系统所在的Windows目录下的FONTS目录里面就可以在各类支持TTF格式字体的应用软件中快速调用。
《信号与系统》课程及《数字信号处理》课程分别涉及到连续信号及离散信号的卷积运算。由于卷积这一种比较特殊的运算形式,仅从原理上讲解,学生理解起来比较困难,如何让学生准确理解这种运算,一直以来是广大相关专业高校教师关注和研究的热点[3~9]。
3)TTF字体可以使用Unicode编码或国标GB系列编码,制作的生僻字可以通过Unicode码、GBK码或者内码输入法实现直接键盘输入,调用十分便捷。
1.2 Unicode字符编码
国际标准组织于1984年4月成立 ISO/IEC JTC1/ SC2/WG2工作组,针对各国文字、符号进行统一性编码。国际标准ISO10646定义了通用字符集 (Universal Character Set,UCS)。Unicode又被称为统一码、万国码、单一码,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode字符编码作为目前国际上较通用的一种编码方式,大多数的操作系统和软件对于Unicode码都支持。在前期对于采用Unicode字符编码制作的试验字在多种制图和数据生产软件中的试用未发现问题。为了提高生僻字库的兼容性,本文所述地名生僻字库制作采用Unicode字符编码。
1.3 字库文件与编码段的选择
1.3.1 字库文件
目前常用的地理信息系统数据生产和制图软件一般都可以调用Windows的FONTS字体集里的各类字体,但是每种地理信息系统软件对数据的管理方式不同,很多软件都采用分层分地物类的方式,在编辑注记内容时,有时会遇到一个图层内的注记只能定义一种字体的情况,因此,在制作生僻字库文件时可以让一个字体文件的字符集比较完整,也就是说一个字体文件内既包括原有的常用汉字,又包括我们需要的生僻字,这样在应用中定义字体类型时,只需要将字体定义成含有生僻字的字体,同时还不影响其他同一字体常用汉字的显示和使用。经过测试,生僻字库采用在原有字体基础上重新构建字体文件的方式是一种可行的解决办法,字库文件存放于FONTS字体集里,使用时直接调用。
1.3.2 编码段的选择
目前常用的几种使用Unicode码的汉字字体所调用的编码基本在“4E00-9FBF:CJK统一表意符号 (CJK Unified Ideographs)”范围。由于现有的常用汉字体中,除了已经调用到的Unicode编码外,其他编码区段并未调用,经过项目前期测试的实际情况,地名生僻字库采用 Unicode定义的自由使用编码区域制作生僻字。选择这一编码段的依据主要为:
1)Unicode编码规则中定义的一般自由使用区域为“E000-F8FF:自由使用区域(PrivateUseZone)”,这个区段中有6400个编码位,完全满足一般生僻字制作使用。
2)自由使用区域 (Private Use Zone)制作新字是遵循Unicode编码的规则标准。经过测试,在这一区域制作的生僻字在目前常用的制图软件或数据生产软件都能成功调用。
3)在使用自由使用区域 (Private Use Zone)制作生僻字时,不改动原有字体内的汉字集,即在原有字符集中添加编码段制作新字。这种方式的优点在于,今后使用生僻字库时,可以采用较灵活的处理生僻字的办法,不会影响其他常用汉字的显示和使用。
1.4 字体
现有的字体种类繁多,包括各式各样的商业字体。生僻字字库首先需要实现目前常用的几种中文字体的制作,以满足数据生产和地名表达时的使用需求。有特殊或数据扩展应用需求时,可以专门制作一些生僻字的商业艺术字体。在生僻字库的字体制作方法上可以用有衬线字体 (Serif)与无衬线体 (sans serif)来区分。有衬线字体制作时注重各笔画的粗细比、笔画末端的修饰,制作难度要高一些;无衬线字体由于其笔画的粗细差不多,没有额外的修饰,制作相对容易。
2 字符采集
2.1 采集方法
目前字符的采集方法多种多样,较传统的方法是扫描原版字样,数字化采集字模。这种方法通过扫描仪和图形处理软件从原始栅格字样中获取字符的矢量轮廓再调整修改,最后使用造字软件制作成字。这种方法的缺点是生产周期较长,字模采集的过程规范化较难控制,后期处理的难度较大等,并不适合地名生僻字库快捷生产的需求。经过相关资料收集和前期对多种造字方法的试验,本文采用直接对已有字体再加工的方法进行生僻字字符的采集。也就是说,由于我们要做的生僻字的组成部件大部分是 Unicode中已有的,所以可以直接用已有的字体通过软件处理,取用原始字体中已有汉字的偏旁部首,经过必要的拆解、缩放、拉伸等调整后进行组合拼接,最终得到我们需要的生僻字。
2.2 规范采集
经过对相关资料的收集整理,我们没有找到现行的关于字体形状的相关规定可供参考,而生僻字制作其实就是一个生成新字的过程,也是需要造出的新字美观、统一、规范。考虑到此次生僻字制作是在各个现成的字体基础上完成的,因此在具体作业过程中,我们以这些现成的原始字体的字形为标准,制作出的新字在字间距、字高、字宽、笔画的习惯等各方面都应与原始字体相一致。
2.3 组字方法
通过在字库制作过程中的经验积累,我们总结形成以下通用的组字方法:直接拼接法、取接近字符调整组合法、取原始字修整组合法、接近字笔画组合法等等。针对生僻字不同的结构,不同的复杂度,可以采用不同的组字方法,最后达到成品字的整体均衡、字形饱满,保证了制作出的生僻字与原字体的笔画形状、字体特征相一致(如图1所示)。
3 应用实例
基于Unicode编码强大的兼容性,地名生僻字库在多种软件中都实现了成功调用,包括了目前流行的多种地理信息系统软件,如ArcMap、Geoway等。由于地名生僻字库具有通用性好,成果调用简便等特点,目前已尝试应用于地理信息软件平台和多个实际作业工作中(如图2-图5所示)。
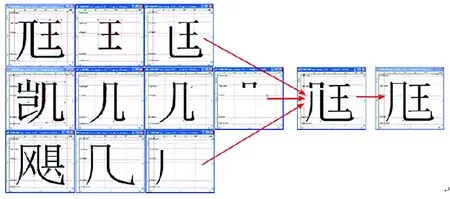
图1 接近字笔画组合法
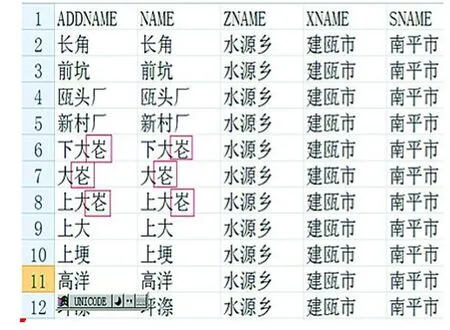
图2 应用于地名地址库编制

图3 应用于地形图符号化(AutoCAD)
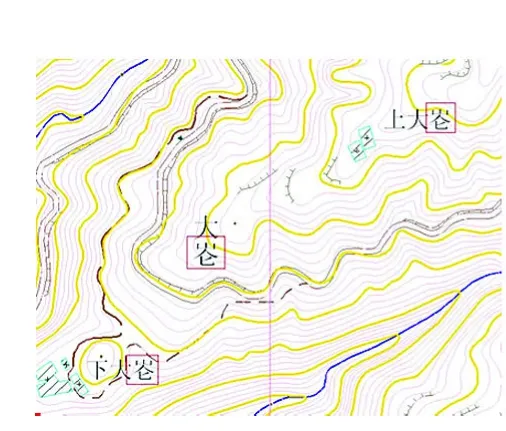
图4 应用于DLG数据编绘(Geoway)

图5 应用于地理信息软件平台(ArcMap)
4 结 语
地名生僻字库的编制完成需要建立在地名生僻字收集编录的基础上,完整规范的字符收录工作才能让生僻字库具有真正的实用价值和开发意义。采用Unicode编码技术的地名生僻字库实现了在通用操作系统字体集中快捷地安装和调用,极大地扩展了字库的通用性和兼容性,便捷的采集方法和基于Unicode编码的特性使其成功地应用于各类地理信息系统软件中,实现了对现代地理信息数据应用的有力支持。
[1] 商瑶玲,张元杰,张义,等.国家基础地理信息地名数据更新软件系统设计与研发[J].测绘科学,2008(2):96-97,54
[2] 胡群英,王金霞,方丽.中文字库及其在测绘生产中的应用分析[J].信息技术与标准化,2009(04):50-52,64
[3] 白毅,易军凯.基于编码的生僻汉字输入方法理论与测试研究[J].北京化工大学学报,2007(1):21-24
[4] 阚映红.地图数据库建立和应用过程中生僻汉字的处理[J].测绘学院学报,2000(01):42-45
[5] 徐洁.基于OpenType格式的国际音标符号和语音古籍生僻字数字化的字体设计[D].上海:上海师范大学,2010
[6] 唐小新.基于Unicode字符集数据迁移的设计与实现[J].企业科技与发展,2011(17):22-24
[7] 杨文敬.地图数字化过程中的生僻地名问题探讨[J].浙江测绘,2006(1):37-38
[8] 斯·劳格劳.基于Unicode和OpenType字库的MWord的研究[D].呼和浩特:内蒙古大学,2006
Research on Database of Rarely Used Place Names Based on Unicode Encoding Method
by JIANG Min
Currently,the nonstandard usage of rarely used Chinese characters in Digital Line Graphic and Geographical Name Database severely affects the accuracy and normalization of the development and application of geographic data.This paper introduced a convenient technical means,which was based on Opentype font technology and Unicode encoding method,to create a rarely used characters database.This paper also reorganized a convenient and effective database of rarely used place names by way of this means.
place names,rarely used Chinese characters,Opentype,Unicode
2012-04-01
P208
B
1672-4623(2012)03-0121-03
江旻,工程师,主要从事测绘成果加工与研发。
猜你喜欢
科普童话·神秘大侦探(2022年1期)2022-05-31 03:49:58
电脑爱好者(2022年15期)2022-05-30 01:29:23
销售与市场(营销版)(2020年9期)2020-11-25 13:38:24
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
小哥白尼·野生动物画报(2019年12期)2019-02-28 11:46:11
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
电子世界(2018年7期)2018-04-26 08:51:35
学生天地(2017年19期)2017-11-06 01:45:11
作文评点报·低幼版(2015年8期)2015-05-30 10:48:04
