
基于Hadoop框架的TF-IDF算法改进
2012-11-24 02:17李彬
网络安全与数据管理 2012年7期
李彬
(暨南大学 信息科学技术学院计算机科学系,广东 广州 510632)
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于资讯检索与文本挖掘的常用加权技术[1],用来评估单词对于一个文件集或一个语料库中的其中一份文件的重要程度。单词的重要性随着其在文件中出现的次数成正比增加,但同时会随着其在语料库中出现的频率成反比下降。TF-IDF算法的各种形式常被搜索引擎、Web数据挖掘、文本分类及相似度计算等各种应用中,而这些应用往往是以处理海量数据的输入为背景。因此,如何在海量数据中快速有效地计算出TF-IDF具有重要意义。
1 TF-IDF算法原理
在一份给定的文件里,词频 TF(Term Frequency)指的是某一个给定的词语在该文件中出现的次数。对于在某一特定文件里的词语ti来说,它的重要性可表示为:

式中,ni,j是该词在文件 dj中的出现次数,而分母则是在文件dj中所有字词的出现次数之和。
逆向文件频率 IDF(Inverse Document Frequency)是一个词语普遍重要性的度量。某一特定词语的IDF,由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到:

式中,|D|表示语料库 中的文件总数,|{j:ti∈dj}|表 示包 含词语ti的文件数目。
在式(1)、式(2)的基础上,可得单词的权重计算公式[2]:

某一特定文件内的高词语频率以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TFIDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
2 Hadoop简介
Hadoop是一个开源的可运行于大规模集群上的分布式并行编程框架,它主要由分布式文件系统HDFS和MapReduce计算模型构成。HDFS实现了文件的分布式存储,它是MapReduce计算的数据载体[3-4]。MapReduce计算模型的核心是Map和Reduce两个函数,这两个函数由用户负责实现,功能是按一定的映射规则将输入的<key,value>对转换成另一个或一批<key,value>对输出[4-6]。HDFS与 MapReduce的关系如图 1所示。
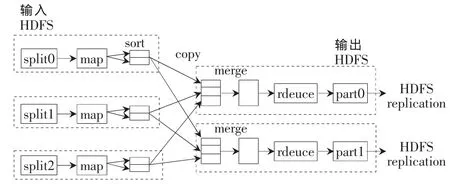
图1 HDFS与MapReduce的关系
3 Hadoop框架下的TF-IDF算法研究与实现
Hadoop分布式计算的核心思想是分割任务,并行运行。从TF-IDF的计算公式可以看出,它非常适合用分布式计算求解。单词词频TF只与它所在文档的单词总数及它在此文档出现的次数有关。因此,可以通过分割数据,并行统计文档中的单词词频TF,加快计算速度。得到单词词频TF后,单词权重TF-IDF的计算取决于包含此单词的文档个数(因为文档总数是一个常量)。因此,只要能确定包含此单词的文档个数,即能以并行计算的方式实现TF-IDF的求解。本文通过设计3次Map、Reduce过程实现TF-IDF的计算。
3.1 统计每份文档中单词的出现次数
原始数据经过分片后传给Map函数。在Map中使用正则表达式识别单词,并以键值对<word#documentName,1>的形式写入中间结果,传入Reduce函数处理。在Reduce中计算单词个数,并将结果输出到临时文件tempFile1中以作为下一步MapReduce计算的输入。输出结果是以<word#documentName>为键、<n>为值,n表示单词word在文档documentName中出现次数。函数设计如下:

此步计算得出单词在文档中的出现次数。
3.2 统计文档单词词频TF
上一步所得的临时文件tmpFile1作为本次Map函数的输入。在Map函数中,重新组织键值对 (以documentName为键、<word=n>为值)以便于下一步的Reduce计算。Reduce中,为计算每份文档单词总数,只需累加每份文档的单词数即可。输出结果存入临时文件tempFile2中以作为下一步MapReduce计算TF-IDF的输入。函数设计如下:

此步计算得出每份文档单词词频TF。
3.3 计算TF-IDF
以上一步所得的临时文件tmpFile2作为Map函数的输入。在Map函数中,重新组织键值对(以单词word为键、<documentName=n/N>为值)以便于计算单词word在整个文档集中出现的次数。Reduce函数中,统计出单词word在文档集中出现个数d、整个文档集个数D,然后按公式 TF-IDF=n/N×log(D/d)计算单词的 TF-IDF值。函数设计如下:

此步计算得出文档集中每份文档的单词TF-IDF值。
计算TF-IDF的整个处理流程如图2所示。
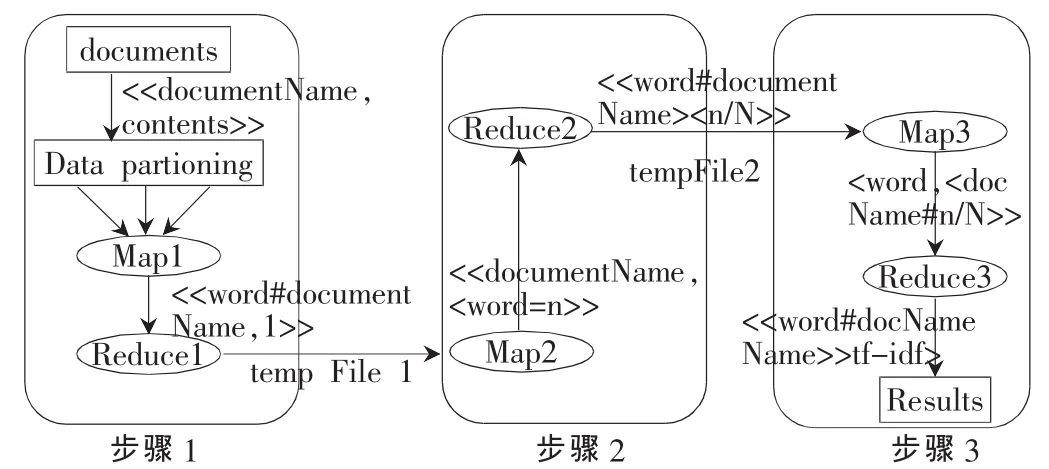
图2 计算TF-IDF的整个处理流程
4 实验与分析
(1)实 验 数 据 获 取 :从 (http://www.sogou.com/labs/)提供的文本分类语料库中选取了20万篇文档作为实验语料库。
(2)数据 预 处 理 :使 用开源中文分词工具IKAnalyzer对文本进行分词处理,同时去掉停用词。维护过多的小文件会降低Hadoop效率,因此需将数据集归档处理。整理后的测试数据如表1所示。
(3)Hadoop群集的搭建:使用了 5台电脑构建了一个群集,其中一台作为主节点,以负责作业调度及文件空间的管理;其余的作为从节点用作TF-IDFSS的计算以及文件的存储。
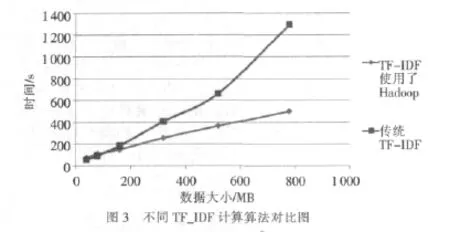
(4)实验结果:将使用了Map/Reducer框架的TD_IDF算法与传统的TF-IDF计算算法进行对比结果如图3所示。传统的TF-IDF计算算法只在一台机上运行,且不能以并行和分布式的方式运行。
从图中可以看出,当数据量不大时(<200 MB),传统算法与新算法的差距并不明显。这是因为Hadoop本身的维护与网络传输需要一定的开销。随着数据量的增大,传统方法计算TF-IDF的时间急剧增长,而应用了Hadoop框架的TF-IDF计算方法所需时间只是线性增长,新算法的效率明显高于传统算法。
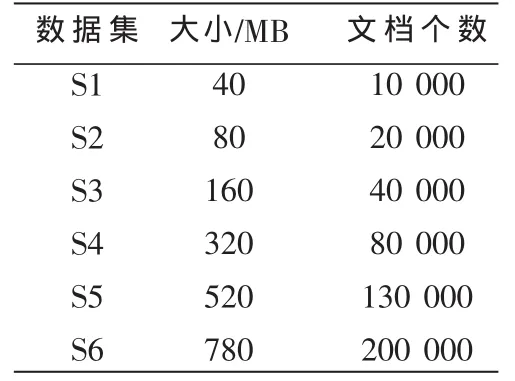
表1 测试数据
本文使用了Hadoop框架提供的服务改进了计算TF-IDF算法的效率。如果仍需要进一步提高算法效率,可以使用序列化文件SequenceFile对输入数据做预处理[7];对Mapper、Reducer的输出做压缩;减少中间文件的生成。此外,还可以通过扩展群集规模、改变群集参数等方式来提高效率。
[1]SALTON G,BUCKLEY C.Term-weighting approaches in automatic text retrieval [J]. Information Processing and Management, 1988, 24(5):513-523.
[2]SALTON G, CLEMENT T Y.On theconstruction of effective vocabularies for information retrieval[C].Proceedings ofthe 1973 Meeting on Programming Languages and Information Retrieval.New York:ACM,1973.
[3]The apache softwar foundation HDFS architecture guide[EB/OL].(2011-11-16)[2011-11-30].Hadoop, http://hadoop.apache.org/hdfs/.do cs/current/index html.
[4]LAMMEL R.Data programmability Team.Google’s MapReduce Programming Model-Revisited[R].Redmond, WA, USA:Microsoft Corp.2007.
[5]Owen O’Malley.Programming with Hadoop’s Map/Reduce[R].ApacheCon EU,2008.
[6]DEAN J, GHEMAWATS.MapReduce: simplifieddata processing on large ousters[C].OSDI’04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, December, 2004.
[7]WHITE T.Hadoop: The definitive guide[M].O’Reilly,2010.
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
天津外国语大学学报(2020年1期)2020-03-25
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
中国修辞(2017年0期)2017-01-31
湖南工业职业技术学院学报(2016年6期)2016-04-17
语言与翻译(2015年4期)2015-07-18
读者·校园版(2015年7期)2015-05-14
图书馆论坛(2014年8期)2014-03-11
