
贝叶斯网在数据挖掘中的应用
2012-11-07 08:40李强徐捷
中国科技信息 2012年13期
李强徐捷
1.国防科技大学电子科学与工程学院,湖南 长沙 410073
2.国防科技大学信息工程研究所,湖南 长沙 410073
贝叶斯网在数据挖掘中的应用
李强1徐捷2
1.国防科技大学电子科学与工程学院,湖南 长沙 410073
2.国防科技大学信息工程研究所,湖南 长沙 410073
贝叶斯网用图形的模式表示变量集合的联合分布,应用于数据挖掘能够将变量之间的潜在依赖关系反映出来。介绍了贝叶斯网,概括了构造贝叶斯网的方法,给出了建网的伪代码,通过一个实例说明了贝叶斯网在数据挖掘中的应用。
贝叶斯网;数据挖掘;贝叶斯学习;贝叶斯推理
贝叶斯网(Bayesian Network),是一种对概率关系的有向图描述,适用于概率性的和不确定性的事物。贝叶斯网的结构蕴含了某些规则,节点之间的依赖关系则蕴含了某些知识。数据挖掘中使用贝叶斯网方法,能够发掘出多层次的、多点的关联关系,具有处理不完整数据和噪声数据的能力,能够挖掘出隐含的知识而且具有良好的可理解性和逻辑性[1]。
1 贝叶斯网
N元随机变量X={X1,X2,…,Xn},其贝叶斯网络模型是一个二元组B={Bs,Bp},其中:
(1)Bs={X,E}表示贝叶斯网络的结构。Bs是一个有向无环图(Directed Acyclic Graph, DAG),X={X1,X2,…,Xn}是结点的集合,每个结点代表一个变量、状态或者属性等实体,记π(xi)为BS中结点的父结点的集合;E是图中结点之间的有向弧的集合,反映结点之间的依赖关系。是贝叶斯网模型的概率分布集合,用于衡量结点之间的依赖关系,其中π(xi)表示结点xi的父节点集合,表示先验知识。贝叶斯网约定任意结点的子节点与非子节点之间是条件独立的,并且满足d-分割[2]的结点都是条件独立的,那么由贝叶斯概率的链规则(chain rule)有:
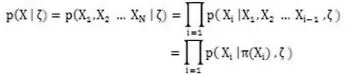

图1 一个简单的贝叶斯网
这种由条件独立性得到的链规则可以将联合分布分解为若干个复杂度较低的概率分布的乘机,使得模型的复杂度降低。例如,假设图1中的变量都是布尔型的,,其中xi表示xi=true,表示xi=false。那么图1中所有变量都取true的联合分布概率可以这样计算:

一般来说,描述图1中8个点组成的联合分布需要28-1=255个局部概率,而在贝叶斯网中,只需要计算21+23+22+21+1+22+1+1=23个局部概率,这就是所谓的条件概率表(CPT)。
2 贝叶斯网的学习
贝叶斯网的学习就是要寻找一种能够按照某种测度最好地与给定实例数据集拟合的网络结构,即寻找一个有向无环图和一个与图中每个结点相关的条件概率表。寻找有向无环图称为网络结构学习,获取条件概率表称为网络参数学习。由于通过网络结构与数据集可以确定参数,故网络结构学习是贝叶斯网络学习的核心。贝叶斯网络结构学习一般可分为两类:基于独立性检测的方法和基于网络质量衡量的方法。
基于独立性检测的方法假设存在一个网络的结构能够完全的表示变量之间的依赖或者独立性关系[3],使用给定的数据集进行统计测试每一个依赖或者独立性关系,其基本步骤为:

基于网络质量衡量的方法也称为基于打分-搜索的方法,其基本思想是为可能的网络结构打分,通过得分衡量网络的质量,选择质量最好的结构。这种方法需要为结构打分的标准和搜索网络结构的方法。常用的打分标准有:贝叶斯标准[4]、MDL[5](最小描述长度)标准、AIC标准和Entropy(熵)标准[6]等。使用穷举法遍历完全结构空间是一个NP难度的问题[7],因此一般使用启发式的搜索算法,常用的有K2算法、爬山法、模拟退火算法、禁忌搜索和遗传算法等。基于网络质量衡量的伪代码如下:

3 贝叶斯网推理
贝叶斯网推理就是在给定一个贝叶斯网模型的情况下,根据已知条件,利用贝叶斯概率中的条件概率的计算方法,计算出查询结点概率[8]。在理论上由联合分布可以推断出任何在贝叶斯网络中人们想知道的概率,根据局部概率分布可以得到联合概率分布。贝叶斯网推理主要有三类问题:由原因推结论的后验概率问题、由结论推出原因的最大后验假设问题(MAP)和提供解释以支持现象的最大可能假设问题(MPE)。
4 贝叶斯网与数据挖掘
贝叶斯网不仅可以表达不确定知识,还能够进行概率推理。其学习算法能够从大量的数据中自动构建网络,非常适合不确定知识的发现。贝叶斯网应用于数据挖掘独特地优势:能挖掘出隐含性的知识,具有良好的逻辑性和可理解性,极大地简化了概率的运算,能够进行因果双向推理。图2是贝叶斯网应用于数据挖掘的基本框架。
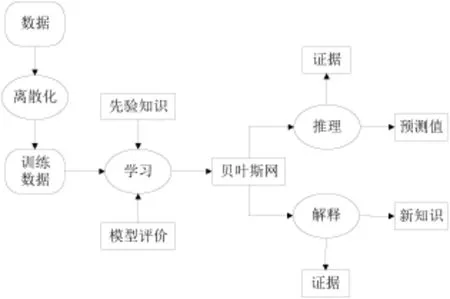
图2 基于贝叶斯网的数据挖掘框架
使用贝叶斯网进行数据挖掘一般按照三步进行:首先确定变量集和变量域,这里要充分利用相关领域的专家知识;然后构建贝叶斯网,确定网络结构和条件概率分布;最后计算查询变量的概率。
为了说明贝叶斯网在数据挖掘中的计算方法,使用来自UCI 的Wisconsin BREAST_CANCER乳腺癌数据集[10]。数据集包含699个实例,每个实例有9个数值型的特征属性和一个类属性。使用这个数据集建立贝叶斯网,挖掘各属性之间的关系,推断肿瘤是良性的(class=0)还是恶性的(class=1)。
针对BREAST_CANCER数据集,李光,张凤斌等使用朴素贝叶斯法和K-Means算法进行了分类挖掘[11],得出的结果如表1中的第2、3行所示。本文在WEKA3.7智能分析环境[9]下使用C4.5决策树算法得到的结果如表1中第4行所示。将以上三种方法作为对比,本文使用贝叶斯网方法进行挖掘。首先将数值型变量离散化,得到如表2所示的结果,接着使用基于MDL评分标准和局部衡量的K2搜索算法进行,得到如图3所示的贝叶斯网结构,经过10重交叉验证,该模型精确度为94.2%。将四种方法得出的结果汇总入表1,可以看出:贝叶斯网方法精度优于朴素贝叶斯算法和K-Means算法,与C4.5算法水平相当,其优势是输出了反映变量依赖关系的网络结构。

表1 结果对比

表2 BREAST_CANCER数据集的属性和值域

图3 由数据集构建的贝叶斯网
从得到的贝叶斯网可以挖掘出一些有用的信息,如属性clump_thickness、cell_ shape_uniformity、bland_chromatin与其他属性依赖关系数量最多,可能是识别肿瘤细胞的重要特征,需要密切关注;没有连线的属性之间不存在依赖关系(如cell_size_ uniformity与bare_nuclei),它们的变化可能是由不同的因素引起的,需要区别研究等,这些信息将为肿瘤细胞状态的推断和病情研究提供辅助。
需要注意的是,同一个问题可能建立起不同的贝叶斯网,但描述的是来自于同一个联合概率分布,这是由于联合概率分布被分解为条件概率分布而产生的。通过机器学习得到的网络中有向边代表依赖关系,因果关系只是依赖关系中的一部分。
5 结语
贝叶斯网是结合概率、统计和图论发展起来的,有坚实的数学基础,是研究复杂系统的不确定性和数据分析的一种有效工具。贝叶斯网应用于数据挖掘,能够发现出数据的内在本质,在许多领域应用并取得了很好地效果,将在数据挖掘领域发挥愈加重要的作用。
[1] 刘伟娜,霍利民,张立国.贝叶斯网络精确推理算法的研究[J].微计算机信息,2006.3-2:92~94
[2] 张连文,郭海鹏.贝叶斯网引论.[M] 北京:科学出版社,2006:67~69
[3] Chen J, Bell D, Liu W.Learning Bayesian networks from data: An efficient approach based on information theory [J].Artificial Intelligence, 2002, 137(1-2), pp.43~90.
[4] David Heckerman.A tutorial on learning Bayesian networks.Technical ReportMSR-TR-95-06, Microsoft Research, 1996.
[5] Suzuki J.Learning Bayesian Belief networks Based on the Minimum Description Length Principle: Basic Properties.IEEE Transactions on fundamentals, 1999, E82-A (9), pp.2237~2245.
[6] Cooper G F, Herskovits E A.A Bayesian method for the induction of probabilistic networks from data[J].Machine Learning, 1992, 9(4), pp.309~347.
[7] Cooper G.Computational complexity of probabilistic inference using Bayesian belief networks.[J].Artificial Intelligence, 1990, 42(2-3), pp.393~405.
[8] 董立岩,苑森淼等.基于预测能力的连续贝叶斯网络结构学习[J].计算机工程与应用,2007,43(9),pp.23~24
[9] Ian H.Witten, Eibe Frank, Mark A.Hall.Data Mining Practical Machine Learning Tools and Techniques.[M] 3rd Edition.2010, pp.262~273
[10] K.P.Bennett, O.L.Mangasarian: "Robust linear programming discrimination of two linearly inseparable sets".[J].Optimization Methods and Software 1, 1992, 23~34 (Gordon & Breach Science Publishers).
[11] 李光,张凤斌.基于树突状细胞算法的分类方法研究[M].电脑知识与技术,2010, 6(31), pp.8798~8800
A
TP391.4
10.3969/j.issn.1001-8972.2012.13.050
李强(1987-),男,硕士研究生 ,研究领域为数据挖掘,信息。
猜你喜欢
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
装备制造技术(2020年3期)2020-12-25
计算机系统应用(2019年9期)2019-09-24
电机与控制学报(2018年9期)2018-05-14
科技视界(2016年19期)2017-05-18
中国工程咨询(2017年3期)2017-01-31
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中国交通信息化(2015年7期)2015-06-06
