
基于遗传算法的形声输入法训练样本生成研究与实现
2012-11-03 06:25:44李锟华段利华桑志强
大理大学学报 2012年4期
李锟华,段利华,桑志强
(大理学院数学与计算机学院,云南大理 671003)
基于遗传算法的形声输入法训练样本生成研究与实现
李锟华,段利华,桑志强
(大理学院数学与计算机学院,云南大理 671003)
在用户利用输入法练习软件学习时,输入法练习软件使用的训练样本设计是否合理,是影响学习好坏的重要因素。讨论以形声编码输入法练习软件训练样本生成作为研究对象,根据用户设定的训练目标,通过遗传算法生成符合训练要求的最优训练样本,来满足用户训练要求。
输入法;训练样本;遗传算法
随着科学技术的不断发展,计算机被广泛应用于人们的生产生活。在我国,计算机应用主要围绕中文信息处理展开,中文信息处理就是通过计算机对汉字的音、形和意等信息进行加工和处理的技术。使用计算机对中文信息处理时,最基础和最重要的一个环节就是把汉字输入到计算机中,转换成内码的过程。如果中文信息没有输入到计算机中转换成内码,就谈不上后期的中文信息处理。
目前,汉字输入到计算机的方法很多,有基于键盘输入的汉字编码方案,有基于模式识别的联机手写识别、脱机手写识别和语音识别等。其中应用得最广泛的是键盘输入法,到2011年为止,国家专利局批准与键盘汉字输入相关的编码方案专利为757个。想要更好地掌握和推广这些键盘输入汉字的编码方案,目前主要存在以下问题:不同的键盘输入方案,编码规则和拆分汉字规则不一致,导致用户不便于记忆和使用。这时就需要汉字输入法练习软件和输入法编码方案设计同步推出,以便于用户利用输入法练习软件快速掌握该种输入法。
在设计输入法练习软件时,设计是否合理,主要看训练样本的生成是否具有目标性和智能性。部分练习软件大都是通过随机的方法产生训练样本,对练习的要求和目标因素不进行考虑,不能更好地为练习者提供个性化的训练样本。本文通过形声汉字编码输入法练习软件样本生成为研究对象,根据用户设定的训练目标,利用遗传算法为形声编码输入法练习软件生成最优化的训练样本。
1 形声汉字编码方案
形声汉字编码方案是一种主要通过汉字笔画和结构之间的关系,以及汉字和笔画部首的读音组合进行汉字编码的方案。
1.1 汉字结构划分 我们把汉字按自然结构划分为两类,一类是两块字,它包含上下结构、左右结构、内外结构3种。如“:类、形”等;另一类为独体字,其特点是不能再次进行拆分的汉字。如:“大、中”等。
1.2 字块笔画的归类 通过汉字的自然结构划分为字块,每个字块都有首笔画和次笔画,如果只有一个笔画,这首笔画和次笔画都用它自身〔1〕。归类后笔画分类如下①首笔画:划分为斜类(包含撇、捺、点、提4种笔画)、横类、竖类(包含竖和折2种笔画)3类;②次笔画:划分为横(提)、竖、撇、点(捺)、单折、复折6种;③两笔画的关系:首笔画和次笔画关系构成交叉型、方框型2种。
1.3 笔画和键盘之间的映射关系 首笔画斜分别对应键盘中的Q至P行、横分别对应键盘中的A至L行、竖分别对应键盘中的Z至M行,次笔画分别对应列及交叉对应Q、A、Z列,方框对应W、S、X列,横对应E、D、C列,竖对应R、F、C列,撇对应T、G、B列,捺对应Y、H、N列,折对应U、J、M列,复折对应I、K、L列,通过首笔定义行,第二笔定义列,在3×8矩阵中确定一个按键位置。
1.4 编码规则 两体字的编码为:编码顺序为(第一体首笔,次笔)+(第二体首笔,次笔)+(第一体拼音首字母)+(汉字拼音首字母)。
单体字的编码规则:顺着笔顺取3组首笔画和次笔划组合+汉字拼音首字母。当组成汉字的编码长度小于4时,在汉字拼音首字母编码后加字母“o”表示结束编码。
2 传统输入法训练样本生成
2.1 随机生成法 用户运行输入法练习软件后,系统统计出练习编码数据库中记录数k,通过随机函数在1至k之间随机选择,选择出记录号后,在数据库中查找对应字符生成训练样本,提供给用户进行练习。该方法随机性因素和不确定因素对训练样本生成影响很大,有时出现常用汉字的训练样本出现概率低,不常用的汉字训练样本出现概率高的现象,不具有智能的特点〔2〕,对训练样本无法控制。
2.2 回溯生成法 在用户进行训练时,设定一个训练要求后,随机选择产生一个训练样本个体,把每个个体状态记录下来,来分析是否满足训练要求,不满足训练要求,就释放该个体,重新进行随机选择出满足训练要求的个体〔3〕。该方法不足之处在于生成训练样本的时间复杂度有时很短,有时很长,甚至有时会出现死机情况,时间复杂度没有办法控制。
针对传统输入法训练样本生成的不足,我们利用遗传算法,来对形声输入法练习软件的训练样本进行生成。
3 基于遗传算法形声输入法训练样本生成
遗传算法是从代表问题可能存在的解集合出发,选择解集合作为一个种群,对该种群进行基因编码,建立基因编码序,形成一定数量的染色体。染色体是基因序作为遗传信息的主要载体,即多个基因的集合组成。第一代种群产生后,按照适者生存和优胜劣汰的原则,根据问题域的适应度函数来选择基因,通过遗传算子对染色体中基因序进行选择、交叉和变异操作,产生出优化了的新种群,然后通过适应度函数对种群进行分析,是否达到预先规定的技术指标,如果达不到指标,继续进化种群,产生下一代新种群,直到求出满足要求的最优化解〔4〕。我们利用遗传算法,对形声编码输入法练习软件的训练样本进行生成。
3.1 目标特征值 在形声编码输入法练习软件中,衡量一个用户掌握该种编码方案的情况,考虑的因素比较多,我们选择其中三个主要的指标①速度:反映每个字符用户训练时该字符的平均速度特征值;②正确率:反映每个字符用户练习时键入该字符的正确率特征值;③常用度:反映每个字符在实际应用中该字符的常用频率特征值。
当速度越快,正确率越高,常用字输入越熟练,则反映用户的练习效果越好。然而速度、正确率和常用度不是编码自身的特性值,而是通过练习编码参加练习时对用户统计得出的特征值,特征值和用户的实际情况有不可分割的联系。首先,我们在学校学生或单位用户中使用练习软件,根据不同学生和用户进行练习,得到每个字符的统计特征值,对训练样本表中特征值进行调整,作为该形声编码初始化特征值,根据遗传算法生成新的训练样本,又提供给学生或单位用户进行练习,经过实际应用证明是可行的。
3.2 遗传算法编码选择 目前常用的有二进制编码、数字编码、灰度编码和字符编码等,编码要求简单明确,但是在选择操作、交叉操作和变异操作中又能够快速精确定位。针对于形声输入法练习软件训练样本的生成,我们直接采用形声汉字数据表中的记录号作为遗传算法的编码,它在数据表中是一个整数,又是关键字字段,它和字符是一对一的对应关系,可以进行快速定位。
3.3 遗传算法适应度函数设计 适应度函数是否合理是能否找到最优解的关键〔5〕。训练样本评价指标体系中最重要的指标为速度(用v表示)、正确率(用r表示)和常用度(用u表示),我们通过这三个指标设计适用度函数。用户定义练习目标值,设定速度(用v′表示)、正确率(用r′表示)和常用率(用u′表示),采用染色体的特征值和目标值之间的差值作为适用度函数(fx),两者之间的差值越小,越符合目标要求,通过最小化问题来实现训练样本的约束模型,表示为:
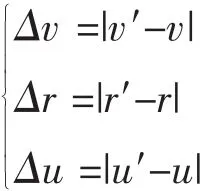
通过约束模型,我们得到形声输入法样本生成的适应性函数为:

其中,0.01是对速度指标调整的系数,(fx)值越小,解集进化度越高,优化度也越高。
3.4 遗传算子设计

3.4.2 交换操作 交换操作主要是进行染色体重新组合,将两个染色体中互相配对的个体按照某种形式实现部分基因个体互换,形成两个新的染色体过程。常用的交叉算子主要包括单点交叉、多点交叉、均匀交叉、算数交叉等。在形声输入法训练样本生成中,我们对于横、竖、斜三种结构的基因个体进行单点交叉,算法思想如下:①在〔0,1〕区间内产生一个随机数R,R小于交换概率Pc;②根据随机数R,在训练样本中确定一个交叉点,把两个基因中交叉点后的个体进行整体交换,产生两个新的训练样本,见图1。
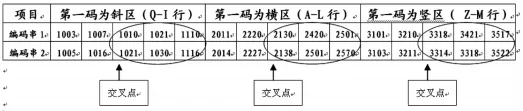
图1 染色体交换操作之前
经过交叉互换后得到新的群体,见图2。
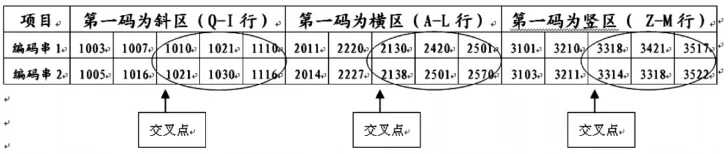
图2 染色体交换操作之后
3.4.3 变异操作 就是将训练样本中染色体编码的某些基因位置上的基因编码,通过随机产生变异点,用其他的等位基因进行替换,从而形成一个新的训练样本。主要的变异算子有:基本位变异、均匀变异、边界变异以及非均匀变异。形声输入法训练样本生成中采用基本位变异法,算法实现如下:①针对训练样本中每个基因,产生一个〔0,1〕范围内的一个随机数Ri;②Ri和Pm进行比较,如果Ri<Pm,则该基因为变异点,用其他的等位基因进行替换,如果Ri≥Pm,则该基因不产生变异。
3.5 实验数据结果与分析 在形声输入法训练样本生成中,我们利用Visual Basic 2005进行代码设计和算法实现,相关数据如下。

图3 染色体初始化数据
3.5.1 实现数据 首先,初始化数据,产生4个染色体组成第一代种群,每个染色体由15个基因组成,见图3。其中c1-c15为产生第一代种群的基因,迭代次数初始化为1,适用函数的染色体值为0.042,0.053,0.057,0.055。
其次,设定遗传算法的参数。迭代次数为20,交叉概率0.4,变异概率为0.4,设置目标速度:60字/分钟,目标正确率为0.8,目标常用程度:0.8,保留染色体精英数:4。点击开始遗传操作,经过20次迭代进化后,生成第21代种群,数据见图4。

图4 第21代种群数据
生成的训练样本,见图5。

图5 训练样本字符
3.5.2 实验结果分析 种群4个染色体经过20次迭代产生新种群的适应性函数返回值,见图6。
从4个染色体经过20次迭代,经过遗传算法的选择操作、交叉操作和变异操作,适应性函数的返回值,见表1。

表1 对比数据表
从实验结果可以看出,种群根据约束条件,经过遗传算法20次迭代进化,数据被优化,取得满足条件的样本。
4 总结
在形声编码输入法练习软件的设计中,通过遗传算法生成符合用户设定目标合理训练样本,提供给用户进行使用,为用户快速掌握该种输入法创造了条件,为汉字编码的学习和推广打下良好的基础。
〔1〕施冰,段利华.基于字块特征的汉字分类方法〔J〕.大理学院学报,2009,8(4):22-23.
〔2〕何振亚.自适应信号处理〔M〕.北京:科学出版社,2002.
〔3〕薛方,苏虞磊.基于改进遗传算法的试卷生成算法研究〔J〕.现代电子技术,2010(6):143-148.
〔4〕肖连,崔杜武.基本遗传算法的试卷生成系统的设计与实现〔J〕.计算机应用,2008,28(5):1362-1364.
〔5〕沈崇圣.遗传算法中常用选择算子在Matlab中的实现〔J〕.上海应用技术学院学报,2003,9(3):200-202.
〔6〕王凌着.智能优化算法及其应用〔M〕.北京:清华大学出版社,2001.
Research for Methods Generating Training Samples about Keyboard Exercise Based on Genetic Algorithm
LI Kunhua,DUAN Lihua,SAN Zhiqiang
(College of Mathematics and Computer,Dali University,Dali,Yunnan 671003,China)
When users learn software with input method,it is an important factor whether the training sample design of input method software is reasonable.In this paper,based on the genetic algorithm,phonetic encoding IM software training generation,as a study sample,is studied to generate the best sample that can meet the training requirements set by users.
input method(IM);training samples;genetic algorithms
TP312[文献标志码]A[文章编号]1672-2345(2012)04-0014-04
云南省教育厅基金项目(07Y41171)
2011-08-15
2012-01-08
李锟华,副教授,主要从事中文信息处理和人工智能技术研究.
(责任编辑 袁 霞)
猜你喜欢
小雪花·初中高分作文(2021年3期)2021-08-27 08:42:22
科技创新与应用(2020年6期)2020-02-29 10:39:27
阅读(教学研究)(2018年2期)2018-05-14 10:31:41
都市家教·上半月(2017年12期)2018-01-19 13:29:25
小学生学习指导(低年级)(2017年12期)2017-11-22 06:22:09
学苑创造·A版(2017年6期)2017-06-23 20:53:37
北京理工大学学报(2016年6期)2016-11-22 11:17:22
中国知识产权(2016年11期)2016-11-11 02:55:06
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
