
智能建模中化工数据的预处理
2012-10-31 03:19李翠英
重庆科技学院学报(自然科学版) 2012年2期
李翠英
(1.重庆大学,重庆 400030;2.重庆科技学院,重庆 401331)
智能建模中化工数据的预处理
李翠英1,2
(1.重庆大学,重庆 400030;2.重庆科技学院,重庆 401331)
阐述智能建模中对化工数据进行预处理的过程,介绍决策变量的选择、数据的采集、数据的去噪、数据的降维等预处理方法。仿真实验显示,数据进行有效的预处理后,其泛化能力强,模型精度有所提高。
数据预处理;3σ准则;五点三次平滑法
基于化工生产过程中高度复杂性和非线性的特点,以神经网络为代表的智能建模方法得到了广泛的应用。而神经网络建模是以样本数据为输入的建模方法,所以样本的数量与质量直接影响建模的效果。那么建模的第一步就是要对样本数据进行预处理[1]。本文以某化工企业的HCN生产为研究对象,对其化工数据进行预处理,通过仿真实验说明,数据进行有效的预处理后,其泛化能力强,可以提高模型的精度。
1 决策变量的选择与数据的采集
1.1 概述
HCN为无色、剧毒、有苦杏仁气味的挥发性液体。其主要用途是制造有机玻璃和金属氰化物,也可作为乳酸和三聚氯氰等有机产品的原料。重庆某化工企业的氢氰酸生产采用安式氧化法,其生产的原料气为氨气、天然气和空气,催化剂为铂铑合金(Pt-Rh),在温度为1 100°C左右时氧化,得到纯净的HCN气体。 在生产过程中,氨的转化率是一个关键指标,提高氨的转化率对企业的经济效益和社会效益具有重要意义。
1.2 决策变量的选择
决策变量的选择主要是指变量的类型、数目和检测点的位置等的选择[2]。它们之间相互关联相互影响相互制约。其选择通常是根据生产过程的机理来确定的。综合HCN生产工艺,影响较大的因素有原料的配比、反应压力、反应温度等,故本文的决策变量选取三种原料气的流量作为输入,氨的转化率作为输出。
1.3 数据的采集
为了适应智能建模的需要,数据的样本必须具有可靠、容量大、可信度高、代表性强的特点,且能够充分反映实际生产的情况。本文选取的是重庆某化工企业记录的自2009年7月至2010年2月的5 000余组数据,经过剔除开停车、升降负荷和调节比值等过渡时期的数据,以及记录不全的数据后,剩余的3 055组数据作为原始数据训练模型。
2 数据的去噪处理
样本的数量与质量直接影响建模的效果,甚至影响过程控制、配方优化等问题。通常,数据的测量误差是不可避免的,所以,对这些误差必须去除。误差可分为两种:过失误差和随机误差。数据去噪就是从测量的数据中除去过失误差并减小随机误差。
2.1 类3σ准则处理过失误差
原始数据决策变量通常根据工艺要求与操作经验,都有控制范围,处理过失误差就是要剔除这部分不在上下控制线范围内的数据。常用的方法是运用概率统计学中的 3σ 准则[3]。
根据3σ准则,中心线与上、下控制线的公式为:

式中:u—总体平均值;σ—标准差。
首先绘出原始数据分布图,图1所示为氨气的补偿流量去除粗大噪声示意图。然后分析图中变量的取值范围,对数据进行处理,检查是否有超出μ±3σ范围的点,同时检查有无异常数据,若个别数据明显高于左右,成为“毛刺”,对这些超范围的和异常的数据选择直接剔除。这个过程可以用Matlab编程来实现。

图1 用3σ准则去除粗大噪声示意图
2.2 五点三次平滑法处理随机误差
处理测量数据中的随机噪声,通常采用数据平滑方法。本文采用的是五点三次平滑法。五点三次平滑法是利用最小二乘法原理对离散数据进行三次最小二乘多项式平滑的方法,五点三次平滑法的计算公式为:
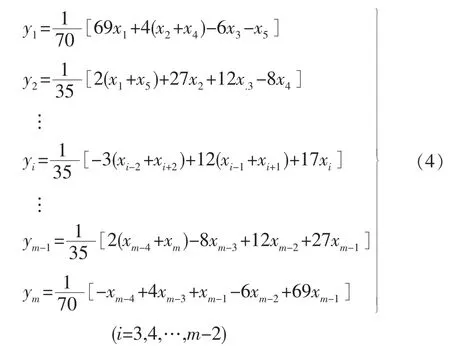
式中x为决策变量的样本数据,利用式 (4)编写Matlab程序对决策变量进行平滑处理,如图2所示为氨气的补偿流量去除随机噪声示意图。
3 数据的归一化处理
由于样本数据中的各个决策参数的物理意义和量纲各不相同,为了提高神经网络的学习效率,减小输出分量的绝对误差,故需进行数据的归一化处理。归一化的计算公式如下:

图2 用五点三次平滑法去除随机噪声示意图
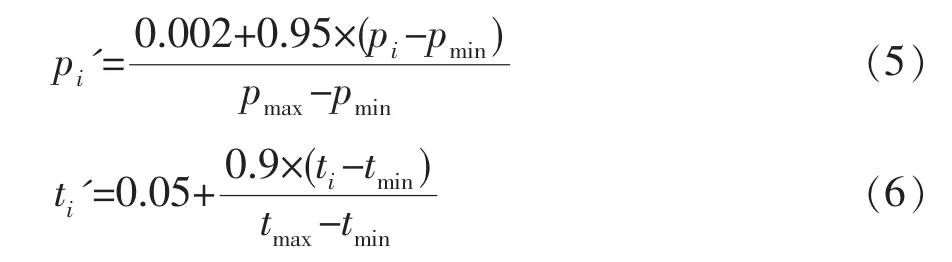
式中:pi、ti为归一化前的决策变量和性能目标;pi'、ti'为归一化后的决策变量和性能目标。在数据归一化时,pmax、pmin、tmax、tmin根据生产实际确定其相应的经验取值范围。
4 数据的降维处理
在建模中若决策变量的个数太多,会降低网络的训练速度,所以在尽量保存原有信息的前提下,对数据进行降维处理,即寻找合适的变量或变量组合,减小变量的维数,以求在后续工作中实现高效率。降维的同时,也可以去除数据的噪声[4]。
由于本文配方建模选取的决策变量个数较少,三种原料气的流量作为输入,氨的转化率作为输出,故不需做降维处理。
5 仿真实验
仿真数据来源于某化工企业的HCN生产实绩,选择其中的3 055组数据作为原始数据,通过3σ准则、五点三次平滑法、归一化处理后得到2 983组数据,A中选择作为训练样本,作为检验样本一,作为检验样本二。用已确定的3-7-1拓扑结构的BP神经网络仿真,测试所得均方误差均比较小,检验样本的相对误差也较小,其中样本二的相对误差如图3所示。说明该BP网络模型的泛化能力比较好,实用性强。
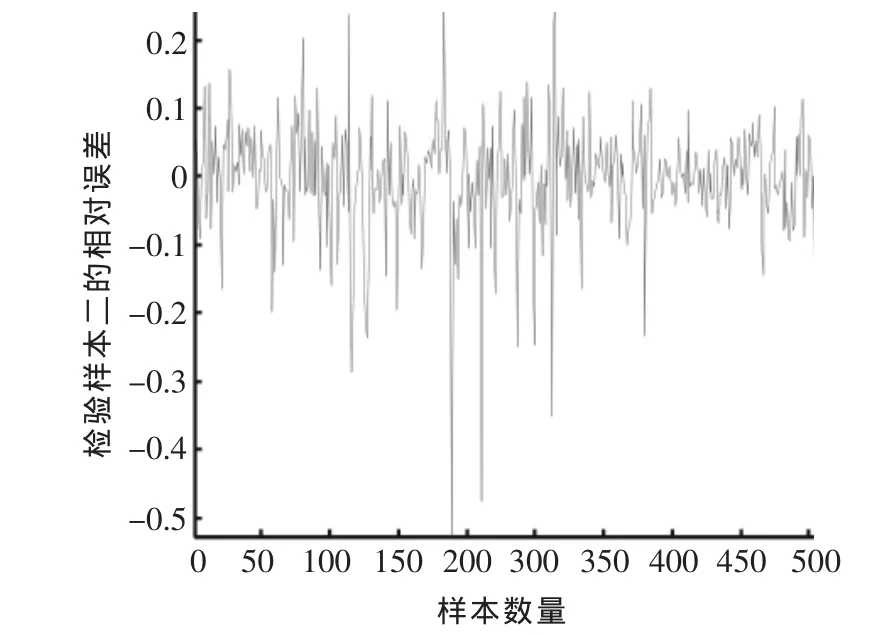
图3 BP网络检验样本二的相对误差
6 结 语
本文讨论了化工数据预处理的过程和常用方法,仿真说明:只要处理好决策变量的选择、数据的采集、数据的去噪、数据的降维等环节,就能有效地提高模型的精度,为产品的优化等进一步控制提供保证。
[1]扬斌,田永清,朱仲英.智能建模方法中的数据预处理[J].信息与控制,2002,31(4):380-384.
[2]夏陆岳.聚氯乙烯智能制造技术研究[D].杭州:浙江工业大学,2004.
[3]姜涛.数据挖掘技术在化工产品配方优化中的应用[D].北京:华北电力大学,2004.
[4]赵恒平,俞金寿.化工数据预处理及其在建模中的应用[J].华东理工大学学报:自然科学版, 2005,31(4):223-226.
[5]张斌,常雷,童钟灵.基于矩的图像归一化技术与Matlab实践[J].四川兵工学报,2010,31(4):75.
Abstract:This paper introduces the intelligent modeling in the chemical data pretreatment process,introduces the choice of the decision variables,data acquisition,data pretreatment methods such as the dimension reduction.Through the simulation experiment,it shows that the pretreatment of the data effectively,its generalization ability becomes stronger,and the precision of the model is improved.
Key words:data pretreatment;3 σ rule;five point three times smoothing
On Pretreatment Problem of Chemical Data in Intelligent Modeling
LI Cuiying1,2
(1.Chongqing University,Chongqing 400030;2.Chongqing University of Science and Technology,Chongqing 401331)
TP301
A
1673-1980(2012)02-0156-03
2011-11-15
李翠英(1973-),女,满族,吉林市人,重庆大学在读硕士研究生,重庆科技学院讲师,研究方向为电路与系统。
猜你喜欢
环球人文地理(2022年8期)2022-09-21
车主之友(2022年4期)2022-08-27
海峡姐妹(2019年12期)2020-01-14
意林·全彩Color(2019年11期)2019-12-30
重庆行政(公共人物)(2018年5期)2018-11-06
制导与引信(2017年3期)2017-11-02
今日重庆(2017年5期)2017-07-05
工业设计(2016年11期)2016-04-16
火控雷达技术(2016年1期)2016-02-06
环境科技(2015年6期)2015-11-08
