
中国机读目录中增补图书在版编目数据核字号信息的商榷
2012-10-23 05:16吴丽坤哈尔滨工程大学图书馆黑龙江哈尔滨150001
图书馆建设 2012年3期
吴丽坤 (哈尔滨工程大学图书馆 黑龙江 哈尔滨 150001)
CNMARC(China Machine-Readable Catalogue,中国机读目录)是资源共享的产物。其在中国产生并应用的20多年来,被越来越广泛地运用于书目机构之间的信息交换。中国版本图书馆CIP(Cataloguing In Publication,图书在版编目)数据核字号(简称CIP数据核字号)是国家新闻出版总署为编制好的CIP数据赋予的唯一一个核准号码。CNMARC与CIP数据核字号一直是各自独立的,从没有过任何关联。笔者认为CIP数据核字号应该作为CNMARC中值得关注的一个信息点。另外,由于CIP数据核字号是中国新闻出版总署信息中心赋予每本图书CIP数据的唯一核准号码[1],所以本文涉及的CNMARC所限定的文献类型是中国出版的中文图书。
1 CNMARC和CIP数据核字号
1.1 CNMARC的背景及含义
MARC(Machine Readable Catalogue,机器可读目录)是以代码形式和特定结构记录在计算机存储载体上、用计算机识别与阅读的目录。MARC可一次输入,多次使用。最早的MARC是美国国会图书馆的LCMARC(Library of Congress Machine Readable Cataloging,美国国会图书馆机读目录),后改名为USMARC(United States Machine Readable Cataloging,美国机读目录)。随后各国开始编制自己的MARC,如英国的UKMARC(United Kingdom Machine Readable Cataloging,英国机读目录)。为便于各国MARC的互相交换,国际图联制定了UNIMARC(Universal Machine Readable Cataloging,国际书目数据通信格式),用以规范各国的MARC格式。我国于1979年开始引进美国的MARC,并对其加以研究。自1988年起,北京图书馆开始研制CNMARC。
CNMARC是我国通用的机读目录通讯格式,被应用于中国国家书目机构同其他国家书目机构以及国内图书馆与情报部门之间,以标准的计算机可读形式交换书目信息。它是依据UNIMARC以及我国出版物的一些特殊情况和规则的新变化而编制的,并根据我国国情设计了一些地方字段,如091(统一书刊号)字段、092(订购号)字段和905(馆藏)字段等。
1.2 CIP数据核字号和CNMARC的关联
CIP是指根据一定的标准,由某一集中编目机构为在出版过程中的图书编制书目数据[2]。在我国,这一集中编目机构是新闻出版总署信息中心。随着图书出版量的急剧增长,为了快速、及时地对图书进行编目加工和报道,图书在版编目应运而生。它的出现避免了单独编目所造成的重复性劳动与人力浪费,有利于提高图书编目的标准化和规范化程度,保证图书编目的质量,是实现编目工作标准化和文献信息工作现代化的重要措施。同时,CIP对出版发行行业的深远影响也体现在CIP数据的规范、集中、共享及可分析方面。CIP数据核字号在国家新闻出版总署网站可以查询验证(见图1),验证结果见图2。

运用CNMARC格式编目的数据和CIP数据两者都承担和执行着一个重要工作,即书目资源共享和编目现代化。编目的任务是对图书进行整序、揭示文献信息、提供检索点、描述文献内容。上述两者各自进行的是对图书不同阶段的描述,揭示图书不同阶段的信息。CIP是为在出版过程中的图书编制书目数据。既然图书尚在出版过程中,那么某些项目的变动则在所难免。而CIP数据核字号是与图书一一对应的,且被赋予之后不会变更。正是因为CIP数据核字号的唯一性,使它作为独立检索点成为可能。因此,CNMARC与CIP数据核字号应该有所衔接。
2 CNMARC中增加著录CIP数据核字号信息的必要性
从图1和图2中可以看出,利用CIP数据核字号查询可以获得图书的题名、责任者、出版发行机构等重要信息。最重要的是CIP数据核字号对图书的ISBN(International Standard Book Number,国际标准书号)也有着准确的反映。ISBN是机读的编码,从图书的印刷、发行到销售始终如一。它的引入简化了图书的订购、库存控制、账目和输出过程等任何出版业的分支程序。同时,ISBN对图书馆和文献中心的图书订购、采选、编目和流通程序也都有促进作用。
图书馆侧重于区别图书的品种,主要通过核查ISBN来确定其是否重复。理论上,ISBN具有唯一性,只要其相同,就一定是同一种书。然而在实际工作中,由于出版物形式的多样性,ISBN并不能完全起到区别图书品种的作用。而且,由于国内出版环境的复杂性,某些图书的合法性有待商榷,其中有些也成为了图书馆的馆藏。因此,在CNMARC中增加CIP数据核字号十分必要。
2.1 CIP数据核字号可作为检索点区分ISBN相同的正规图书
目前,由于图书形式的多样性,国家新闻出版总署可验证的出版物中同一ISBN不止对应一种图书(非丛书)的情况绝非罕见(见图3、表1)。


表1 ISBN相同、CIP数据核字号不同的图书列表
书目数据是依据MARC标准编制的,无论其来源于何处,只要MARC标准没变,CIP数据核字号的缺失便是共性问题。如图3显示,ISBN为7-5087-0015-5的记录共8条,其各自的CIP数据核字号都不同,但CNMARC数据无法对CIP数据核字号的不同给予显示。在ISBN相同的前提下,CIP数据核字号可以作为区别文献的明显信息,发挥区分相同ISBN图书的作用。
2.2 CIP数据核字号可区分合法性有待商榷的图书
合法性有待商榷的图书通常分为3种:
(1)盗用ISBN的图书 所谓盗用ISBN的图书是指出版社出版的图书使用的是某个已经使用过或者即将被使用的ISBN,而且,盗用的ISBN通常被不止一次地使用。例如:以“ISBN” 为检索入口,以 “7-80099-634-4” 为检索条件,在CALIS中文联合目录数据库中与国家图书馆中文及特藏数据库中分别进行检索,检索结果见图4和图5。

在CALIS 中文联合目录数据库中检索到12种图书。在国家图书馆中文及特藏数据库中检索到16条书目数据。这些图书既不是丛书,作者也不相同,彼此没有关系。拥有同一ISBN的数十种图书的CNMARC数据,没有一个信息点、一个子字段反映CIP数据核字号的情况。CIP数据核字号存在与否、真实与否、正确与否不得而知。
(2)使用其他图书的CIP数据核字号的图书 有一类图书显示了CIP数据核字号,但是经验证发现,该CIP数据核字号与其他图书的吻合。例如,图6中《世界美术全集》的CIP数据核字号为“2003013458”、ISBN为“7-80145-705-6”。将该CIP数据核字号通过中国新闻出版总署网站进行验证,结果见图7。显然,图7中的CIP数据核字号的图书题名和ISBN等各项信息均与图6不符。使用其他图书的CIP数据核字号的图书数据来源见图8。


毫无疑问,图4中显示的同一ISBN的十几种毫无关联的图书,图6中使用其他图书的CIP数据核字号的图书及图9中不明原因缺失CIP数据核字号的图书,在出版过程中其数据没有经过新闻出版总署信息中心的备案审核。这种做法显然违背了《出版管理条例》,这些图书的合法性有待商榷。其CNMARC数据无法让图书馆业内人员及读者分辨哪些是经过国家新闻出版总署验证核准的合法出版物,哪些是盗用书号的图书和出版过程中不曾被权威机构验证核准的图书。图书馆的采访原则是采集正规途径的出版物,同时收集对读者有价值的文献也是图书馆的职责[4]。从这个层面上说,无论是作为我国图书馆事业核心和总书库的国家图书馆,还是作为高等教育文献保障平台的CALIS,即便不排斥这样数据的出现,也有义务在图书的CNMARC格式数据中对CIP数据核字号的信息有所体现,有责任把CIP数据核字号缺失或不正确的图书和其他图书区分开来。目前,CNMARC中没有一个点可以显示CIP数据核字号。笔者认为,即使CNMARC无法验证CIP数据核字号正确与否,仍旧可以将其作为一个信息标注点,以便在需要验证的时候有据可查。
2.3 CIP数据核字号可为服务读者提供方便
读者的信息素养和认知方式千差万别,一部分读者曾试图利用CIP数据核字号向图书馆荐购或要求获取资源。面对这样的情况,我们曾要求读者重新提供检索信息,也曾经到新闻出版总署CIP核字号验证中心查证。如果CNMARC数据库中的CIP数据核字号信息完备,只要掌握CIP数据核字号这个信息(即便是错误的或被杜撰出来的),就可以从数据库中检索到其所属的图书信息。
3 在CNMARC中增补CIP数据核字号信息的构想
CNMARC的根本依然是引进的UNIMARC,在此基础上研究、翻译,并依中国国情设计了一些地方字段。CNMARC的书目格式提供了对各种文献类型进行著录、检索的详细说明,也提供了对书目控制所需要的各种编码数据元素的详细说明。CNMARC的书目格式由记录头标区、目次区和数据字段3个部分组成。增加信息检索点需要在数据字段部分增加字段或子字段。
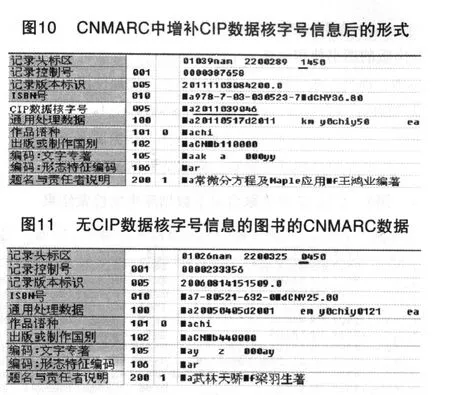
数据字段部分0--是标识块,图书馆和数据中心查重、检索利用最为广泛的ISBN就著录在标识块的010标准编号及获得方式项中。所以,要在CNMARC中增补CIP数据核字号,笔者建议在标识块增加一个体现中国国情的地方字段,如095字段,将其取名为“中国版本图书馆CIP数据核字号”。另外,为了把没有CIP数据核字号的出版物区分开来,也为了便于统计这类图书的数量,笔者建议用记录头标区未定义(即空位)的第19字符位的不同取值来体现。例如,当该字符位取值为1时,表示该CNMARC数据有CIP数据核字号信息(见图10);当该字符位取值为0时,表示CNMARC数据中无CIP数据核字号信息(见图11)。
4 结 语
和任何新生事物一样,CNMARC在中国诞生20多年来,经历了不断完善和丰富的过程。当前我国图书形式的多样性和出版发行环境的复杂性使在CNMARC中增补CIP数据核字号信息的需求愈加迫切。
[1]武二伟.国外图书在版编目(CIP)现状分析及对我国的启示[J].现代情报,2009(3):18-22.
[2]曾照云.图书在版编目(CIP)述评[J].现代情报,2006(11):94-96.
[3]中国新闻出版信息网[EB/OL].[2011-09-17].http://www.cppinfo.com/.
[4]赵志刚.对“盗号书”现象的剖析:基于新制度经济学视角的分析与思考[J].图书馆建设,2008(6):52-55.
猜你喜欢
卫生职业教育(2022年24期)2022-12-22
卫生职业教育(2022年23期)2022-12-10
卫生职业教育(2022年20期)2022-10-11
卫生职业教育(2022年19期)2022-10-10
今日农业(2021年19期)2022-01-12
天一阁文丛(2020年0期)2020-11-05
航空世界(2020年6期)2020-10-26
戏曲研究(2017年3期)2018-01-23
法制博览(2017年18期)2017-01-27
图书馆学刊(2015年8期)2015-12-26
