
基于SIS系统的数据采集及过程数据挖掘
2012-09-04 08:45吴杰,华驰
苏州市职业大学学报 2012年4期
吴 杰,华 驰
(1.江南大学 物联网工程学院,江苏 无锡 214122;2.江苏省宜兴中等专业学校 就业指导处,江苏 宜兴 214206;3.江苏信息职业技术学院 物联网工程系,江苏 无锡 214122)
(1.Internet of Things Engineering College,the IOT College of Southern Yangtze University,Wuxi 214122,China;2.Department of Career Guidance,Yirshing Trade School,Yixin 214206,China;3.Department of Internet of Things Engineering College,Institute of Information Technology,Wuxi 214122,China)
基于SIS系统的数据采集及过程数据挖掘
吴 杰1,2,华 驰3
(1.江南大学 物联网工程学院,江苏 无锡 214122;2.江苏省宜兴中等专业学校 就业指导处,江苏 宜兴 214206;3.江苏信息职业技术学院 物联网工程系,江苏 无锡 214122)
通过对基于SIS系统的数据采集及工厂过程控制数据挖掘的研究,提出面向电厂SIS系统数据仓库进行数据采集以及过程控制数据挖掘的解决方案.针对生产过程中性能优化、经济分析、故障诊断等方面的应用,以锅炉结焦原因为例,进行分析与研究,取得了较好的效果.
SIS系统;数据挖掘;性能优化;故障诊断
随着国民经济的发展,越来越多的趋于大容量、高参数的发电机组投入了运行,这对电厂自动化水平提出了更高的要求;而数据挖掘技术给生产运行过程中产生大量驳杂数据的电厂性能计算,故障诊断、经济分析、性能优化方面的利用带来了实际应用的可能.
电厂的控制系统很多,如DCS系统(分散控制系统)、PLC控制等;还有独立控制的如BMS(燃烧器管理系统)、DEH系统(电液控制系统)等,如此繁多的系统对数据采集是个很大的挑战.本文研究如何将现场数据进行整合,并且把整合后的数据针对生产过程中性能优化、经济分析、故障诊断等方面的问题,提炼挖掘成有用的规则信息.
1 SIS系统及其数据采集和挖掘技术
1.1 SIS系统
随着信息技术和控制技术的飞速发展,电子研究学者提出一种新的电厂应用信息系统——厂级监控信息系统(supervisory information system,SIS)被电力研究学者提出.SIS属于厂级生产过程自动化范畴,实现电厂管理信息系统与各种分散控制系统之间数据交换的桥梁[1].厂级实时监控信息系统以分散控制系统为基础,以经济运行和提高发电企业整体效益为目的,采用先进、适用、有效的专业计算方法,实现整个电厂范围内信息共享,厂级生产过程的实时信息监控和调度,同时又提高了机组运行的可靠性.为电厂管理层的决策提供真实、可靠的实时运行数据,为市场运作下的企业提供科学、准确的经济性指标.
在整个SIS中,处于基础和核心的子系统是实时数据库,实时数据库系统能用于生产数据的自动采集、存贮和监控.系统可在线存贮每个工艺过程点的多年数据;用户既可浏览电厂当前的生产情况,也可回顾过去的生产情况;由于电厂生产数据存放在统一的数据仓库中,企业中的所有人无论在什么地方都可以看到和分析相同的信息.
从图1中可以看出,SIS中的实时/历史数据库可以长期记录下DCS(主系统)、网控、程控、化水、除灰等系统运行中的过程点及重要中间点的数据.通过这种全厂范围内的实时数据记录,可从全局的角度下分析问题.
1.2 数据采集和挖掘技术
数据挖掘技术是一种利用各种分析工具在海量数据中发现模型和数据间关系的过程,这些关系和模型可以用来做出预测.自20世纪末提出至今,它汇集了机器学习、模式识别、数据库、统计学、人工智能以及管理信息系统等多学科的成果.海量数据的背后往往蕴涵着许多知识,但由于这些数据本身的多元性、动态性与交连性,又给人工分析和处理带来困难.而数据挖掘与知识发现技术作为一门新兴学科,有效地解决了这方面的问题,它能够在很少人工干预情况下,处理复杂的数据信息,提取有关知识规则.
随着信息技术的进步及其计算机技术和网络技术的发展,工业生产过程中采集的数据可以方便地被收集和存储在各种数据库中,采用传统的数据分析方法对这些巨量的数据进行分析不仅费时且难以有效地挖掘出隐含的知识.另一方面,尽管专家系统、智能诊断等方法在生产过程中得到广泛应用,但专家系统的知识瓶颈和智能诊断方法所带来的推理过程困难等问题仍未得到很好的解决,数据挖掘却可以有效地解决这些问题,因此将数据挖掘技术应用于生产过程中是必然的也是可行的.
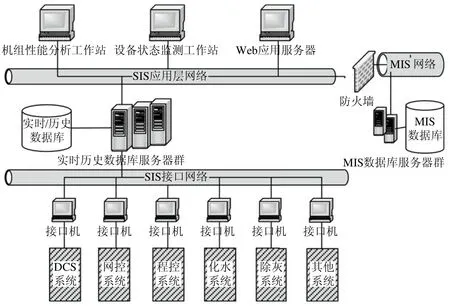
图1 SIS的系统结构
2 解决方案
2.1 可行性及必要性
电厂在生产过程中使用的数据有数据来源多、数据量大、数据种类混杂等特点.例如主控系统使用的是DCS系统,其网络通讯各项指标:速率为100 MB/s;容量为20万实时点/s;节点为1 000个;网络拓扑,双环冗余,故障点环绕等.DCS系统产生海量的数据信息,这些数据信息存放在数据服务器上;而输煤、化水等系统使用的是PLC控制,使得数据的采集和存储产生了大量问题,如:不同公司对某个设备或控制过程点本体的定义描述不同;大量的数据只能在数据服务器保存几个月就会磁盘报警;数据在数据服务器存储的格式不同;数据只能使用同一公司的数据分析报表软件,无法直接导出再处理等,制约了电厂数据仓库的建立.
使用SIS系统是一个比较好的解决手段.SIS系统总体包括3大部分:实时数据采集,实时/历史数据库以及建立在数据库基础上的数据分析挖掘.
实时/历史数据库是整个系统的核心,是电厂生产运行的“黑匣子”,其存储容量和存储效率直接关系到数据采集的范围和精度.由于电厂生产过程数据海量、无序、精度要求高、带有时标,常见的关系型数据库不能很好地满足要求,因此使用美国OSI Software公司的PI实时/历史数据库.它主要提供3种接口方式:世界多数著名DCS系统厂家专用接口,基于OPC标准的通用接口,基于API开发的特殊接口.大量的各种数据通过PI数据库的通信接口,读取到PI数据库内,通过统一的格式进行定义使用,为下一步数据挖掘提供了基础,而且PI数据库使用Swing Door压缩算法,每个采集点的数据压缩率可自行设置;在保证数据精度要求的条件下优化了系统的运行效率,使调用数据速度极快,可以满足应用的需求[2].
2.2 数据挖掘技术在电厂的应用
数据挖掘过程可以大略地分为数据收集、数据预处理、数据转换、数据挖掘及使用等5个过程.基于SIS系统,在强大的PI数据库中已经能很好处理长达多年并且几万点的数据量,同时可以在此数据仓库的基础上,根据需要选取相关数据进行预处理及数据转换工作,因此SIS系统所进行的数据收集过程是非常重要的.
根据挖掘任务的不同,对数据仓库进行规则分析、关联分析、分类分析、聚类分析、预测分析、趋势分析、偏差分析等.应用于电厂发电行业,目前所作的研究主要集中于通过关联规则分析的运用,从历史/实时数据库中发现未知的、未被应用的数据相关关系,如通过挖掘分析导致管壁超温现象的原因;通过回归分析,对某些重要参数进行预测拟合,对事故的发生进行预判等,如预测凝汽真空、用电调度等;根据已知数据通过应用BP神经网络估算未知数据,例如可以通过BP神经网络,采集与锅炉管壁某段有关的易于测量的几个点的测量值,预测锅炉管壁上不易于测量管壁点的温度或者压力等.因此数据挖掘在电厂应用前景非常广阔,应用多种数据挖掘技术,可以从数据仓库中挖掘出对发电机组安全性与经济性的规律和信息,形成一定的知识储备,可以帮助运行人员操作指导,为提高机组的经济安全运行提供了科学依据.
2.3 应用实例
某电厂350 MW机组投产至今多次发生由于管壁超温而引起的锅炉结焦泄漏事故,在煤粉锅炉运行过程中,结焦不仅降低锅炉的热效率,而且对锅炉设备造成损害,严重影响安全经济运行,尤其是因结焦严重而停炉处理,其经济损失更大.以350 MW机组配套设备为例,如果因为结焦停炉10 h,电价按0.3 元kW/h计算,则损失达百万元以上.锅炉结焦过程十分复杂,大部分前期症状体现在锅炉管壁超温上,而锅炉管壁超温的原因由于锅炉内燃烧模型复杂,各种因素相关关系错综,无法用一个完整的数学模型直接分析[3],因此对管壁超温现象用数据挖掘的方法进行关联规则的分析是非常必要的.对特定的机组分析管壁超温,排除由于煤质问题、锅炉本体设计问题等无法干预的可能,从运行优化的角度,本例将以改进的Apriori算法研究电厂锅炉管壁超温故障与机组其他运行参数之间的关联规则.
Apriori算法是一种较有效的频繁项集挖掘算法[4].该算法使用一种称为逐层搜索的迭代方法,k项集用于探索(k+1)项集.首先,通过扫描数据库,累积每个项的计数,并收集满足最小支持度得项,找出频繁1项集,记作L1,L1用于探索频繁2项集的集合L2,而L2用于找L3,如此下去,直到不能找到频繁k项集.找每个Lk需要一次数据库扫描.一旦从数据库的事务D中找出频繁项集,就可以根据最小置信度直接产生强关联规则.
Apriori算法选取的数据对时间参量没有严格的离散值[5],电厂生产过程是连续的、不间断的,而且单位时间内数据量非常大,实时性要求也比较高.根据电厂本身的关联特性和生产难以解决Apriori的适应性问题[6].因此本文将算法改进分为3部分:
1) 从SIS系统的PI数据库内提取电厂所有相关历史数据.在这一过程中,根据专家意见,排除大部分不可能的数据,如本次研究的是锅炉超温时间,则关于发电机部分的所有数字量和模拟量均可不在采集范围内.对数据进行初步的聚类分析可以有效地减少计算量和驳杂数据对结果的影响.
2) 按照工业生产的规律性分段.通过数据划分技术来挖掘频繁项集;只需扫描整个数据库2次.其包含2个主要处理阶段.第一阶段,算法将数据库按照生产规律分为N个互不相交的部分,若数据库D中的最小支持阈值为min_sup,那么每个部分所对应的最小支持频度阈值为:min_sup乘以number_of_partition.对于每个划分(部分),挖掘其中所有的频繁项集,它们被称为是局部频繁项集.就整个数据库D而言,一个局部频繁项集不一定就是全局频繁项集,但是任何全局频繁项集一定会出现从所有划分所获得的这些局部频繁项集中,这一点很容易反证获得.因此可以将从N个划分中所挖掘出的局部频繁项集作为整个数据库D中频繁项集的候选项集.第二阶段再次扫描整个数据库以获得所有候选项集的支持频度,以便最终确定全局频繁的项集.根据数据划分技术及挖掘的目的可以将事件项目以字母顺序排列,编号用<x,Te>来标识,这里Te表示超温测点编号,x表示一些连续数值型数据,如负荷、给水温度等和一些离散数值型数据;并对模拟量数据进行离散化处理,如,负荷M的值在0 ~360 MW之间变化,可先将它分成18段.M1为<20 MW,M2为20~40 MW,…,M18为>340 MW等.
3) 利用Apriori算法产生期望的规则.
改进后的Apriori算法流程如图2所示.
通过设定不同的最小置信度及最小支持度,可以分析各种因素在锅炉管壁超温现象中的隶属度,从而得出有利于运行优化方案的科学根据.在实际计算中,笔者以再热器管壁温度第6排第1点为基准超温点,采集一年内超过605 ℃时的数据点3 253组,经过专家验证,排除重复项、采样测点故障异常项等干扰项后得到数据1 165组.选取最小支持度为min_sup=25%,最小置信度为min_conf=60%,得出当此温度点超温时与再热器挡板前左侧温度值的上升与#1OFA阀门开度相关的结论,以此可以提醒在下次发生再热器挡板前左侧温度值的异常上升时,关注再热器管壁超温结焦现象,并且可以通过对#1OFA阀门开度的测定,确定实际配风量,以达到防止超温的目的.
基于改进后的Apriori算法完成管壁超温现象中各类数据关联规则的分析,可以大大降低由于管壁超温而引起的锅炉结焦泄漏事故,从而在煤粉锅炉运行过程中,降低结焦率,减少经济损失.
除了此类改进的Apriori算法,其他诸如C4.5,k-Means,SVM,EM,PageRank等数据挖掘算法在SIS系统中应用也都比较常见,其对数据的相关性分析可以应用在电厂的各个方面,比如,汽轮机振动故障性能分析,凝器真空下降原因分析,空预器漏风分析等,本文就不一一详述.
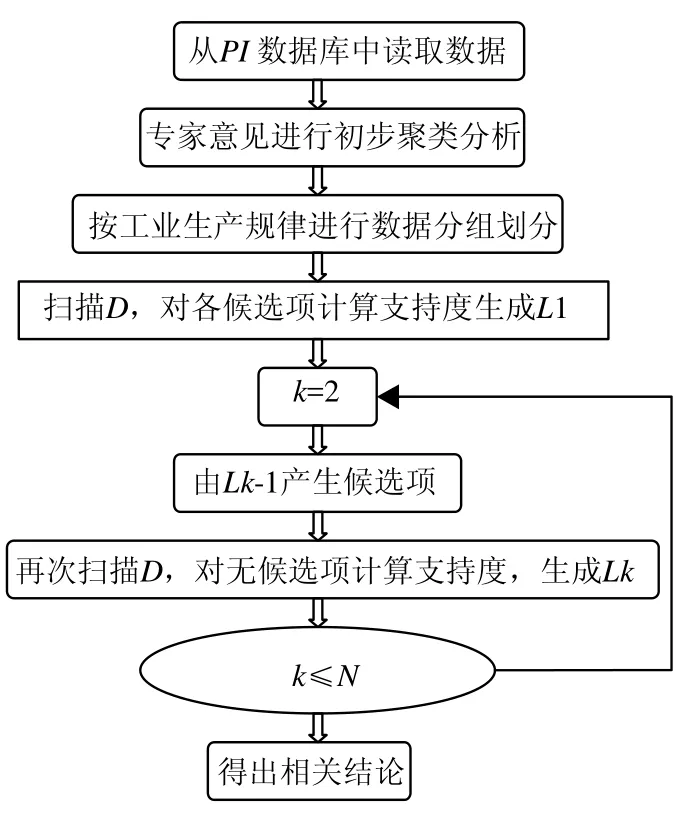
图2 改进后的Apriori算法流程图
3 结论
随着大容量火力发电机组的投产,再加上日益紧迫的能源与环境问题,作为耗能大户的热电厂需要有效的手段提高运行效率、降低排污.从基于SIS系统的数据采集和数据挖掘手段着手,对机组的安全、优质、稳定运行提出了一种新的分析思路,将各种隐藏的知识用挖掘的手段展现出来,并且能得到很好的实际效果.因此,能否从热力系统自身的运行数据中找到改善系统运行的知识和手段,是一个很有现实意义和研究价值的课题.
[1]侯子良. 再论火电厂厂级监控信息系统[J]. 电力系统自动化,2002,26(15):1-3.
[2]彭春华,林中达. PI实时数据库及其在电厂SIS 系统中的应用[J]. 工业控制计算机,2003,16(6):28-33.
[3]周校平,张晓男. 燃烧理论基础[M]. 上海:上海交通大学出版社,2001.
[4]王伟勤,郑海. Apriori算法的进一步改进[ J]. 计算机与数字工程,2009,37 (4 ):20-23.
[5]徐章艳,刘美玲,张师超,等. Apriori算法的三种优化方法[ J ]. 计算机工程与应用,2004,40( 36):190-192.
[6]陈应霞,陈艳. 关联规则中的Apriori挖掘算法改进[ J]. 长江大学学报:自然科学版,2008,5 (4):341-343.
SIS-based Data Collection and Process Control Data Mining
WU Jie1,2,HUA Chi3
Based on the Supervisory Information System(SIS)-based data collection and the plant process control data mining research,this paper proposes a solution of data collection and analysis targeting at the power plant SIS data warehouse. Using the methods to optimize performance,economic analysis,fault diagnosis,such as the application to the boiler coking reason,the study achieves good results.
supervisory information system(SIS);data mining;performance optimization;fault diagnosis
TP311
A
1008-5475(2012)04-0013-04
2012-09-15;
2012-10-10
江苏省十二五规划建设2011课题;江苏省教育科学研究院2011现代教育技术研究立项课题(18959)
吴杰(1980-),男,江苏宜兴人,讲师,硕士研究生,主要从事计算机信息管理研究.
(1.Internet of Things Engineering College,the IOT College of Southern Yangtze University,Wuxi 214122,China;2.Department of Career Guidance,Yirshing Trade School,Yixin 214206,China;3.Department of Internet of Things Engineering College,Institute of Information Technology,Wuxi 214122,China)
(责任编辑:李 华)
猜你喜欢
大众投资指南(2021年35期)2021-02-16
天津科技大学学报(2018年4期)2018-08-22
计算机测量与控制(2017年6期)2017-07-01
电力与能源(2017年6期)2017-05-14
中国塑料(2016年12期)2016-06-15
信息通信技术(2015年6期)2015-12-26
中国塑料(2015年12期)2015-10-16
电子设计工程(2014年18期)2014-02-27
中国医学科学院学报(2013年3期)2013-03-11
网络安全与数据管理(2010年1期)2010-05-18
