
基于k-medoids与c5.0联合约束的药品信息挖掘算法*
2012-08-10 09:49章慧
长沙大学学报 2012年5期
章 慧
(淮阴工学院计算机工程学院,江苏 淮安 223003)
随着Internet的迅速发展,当今IT技术、电子商务及互联网的快速发展和迅速普及,导致在各个应用领域的数据库中存储了大量的数据,传统的数据挖掘技术无法有效地得到需要的兴趣信息[1].这些数据集中包含了很多有用的知识,如何发现其中所隐藏的、预先未知的信息以辅助相应的应用显得尤为重要,这正是数据挖掘所要完成的任务.目前,使用数据挖掘来进行数据分析已经出现了很多的方法,魏鸿等人提出要使用更高级的数据挖掘的方法来进行网络的数据分析[2]来提升挖掘的满意度.张丽华等人[3]提出客户满意度的测评方法在满意度提升中的作用.与此同时,大量的研究者将数据挖据的方法引入到数据的分析中,使数据挖掘成为计算机相关算法中最活跃的一个领域[4-6],这些方法为数据的合理有效分析提供了强大的理论基础.
但是这些数据挖掘其实还仅仅停留在简单的数据分析或者OLAP阶段,即使有数据挖掘的使用也仅仅停留在简单的分类统计和简单预测等阶段,当应用到一些大型多区域的复杂领域时,很少考虑数据的真实完整与数据预处理对挖掘带来的影响.这些研究方法还没有将数据挖掘的研究结果整合到一个完整的分析体系中,这些方法的适用范围与准确程度就出现了很大的局限性.一些方法仅仅是将客户的数据在没有进行合适的预处理的情况下就进行简单的聚类,完成聚类以后进行简单的分析,没有发挥数据挖掘强大的预测能力,使这些预测的数据丢失了继续使用的价值[7].
为了解决这一问题,采用真实的多区域药品数据进行实验对象.使用合适的数据预处理的方法来降低噪音和孤立点等数据对原始数据的分析影响.结合经典的k-medoids与c5.0数据挖掘的方法,将聚类分析中的得到的结果作为决策树的测试集来进行分析,这样就能保证决策树中的属性数据真实可靠[8,9].实验证明上述的方法可以提高药品数据分析的准确率.
1 k-medoids算法的数据挖掘
在数据挖掘的聚类分析中最常用的是k-medoids算法,k-medoids算法是基于质心的算法.以k为参数,把n个对象分为k个簇,以使簇内具有较高的相似度,而簇间的相似度较低,相似度的计算根据簇间的一个平均值(被看作簇的重心)来进行.通常采用准则函数是平方误差的准则函数来进行,其定义如下:
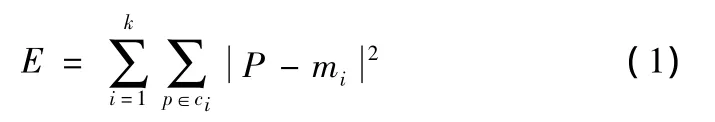
上式中e是数据库中所有对象平方误差的总和;p是空间中的点,它表示给定的数据对象mi是簇ci的平均值,也就是说每个簇中的每个对象,求对象到其簇中心距离的平方然后求和,这个准则试图使生成的结果簇尽可能的紧凑和独立.因为一个极大值的对象可能相当程度上扭曲数据的分布,所以上述方法对于孤立点与噪声具有极强的敏感性.kmedoids算法使用最靠近中心的一个对象来代表该聚类.定义如下:
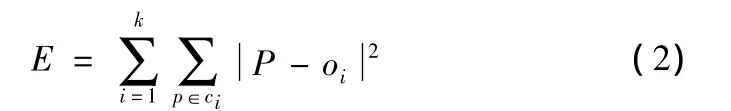
上式中e是数据库中所有对象平方误差的总和;p是空间中的点,它表示给定的数据对象oi是簇中的代表对象.在经典的ID系列的算法中存在着一定的归纳偏置,较短的树比较长的树优先产生,也就是那些信息增益高的属性更靠近节点会产生优先生成树的特权.为了避免偏置研究者们引入了增益比率来进行决策,增益比率通过一个分裂信息来分析分裂属性,由如下公式进行定义

在上述方法中选择具有最大增益率的属性作为分裂属性进行决策分析.在数据分析中由于不同数据的属性具有极强的非线性,即使进行了强大的数据预处理,由于它要求在聚类分析中输入数字K确定结果的个数,并且不适合发现非凸面形状的簇,或者大小差别很大的簇.所以这些启发是聚类针对中小规模的数据可以使用,但是对于大规模的非结构化的数据就需要进行更进一步的处理;另外聚类后的属性性质其实是做为一种描述的现象来进行数据分析,忽略了这些原始数据聚类后得出的结果可以作为最真实的样本来进行数据进一步的决策.为了避免这种情况,先在数据的时间属性上减少噪声与孤立点的数据影响.进行聚类后建立决策数据模型,能取得好的效果.
2 药品数据预处理与约束数据挖掘
2.1 药品数据预处理
在大量的待挖掘的药品数据中,出现了大量的冗余数据.一些具有关键意义的药品数据在实际的整体数据中所占比例很小.为了解决冗余问题,在属性约简的过程中使用组距众数的方法消去.

上述两式中f-1表示药品数据众数所在组前一组的次数f+1表示药品数据众数所在组后一组的次数;L表示药品数据众数所在组组距的下限;U表示药品数据众数所在组组距的上限;i表示组距,将一些差异药品数据的属性分别进行上述的组距众数的计算将会消去一部分冗余属性.在药品数据挖掘算法中有些属性可以进行阶段性的汇总,这部分属性的时间趋势不是很强烈,可以用总的汇总表来代替这部分数据的使用.使用一些药品数据属性表来进行数据的分析、数据的汇总处理,包括以下几个步骤:
(1)用药品数据表生成更多数据的汇总表,只保留药品数据的一部分信息.
(2)把一些相互有关联的药品数据进行合并,只保留一些药品数据的起始日期、终止日期与数据统计表.
(3)将上述的步骤应用于每一个月生成的药品数据进行对比统计.
进行药品数据预处理的方法如图1所示:
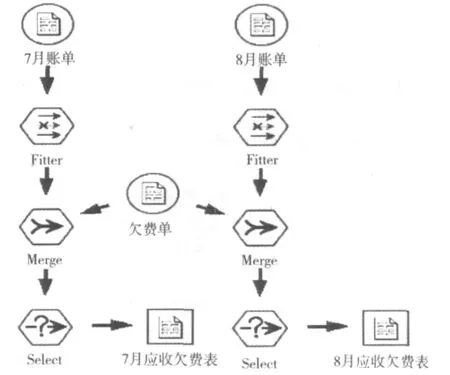
图1 药品数据预处理部分
面对大量的相关药品数据或者药品日志文件,对其进行筛选,完成药品数据初始化的操作是十分必要的,去除不相关的冗余数据才能更有效地对核心药品数据进行挖掘,一旦存在大量的冗余数据,对挖掘算法的影响是十分巨大的.大规模的存在冗余的海量药品数据通常是以文本的形式存储的,如一些文本文件,记录了药品相关数据的详细信息,其中包含了一些不全的、重复的甚至错误的药品冗余数据,所以需要进行处理,否则就会影响挖掘的结果.
用户在访问药品数据库时,有一些药品数据信息是自动加载的,如:图片、网站的页眉页脚的固定页面、JS脚本等,而这些加载的行为也会作为动作记录到一些相关的文本文件中,显然这些信息对后期的数据挖掘是无用的,所以必须通过一些方法来对相关的数据进行筛选.对于这些自动加载的图片等对挖掘无用的数据,应当通过相应的技术去删除它们,如结尾为.JPEG、.GIF、.PNG 和.js等.
定义Ld为此次过程中药品数据在种群中的密度,则Ld,n表示该个体在种群中出现的次数,M表示当前种群的大小.

选择概率为P= ∂Pf+(1- ∂)Pd,其中∂∈(0,1)为调控参数.
通过以上的数据预处理将生成描述数据价值的情况表.
2.2 双约束药品数据挖掘
将药品数据进行预处理以后得到的数据汇总表,在聚类分析中将这个表作为挖掘药品数据的来源,目标输出数据是聚类数据汇总情况表.实验中使用了式(2)中介绍的k-medoids的聚类分析方法,采用此方法对药品数据进行约简与实际的噪声处理后,仿真的效果非常明显.将相关的药品数据情况用二进制数据来表示:药品数据一致的用1来表示,不一致的用0来表示.不一致的定义字段为一个波动的范围以内,需要注意的是在进行药品数据的分析聚类的时候,表的属性只能包括一些不能明显描述药品数据分类的属性.经过聚类后的数据字段应该包括如下:平均药品数据分布、平均药品数据均值、药品数据信息、药品数据分类情况等类别.使用C5.0算法的决策分析中需要一定的测试集来进行决策的划分,使用上一步药品聚类的结果来进行测试,这种分析方法的准确性得到大大的提高.
3 实验及结果分析
为了验证本文算法的有效性,运用基于k-medoids与c5.0联合约束挖掘算法,对药品数据价值进行分析.首先将药品数据进行有效的预处理,得到原始的工作表,决策分析时使用聚类后的药品价值分析数据.通过与传统方法对比,证明了分析的严谨与效果的显著.效果验证分析、实验流程如图2所示.

图2 实验流程图
实验环境为Windows XP操作系统,spss Clementine数据挖掘软件通过节点流构造模型,进行可视化的结果展示.实验采用某区域药品公司中7、8、9三个月客户消费的账务信息表作为原始的数据,来进行药品价值的分析.首先进行聚类分析找到消费群体的分布与包含的数量.数据聚类的结果示意图如图3所示:

图3 药品信息聚类分析后的散点图
统计各药品类别包含的用户群比例,结果如图4所示:
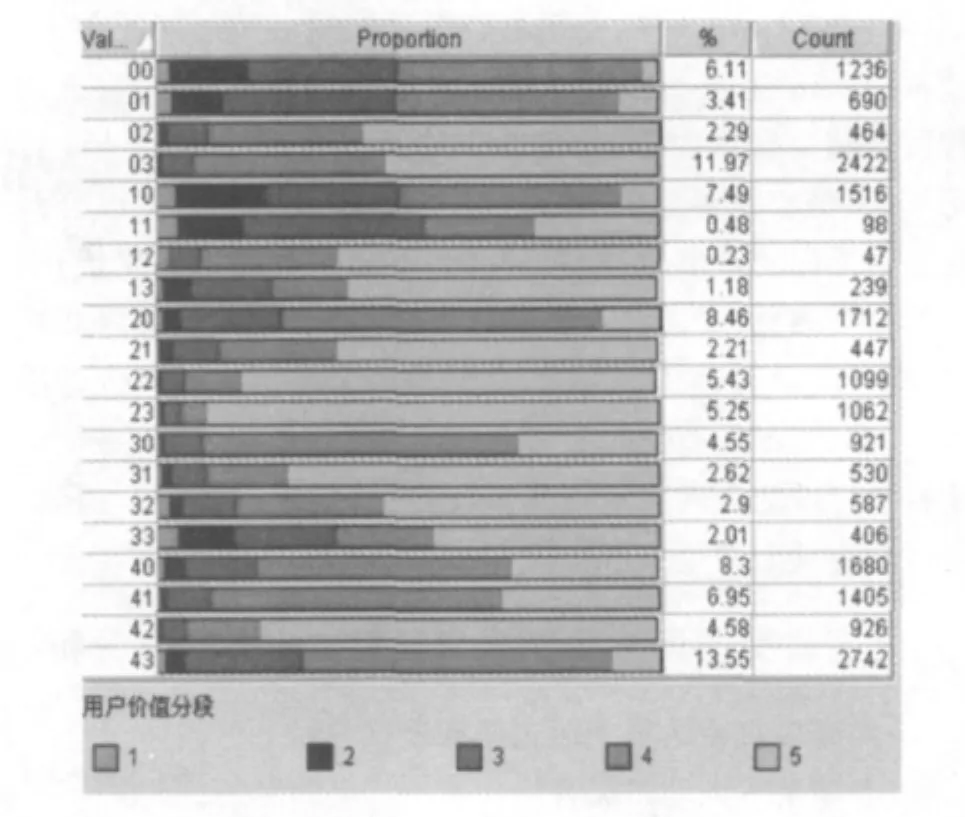
图4 药品类别包含的用户群比例分析
从上图可以清晰地发现在每一个药品用户群中分散开来,并且没有出现会聚在一个类别中的现象.将上述的聚类测试集用来抽样,本文按照测试集与检验集7:3的原则,共抽取10000条样本来进行决策树的构造.从图中可见最优价值的药品在4、5两个阶段的情况,覆盖了大部分的客户消费.
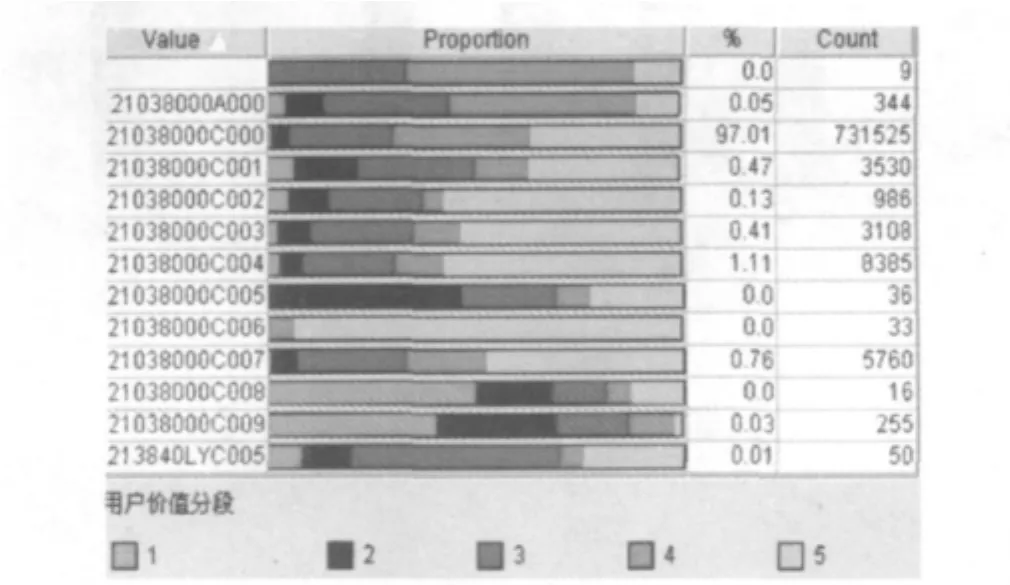
图5 药品价值分段与药品销售情况

图6 药品的价值分段与销售时间的关系图
上图可见用户的药品价值分段与销售时间情况符合聚类的属性划分,效果显著.价值分段较低的药品,销售的时间也比较短.本文提出的算法在出现跨区域冗余数据属性干扰的情况下,具有一定的优势.
4 结束语
提出了一种基于k-medoids与c5.0联合约束的药品价值分析与挖掘的方法,通过进行高效的药品数据预处理,使用更加具有鲁棒性的k-medoids与c5.0数据挖掘方法,将聚类的方法使用在决策树的构造与决策分析中,这样就避免了因为数据前后处理不一致,而造成的失真与噪声过大导致挖掘效果不明显的情况.实验表明,这种方法能够有效提取出药品特征信息并进行准确分类,具有较高的识别准确率,取得了满意的结果,具有较高的使用价值.
[1]李莉.中药材质量控制方法发展状况分析[J].社区医学杂志,2011,(3):54 -55.
[2]梁志瑞,陈鹏,苏海锋.关联规则挖掘在电厂设备故障监测中应用[J].电力自动化设备,2006,(6):17 -19.
[3]陈果.基于遗传算法的支持向量机分类器模型参数优化[J].机械科学与技术,2007,(3):347 -350.
[4]陈金波.面向电信CRM的数据挖掘应用研究[D].南京:东南大学博士学位论文,2006.
[5]王晓华,苏宏业,渠瑜,等.面向电信欠费挖掘的数据质量评估策略研究[J].计算机工程与应用,2011,(12):220 -224.
[6]黄江波,付志红.基于自适应遗传算法函数优化与仿真[J].计算机仿真,2011,(5):237 -239.
[7]徐光宪,刘建辉.数据挖掘在电信客户关系中的应用[J].中国数据通信,2005,(4):44 -47.
[8]唐慧慧,郭希娟.基于最优模板选择和水平集的图谱分割算法[J].计算机仿真,2009,(3):213 -216.
[9]何尧,赵跃龙.一种新的Web用户行为模式挖掘算法的研究[J].计算机测量与控制,2005,(6):600 -602.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
铁道通信信号(2019年6期)2019-10-08
制导与引信(2017年3期)2017-11-02
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
工业设计(2016年11期)2016-04-16
信息通信技术(2015年6期)2015-12-26
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
