
基于父节点的XML查询优化算法⋆
2012-07-30 04:06:44宗传霞
电子测试 2012年7期
宗传霞
(烟台南山学院,山东龙口 265713)
0 引言
XML 文档中的关键词检索是以XML 元素为粒度来返回检索结果的,即在返回检索结果时,并不需要将整个文档返回给用户,而只需返回用户感兴趣且符合检索条件的元素集即可,该集合可以看作是原文档的一个片段。因此,XML文档中的关键词检索不但可以使得检索结果更为准确,也使得传输的数据量大大减小。基于父节点的XML 查询优化算法的目的就是返回用户在XML 文档中的最小子树根节点,从而查询出对应于最小子树根节点的最紧致片段。
在XML 查询优化算法中,典型算法主要分为基于索引的搜索算法、基于堆栈的算法和基于扫描的算法。
基于索引的搜索算法基本思想是将XML 数据保存到B+树结构,插入B+树的数据形式为(key,dewey),这相当于将XML中的数据按照关键词(keyword)和关键词在XML 树中的节点Dewey码进行排序[1]。之后,借助于B+树结构以及Dewey 码的基本运算(大于、小于、子孙码、公共前缀等)计算最小子树根节点。但是,这种算法必须修改B+树结构来支持Dewey 码操作,实现比较复杂。基于堆栈的算法主要是利用栈来进行存储,操作起来相对简单。但是,这种算法空间复杂度很高[2]。基于扫描的算法在时间复杂度和空间复杂度方面都不是很理想[3]。相对来说,在这3种算法中,基于索引的搜索算法应用比其他两种算法广泛。
鉴于这种情况,改进XML 信息查询技术具有必要性和紧迫性,这是基于父节点的XML 查询优化算法研究的主要动力。本文以如何提高其数据信息的查询效率为目的,描述了一种既能够在保证查全率的同时又对其查准率有所提高的基于父节点的XML 查询优化算法。
1 查询方案
基于父节点的XML 查询优化算法,首先根据关键词的个数分别进行标记,以便区分不同的关键词。然后,根据关键词的顺序,依次查找关键词在XML 树叶节点中出现的次数并且进行标记。这里分两种情况:第一,如果关键词在XML 树叶节点中出现的次数不相同,那么关键词出现的最小次数就是最小子树根节点的个数;第二,如果关键词在XML 树叶节点中出现的次数相同,那么该次数就是最小子树根节点的个数。
其次,按照关键词顺序依次查找它们对应的父节点,如果父节点的标记没有包含所有关键词的标记,则继续进行查找,直到达到第二层,或者查找完最小子树根节点为止。这里主要分为两种情形:第一,如果关键词在XML 树中叶节点所在层数不一致,那么向上一层查找父节点时,就一定有关键词查找的父节点先到达第二层,这时候,该关键词不用再去查找它的祖先节点,它需要做的是等待其他关键词继续寻找其父节点。然后,验证自己已经标记过的节点和其他关键词标记过的节点标记有没有同时出现。如果查找的各个关键词标记在同一个父节点出现,那么该节点就是最小子树根节点,从而根据最小子树根节点得出对应的最紧致片段;第二,如果关键词在XML树中叶节点所在层数一致,那么在向上一层查找父节点时,就仅仅需要按照关键词的顺序循环查找父节点并且进行标记,等出现包含所有关键词标记的父节点时,即为最小子树根节点,从而根据最小子树根节点得出对应的最紧致片段。
此时,该关键词组集合的最小子树根节点求解完成,从而也得到了它们对应的最紧致片段。
2 算法步骤及其流程图
下面是基于父节点的XML 查询优化算法的算法步骤。
(1)为n个关键词进行标示,标记为k1,k2,…,kn以便区分不同的关键词。
(2)依据k1,k2,…,kn的顺序进行循环查找父节点,并且父节点也按照关键词的顺序依次标记,分别为k1,k2,…,kn。
(3)查找出的父节点集合两两求交集。如果父节点集合交集为空,则继续求查找出的父节点的父节点,也就是关键词的祖先节点;如果父节点集合交集不为空,则记录下来,然后再去求关键词的祖先节点。当进行到第二层,或者父节点集合中任何一个集合为空集时,循环结束,计算终止。
(4)把求得父节点集合的交集组成一个集合,它就是所求的最小子树根节点集合,进而根据所得的最小子树根节点得出用户所需的最紧致片段。
根据基于父节点的XML 查询优化算法的算法步骤设计的详细流程图,如图1所示。
3 实验
为了验证改进的效果,本文对基于索引的搜索算法、基于堆栈的算法、基于扫描的算法、基于父节点的XML 查询优化算法进行了实验对比和分析。
3.1 实验结果
实验平台是Windows VistaTM Home Basic,Intel(R) Core(TM)2 Duo CPU T5800@2.00 GHz 2.00 GHz,内存(RAM)2.00GB,32位操作系统,160GB 硬盘。开发工具是在Microsoft Visual Studio.NET 2003(实现语言为vb.net),Microsoft SQL Server 2000环境下设计并实现的。
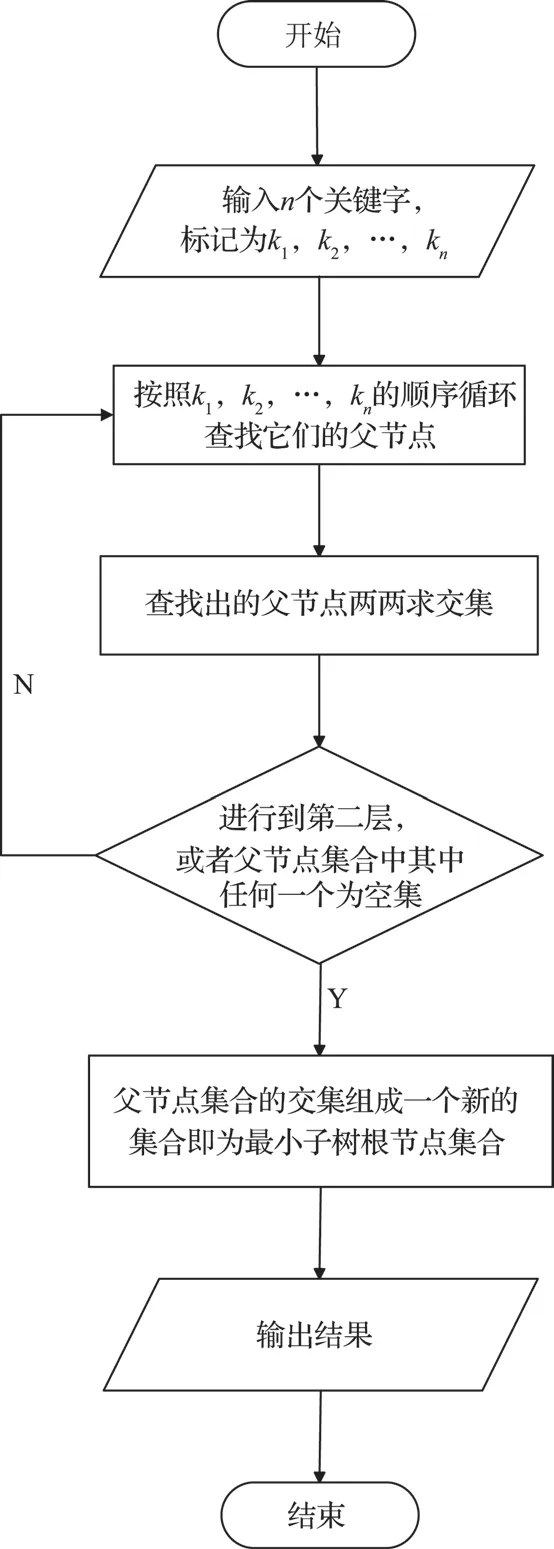
图1 流程图
INEX(Initiative for the Evaluation of XML Retrieval的缩写)[4]是XML 信息检索中具有代表性的文档集,其资源的核心内容是从1995年到2000年出版的1.2万篇期刊文章。本文选取INEX 2006上的Wikipedia XML 文集进行实验的测试,整个文集是由八种不同语言部分组成。本文选择以英语文集为主要的实验对象。该实验数据集共包含659388篇文章,约4600 MB 大小,文档的平均大小约为7.1 M,平均深度为6.732层。
在进行的XML 查询优化算法时,实验数据的装入是通过调用基于事件的XML parser 来实现的,它分析XML 文档,实现对元素节点的编码和元素索引记录的插入[5-8]。表1是XML 查询优化算法实验对比结果。

表1 XML查询优化算法实验对比结果
最后,实验得出,基于父节点的XML 查询优化算法不论是从内存占有率、数据准备时间还是时间复杂度方面,都优于其他3种算法,是一种行之有效的算法。
3.2 实验分析
本文提出的基于父节点的XML 查询优化算法比基于索引的搜索算法具有更高的查准率。另外通过实验也得出,只有用户输入的查询关键词大于等于五个时,这种查询优化算法才能发挥出它的优势。
下面是10组数据的查询,查询内容如表2所示。

表2 其它10组查询内容
对实验数据进行统计分析,虚线表示基于索引的搜索算法,实线表示基于父节点的XML 查询优化算法。如图2所示。
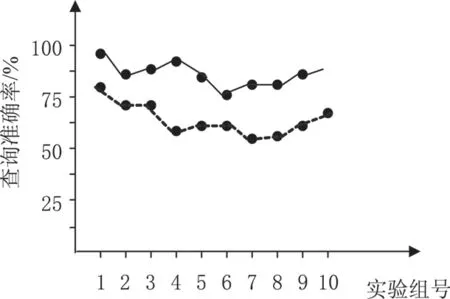
图2 统计结果分析
4 结论
基于父节点的XML 查询优化算法,主要是根据关键词的顺序依次求父节点,并且把求得的父节点进行标示,然后再根据关键词的顺序依次求父节点并且进行标示,持续循环,直到求得的父节点标示为所有关键词的标示为止。这时,该父节点即为所求的最小子树根节点,进而根据最小子树根节点得出对应的最紧致片段。
通过实验验证,该算法在内存占有率、数据准备时间、时间复杂度方面都有一定程度地提高。与传统的XML 查询优化算法相比,它的查询结果更为准确,更符合用户的需要。
[1]王国仁,于戈,杨晓群,等.XML数据管理技术[M].北京:电子工业出版社,2007.
[2]基于堆栈的查询算法,http://bbs.pediy.com/archive/index.phy?t-52885.com.
[3]江腾蛟,万常选.针对XML文档集的关键词检索结果排序[J].软件技术与数据库,2007,33(2):59-61.
[4]G.Gou,R.Chirkova.Efciently Querying LargeXml Data Repositories:ASurvey[J].IEEE Trans.Knowl.Data Eng,2007,19(10):1381-1403.
[5]万常选,鲁远.基于权重查询词的XML结构查询扩展[J].软件学报,2008,10(19):2611-2619.
[6]沈剑沧,鲍培明.XML查询方法的设计与研究[J].计算机工程,2007,21(33):63-65.
[7]宗传霞.基于编辑距离的XML查询方法[J].电子测试,2011(3):1-4.
[8]郭俊文,衡星辰,邵利平,等.一种基于XML文档聚类的XML近似查询算法[J].计算机工程,2006,32(15):52-54.
猜你喜欢
小学科学(学生版)(2021年10期)2021-12-28 15:01:27
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
少儿画王(7-10)(2020年11期)2020-09-13 02:44:51
意林(儿童绘本)(2019年10期)2019-12-23 09:03:40
学生天地(2019年28期)2019-08-25 08:51:00
小哥白尼(野生动物)(2018年8期)2018-09-10 05:52:40
小溪流(画刊)(2018年3期)2018-06-29 06:38:56
幼儿画刊(2017年10期)2017-10-18 00:46:02
电测与仪表(2015年15期)2015-04-12 00:43:48
河北科技大学学报(2015年5期)2015-03-11 16:16:37
