
网络信息分级过滤系统的研究与实现
2012-07-25 03:19卢秉亮张春宇
微处理机 2012年2期
朱 健,卢秉亮,张春宇
(1.沈阳航空职业技术学院,沈阳110034;2.沈阳航空航天大学计算机学院,沈阳110136;3.中国电子科技集团公司第四十七研究所,沈阳110032)
1 引言
随着Internet的迅速发展和用户对网络信息安全需求的不断增加,信息过滤以及相关技术取得了很大进展。Denning于1982年提出了“信息过滤”[1]的概念,利用“内容过滤器”对实时的电子邮件进行信息过滤。1987年,Malone等人研制了基于内容过滤(Content-based Filtering)的“Information Lens”[1]。上世纪八十年代末,由美国 DARPA(高级研究计划局)资助的“Message Understanding Engineer”[3]极大地推动了信息过滤技术的发展。在我国,清华大学的曾春等根据不同用户的兴趣不同及多样性的特点,提出了基于内容的个性化搜索算法[4],田范江等人从用户要求的不同角度出发完善算法,不断提高信息过滤的质量和速度[5]。
2 内容过滤技术
2.1 包过滤技术
网络上的内容信息是以数据包(Packet)进行传送的。每个包都有一个源IP地址和一个目的IP地址,包过滤可以通过检查数据包的IP地址来过滤信息内容。但IP地址和内容并不是一一对应关系,往往会对合法内容造成误判,不能满足基于内容安全的保护需求,需要采用内容过滤技术。
内容过滤是对应用层内容协议中所传输的信息内容进行分析,并根据预先设置的过滤条件,控制信息的下一步传送方向。内容过滤主要有两种实现形式:白名单(White List)也称为包含过滤 (Inclusion Filtering),只有在此名单中的信息才能被访问,具有较高的安全性,但“白名单”数据量大,在进行关键字匹配时需要较多的时间,影响了网络速度,同时也增大了维护的代价。“黑名单”(Black List)也称为排除过滤(Exclusion Filtering),是目前比较常用的过滤策略,其思想是将影响到网络安全的信息加入黑名单,使其不能被其他网络用户访问,对于那些不在黑名单中的信息都可以被访问到。很明显,这个黑名单将小得多,但需要对黑名单不断更新以保证其安全性。
2.2 关键字过滤
关键字过滤就是对信息的内容进行关键字匹配,通常用黑名单来实现。只要站点包含有与关键字相匹配的信息,它就会被禁止访问。
2.3 URL过滤
IP和URL数据库过滤是根据用户的需求把用户认为有问题、有危险性的IP地址或URL进行控制,一旦发现有该IP地址或URL的网页则立即将其过滤掉。因为URL对应的是具体的网页而不是网页所在的服务器,克服了传统包过滤的缺点,大大提高了过滤的准确性。
3 网络信息分级过滤系统的设计与实现
网络信息过滤系统必须要保证众多用户同时与互联网联网时的速度和质量,为保证信息过滤的准确性和高效性,系统采用分级匹配过滤的策略,在保留IP地址、URL和关键字过滤的基础上,增加内容分析过滤。其过滤的过程如图1所示。
3.1 关键字、IP过滤、URL过滤
首先建立信息关键字数据库、非法网页的IP数据库和URL数据库,当信息进入到过滤系统所在的服务器缓存中时,系统首先将此信息与服务器中IP、URL数据库、关键字数据库进行比对。如果与关键字数据库中的关键字相同或网页的IP、URL与数据库中的某IP、URL相同时,系统就会屏蔽这个信息,这样就免除了重复过滤,缓解了系统压力,提高了响应速度。
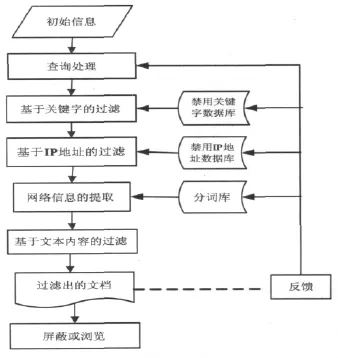
图1 系统主要过程图
3.2 网络协议识别
应用层的内容过滤与网络端口处理相比,要求大量的计算资源,如果在网络边缘对内容进行处理,带来的问题是必然导致性能下降。为了能够对应用层数据进行内容过滤,突破内容处理障碍,达到实时分析网络内容和行为,首先需要识别应用层协议类型,然后针对不同的协议给出相应的具体处理方法。一般的协议类型识别方法是利用RFC规定的协议默认端口来判断协议的类型,然而这种方法的准确性并不高,系统通过增加对后续数据报文内容的分析来综合判断协议类型。
相对于网络层的协议而言,应用层的协议没有统一的表示来表明协议的类型,除了少数协议,如DNS和SMTP协议可以通过TCP连接的目的端口判定以外,其他的协议均可以变换连接端口,比如HTTP协议默认使用80端口,但是实际应用中,也可以采用1080、8080等其他端口。因此,对于应用层协议的判定要通过对数据内容进行分析来进行协议识别,如图2所示,每个数据报文按自上而下的顺序依次传递给处理子程序进行网络协议识别并进行相应的处理。
当捕获到一个TCP连接的建立信息时,系统将这个连接建立的信息提交所有的TCP协议处理子程序进行处理。所有的子程序都必须对当前连接的内容进行处理,判定当前连接的类型是否是自己所能处理的协议。如果不是,则通知系统放弃当前连接的处理权,如果子程序识别出当前连接的协议和其所能处理的协议吻合,则通知系统获得对当前连接的处理控制权。对于那些根据当前信息还不能进行有效判断的连接,则通知系统等待更多的数据到来以完成有效的判断,直到找到当前连接的处理子程序或者所有的处理子程序均放弃对当前连接的处理权为止。
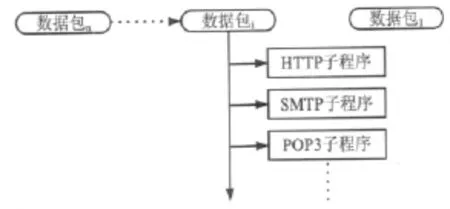
图2 TCP报文识别
3.3 基于内容的信息过滤
对于经过关键字过滤和IP、URL过滤后仍无法确认该信息是否合法,则继续进行基于文本内容的过滤,即将被测文本分词与分词字典进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
系统采用KNN(K-Nearest Neighbor)这样一种基于统计的模式识别算法,其基本思想是:在给定新文本后,考虑在训练文本集中与该文本距离最近(最相似)的K篇文本,根据这K篇文本所属的类别来判断新文本所属的类别。也就是说,把每一篇文本都看作是一个N维向量,计算新文本与这K篇文本之间的距离,通过这些距离和K篇文本所属的类别来确定新文本的类别。具体的算法步骤如下:
1)根据特征项集合重新描述训练文本向量。
2)当出现一个新文本后,对新文本进行分词处理,分词的依据是使用特征词,进而确定新文本的向量表示。即使用向量空间模型,文本用向量表示。
3)在训练文本集中选出与新文本最相似的K篇文档,计算文本相似度,可转换为两个文本向量的夹角余弦值。给定文本 di(di1,di2,…din)和dj(dj1,dj2,…djn)的相似度计算公式为:

4)在新文本的K个邻居中,依次计算权重,计算公式为:
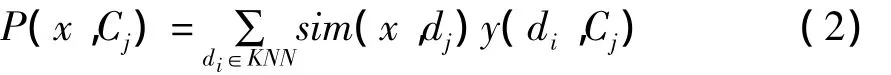
其中,x为新文本的特征向量,sim(x,d)为相似度计算公式,Y(di,Cj)为类别属性函数,如果di属于类Cj,那么函数值为1,否则为0。
5)对类的权重进行比较,将文本分到权重最大的那个类别中。
在具体操作中,按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;系统采取双向最大匹配分词策略[6],如果两者切分结果相同,说明没有歧义,直接输出分词结果。如果不一致,则输出最短路径的那个结果,如果长度相同,则选择少的那一组切分作为结果。如果单字也相同,则选择正向分词作为结果。
4 测试
内容过滤服务器端使用Win2003 server操作系统,利用Winpcap进行抓包。测试方案从Internet上整理600份网页作为测试库,其中,正常网页、非法网页各300份。利用开发出的系统对这600份网页进行过滤,以测试该过滤系统的性能。
英国学者克里维顿(C.M.Cleverdon)首次将查全率(Recall)和查准率(Precision)[7]作为信息检索和过滤系统效率的评价指标以后,这两个指标就一直成为对信息系统进行评价和试验的重要指标。查全率指系统在实施某一检索作业时,检出相关文献的能力;查准率指系统在实施某一检索作业时,拒绝不相关文献的能力,分别用公式(3)和公式(4)表示。

文献[8]使用了另外一种评价指标,如公式(5)所示。

对于这三个评价指标,可以得到相应的测试结果,如表1所示。

表1 测试结果表
由测试结果可以看出,查全率达到85%以上,准确率达到87%以上,F1的值达到了86.671%(一般情况下要求F1的值达到75%以上),此方案的过滤效果比较理想。
5 结束语
系统利用Winpcap对进出网络的信息进行数据包的抓取,采用分阶段过滤策略,通过对查准率和查全率的测试,实验结果表明过滤效果比较理想。由于在一个报文的匹配中,最为耗时的匹配运算是在报文中匹配多个串,为了提高响应速度,可以考虑引入AC算法、WM算法等多模匹配算法。
[1] 刘辉.网页信息过滤系统的研究与设计[D].江苏:苏州大学,2009.
[2] 黄晓明,夏明春.网络信息过滤的成本效益分析[J].情报科学,2003,21(11):1129-1132.
[3] Lynette Hirschman.Comparing MUCK- Ⅱ and MUC-3:Assessing the difficulty of different tasks[C].Proceedings of the 3rd Conference(MUC-3).DARPA,Morgan Kaufmann,1991:25-30.
[4] 曾春,刑春晓,周立柱.基于内容过滤的个性化搜索算法[J].软件学报,2003 14(5):999-1004.
[5] 田范江,李丛蓉,王鼎兴.进化式信息过滤方法研究[J].软件学报,2000,11(3):328-333.
[6] 冯是聪.搜索引擎个性化查询服务研究[J].计算机应用,2002(3):45-50.
[7] Thorsten Joachims.Text Categorization with Support Vector Machines:Learning with Many Relevant Features[C].The 10th European Conference on Learning(ECML),1998.
[8] 贾美娟,李娟.基于分级匹配的信息过滤研究[J].大庆师范学院学报,2007,27(5):14-17.
猜你喜欢
华人时刊(2022年1期)2022-04-26
校园英语·月末(2021年13期)2021-03-15
铁道通信信号(2020年11期)2020-02-07
动漫界·幼教365(大班)(2019年10期)2019-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
网络安全和信息化(2018年3期)2018-03-03
黑龙江电力(2017年1期)2017-05-17
科学中国人(2017年14期)2017-01-28
环球时报(2009-11-25)2009-11-25
