
基于日志挖掘的打印管理系统的分析与设计
2012-07-04 03:26:56唐维燕
电子工业专用设备 2012年5期
唐维燕
(中国电子科技集团公司第四十五研究所北京100176)
1 原型系统的总体结构
本系统采用了WMI 和数据挖掘技术,对打印服务器的系统日志进行分析,用以进行打印任务查询、打印成本分摊、设备使用情况分析等打印管理工作。打印管理系统主要由前端、后端的打印管理控制台和打印日志数据库及打印服务器组成。前端主要包括收集查询条件、统计打印信息和打印分析展现等3 个部分。后端主要由日志数据库管理、日志查询统计分析处理、日志记入数据库、日志文件保存与备份、日志挖掘与分析等5 个部分组成。原型系统总体结构如图1 所示。

图1 系统总体结构图
本文讨论的重点在于数据挖掘过程中打印日志数据准备、数据预处理、挖掘和分析部分,着重探讨如何进行打印日志的数据准备、挖掘和分析。其中涉及的功能模块包括:
●打印管理前端:一个人机对话的窗口,提供可视化的界面。
●数据库管理模块:提供数据的可维护功能。
●数据预处理模块:根据对打印管理信息的需要,利用WMI 对打印服务器的系统日志记录中关于打印数据信息进行提取和预处理,包括数据的清洗、归约、交换、集成等功能。
●数据挖掘模块:对日志数据源进行关联挖掘分析,以得到有用的信息。
●日志查询统计模块:对经过数据挖掘和分析的日志记录依据查询条件计算、分析、汇总。
2 WMI
本系统的打印日志数据准备借助WMI 技术实现。WMI (windows management instrumentation,Windows 管理规范) 是内置在Windows 2000、Windows XP 和Windows Server 2003 系列操作系统中核心的管理支持技术,它基于Distributed Management Task Force (DMTF) 所监督的业界标准,WMI 是一种规范和基础结构,通过它可以访问、配置、管理和监视几乎所有的Windows 资源,如计算机系统、磁盘、外围设备、事件日志、文件、文件夹、文件系统、网络组件、操作系统子系统、性能计数器、打印机、进程、注册表设置、安全性、服务、共享、SAM 用户和组、Active Directory、Windows 安装程序、Windows 驱动程序模式(WDM) 设备驱动程序,以及SNMP 管理信息基(MIB) 数据等。WMI 体系结构由3 个主层组成,如图2 所示。
下面重点阐述一下WMI 体系结构中最重要的中间层——WMI 基础结构。WMI 基础结构由3个主要组件构成:公共信息模型对象管理器(Common Information Model Object Manager,CIMOM)、公共信息模型(Common Information Model,CIM)储存库、提供程序,以及WMI 脚本库。前3 个WMI 组件共同提供通过其定义、公开、访问和检索配置和管理数据的基础结构,第4个组件WMI 脚本库是编写脚本绝对不可或缺的部分。

图2 WMI 体系结构
2.1 WMI 提供程序
WMI 提供程序在WMI 和托管资源之间扮演着中间方的角色。WMI 提供程序使用托管资源本机API 与其相应的托管资源通讯,使用WMI 编程接口与CIMOM 通讯。例如,内置的事件日志提供程序调用Win32 事件日志API 来访问事件日志。
提供程序通常作为驻留在%SystemRoot%system32wbem 目录中的动态链接库 (DLL) 实现。WMI 包括很多针对Windows 2000、Windows XP以及Windows Server 2003 系列操作系统的内置提供程序。内置提供程序(也被称为标准提供程序),从已知的操作系统源(如Win32 子系统、事件日志、性能计数器、注册表等)提供数据和管理函数。
2.2 CIMOM
CIMOM(读作see-mom)处理使用者和提供程序之间的交互。所有的WMI 请求和数据都经过CIMOM。Windows Management Instrumentation 服务 (winmgmt.exe),在Windows XP 和Windows Server 系列操作系统上提供了CIMOM 角色,在通用服务主机进程 (svchost.exe) 的控制下运行。管理应用程序、管理工具和脚本调入CIMOM 以挖掘数据、订阅事件或执行一些其他的与管理相关的任务。
2.3 CIM 储存库
WMI 的基本思想是——可以用一个架构统一表示来自不同源的配置和管理信息。CIM 就是这个架构,还调用了模型化托管环境和定义每个由WMI 公开的数据块的对象储存库或类存储。该架构基于DMTF 公共信息模型标准4。与建立在类概念基础上的Active Directory 的架构非常相似,CIM 由类组成。然而,不同于Active Directory类表示创建并存储在目录中的对象,CIM 类通常表示动态资源。就是说,资源的实例并不存储在CIM 中,而是通过基于使用者请求的提供程序动态检索。这是由于大多数WMI 托管资源的操作状态更改很频繁,因而必须按需读取以确保检索的是最新的信息。
与Active Directory 类相似之处还有就是,CIM 类是分级组织的,每一级的子类从父类继承。DMTF 维护一组核心和公共基类,系统和应用程序软件开发人员(如Microsoft 的那些)从这些类派生和创建系统(或应用程序)特定的扩展类。
2.4 WMI 脚本库
WMI 脚本库提供自动化对象集,脚本语言(如VBScript、Jscript 及ActiveState 的ActivePerl)利用它访问WMI 基础结构。
WMI 脚本库在一个名为wbemdisp.dll 的单个DLL 中实现,该DLL 物理驻留于%SystemRoot%system32wbem 目录中。WMI 脚本库还包括一个名为wbemdisp.tlb 的类型库。可以使用WMI 脚本类型库来从基于XML 的Windows 脚本文件(扩展名为.wsf 的WSH 脚本)引用WMI 常数。
本系统就是利用VBScript 语言访问WMI 基础结构,从打印服务器的Windows Server 2003 操作系统的系统日志中提取打印相关数据信息。核 心代码如下:

3 数据预处理模块设计
数据源准备部分是整个日志分析的基础,它为后续的分析模块提供真实可靠、适宜的挖掘数据源。数据挖掘中的预处理阶段主要是接收并理解用户的知识发现需求,确定发现任务,抽取并处理与任务有关的数据源,根据背景知识中的约束性规则对数据进行合法性检查,通过清洗、归约、集成等操作,生成供数据挖掘核心算法使用的目标数据,即知识基。知识基是原始数据库经数据汇集处理后得到的二维表,纵向为属性,横向为记录。它汇集了原始数据库中与发现任务相关的所有数据的总体特征,是知识发现状态空间的基底,也可以认为是最初的知识模板。
3.1 数据预处理方法
一般系统的日志信息量非常庞大,并且存在杂乱性、重复性和不完整性的问题。由于系统日志中记载的原始数据来源不一,有关于硬件、软件和系统问题的日志,以及反应系统中发生的事件等等,这些信息源的配置并不完全相同,所产生的日志信息存在一定的差异,因此有些数据显得杂乱无章,这是日志杂乱性问题所在。重复性是指对于同一个客观事物在系统中存在两个或两个以上完全相同的物理描述,这样就带来了数据的重复和冗余问题。不完整性是由于实际系统存在的缺陷以及一些人为因素造成的数据记录的缺失,或者数据记录中出现数据属性值的丢失或不确定的情况。为此,我们需要对这些原始的数据源进行数据预处理,通过数据清理、数据归约、数据变换、数据集成等方法,对系统的打印日志信息进行预处理,产生可供挖掘和进一步处理的数据源。
●数据清理的任务是要去除源数据即打印日志信息数据中的噪声数据和无关数据,处理遗漏数据和清洗脏数据,去除空白数据和在知识背景上的白噪声,考虑打印日志信息的时间变化和它们的数据变化,主要是对重复数据和缺值数据进行处理,去除重复数据记录,填补缺省数据。
●系统日志中有些数据属性对打印分析没有什么作用,但会大大影响数据挖掘效率,甚至可能导致数据挖掘结果的偏差,产生误导作用,因此,有效地对数据进行简化是很有必要的。数据归约简化是在对发现任务和数据本身内容理解的前提下,最大限度地精简数据集。分别对系统打印日志信息中的属性和记录进行简化,对数据的属性进行剪枝、并值等相关操作。剪枝就是去除对提取打印相关信息没有贡献,或者贡献率很低的属性值。并值就是把相近的属性进行综合归并处理。
●在系统日志信息中,有些属性域需要做一定的变换处理,使得挖掘的结果能够合乎我们的习惯逻辑和表达,如在系统日志记录中,时间维的属性值总是表示为一个精确到秒级的数值,但是在某些情况下,我们不需要知道如此精确的时间,而只需要知道大致的时间范围段,比如以一天这样的时间段划分,所以我们要根据需求,做一定的数据变换工作。数据变换也属于概念分层的范围,即通过收集并用较高层的概念替换较低层的概念来定义数值属性的一个离散化。概念分层可以用来归约数据,通过这种概化,尽管细节丢失了,但概化后的数据更有意义,更容易理解,并且所需的空间比原数据少。
●数据集成主要是将多个文件中的异构数据源进行合并处理,解决语义的模糊性。该部分主要涉及数据的选择,数据的冲突性以及数据的不一致性问题处理。
在实际的数据挖掘应用中,数据清理、数据集成和数据归约不一定都用到,需要根据实际情况和需求,合理地对源数据进行预处理。
3.2日志记录预处理和特征提取
在系统日志中,每一条记录都包含一些主要的属性信息和一些次要的信息,如来自系统打印日志的一条记录可能包含:事件类别、计算机名、日志事件代码、日志信息、日志记录编号、日志来源、时间、请求类型、用户名等信息。但是在打印管理分析中,有些信息不是非常重要的,比如事件类别和日志事件代码等;有些信息则可以通过预处理中的概化方法,比如对时间信息,我们可以进行概化处理,方便挖掘;而计算机名、用户名、日志来源等则是一些关键信息,必须保留原始样式。同时对于日志信息,这些内容格式不固定的记录需要进行日志记录的规范化预处理(如图3 所示)。

图3日志规范化处理流程模块图
规范化格式处理的目的是为了达到以下几个目标:完整性、可扩展性、简单性。完整性要求规范化处理后的打印日志包含所有的需要信息,否则这个日志在打印分析中就不可用。可扩展性是要求这种方法必须能容纳不同的日志内容使日志在类型上不受限制。简单性是要求规范化格式处理后的日志,要容易被后面的挖掘算法处理分析,同时也方便打印日志数据库的设计实现。在具体系统实现时,可以作为用户自定义在对原始日志进行规范化格式处理的同时,得到所需的信息。
4 挖掘与分析平台设计
完成数据源的准备工作后,采用关联分析方法从这些数据中找出各个数据项之间的关联规则,从而获得打印数据之间存在的关联信息;然后采用分类算法对所有数据进行分类分析,建立分类模型,对打印日志数据做进一步分类。其实应用于打印分析的数据挖掘方法并不局限于这几种,其他如聚类、估计、预测方法等挖掘算法,也将随着打印分析研究的深入和挖掘算法的进一步完善,会得到更好的应用。
因此在设计挖掘与分析模块的时候,充分考虑到将来的发展趋势,着眼于系统的伸缩性和可扩展性,采用分层结构的框架来设计挖掘和分析平台,将挖掘分析应用部分分为四个层次:数据层、挖掘算法层、挖掘任务层、模式表示层。框架结构如图4 所示。
●数据层:经过规范化预处理的日志数据,为挖掘数据源部分。
●挖掘算法层:提供关联规则、分类算法、聚类算法等挖掘算法的具体实现,以接口的形式提供给挖掘目标层的任务挖掘。
●挖掘任务层:根据具体的挖掘任务,利用挖掘算法层提供的算法,对挖掘数据源进行日志属性的内部关联挖掘、时间序列挖掘、异常检测、日志分类或聚类分析、统计计算等.
●模式表示层:把挖掘得到的结果以易于用户理解的直观方式呈现给用户,便于用户对模式进行评估和分析。
以分层结构来设计挖掘分析平台,结合了打印管理分析工作的特点和数据挖掘技术快速发展的现况,既满足了现阶段数据挖掘在打印管理领域的应用,也增加了整个系统方案的灵活性和可扩展性。
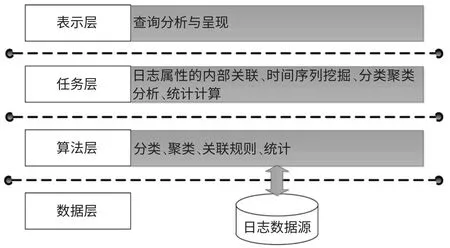
图4 挖掘层次分析结构框架图
5 小 结
本文以打印管理的实际功能需求,讨论了基于日志的打印管理原型系统设计中应该考虑和需要解决的几个问题,以数据挖掘的技术要点和过程为出发,从利用WMI 对数据源的提取准备、数据预处理、数据挖掘分析方法的实现这三部分来分析和设计基于网络共享的打印管理原型系统,着重讨论了各个功能模块的设计思想和使用的技术。利用WMI 获取系统日志只是WMI 应用中很小的一块,通过它可以访问、配置、管理和监视几乎所有的Windows 资源,本文作者在此借助这个打印管理系统抛砖引玉,希望大家利用WMI“深度挖掘”Windows 系统的各项“潜能”,实现更便捷的管理。
[1] 林晓东,刘心松.文件系统中日志技术的研究[J].计算机应用,1998,118(1):28-30.
[2] 张施展,高景昌. 基于WMI 技术的计算机自动化管理[J];吉林大学学报(信息科学版);2006,24(4):451-456.
[3] Han Jiawei,Kamber M 数据挖掘概念与技术[M].范明,盂小峰译,北京:机械工业出版社,2001
[4] 屈定春,林原. 一种新型的数据库应用——数据采掘.计算机应用研究,1996(6):8-11.
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
大众投资指南(2021年35期)2021-02-16 01:06:26
心声歌刊(2020年4期)2020-09-07 06:37:14
计算机与生活(2018年3期)2018-03-12 08:38:11
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
电力与能源(2017年6期)2017-05-14 06:19:37
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
信息通信技术(2015年6期)2015-12-26 01:16:46
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
电子设计工程(2014年19期)2014-02-27 12:00:42
