
基于双语平行语料的中文缩略语提取方法
2012-06-29 01:37刘友强陈家骏
中文信息学报 2012年2期
刘友强,李 斌,2,奚 宁,陈家骏
(1. 南京大学 计算机软件新技术国家重点实验室,江苏 南京 210093;2. 南京师范大学 语言信息科技研究中心,江苏 南京 210097)
1 引言
缩略语是短语或词的全称的缩写形式,如“中国”简称“中”。由于其省时省力的效果,在自然语言中被广泛使用,是未登录词的主要来源之一。据研究,在一篇典型的中文新闻文章中,近20%的句子包含缩略语[1]。而未登录词对于中文的自动分词与词性标注等词法句法分析任务有很大地影响,这使得中文缩略语有较大地研究价值。
一般来说,现代中文缩略语的构成方式主要有四种。(1)语素方式: 缩略语由原词语各部分的语素构成。例如,奥林匹克 运动——奥运;(2)中心词方式: 缩略语由原词语核心的词构成。例如,人造 地球 卫星——人造卫星;(3)混合方式: 缩略语由语素和中心词构成方式混合使用而得。例如,中央 电视台——中央台;(4)合并方式: 缩略语由原词语中的并列词归纳而得。例如,包退、包换、包修——三包。
从整体上看,缩略语研究可以分为缩略语的探测识别、简称—全称的对应(还原生成)两大类工作。在缩略语的探测识别方面,Zhu,et al.针对单字人名、地名简称,采取了基于分类器的预测模型[2];李斌等对汉语单字国名采取了统计评分法进行识别[3]。缩略语的自动识别研究工作主要集中于缩略语的“简称—全称”的还原、生成工作以及缩略语词典的自动构建。在还原、生成方面,Chang 和 Lai将缩略语的生成和还原问题转化为隐马尔可夫模型(HMM)问题,使用缩略语词典进行训练[1]。支流等设计了一个基于模糊匹配的缩略语还原算法,从缩略语上下文和缩略语词典中获得备选的全称[4]。在缩略语词典自动构建方面,崔世起等针对未登录词,在生语料中使用重复串搜索技术和词性过滤获得候选缩略语集和全称短语库,再利用语言模型和对齐模型进行候选缩略语和全称短语的对齐,最后得到148对缩略—全称语对,准确率为51.4%[5]。武子英等从词性标注语料中获得候选缩略语集和全称短语库后,利用上下文的相似度对缩略语和全称短语配对,从而获得缩略语词典,准确率达到74.1%[6]。这两种方法都是在汉语单语文本上的工作,有两点不足。(1)缩略语的采集效率比较低。多重视“简称—全称”的对应,而作为对应前提的简称的自动识别则研究较少;(2)仅使用单语的缩略规则模板,导致准确率不是很高。
中文缩略语的大量存在对汉-外统计机器翻译也造成一定的影响。Li et al.提出了一种获得中文缩略语英文翻译的方法[7]。该方法首先识别英文语料中的实体,并翻译为中文短语,以此作为全称短语。然后,根据中文单语语料中短语的共现信息提取出缩略语,以英文实体为其翻译。该方法的目的是获得候选缩略语的英文翻译,因而对于缩略—全称语对的准确度要求不高。但这启示我们两种语言的翻译关系可以作为联系全称和缩略语的桥梁。
本文遵循从双语对译关系中挖掘全称—简称关系的思路,尝试找到一种准确率比较高的自动获取方法,以中文缩略语为研究对象,取得了不错的实验结果。我们首先从句对齐平行语料库中抽取出中英文短语对。然后根据短语对的一些特征训练出一个SVM分类器,将短语对根据对应的质量分为“对应”与“不对应”两类。从对应质量好的那一类短语对集合中,利用一些约束条件和英文翻译抽取中文缩略—全称语对。实验表明,该方法抽取出的缩略—全称语对有较高地准确度。
2 中文缩略语提取
从句对齐平行语料中提取中文缩略语的过程可分为三个部分: 短语对抽取,短语对分类和缩略—全称语对的抽取。
2.1 短语对的抽取
这里短语对抽取采用基于短语的机器翻译[8]的短语对抽取方法,流程如图1所示。

图1 短语对抽取流程图
抽取短语对的步骤:
(1) 对平行语料中的中文分词,英文全部换成小写字母并将符号与词分隔开(Tokenization);
(2) 利用开源的词对齐训练工具GIZAC++*http://www-i6.informatik.rwth-aachen.de/Colleagues/och/software/GIZA++.html对平行语料进行词对齐训练。词对齐训练的目标是获得语句对中词的对应关系。如图2所示,连线的词之间存在对应关系。注意,由于这里的词对齐关系是通过统计方法自动获取的,因而未必完全正确;
(3) 使用开源的机器翻译系统Moses*http://www.statmt.org/moses,抽取与词对齐信息一致的中英文短语对。比如从图2中的中文句子抽取的短语可以是“中共”、“中共 代表团”。不过,这里的短语不一定是语言学严格意义上的短语。这里的短语是指由语句中连续的一个或多个词构成的语句的子串;
(4) 合并相同的短语对,输出到文件。

图2 词对齐示例
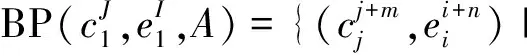
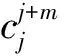
抽取短语对的过程中,为了提高效率,我们排除了那些不太可能作为一个缩略语或缩略语英文翻译的短语。排除条件有: (1)中文或英文短语中含有标点符号;(2)中文短语的边界词为“了”、“是”、“个”等三个一些不太可能作为缩略语或其全称边界的词;(3)英文短语边界词为介词,或词尾为“the”的不太可能作为缩略语或全称的英文翻译边界的虚词。
2.2 基于SVM分类器的短语对分类方法
由于语料库中的噪声以及训练出来的词对齐不可能完全正确,使得相当多的一部分中英文短语对事实上并不对应。这些并不对应的短语对会影响到后面缩略语提取的准确度和效率。因此,我们采用四个特征来衡量中英文短语对的对应质量。并据此训练出一个基于SVM (支持向量机)的分类器[10],将短语对根据对应质量分为“对应”与“不对应”两类。
对于中—英短语对C-E,其中C=c1c2…cn,E=e1e2…em,采用的四个特征为:
(1)C翻译为E的短语翻译概率,采取极大似然估计。
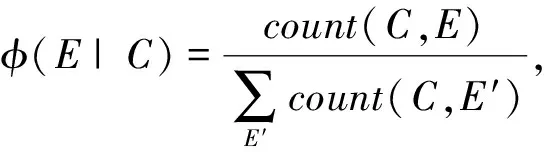
(2) 词汇化翻译概率,C中的词翻译为E中的词的概率平均值;
其中A为训练得到的C-E中词的对应关系,由于训练过程中对于相同的C,E可能有不同的对应关系,我们这里采用值最大的φ(E,A|C)作为φ(E|C)的值。其中,w(ei|ci)为根据语料词对齐信息得到的词翻译概率,采用极大似然估计;
(3)φ(C|E),即E翻译为C的短语翻译概率。
(4)φ(C|E),即E中词翻译到C中词的概率平均值。
这些特征可以较好地表征短语对齐效果,计算量不高,分类效果也不错(实验结果见3.1节)。
2.3 缩略语抽取算法
经上一节分类后得到比较可靠的中—英短语对,接下来的任务就是从这些短语对中提取出候选缩略—全称语对。算法分为两部分: 第一部分(2.3.1)抽取出一个缩略—全称语对的候选集;第二部分(2.3.2)对这个候选集进行过滤,获得一个准确度较高的缩略语词典。
2.3.1 匹配约束
我们将中文短语按字长度进行分组,长度不超过5的短语被认为是候选的缩略语。一对中文短语对C1-C2(C1为缩略语,C2为全称语)被选为一对候选缩略—全称短语对,当且仅当: (1)C1中的字都在C2中出现;(2)C1和C2存在相同的英文翻译。
2.3.2 噪音过滤
为提高缩略—全称短语对的准确性,要对其中的噪音进行过滤。我们对抽取出的候选缩略语对进行了词性标注,使用的工具为ICTCLAS*http://www.ictclas.org/。我们将候选缩略语的词性限于名词(n)、动词(v)、形容词(a)、区位词(b)及数词(m)。经过观察,我们发现抽取出的候选缩略-全称语对的一些特性。主要分为以下几类。
(1) 候选缩略语为单字的情况。此时的抽取出的候选缩略-全称语对可以分为以下几类:
1. 人名、地名等专有名词的缩略。这是单字缩略最常见的情况。例如,“阿/b-阿根廷/nsf”,“董/nr1-董建华/nr”。这一类缩略—全称语对准确性比较高;
2. 候选缩略语与候选全称有相同的意义,但不是缩略语对。例如,“园/ng-公园/n”;
3. 噪音。这类语对并不是缩略—全称的关系,是由于词对齐信息不完全正确导致的错误。例如,“他/rr-表示/v 他/rr”。这类候选缩略语和全称语的词的个数和词性往往不相同。
因此对于候选缩略语为单字的语对,我们根据词性标注的结果选取第一类,也即选取缩略或者全称词性标注为人名(nr)、地名(ns)、机构团体名(nt)及其他专名(nz)的候选语对。
(2) 候选缩略语字长为2,3,4,5的情况。此时,采用语素构成的候选缩略语正确率很高,而采用中心词构成的候选缩略语正确率较低,是大部分噪音的来源。针对这个特点,我们选取的候选缩略语对分为以下几类:
1. 候选缩略语和全称语为单个词且被均标注为人名(nr)、地名(ns)、机构团体名(nt)及其他专名(nz)。例如,“国家计委/nt-国家发展计划委员会/nt”。这里对于专名的处理要求比(1)中严格是因为专有名词的字长较长时更有可能与一些长的短语产生对应关系,尽管这些短语不是它的全称。例如,“非洲/nsf-非洲/nsf 国家/n”。同样地,长的专有名词在上下文中也经常被简称为短的非专有名词,然而,这种缩略形式并没有被固定下来。例如,“军委/n-中央军事委员会/nt”;
2. 语素构成方式。这类候选缩略—全称语对的准确率较高。根据候选全称语的词长,我们再将之分为两类。候选全称语的词长大于1时,我们直接将之选取到缩略语词典中。例如,“海基会/n-海峡/n 交流/vn 基金会/n”。候选全称语词长为1时,此时我们的选取条件是: 候选缩略语不是候选全称语的子字符串。例如,“中科院/n-中国科学院/nt”。这样做主要是为了排除主要的词重叠的候选缩略—全称语对,这类短语对意义相近,但不是缩略—全称关系。例如,“人大/n 常委会/n-全国人大常委会/nt”。
3. 混合构成方式。以混合方式构成的候选缩略语中,有很大一部分是由字长较短的缩略语和其他词组合成的短语。例如,“中国/ns 社科院/n-中国/ns 社会/n 科学院/n”由“社科院/n-社会/n 科学院/n”与“中国/ns”组合产生。这一类的候选缩略语对于缩略语词典没有太多意义。因此我们只选择候选缩略语为单个词的候选缩略—全称语对,例如,“藏族/nz-藏/b 民族/n”,从而过滤掉由字长较短的缩略语和其他词组合成的候选缩略语。
综上所述,我们结合候选缩略—全称语对的长度、词性和缩略方式,将符合如下5条规则的候选缩略—全称语对选出,过滤掉其他的候选语对。
(1) 候选缩略语字长为1,候选缩略语或者候选全称语为专有名词。例如,“埃/b-埃及/nsf”;
(2) 候选缩略语为多字,候选缩略语和候选全称语均为专有名词。例如,“中央军委/nt-中央军事委员会/nt”;
(3) 候选缩略语为多字,采用语素方式缩略,候选全称语为多个词组合。例如,“港商/n-香港/ns 商人/n”;
(4) 候选缩略语为多字,采用语素方式缩略,候选全称语为单个词且候选缩略语不是全称语的子字符串。例如,“民盟/n-中国民主同盟/nt”;
(5) 候选缩略语为多字,采用混合方式缩略,候选缩略语为单个词。例如,“地空导弹/n-地对空/b 导弹/n”;
经过这五条规则筛选后,得到的缩略语词典的准确率会得到很大地提高。当然,这些规则也不可避免地会排除掉一部分真正的缩略语,使得召回率略有下降。
3 实验
3.1 实验过程
(1) 语料预处理。考虑到缩略全称语对在新闻领域的语料中出现的比较多,我们使用了新闻领域汉英平行语料LDC2003E14*http://projects.ldc.upenn.edu/TIDES/mt2003.html,从中随机选取了20万句对。采用Stanford Chinese Segmenter*http://nlp.sttanford.edu/software/segmenter.shtml对中文语料进行自动分词,将英文语料全部换成小写字母并将符号与词分隔开。
(2) 词对齐训练。将预处理后的语料用开源软件GIZAC++训练得到词对齐结果。
(3) 抽取短语对。按照2.1节中的方法抽取短语对,最终得到114 446个短语对。根据抽取出的短语对的对应次数和(2)中得到的词对应次数,可以计算出2.2节中提出的衡量中英文短语对齐质量的四个特征。
(4) SVM短语对分类。从中英文短语对集合中选取186条短语对,根据中英文短语是否对应,手工标注为“对应”和“不对应”两类。为获得高召回率,我们放松了对应标准。以标注后的数据为训练集,得到一个SVM分类器。从短语对集合中随机挑选出100条短语对(对应和不对应数据各一半)用于测试,结果如表1所示。正确率为81%,召回率为86.36%,F值为83.59%。用SVM分类器对短语对分类后得到结果为正的短语对91 884句,占总短语对数的80.28%。

表1 中英文短语对对应质量分类器的测试结果
(5) 匹配约束。选出(4)中分类后标注为“对应”的中英文短语对。其中的中文短语经过匹配约束(2.3.1)后得到候选缩略—全称语12 639对。根据候选缩略语的字长统计情况如表2所示。

表2 候选缩略—全称语对统计
(6) 噪音过滤。对经(5)得到的候选缩略—全称语对采用ICTCLAS进行词性标注。对得到的带有词性信息的候选缩略—全称语对进行噪音过滤(2.3.2)。最终得到缩略—全称语710对。
3.2 实验结果和分析
经过3.1中的实验步骤,我们得到最终的缩略—全称语词典。表3显示的是按缩略语字长和组合方式给出的统计结果。结果显示提取的缩略语以二字长的居多,占到总数的64%。字长为四和五的缩略语比较少。这一方面是我们提取过程中的偏向,另一方面是字长为二的缩略语在自然语言中分布确实很多。在缩略语构成方面,我们的方法偏向于语素构成方式,占总数的71.83%。混合方式占16.05%,而中心词构成方式产生的缩略语主要来源于专有名词,因而数量不多。另外,对于合并缩略方式构成的缩略—全称语对我们的算法没有考虑,原因是这类缩略语和全称语的英文翻译往往不相同。

表3 提取出的缩略语统计表

表4 缩略语的准确率评测
我们对得到的710条缩略语进行了评测。统计的结果如表4所示,整体准确率达到86.3%。我们可以看到该方法在不同词长下的正确率比较稳定。其中错误的例子一部分是由分词和词性标注错误以及短语词对齐不准确造成,例如,“韩国/nsf-韩三国/nr”及“美/b-韩美/nr”。另外一部分则属于我们的方法较难处理的,例如,“我军/n-我国/n 军用/b”。当然这种情况可以用添加规则的方法解决。但是如果增加过多语言学过滤规则,在自动分词和词性标注不够精确的情况下,又会使得召回率低下。
4 结论及未来工作
本文提出了一种从双语平行语料中提取缩略语词典的方法。与其他方法相比,我们利用了语言之间的翻译关系,获得较为可靠的候选集。需要的人工标注量很小,最终的缩略语词典正确率比较高。实验中,我们的噪音过滤方法使得一些好的缩略语被过滤掉。在今后的研究中我们将探寻更好的解决方法,例如,用更多的信息,如短语的上下文特征,来过滤候选集[6,11]。
本文的方法利用了双语词对齐信息作为缩略—全称语获取的依据,目前在中小规模数据上得到的缩略语数量还不是很大。但是该方法具有良好地可扩展性和应用价值: (1)在平行语料库上英汉互增益获取双语缩略语词典。具体步骤为,将本文的方法逆向使用,自动获取英文的缩略—全称语资源;利用英文的缩略—全称语信息,将英文的“缩略—全称语”当作同义词,对中文缩略语候选词对进行扩展,以增益中文缩略语获取效果;利用中文的缩略—全称语信息,增益英文缩略语获取效果;得到英汉双语对译的双语缩略语信息库;(2)可扩展至其他任意双语语料库的缩略语获取;(3)将双语缩略语信息库应用于机器翻译的双语词对齐工作,提高一部分因缩略语造成对齐困难;(4)有助于满足机器翻译等语言服务系统对于单语和双语缩略语的处理需求,解决形如“苏-Jiangsu province”的双语对译问题。
[1] Jing-Shin Chang, Yu-Tso Lai. A preliminary study on probabilistic models for Chinese abbreviations[C]//Proceedings of the 3rd SIGHAN Workshop on Chinese Language Processing, 2004, 9-16.
[2] Xiaodan Zhu, Mu Li , Jianfeng Gao, et al. Single Character Chinese Named Entity Recognition[C]//Proceedings of the Second SIGHAN Workshop on Chinese Language Processing, ACL, 2003.
[3] 李斌,方芳.中文单字国名简称的自动识别[J].计算机工程与应用2006, 42(28): 167-176.
[4] 支流,朱学锋,段慧明,等.中文缩略语还原技术初探[C]//全国第八届计算语言学联合学术会议(JSCL-2005).
[5] 崔世起,刘群,林守勋等.中文缩略语自动抽取初探[C]//全国第八届计算语言学联合学术会议(JSCL-2005).
[6] 武子英,郑家恒.现代汉语缩略语自动识别的方法研究[J].计算机工程与设计2007, 28(16):4052-4054.
[7] Zhifei Li, David Yarowsky. Unsupervised Translation Induction for Chinese Abbreviations using Monolingual Corpora[C]//Proceedings of ACL 2008: 425-433.
[8] Philipp Koehn, Franz Joseph Och, Daniel Marcu. Statistical Phrase-Based Translation[C]//Proceedings of HLT/NAACL. 2003.
[9] F.J.Och, C.Tillmann, H.Ney. Improved alignment models for statistical machine translation[C]//Proceedings of the Joint Conf. of Empirical Methods in Natural Language Processing and Very Large Corpora, 1999, 20-28.
[10] V.Vapnik, C.Cortes. Support vector networks[J]. Machine Learning,1995, 20: 273-293.
[11] Boxing Chen, George Foster, Roland Kuhn. Bilingual Sense Similarity for Statistical Machine Translation[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics,2010: 834-843.
猜你喜欢
中国脑血管病杂志(2022年4期)2022-11-10
中国脑血管病杂志(2022年3期)2022-10-03
中国脑血管病杂志(2022年2期)2022-09-01
传染病信息(2022年2期)2022-07-15
医药与保健(2022年2期)2022-04-19
延河·绿色文学(2020年6期)2020-09-10
中国脑血管病杂志(2019年4期)2019-10-29
长江丛刊(2018年23期)2018-11-14
中国美容整形外科杂志(2016年11期)2016-01-16
