
统计与词典相结合的领域自适应中文分词
2012-06-29 01:55张梅山邓知龙车万翔
中文信息学报 2012年2期
张梅山,邓知龙,车万翔,刘 挺
(哈尔滨工业大学 计算机学院 社会计算与信息检索研究中心,黑龙江 哈尔滨 150001)
1 引言
中文分词是中文自然语言处理中最基本的一个步骤,非常多的研究者对它做了很深入的研究,也因此产生了很多不同的分词方法,这些方法大体上可以分为两类: 基于词典匹配的方法和基于统计的方法。
基于词典的方法[1-2]利用词典作为主要的资源,这类方法不需要考虑领域自适应性的问题,它只需要有相关领域的高质量词典即可,但是这类方法不能很好的解决中文分词所面临的歧义性问题以及未登录词问题。
基于统计的方法[3-6]是近年来主流的分词方法,它采用已经切分好的分词语料作为主要的资源,最终形成一个统计模型来进行分词解码。基于统计的方法在分词性能方面有了很大的提高,但是在跨领域方面都存在着很大的不足,它们需要针对不同的领域训练不同的统计分词模型。这样导致在领域变换后,必须为它们提供相应领域的分词训练语料,但是分词训练语料的获得是需要大量人工参与的,代价昂贵。而基于词典的方法却在领域自适应方面存在着一定优势,当目标分词领域改变时,只需要利用相应领域的词典即可。领域词典的获取相比训练语料而言要容易很多。如果把这两种方法结合起来,使得统计的方法能够合理应用词典,则可实现中文分词的领域自适应性。
赵海等人[7]以及张碧娟等人[8]都曾提出将词典信息融入统计分词模型中大大改善了分词的性能。但是他们实际上都始终把词典当作一种内部资源,训练和解码都使用同样的词典,并没有应用到解决中文分词领域自适应性的问题中。本文借鉴在CRF[9]模型中融入词典特征信息的方法来解决中文分词的领域自适应性问题。在训练CRF分词模型时,使用通用词典;而分词阶段通过额外再加入领域词典来实现领域自适应性。当分词领域改变时,只需要在原有词典的基础上再添加相应领域的词典,而且不需要改变原有已经训练得到的统计中文分词模型,就可以大大改善该领域的分词准确率。
最后本文利用SIGHAN CWS BAKEOFF 2005中提供的PKU corpora进行训练,训练过程中采用通用词典,训练得到的统计分词模型分别在PKU test corpus和人工标注的金融领域语料上进行了测试。测试时,PKU语料所用的词典保持与训练语料所用的词典一致,而金融领域所用的词典则额外再加入了部分金融领域的专业词汇。最后的结果显示,PKU语料上取得了2%的F-measure值提升;金融领域上取得了6%的F-measure值提升,最终达到93.4%。
本文组织内容为: 第二部分介绍CRF中文分词;第三部分介绍领域自适应性的实现;第四部分为实验部分;第五部分为结论及进一步工作。
2 CRF中文分词
薛念文[3]等人2003年提出将中文分词问题看成序列标注问题。句子中每个字根据它在词中的位置进行分类,共分为B,M,E,S四类。其中B代表该字符是每个词的开始,M表示该字符在某个词的中间位置,E表示该字符是某个词的结束位置而S表示该字符能独立的构成一个词。
CRF[9]是目前主流的序列标注算法,它在序列标注问题上取得了很大的成功。对于给定的句子 x=c1…cn及其某个分词标注结果为y=y1…yn,其中ci为输入字符,yi∈{B,M,E,S}(1≤i≤n),我们可以用如下的方法表示y的概率:
(1)
其中Z(x)为一个归一化因子,Φ(yi-1,yi,x)为特征向量函数,λ为特征权重向量。
2.1 统计模型所使用的基本特征
对于CRF模型,特征的选择尤为重要。本文首先使用了三类基本特征: 字符n-gram特征,字符重复信息特征和字符类别特征。这三类特征和论文Tseng[4]中提到的特征类似,这里对字形态特征做了一定的扩展,将输入字符分为九类: Single,Prefix,Suffix,Long,Punc,Digit,Chinese-Digit,Letter以及Other。本文中所使用的字符类别的定义以及相关例子如表1所示。
给定一个中文字符,首先判断它是否属于标点符号(Punc)、数字(Digit)、中文数字(Chinese-Digit)或者字母(Letter);如果不属于其中的任何一类,则统计该字符在训练语料中出现的时候所处在的词的位置,仍用B、M、E、S表示,如果B位置出现的频次超过总次数的95%,则判定该字符属于Prefix类别,如果E位置出现的频次超过总次数的95%,则为Suffix类别,同理S位置对应于Single类别, M位置对应于Long类别;如果还未找到该字符的类别,则标记为Other类别。

表1 字符类别定义以及示例
最后这里列举一下在本文中CRF中文分词模型所使用的基本特征,如表2所示。

表2 CRF中文分词模型中所使用的基本特征
其中下标代表距离当前考察字符的相对位置,例如,c-1表示该字符的前一个字符。Reduplication(c0,ci)表示c0和ci是否为两个完全一样的字符,Type(ci)表示字符ci的类别。
3 领域自适应性的实现
词典对中文分词有着很大的用处,最初基于词典简单匹配的方法以及基于二元语法的方法都曾经取得了很大的成功。而且词典的获取途径非常广泛,与统计模型中用到的分词语料相比较,它更容易获取。针对特定的领域,领域词典的获取也非常容易而且覆盖面广。但是过去这些基于词典的方法在解决分词的歧义性问题上比统计模型的方法要弱很多。
本文通过在统计中文分词模型中融入词典相关特征的方法,使得统计中文分词模型和词典有机结合起来。一方面可以进一步提高中文分词的准确率,另一方面大大改善了中文分词的领域自适应性。
由于本文中所使用的特征并不依赖特定的词,而是采用类似最大匹配的思想将包含目前字符的最长的词的长度信息提供给统计模型,因此当为特定领域进行中文分词时,不需要改变原有的分词模型,只需要加载相应的领域词典,便可以大大的减少不同领域对分词所产生的影响。整个系统框架如图1所示。
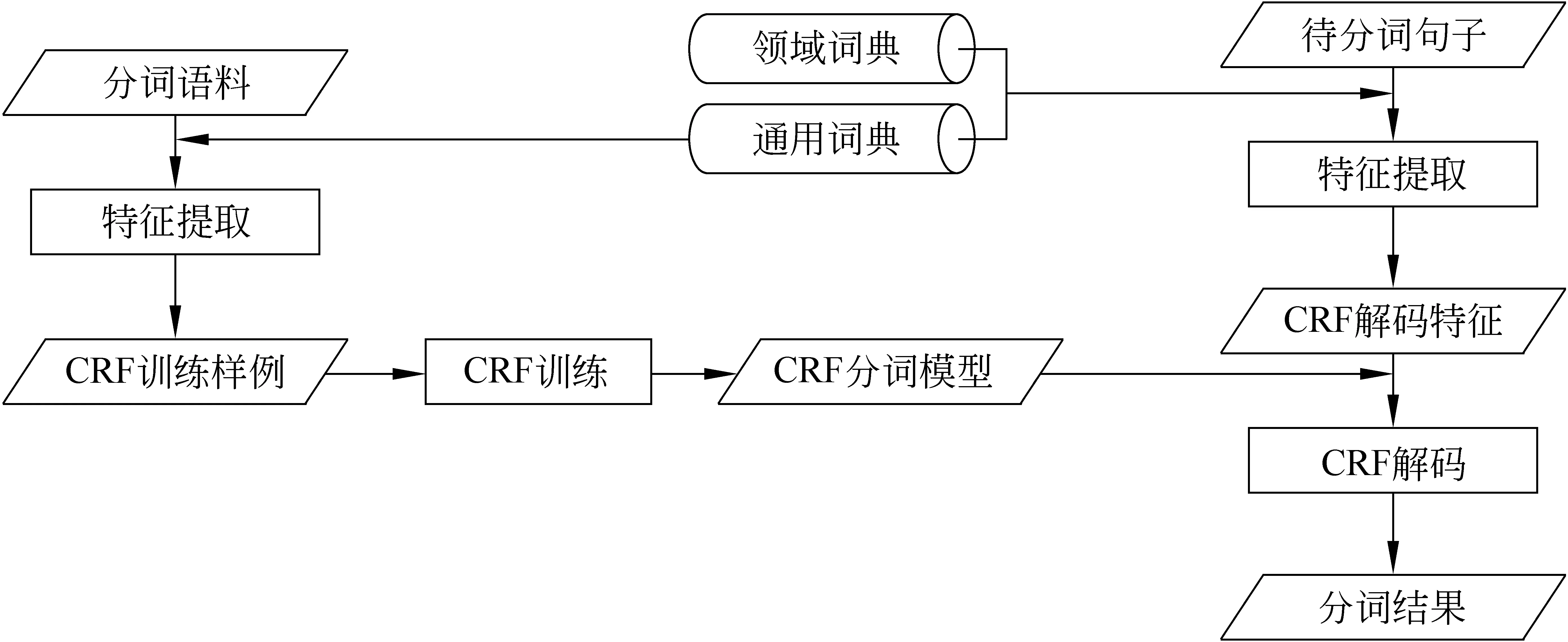
图1 领域自适应性分词系统框架图
3.1 词典信息在统计模型中的特征表示
对于给定句子x=c1…cn,以及词典D,考虑其中的第j个字符cj(1≤j≤n),定义如下三个函数:
(2)
其中w表示词语;fB(x,j,D)表示对于句子x在j位置根据词典D采用正向最大匹配所获得的词的长度;fM(x,j,D)表示对于句子x在j前面的某个位置根据词典D采用正向最大匹配所获得的经过j位置而且不以j结尾的最长词的长度;fE(x,j,D)表示对于句子x在j位置根据词典D采用逆向最大匹配所获得的词的长度。
本文对CRF分词模型所引入的与词典D相关的扩展特征如表3所示。
假设目前考虑位置为j,则上面相应的[fB]i=fB(x,j+i,D),[fM]i=fM(x,j+i,D),[fE]i=fE(x,j+i,D),[fM]i。考虑一个例子,“门前车水马龙”,如果词典中与这个句子相关的词为“门, 门前,车,水,车水马龙,马,马龙”,考虑当前字“水”,则有 [fB]-1=4,[fB]0=1,[fB]1=2,[fM]-1=0,[fM]0=4,[fM]1=4,[fE]-1=1,[fE]0=1,[fE]1=1。

表3 CRF中文分词模型中所使用的词典特征
4 实验
本文利用SIGHAN CWS BAKEOFF 2005中提供的PKU训练语料进行训练,训练过程中使用北京大学中国语言学研究中心公开的词典*http://ccl.pku.edu.cn/doubtfire/Course/Chinese%20Information%20Processing/Source_Code/Chapter_8/Lexicon _full_2000.zip.,该词典一共包含大约10万多个词。最后分别在相应的PKU测试语料和人工标注的金融领域语料上进行了评测,表4给出了两个测试语料的统计信息。本文使用准确率(P)、召回率(R)和F-measure值(F)来评价分词系统。本文采用CRFC++工具包*http://chasen.org/?taku/software/CRF++/.来进行训练和标注。
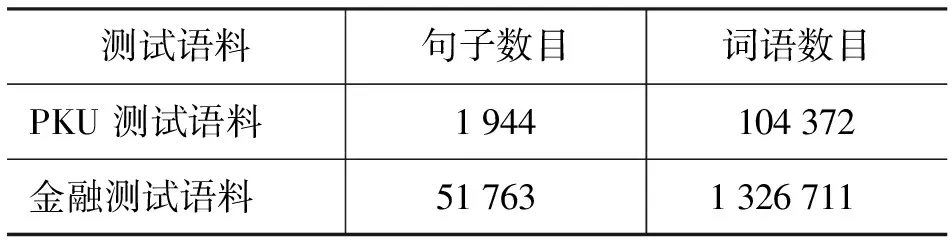
表4 测试语料相关统计信息
4.1 实验结果及分析
CRF-basic代表仅使用基本特征训练出来的模型;CRF-post表示使用拼接的后处理方法去纠正被CRF错误切分的词,这个方法假定词典中没有在训练语料中出现的词都应该是不可切分的;CRF-extern 表示融入了词典信息特征之后所得到模型。
在PKU的测试语料上,使用训练出来的模型,测试时所使用的词典和训练时所使用的词典一致。表5给出了PKU语料上测试的结果。从表中可以看出,CRF-extern与CRF-basic相比,F-measure提升了1.8%;与CRF-post相比,提升了0.3%。
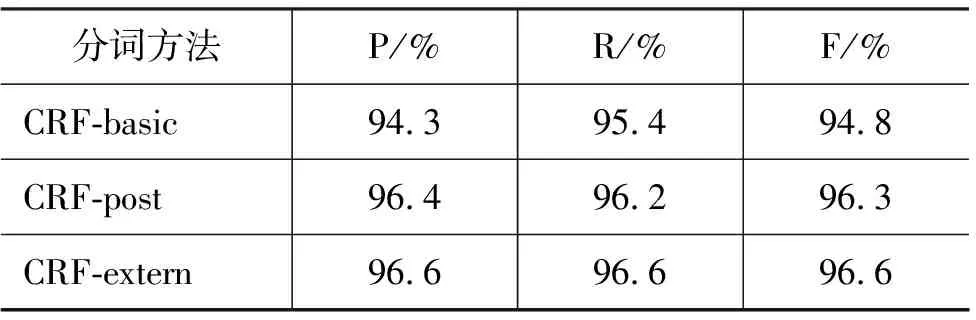
表5 SIGHAN BAKEOFF 2005 PKU测试语料上分词性能比较
在金融领域的测试语料上,保持训练出来的CRF分词模型不变,使用的词典是在训练语料的词典基础上增加了1 000个左右的金融领域专用词典。表6给出了金融领域测试语料上的结果。从表中可以看出,CRF-extern与CRF-basic相比,F-measure提升了7.6%;与CRF-post相比,提升了3.2%。
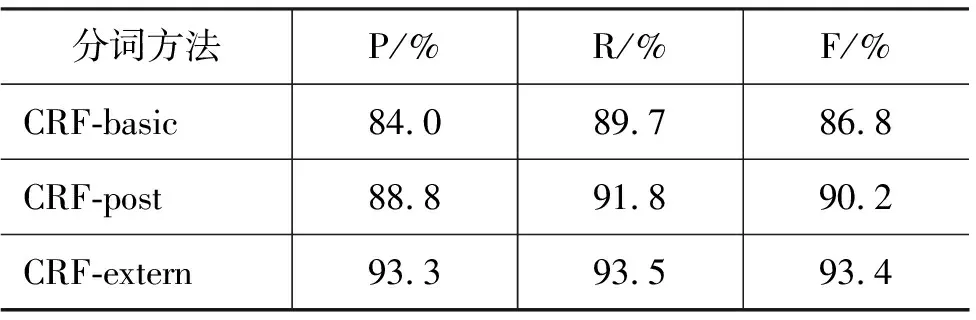
表6 金融领域测试语料上分词性能比较
从上面的两个实验可以看出,(a) 无论测试语料的领域与训练语料领域是否相同, CRF-extern对比CRF-basic显著提高了分词的性能; (b) 当训练语料和测试语料领域相同时,CRF-extern和CRF-post相比,分词性能有稍微的提高;但是当领域不同时,CRF-extern对比CRF-post而言,有了非常显著的提高; (c) 测试领域和训练语料不同时,最终的分词F-measure值达到了93.4%,已经非常接近于CRF-basic在不考虑跨领域时的F-measure值94.8%。
综上所述,在统计模型中融入词典信息特征后,一方面分词性能有了一定的提高;另外一方面领域迁移后,分词性能依然能够保持在一定的水平。因此统计模型与词典结合后,使得中文分词具有良好的领域自适应性。
4 结论及下一步工作
本文通过在CRF统计分词模型中融入词典特征来实现中文分词的领域自适应性。当面向不同的领域时,只需通过加载相应领域的词典。因为领域词典的获取与为该领域标注分词训练语料相比代价要小很多。最终实验结果表明,该方法不仅仅在原有领域上取得了比较好的效果,而且在金融领域上也取得了不错的效果。
下一步我们需要自动挖掘各种领域相关的词,从而使得我们的分词系统能适应各个领域的需求。
[1] 骆正清,陈增武,胡尚序.一种改进的MM分词方法的算法设计[J].中文信息学报,1996, 10(3):30-36.
[2] 吴春颖,王士同.基于二元文法的N-最大概率中文粗分模型[J].计算机应用,2007, 27(12):332-339.
[3] Nianwen Xue. Chinese word segmentation as character tagging[J]. International Journal of Computational Linguistics and Chinese Language Processing, 2003, 8(1):29-48.
[4] Huihsin Tseng, Pichuan Chang, Galen Andrew, et al. A conditional random field word segmenter for sighan bakeoff 2005[C]//Proceedings of the fourth SIGHAN workshop. 2005:168-171.
[5] Yue Zhang, Stephen Clark. Chinese segmentation with a word-based perceptron algorithm[C]//Proceedings of the 45th ACL. 2007:840-847.
[6] Xu Sun, Yaozhong Zhang, Takuya Matsuzaki, et al. A discriminative latent variable chinese segmenter with hybrid word/character information[C]//Proceedings of NAACL. 2009:56-64.
[7] Hai Zhao, Chang-Ning Huang, Mu Li. An Improved Chinese Word Segmentation System with Conditional Random Field[C]//Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing. 2006:162-165.
[8] Pi-Chuan Chang, Michel Galley, Christopher D.Manning. Optimizing Chinese Word Segmentation for Machine Translation Performance[C]//ACL Workshop on Statistical Machine Translation. 2008:224-232.
[9] John D. Lafferty, Andrew McCallum, Fernando C. N. Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of ICML. 2001:282-289.
猜你喜欢
通信技术(2021年12期)2022-01-25
校园英语·月末(2021年13期)2021-03-15
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
