
分布式视频转码服务调度算法研究
2012-06-25 07:03谭智一宋建新
电视技术 2012年9期
谭智一,宋建新
(南京邮电大学通信与信息工程学院图像处理与图像通信实验室,江苏 南京 210003)
分布式视频转码服务是基于云特性的视频服务之一,将一个大的视频转码源序列按不同粒度(GOP,Slice等)划分为多个小的分段作为子任务并将这些子任务分配到分布式网络中位于不同物理位置通过网络相互连接的处理节点上进行转码处理,可以较为有效地缓解不断增加的视频转码任务负担给视频处理服务器造成的压力和单台节点计算机视频处理能力不足的缺陷。在这种分布式的转码任务处理模式下,有2个有待解决的问题:一是如何根据节点资源及客户信道质量合理地接收客户任务请求;二是如何将处理后的Close-GOP分段有控制地发送给客户端使客户可以收看到流畅的视频服务,同时保证尽可能低的额外延迟代价。
Haiyan Luo,Song Ci等人在文献[1]中提出的P2P网络中跨层优化实时传输控制算法;Sonia Nazari和Hamid Beigy在文献[2]中提出的WiMAX网络中的上行实时任务数据传输控制算法以及Chenghan Tsai和Taiyi Huan在文献[3]中提出的基于QoS的基于时间片实时任务传输调度算法均是对上述问题有意义的探索和研究。
1 研究背景及问题描述
1.1 分布式视频转码服务
可以为客户提供视频转码的分布式网络如图1所示。

图1 分布式视频转码服务示意图
图1中Node表示分布式网络中的1个节点,任意节点根据其是否发出任务请求(图1中Task Request)或者是否愿意为服务节点Service Node提供资源可以自由地作为客户节点或者处理节点。Client Cluster中的节点向Processing Node Cluster中的Service Node发出任务请求,Service Node根据当前从Processing Node Cluster中获取的当前可利用节点资源总量的反馈以及从Client Cluster中获取的发出请求的各客户端信道质量的反馈接收来自Client Cluster的Task Request;来自客户的Task Request根据客户自身信道质量调整为合适任务版本后(这里主要是视频的空间分辨力)作为1个任务(Job)接入。每个任务按一定粒度划分为多个子任务(Sub-Job)被分配到Processing Node Cluster中的各个处理节点上进行处理[4]。完成处理后,Service Node将重新调整各处理节点返回的视频序列分段向客户端的发送顺序和间隔,为客户端提供流畅的视频服务。
1.2 问题描述
设当前有n个视频转码任务,集合{delayi}={delay1,delay2,…,delayn}表示其相应的服务延迟,集合{dli}={dl1,dl2,…,dln}表示任务各自的deadline。{wi}={w1,w2,…,wn}为相应任务在GOP级别并行处理模式下的任务负载;对于每一个任务ti,令ti_j为其按Close-GOP分割后第j个分段,Aj表示当前到达客户端j的视频任务i的分段集合,集合{ATi_k}表示对于客户任务ti的第j个分段到达的时间,集合{EXCi_j}表示该分段在客户端上的执行时间(解码时间+播放时间),集合{BSj}表示客户端j的视频缓冲区大小。利用以上设定,可以把本文1.1节中所述的两个问题描述为如下最优化问题形式
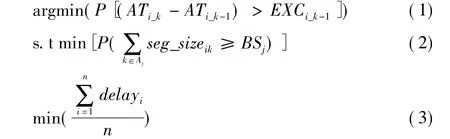
2 反馈的定义
2.1 处理节点资源
本文所设计的任务接受控制策略使用的反馈有2项:一是处理节点的资源反馈[5-6],另一项则是用户的信道质量反馈[7]。在本文的研究中,对于视频转码处理任务,考察的节点资源为CPU和RAM空闲率。按照1.2中的问题设定,首先在分布式网络中选择1个处理节点作为参考节点,设εi为处理节点i的环境等级因子,用于描述节点由自身硬件配置决定的视频转码任务处理能力的高低,则参考节点的环境等级因子为1。ri表示经过本节公式(1)计算后得到的处理节点i资源,CoffCPU和CoffRAM分别为CPU和RAM的加权系数,表示在视频转码处理对二者的占用比重;UCPU_i和URAM_i分别为处理节点i上当前的CPU和RAM的占用率。利用这些变量设定,我们提出公式1用于计算处理节点当前的可用资源量
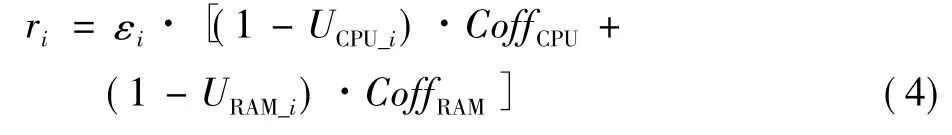
2.2 参量εi、CoffCPU及CoffRAM的获取
通过对视频转码实验(本文主要是空间分辨力转码)的资源占用数据进行分析表明,任一空间分辨力视频转码任务在执行过程中的资源占用只与其源序列的空间分辨力和序列大小有关,而与音视频采样率,音视频码率以及目标空间分辨力等其他任务参数无关。表1为实验中的部分统计数据(统计平均)。

表1 不同空间分辨力转码资源占用统计结果
此外,实验表明不同源序列空间分辨力和序列大小的视频转码任务对CPU和RAM占用的比值基本上是不变的。据此,取一组空间分辨力和大小均不相等的源视频序列{Si}={S1,S2,…,Sk},在2.1中所选定的参考节点上执行空间分辨力转码任务。令ΔUCPU_j和ΔURAM_j分别为序列Sj处理时的CPU和RAM占用率,则由公式(5)和公式(6)可以分别得到CoffCPU和CoffRAM的值

同样使用上述随机视频序列{Sj},令ΔUCPU_j_i和ΔURAM_j_i分别为序列Sj在节点i上进行处理时的CPU和RAM占用率,ΔUCPU_j_s和ΔURAM_j_s为序列Sj在该参考节点上处理时相应的CPU和RAM占用率。则可以由公式(7)计算得到任一处理节点i相对于该参考节点的环境等级因子εi

2.3 信道质量反馈的设定
由于本文研究的主要是有线信道,因此可以认为信道自身是稳定的,不存在突发的丢包率波动。因此,文章考虑的信道质量主要是信道的等效带宽。信道等效带宽决定了视频分段数据从服务器端传输到客户端所需要的时间。若令RTTj为服务器测得的单位大小数据包在客户端j信道中的往返传输时间,BWj为客户端j与服务器连接的等效信道带宽,那么任务序列i的第k个分段在信道j中的传输时延可以由公式(8)计算得出
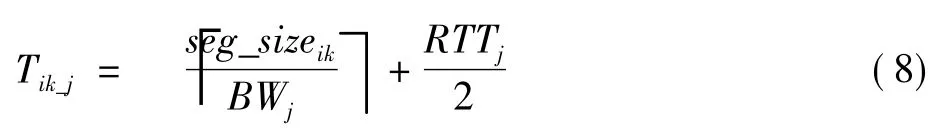
流式媒体服务自身的特点决定了1个视频任务并不需要客户端等到所有分段到达后才开始解码和播放,只要在当前分段播放结束前,下一个分段到达客户端并完成解码即可实现流畅的视频服务。虽然目标空间分辨率并不影响视频转码任务执行时的资源占用,但其决定处理后的序列分段大小。如果令集合{STi_k}表示任务序列i的第k个分段从服务节点发出的时间,那么参量Tik与1.2节中分段到达时间ATi_k的关系可由公式(9)表示,而每个视频分段的播放时间EXCi_k是已知的,因此,流畅视频服务的条件则可以表示为公式(10)
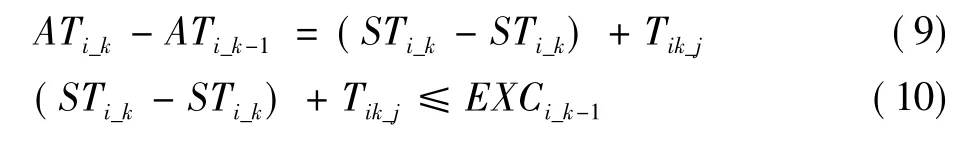
3 任务接收策略
用于任务接收的两个控制条件,一是接收的任务资源占用不能超过当前节点的可用资源总量[8];另一个则是一轮任务的接受周期不能太长以至于最先接入的任务失去其生存周期[9-10]。利用前面3个小节的设定,首先设置1个用于任务接收控制的资源终止门限Thstop以及1个任务最大接受周期TAmax。使用的反馈信息为客户端的信道往返传输时延RTTj和信道等效带宽BWj,并将公式(8)计算得到的传输时延Tik_j设为信道质量阈值。根据公式(10),对于任一目标分辨率的任务,客户端相应的Tik_j最大值应该在两个相邻任务分段连续发送,也即发送间隔趋向于零的时候达到,即满足条件Tik_j≤EXCi_k-1。根据以上分析,本文设计的动态任务接受策略如图2所示。
4 视频分段传输控制算法

图2 动态任务接收流程
本文1.2节的问题描述说明了流畅的视频服务应该满足的条件,即下1个视频分段必须在当前视频分段播放结束之前到达客户端。由于每个客户端信道的质量状况是可以通过反馈信息确定的,因此,传输控制算法主要控制的是分段之间的发送间隔。过大的发送间隔会导致视频服务的中断,而过小的间隔则会造成客户端视频缓冲区的溢出;合理的传输控制算法还应该在保证流畅视频服务的同时尽量减少其带来的额外服务延迟[10-11]。
对于视频转码任务,通过实验数据统计发现,空间分辨力转码任务的处理时间与源序列的空间分辨力和序列大小相关。本文研究中为便于实验统计和算法设计,使用了相同空间分辨力的任务源视频序列,则对于任一源序列i,实验数据统计表明其处理时间与序列大小成近似线性正比关系,由此可以近似得到该序列每个分段的估计处理时间{ETik}={ETi1,ETi2,…,ETih}。由于对于任一分段而言,其大小均小于源序列大小;因此,每一个分段均可以在任务自身deadline之内完成处理。令{WTik}表示任务i的第k个分段在完成处理后在服务器端等待发送的时间,利用本文1.2节的问题说明和公式(10)的相关设定,将流畅视频服务的条件进一步改写为
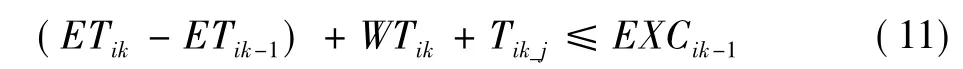
在公式(11)描述的条件中,任务的估计运行时间ETik、客户端信道质量Tik_j和分段在客户端上的执行之间EXCik均是无法控制的;因此,本文设计的传输控制算法控制的参量主要是分段在服务器端的等待时间WTik。对于到达服务器端的任务序列i的分段k,本文提出的控制算法处理步骤如下:
步骤1,若k=1,检查第k+1个分段是否到达服务器端;若分段k+1尚未到达,跳转至步骤3,否则跳转至步骤4。
步骤2,若k>1,检查第k-1个分段是否到达服务器端;若分段k-1已发送,跳转至步骤5;若分段k-1到达服务器端尚未发送,跳转至步骤6;否则等待分段k-1。
步骤3,计算WTik=×(ETik+1+Tik+1_j),比较WTik与dli-ETik-Tik_j的大小;若WTik≤dli-ETik-Tik_j,则分段k在等待WTik时间后发送;否则等待dli-ETik-Tik_j时间后发送。
步骤4,直接发送分段k,并跳转至步骤2。
步骤5,检查分段k+1是否到达服务器;计算WTik=× (ETik+1+Tik+1_j),若 WTik+Tik_j≤ EXCik-1,分段k在等待WTik后发送;否则等待EXCik-1-Tik_j时间后发送分段k,考察分段k+1,跳转至步骤3。
步骤6,立即发送分段k-1,跳转至步骤5。
5 仿真与实验
对本文算法的验证实验,选择在UNIX环境下使用C语言编程进行实现,使用的实验编程环境为Ubuntu11.04,编译器版本gcc-4.5.1,系统内核版本为Linux-2.6.38。利用前文对转码任务资源占用的特点分析,实验中对不同序列使用资源占据因子ε来计算其资源占用。实验中有意选择了Close-GOP分段大小不均匀的序列(但排除大小差异极大的极端情况)便于对比本文提出的传输控制算法在保障流畅视频服务上的效能。在实验中使用的视频序列参数如表2所示,每个任务序列均有176×144,360×240和480×360这3种不同的可供客户端选择的目标分辨力,其相应的客户信道质量阈值分别设置为0.2 s,0.3 s和0.5 s,3种目标分辨力的任务各自的deadline分别设为6 s,8 s和12 s。此处为方便实验对比,有意限制了等效带宽;deadline是目前相应分辨力视频服务常见的deadline。

表2 用于实验的视频序列信息
一共设置了30个客户端节点,每个节点的任务请求均相互独立。实验中,将测试在使用和未使用本文所设计的传输控制算法的情况下,每个客户端的服务延迟以及视频的中断情况。
图3为使用和未使用传输控制算法的情况下,客户端收到视频服务的延迟对比。

图3 客户端服务延迟对比
图4为使用和未使用传输控制算法的情况下,客户端收看到视频的总中断时间对比。
图3和图4所描述的实验结果表明,在服务器端使用本文设计的传输控制算法之后,相比于不使用该控制算法的情况下,客户端收看到视频服务的延迟会略有增加。时间的增量按照源视频序列Close-GOP分段的大小波动情况的不同大约在5%~25%之间(实际延迟增量在0.2~1.5 s之间),但任务的延迟基本上仍控制在实验中设定的deadline范围之内。而在图4中,视频服务的中断情况相比不使用传输控制算法的情况而言有了较为明显的改观;相比而言,出现服务中断的任务有所减少。但同时也可以看到,本文提出的传输控制算法并不能完全杜绝流式视频服务的中断;由于人眼的视觉暂留效应,只要中断时间足够短,在用户看来也属于流畅的视频服务。而图4中表明,在使用了本文设计的传输控制算法之后,出现中断的视频,其在实验中表现出的中断时间基本被控制在0.5s以内,具有较为良好的视觉流畅性。对比本文提出的分段传输控制算法在视频服务流畅性上的提升,该算法的延迟代价是可以接受的。

图4 客户端视频总中断时间对比
6 小结
本文针对分布式网络中流媒体服务的客户请求接受和流畅服务的传输控制问题进行了一定的探索和研究,通过对空间分辨力视频转码任务执行时对处理资源的占用分析发现其资源占用只与源序列分辨力和序列大小相关的特点。结合不同分辨力的流式视频服务队客户信道等效带宽和传输延迟的需求,本文提出了基于节点资源和客户信道质量反馈的自适应客户任务请求接收算法。此外,通过分析为实现流畅视频服务视频的分段的发送控制需要满足的条件,本文提出了用于保障视频服务流畅性的视频分段传输控制算法。通过实验,证明了本文提出的分段传输控制算法可以在较小的额外延迟代价条件下,较为有效地减少流式视频服务的中断概率,提高客户端收看视频的流畅性。
[1]LUO Haiyan,SONG Ci,WU Dalei.A cross- layer optimized distributed scheduling algorithm for peer-to-peer video streaming over multi-hop wireless mesh networks[C]//Proc.IEEE Communications Society Conference on Sensor,Mesh and Ad Hoc Communications and Networks.[S.l.]:IEEE Press,2009:1-9.
[2]NAZARI S,HAMID B.A new distributed uplink packet scheduling algorithm in WiMAX networks[C]//Proc.International Conference on Future Computer and Communication.[S.l.]:IEEE Press,2010:232-236.
[3]TSAI Chenghan ,HUAN Taiyi.An efficient real-time disk-scheduling framework with adaptive quality guarantee[J].IEEE Trans.Computers,2008,57(5):634-657.
[4]ANTIF Y,HAMIDZADEH B.A scalable scheduling algorithm for realtime distributed systems[C]//Proc.International Conference on Distributed Computing System.[S.l.]:IEEE Press,1998:352-359.
[5]BIZZARRI P,BONDAVALLI A,GIANDOMENICO F D.A schedulin algorithm for aperiodic groups of tasks in disributed real-time system[EB/OL].[2011-11-03].http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.81.8989&rep=rep1&type=pdf.
[6]LU Chenyang ,WANG Xiaorui,KOUTSOUKOS X.Feedback utilization control in distributed real-time systems eith end-to-end tasks[J].IEEE Transactions on Parallel and Distributed System,2005,16(6):500-561.
[7]ZHANG Dongsong,JIN Shiyao,WU Tong,et al.Feedback- based energyaware scheduling algorithm for hard real-time tasks[C]//Proc.IEEE InternationalConference on Networking,Architecture and Storage.[S.l.]:IEEE Press,2009:211-214.
[8]LIU C L,LAYLAND J W.Scheduling algorithms for multiprogramming in a hard-real-time enviroment[EB/OL].[2011-11-03]http://inst.eecs.berkeley.edu/~ee249/fa07/discussions/liu73scheduling.pdf.
[9]WANG Chenjun.The research on real-time scheduling algorithm in distributed system[C]//Proc.Pacific-Asia Conference on Knowledge Engineering and Software Engineering.[S.l.]:IEEE Press,2009:71-74.
[10]CHAI Yunpeng,DU Zhihui,LI Sanli.A new scheduling algorithm for distributed streaming media system based on multicast[C]//Proc.The 28th International Conference on Distributed Computing Systems Workshops IEEE Computer Society.[S.l.]:IEEE Press,2008:587-592.
[11]LI Jie,GUO Ruifeng,SHAO Zhixiang.The Research of Scheduling Algorithms in Real-time System[C]//Proc.International Conference on Computer and Communication Technologies in Agriculture Engineering.[S.l.]:IEEE Press,2010:333-336.
猜你喜欢
红外技术(2022年4期)2022-04-25
天津科技(2021年5期)2021-06-04
缔客世界(2020年1期)2020-12-12
中国医学装备(2019年1期)2019-02-14
传播力研究(2018年7期)2018-05-10
制造技术与机床(2017年6期)2018-01-19
医疗卫生装备(2015年9期)2015-12-27
中国光学(2015年5期)2015-12-09
电源技术(2015年9期)2015-06-05
电测与仪表(2014年14期)2014-04-04
