
云计算平台的自适应资源供给*
2012-06-11 11:04赵淦森季统凯
电信科学 2012年1期
赵淦森 ,虞 海 ,季统凯 ,宋 泓
(1.华南师范大学 广州 510631;2.中山大学 广州 510275;3.广东电子工业研究院 东莞 523000;4.中国电子科技集团公司 北京 100846)
1 引言
1.1 研究背景
云计算(cloud computing)是一种抽象、虚拟化、动态可扩展的,能将托管的计算能力、存储能力、平台及服务按需提供给外部客户和应用的,以规模经济驱动的大规模分布式计算模式[1]。
云计算平台通常提供3个层次的服务,自高而低依次为:软件即服务 (software as a service,SaaS)、平台即服务(platform as a service,PaaS)、基础设施即服务(infrastructure as a service,IaaS)[2,3]。其中,SaaS允许用户订阅软件服务,并将部分或全部的数据及代码保留在远程的云中,如Google Docs;PaaS提供基础应用支撑,允许开发者在已建立的统一的应用基础设施上构建和部署服务,如Google App Engine;IaaS通过虚拟化等手段对基础的物理资源进行服务化封装,通过服务的形式为应用服务提供物理资源,包括计算、存储、网络资源等,如Amazon EC2[4,5]。本文主要关注IaaS云。
作为云计算的重要特性之一,较高的规模可扩展性要求云中应用所获得资源的规模可以动态伸缩,以满足应用规模增长或缩减的需要。现有的IaaS云允许用户在需要更多资源时手动开启多个虚拟机实例以提供更多的资源,或在资源需求下降时关闭部分乃至全部虚拟机实例以节约成本。在这些云中,用户开启虚拟机实例时仅需选择所需资源的数量及所使用的虚拟机镜像。通常,所需的资源是以虚拟机容器的形式提供给用户,用户选择虚拟机容器及所用虚拟机镜像后,系统将自动分配资源,开启虚拟机,用户无需关心资源是如何被调度或虚拟机究竟运行于哪台物理机。当用户关闭虚拟机实例时,仅需选择要关闭的虚拟机实例,系统将自动完成虚拟机实例的关闭与资源的回收,无需用户关心虚拟机实例究竟运行于哪台物理机、所占资源如何释放等。这种虚拟机实例开关的自动调度方法降低了用户的使用门槛,方便了用户,保证了云内部的安全与稳定性,使得用户的注意力能够完全集中在对资源的使用而非资源获取上,提高了效率。但是,当前的IaaS云均不支持以上过程的自动化,即无论是开启还是关闭虚拟机实例,均需用户主动介入,系统不会进行任何自动操作或提示。
1.2 研究内容
本文研究IaaS云计算平台的规模自适应性。云计算平台的规模自适应性是指平台具有即需伸缩的资源管理能力。所谓即需伸缩,是指云计算平台在运行时能够根据云中应用负载的变化,动态地扩张或缩减其规模[6]。
云计算的规模可扩展性作为吸引互联网应用服务商和用户的最重要因素之一,能够使得互联网应用服务商和用户从中直接获益,其可以分解为以下3大元素。
·向上扩展性:指云能够提供足够多的资源以适应计算资源需求的增长,通过大规模的资源来支撑大规模的计算。
·向下扩展性:指云能够减少资源的供应,以适应计算资源需求的减少,节约成本。
·规模的自适应性:指平台能够按照用户对计算资源需求的变化,及时地自动调整计算资源的供应,提供充足但不过量的计算资源。
1.3 研究现状
[6]针对本文所研究的问题提出了通过使用与平台及应用无关的profile描述云平台上规模调整的专家知识,在运行时根据profile中包含的专家知识实施规模调整的思路,但并未能给出详解的自适应算法及实现。同时,profile需由应用专家定制,通用性较差。
参考文献[7,8]提出以应用的用户数量为衡量标准,假定可以利用合适的数学模型通过用户数量得出相应的资源需求量,从而实现规模适应性,但并未给出用户数量与资源需求量间的详细关系,亦未给出增加或减少资源供给的详细方法。
参考文献[9]提出了一种应激性的资源分配方法,在负载高峰时立即增加资源供给并自动将数据迁移和复制到新供给的资源上,以保证系统正常运行,但并未涉及负载低谷时的规模问题。
参考文献[10]提出了一种在网络计算中通过统计学方法保证服务质量的方法。该方法将每日分为24个时段,并以每日同一时段内的历史负载数据作为统计预测的资料,研究了短期负载的预测问题。
2 系统假设与系统模型
2.1 系统假设
本文的研究是在基于资源池的IaaS云环境下进行的。所谓虚拟机资源池,是指将系统中所有的资源整合在一起,当应用需要资源时,系统从资源池中分配出相应数量的资源,以虚拟机实例的形式提供给应用使用;当应用释放资源时,系统回收虚拟机实例,将所使用的资源放回资源池。基于此,本文进一步对所研究的问题给出以下假设:
(1)所有虚拟机调度指令能在足够短的时间内完成,在确定调度策略时无需考虑实际调度指令的滞后时间;
(2)云中有且仅有一种已部署应用;
(3)上述应用支持自动负载平衡、自动节点发现及自动容错。
在实际应用环境下,假设(1)可以通过实例缓存等技术达成;假设(2)是为简化研究而设,实际应用中可为每个应用单独应用本模型;假设(3)是为评估性能而设,支持自动负载平衡及自动节点发现的应用能更好地反映增加的虚拟机资源对应用性能的提升作用,并能在部分节点虚拟机实例被终止时保持正常运行。
2.2 系统模型
云计算平台的规模自适应方法,用来保证云中应用的可用性,即在资源需求高峰时,避免过载,保证服务的正常可用;保证云中应用的高效性,即在资源需求低谷时,尽量减少资源占用,避免浪费。
如前文所述,本文所研究的问题是基于IaaS云,在此环境下,提出了一种云计算平台的规模自适应性方法,系统模型如图1所示。本方法分为3个算法:最大并发请求数预测、预测修正及虚拟机选择。其中,最大并发请求数预测部分根据历史的每时段最大并发请求数记录,定期对下一时段内的最大并发请求数做出预测,并据此调用虚拟机选择部分,以确保在资源需求高峰时服务的正常可用及在资源需求低谷时的节约性;预测修正部分实时监测云系统的并发请求情况,在任意时刻,一旦监测到系统中实际的并发请求数已超过预测,立即增加预测的最大并发请求数,以确保在访问高峰时服务的正常可用;虚拟机选择部分接收前两部分给出的最大并发请求数,在保证资源供给的前提下,确定浪费最少的、适合的虚拟机种类及数量,并调用云系统API完成调度。
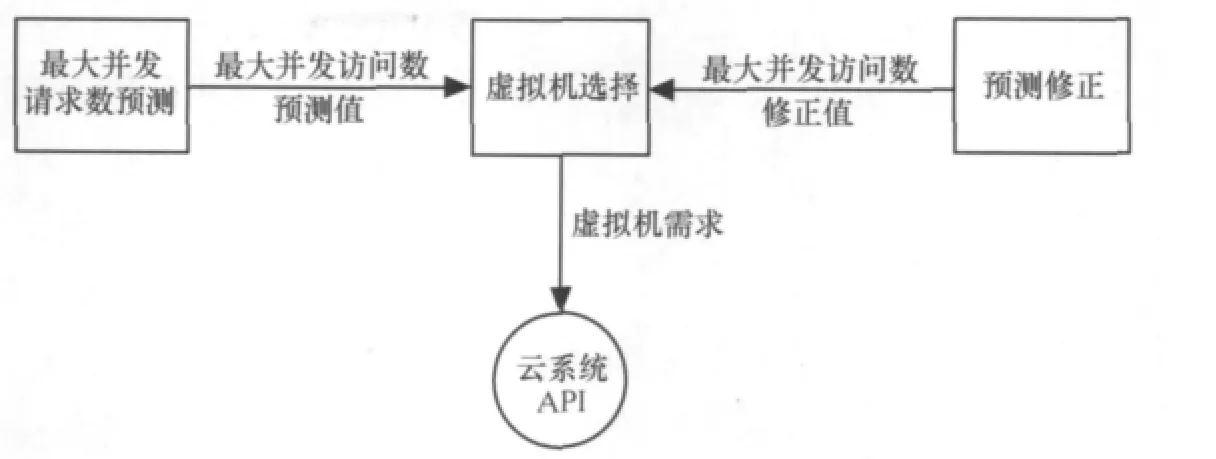
图1 系统模型
3 模型算法
3.1 符号表
符号描述见表1。

表1 符号描述
3.2 最大并发请求数预测
所谓最大并发请求数预测,是指根据应用的历史最大并发请求数记录,对下一时段内的最大并发请求数做出预测,并根据此预测值调用虚拟机选择部分,以确保在访问高峰时应用的可用性及在访问低谷时资源的节约性。典型情况下,每日不同时段的最大并发请求数具有一定的规律性,如每日早09:00上班后迅速上升,而后在某个较高位保持,至17:00下班后迅速下降,并在某个低位保持直至第二日上班。同时,中期而言,同一应用每日相同时段的访问量具有一定的趋势性,如企业由销售淡季转入旺季、新项目开始或结束等。综上,本文采用一种分时段以日为最小单位的时间序列预测算法[10]作为最大并发请求数预测方法。
所谓分时段以日为最小单位的时间序列预测算法,是指将每日的24 h分为若干时段,在预测当日某一时段内的最大并发请求数时,仅考虑历史数据中同时段的数据而不考虑其他时段的数据。例如,若当前时间为07:59,需要预测当日08:00~08:59这一时段的最大并发请求数,则预测时应忽略其他时段的最大并发请求数,仅将历史记录中每日08:00~08:59这一时段的最大并发请求数作为输入传递给时间序列预测算法。由此可以看出,各时段之间的预测互不影响。就本文所研究的问题而言,使用时间序列预测算法的主要是目的是预测下阶段的最大并发请求数,即算法需要面对的是一个短期的预测。而平台的基础设施性决定了其通常会连续运行较长时间,能提供大量的历史数据,同时,也决定了算法应该能够具有较大限度的通用性以应对不同类型的应用。最后,从中短期来看,最大并发请求数的变化往往有一定趋势性。综上,本文选用二次移动平均法作为预测下阶段资源需求的时间序列预测算法。二次移动平均法如下[11]:

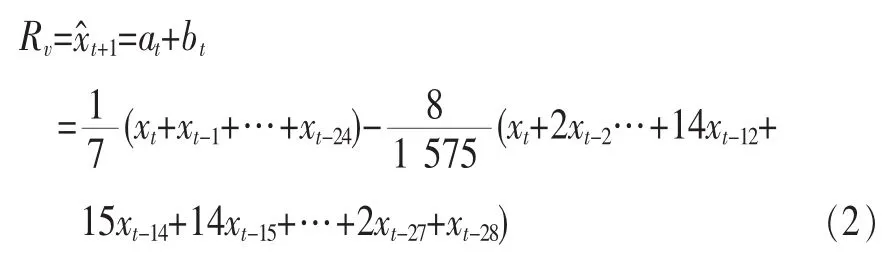
可以看出,算法使用了最近一个月(29日)的历史数据,考虑到实际情况,以最近一个月的最大并发请求情况来预测当日当时段的最大并发请求数是合理而且可行的。由于算法是在同一时段内进行预测和产生结果,时段的起止时间不会影响算法本身的使用。为简洁及实用起见,本算法在此取时段长度为1 h,起止时刻为每小时的第0分至第59分,即将每日划分为24个时段:00:00~00:59、01:00~01:59、…、23:00~23:59。数据的记录及分时段整理由云平台接口完成,此处从略。算法在每个时段起始前的瞬间周期性地运行。
3.3 预测修正
本算法对不足的最大并发请求数预测做出修正。所谓的修正,是指一旦监测到实际的并发请求数达到预测算法的预测值时,立即增大原有预测值,以追加分配资源,保证应用的正常运行。其中,预测值的增大数由历史平均的预测不足率确定。预测不足率是指预测算法的预测值或经本节预测修正算法修正后的预测值相比实际值的不足量与实际值之比。本部分将历史数据平均的预测不足率作为增大修正预测值的系数,即增加的预测数为现有预测数与历史数据平均的预测不足率之积。
预测修正部分保证了预测算法所得结果小于实际值情况下应用的正常运行,是对整个模型的一个有益补充。云平台发现当前的并发请求数已超过预测值时,随时调用本算法并负责提供及记录历史平均的预测资源不足率,此处从略。
3.4 虚拟机选择
本算法将给定的预测或修正的最大并发请求数转化为实际的虚拟机调度方案。定义应用的最大并发请求数req与所需资源rc间存在函数关系freq-rc,即:

由于函数关系freq-rc并不是本文的研究重点,故本文在此认为其为已知且由云系统提供。
根据式(3),可以通过freq-rc将给定的并发请求数转化为资源需求,对此资源需求,云系统需适当调度虚拟机以适应。实际的虚拟机调度方案为以下两种之一:开启某类型的一台虚拟机或关闭一台正在运行的虚拟机,即需要在给定的资源需求大于已开启虚拟机的总资源时,选择开启适当类型及数量的虚拟机以保证资源供给;或在相反的情况下,选择关闭适当的虚拟机。
本文对这一问题采用聚类算法,以待分配资源(当预期资源需求大于已开启虚拟机的总资源时为正,反之为负)与虚拟机之间的资源差加权向量模长为聚类距离。本文扩展了参考文献[11,12]的向量模长,引入了不同维度的权值。定义向量=(v1,v2,…,vn),相应维度的权值为(w1,w2,…,wn),则向量的加权长度为:
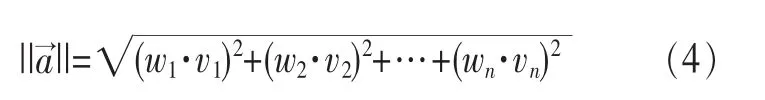
具体而言,本算法将最大并发请求数预测值及函数关系freq-rc作为输入。算法先通过freq-rc计算出所需的资源量,然后计算出每类虚拟机所能提供的资源量与预测值所需资源量之差所构成向量(以资源价值WX为权值)的向量模长,通过不断地寻找最小模长,从而确定当次所选的待开启的虚拟机,直至所选的虚拟机已经能够满足预测值的资源需求。当预测值的资源需求被满足后,再计算出每个虚拟机实例所能提供的资源量与预测资源需求量之差所构成向量(以资源价值WX为权值)的向量模长,在满足资源需求的前提下,通过不断地寻找最小长度的向量,从而确定当次所选的待关闭的虚拟机。得出所需的每类虚拟机的数量后,通过与已开启的虚拟机进行比较,得出合理的虚拟机开启/关闭方案,并进行虚拟机调度。其中,资源价值WX是由管理员给出的,用于平衡各资源间不同单位及价值的参数。例如,设定WCPU=1(/GHz),WMEM=1(/MB),WStore=0.5(/GB),表示使用同相时长的1 GHz CPU时间与1 MB内存的成本相同,而使用同相时长的1 GB存储空间的成本则仅有前二者的一半。此时,算法在计算虚拟机分配方案时,会倾向于在满足需求的前提下,以稍大的存储空间来换取较小的CPU时间及内存浪费。
4 仿真实验
4.1 仿真方案
为仿真需要,本文实现了第3章所述的各个云系统API的代理,将仿真数据作为实际数据输入,以考察算法。由于应用的最大并发请求数与所需资源间存在的函数关系freq-rc不是本文的研究重点,在此假定最大并发请求数与所需资源间存在线性关系。
4.2仿真数据
本文选取了广州大学门户网站2010年04月21日至2011年04月20日间每小时的最大每分钟并发登录量数据,共8 760项。每项数据由两个域组成:时间及最大每分钟并发登录量。时间域记录了数据的记录时段,如2011-01-01 00,指数据的记录时段为2011年01月01日00:00~00:59;最大每分钟并发登录量记录了在此时段内最大的每分钟并发登录量。
本文选取了Amazon EC2的5种虚拟机实例[13]为仿真用虚拟机的资源值。设定仿真用最大并发请求数与所需资源间存在的线性关系freq-rc如下:
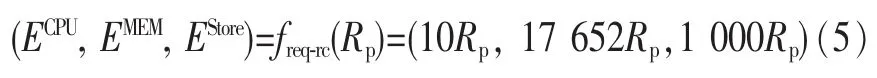
设定仿真用资源价值向量如下:
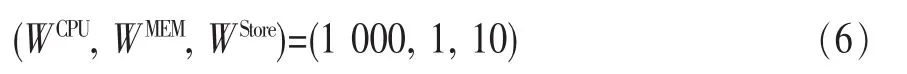
4.3 仿真结果
原数据共有365日,8 760项。本文所提出的最大并发请求数预测算法使用了最近一个月(29日)的历史数据来预测下一时间段的资源需求,故算法只能用于数据时间段的第二个月起的需求预测,即本文共得出8 016项结果。
4.3.1 最大并发请求数预测仿真
在仿真中,本文共产生了8 016个预测结果,预测结果面积见图2。由于数据较多,限于排版精度,仅显示了前500个数据;由于数据波峰及波谷的数值差距较大,限于排版精度,在绘图时使用了以2为基底的对数刻度。
从图2中可以看出,预测值的大小及变化趋势与实际值基本相符。对全部数据而言,预测值对实际值的平均误差为+28.50%,平均每项误差方差为0.042%。
4.3.2 预测修正仿真
最大并发请求数预测仿真共产生了8 016个预测结果,其中,有3 976项即49.60%预测值小于实际值,需要使用预测修正算法进行修正以满足资源需求。预测修正算法的仿真结果见图3。由于数据较多,限于排版精度,仅显示了前500个数据,纵坐标轴为预测修正算法即时增加供给后对实际值的平均超量百分比,即预测值加预测修正算法的即需供给值超出实际值的百分比。
从图3可以看出,预测修正算法即时增加供给后对实际值的平均超量百分比为14.01%,平均每项超量百分比方差为0.0017%。
4.3.3 虚拟机选择算法仿真
最大并发请求数预测及预测修正仿真共产生了8 016个预测结果,依此对虚拟机选择算法进行了仿真,仿真结果见图4。由于数据较多,限于排版精度,仅显示了前500个数据,纵坐标轴为虚拟机选择算法浪费率,即经算法调度的所有虚拟机所提供的资源大于实际所需资源的部分与实际所需资源之比。
从图4可以看出,虚拟机选择算法平均浪费率为6.44%,平均每项浪费率的方差为0.00080%。
4.3.4 仿真结果分析
本章从3个方面描述了仿真结果,最大并发请求数预测算法产生的预测值对实际值的平均误差为+28.50%,平均每项误差方差为0.042%;预测修正算法即时增加供给后对实际值的平均超量百分比为14.01%,平均每项超量百分比方差为0.0017%;虚拟机选择算法平均浪费率为6.44%,平均每项浪费率的方差为0.00080%;模型整体误差为+55.94%,即有效资源利用率为64.13%。
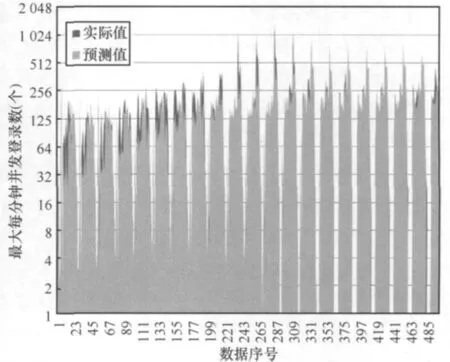
图2 资源仿真结果面积

图3 预测修正超量折线

图4 虚拟机选择算法浪费率折线
总的来说,本文提出的这一模型的有效资源利用率为64.13%,远高于当前绝大多数的数据中心服务器15%~20%的利用率,其使得具有自适应性云计算模型相较于传统的数据中心,在硬件购置成本、能源消耗及中长期规划设计上均能够体现出一定的优势。
5 结束语
本文在IaaS云环境下,通过探索合适的资源供应算法,建立了相应的自动资源管理模型,基本解决了云计算平台的规模自适应性问题。自适应资源供给的实现使得云能够根据运行时的状态自动调整资源供应,从而保证了资源的供应规模能够随云服务运行时业务负载的变化而伸缩。
本文采用了二次平均时间序列预测算法来预测业务负载,特别适合于业务负载周期性变化规律较为明显的环境。实验数据表明,该算法较好地完成预期目的,具有一定的精确性及稳定性,能够基本正确地反映资源需求的短期变化情况,但也造成了模型中大部分的误差,且这一误差被后续算法进行了放大,故仍有进一步改进的空间及必要。预测修正算法较好地解决了模型可能面临的突然出现的快速增长的需求尖峰问题,对现有最大并发请求数预测算法不失为一种有益的补充,但没有涉及预测值远大于实际值的情况,为今后进一步研究的方向之一。虚拟机选择算法以较好的代价及稳定性解决了给定资源需求下的虚拟机分配问题,利用加权的向量长度,给予了系统管理员合理的自主性。但这一算法目前没有考虑将多个小虚拟机替换为一个大虚拟机的情况,今后可以进一步研究。
除第4章所讨论的理论上影响算法效率的因素之外,一些实际因素亦会对算法的最终效率造成影响。例如,虚拟机调度指令显然需要占用一定甚至较多的系统资源,且不同的调度指令所消耗的资源通常不同,从而使得虚拟机调度指令在整个算法的实际消耗中占据了较大且不易进行纯理论分析的一部分;又例如,支持自动负载平衡、自动节点发现及自动容错的动作时间及资源消耗,显然是与应用相关的。限于各种条件,以上两例及其他一些可能的影响实际算法效率的因素留待今后讨论。整体而言,本文的工作能够大幅提升资源利用率至64%,使得具有自适应性的云计算系统相较传统的数据中心,在硬件购置成本、能源消耗、服务质量及中长期规划设计上均能够体现出一定的优势。
参考文献
1 Ian Foster,Yong Zhao,Ioan Raicu,et al.Cloud computing and grid computing 360-degree compared.Grid Computing Environments Workshop,2008
2 Carsten Binnig,Donald Kossmann,Tim Kraska,et al.How is the weather tomorrow?towards a benchmark for the cloud.Proceedings of the Second International Workshop on Testing Database Systems,ACM New York,NY,USA,2009
3 云端运算.维基百科,http://zh.wikipedia.org/w/index.php?title=%E9%9B%B2%E7%AB%AF%E9%81%8B%E7%AE%97&oldid=18129937,2011
4 Amazon Elastic Compute Cloud (Amazon EC2).http://aws.amazon.com/ec2/,2011
5 John Viega.Cloud computing and the common man.Computer,2009(42)
6 Jie Yang,Jie Qiu,Ying Li.A profile-based approach to just-intime scalability for cloud applications.Proceedings of IEEE InternationalConferenceonCloudComputing,Bangalore,India,2009
7 Gansen Zhao,Jiale Liu,Yong Tang,et al.Cloud computing:a statistics aspect of users.Proceedings of the First International Conference on Cloud Computing,Beijing,China,2009
8 Gansen Zhao,Chunming Rong,Jiale Liu,et al.Modeling user growth for cloud scalability and availability.Journal of Internet Technology,2010,11(3)
9 Gokul Soundararajan,Cristiana Amza.Reactive provisioning of backend databases in shared dynamic content server clusters.ACM Trans Auton,2006,1(2)
10 Jerry Roliaa,Xiaoyun Zhua,Martin Arlitta,et al,Statisical service assurances for applications in utility grid environments.Performance Evaluation,2004,11(58):319~339
11 二次移动平均法.http://course.cug.edu.cn/cugFirst/statistics/neirong/zhang194.htm,2011
12 矢量.http://zh.wikipedia.org/wiki/%E5%90%91%E9%87%8F,2011
13 Amazon EC2 Instance Types. http://aws.amazon.com/ec2/instance-types/,2011
猜你喜欢
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
基层中医药(2020年7期)2020-09-11
国外核新闻(2020年8期)2020-03-14
中国生殖健康(2019年8期)2019-01-07
西南军医(2015年5期)2015-01-23
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
江苏卫生事业管理(2013年5期)2013-03-11
