
基于动态指令基因的病毒防护方法研究
2012-06-03 09:15:30白杰
电子技术应用 2012年10期
白杰
(光束(北京)国际工程技术研究院有限公司,北京100083)
在互联网高速发展的今天,网络通信和网络交易已经成为日常生活不可分割的一部分。但病毒生成技术的提高,已经严重影响到世界通信安全和国家的经济命脉。早期特征码技术已经无法单独应对现在的计算机病毒。为了解决此问题,近些年国际上提出了依据程序行为识别病毒的技术。其原理就是监控程序的行为,将程序行为与有害程序行为数据库进行比较,判断被监控程序是否为病毒。目前为了提高识别病毒的精度,减少误报和漏报情况,各国研究人员从不同的角度,定义程序的行为数据和获取行为数据的方法,设置了不同行为数据类型的有害行为数据库,但程序仍然存在很大的不稳定性、误识别率,且严重依赖系统并发资源。
本文提出的利用程序被执行过程中的有效指令基因判断病毒的模型摒弃了目前占主流地位的“通过获取程序静态行为”的思路,通过运算出程序被执行过程中的动态指令基因达到精确识别病毒的目的,该模型突破了目前只能依靠“程序静态行为”分析病毒方法,以及目前无法在程序被执行过程中达到同步且动态实时监控的目标,并取得了理想的效果,克服了互联网防御病毒的技术障碍。
1 程序动态指令基因防御病毒的系统模型
通过滑动窗口实时动态扫描被检测程序运行过程中在处理器以及存储器中的数据流,计算出程序指令基因(有效指令结构的指纹数据)。
1.1 获取待检测程序被执行过程中的数据流
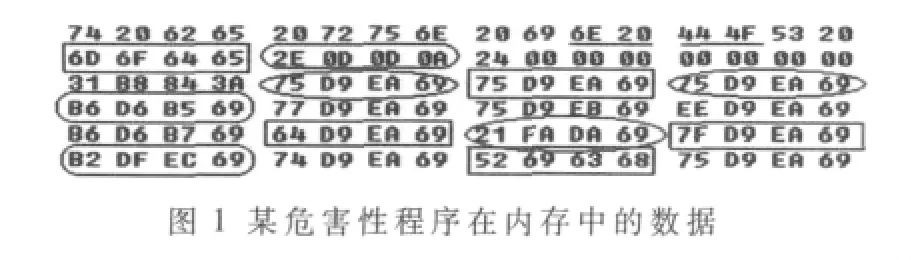
获取待检测程序运行过程中的内存数据并将之输出。使用函数createtoolhelp32snapshot()创建内存快照;将返回句柄传递给函数 process32first(),函数 process32next()遍历内存中的进程,遇到待检测程序的进程时,保存其进程 id;用函数 openprocess()打开该进程,获得该进程的句柄;用函数readprocessmemory()读取该进程句柄;获得待检测程序运行过程中的内存数据。图1是程序的内存数据,标示的代码就是有效指令代码(指令基因)。
1.2 有效指令基因分析
利用滑动窗口动态扫描程序的有效指令基因数据,如图2、图3所示。定义该 3个应用程序为:EXE1、EXE2、EXE3,指令基因码分别是:EXE1=[a1,a2,a3,a4,a5,a6,a7…an,a(n+1)]; EXE2=[a1,a0,a02,a3,a02,a6,a7…an,a(n+1)];EXE3=[a1,a06,a2,a3,a08,a6,a7…an,a(n+1)];采用“分段式多指针位移算法”将待扫描数据进行不间断式取点分段,设定多项指针,通过指针段内位移,对数据进行扫描,在实现过程中采用线程结构。
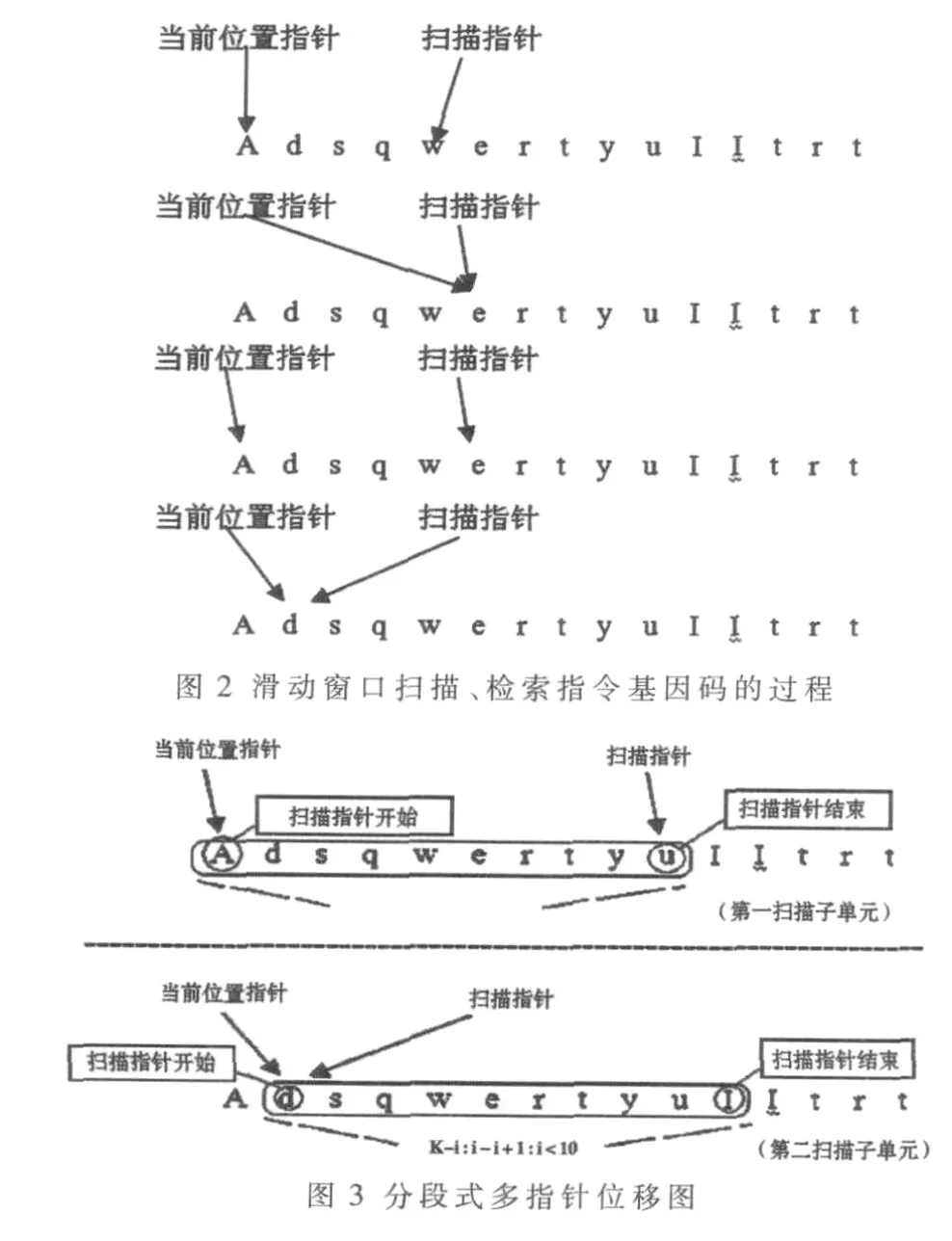
比较 3个程序的功能和执行结果,得出:K=EXE1=EXE2=EXE3。分别考察 EXE1、EXE2 和 EXE3,得出(a1)、(a2,a3)、(a6,a7)、an,a(n+1)是 有 效 的 基 因 序 列 ,其 余 的是相对于执行结果无效代码,也就是对于特定的K,其指令元数据序列片段“(a1)、(a2,a3)、(a6,a7)、an,a(n+1)”是稳定的。
被截获的待检测程序能够完成特定功能或结果的指令元数据序列为源序列。所有源序列的集合:E={e1,e2,e3,…,en,e(n+1)} ,其中 e1,e2,e3,…等为具体的源序列,n为正整数。在系统S中,产生的源序列v1,v2,…,vi,就是待检测程序在系统 S中的踪迹,其中 vi∈E,i为正整数,并且i≤n,每个源序列有时间性和执行性为 C(vi),指令执行 按时间排序,即对所有的i≥1,C(vi)<C(vi+1);假设执行性为 O(vi),表示指令的执行性,用pid表示进程,则O(vi)∈pid。对任意一个进程pi,其指令序列 v1,i1,v2,i2,…,vi,ii,vi+1,ii+1。 其中,i1,……,ii+1分别对应指令结果 v1,v2,…,vi+1的执行结果,进程pi对应的指令序列为进程踪迹。可见,pi的进程踪迹是待检测程序在系统S中踪迹的子串。假设被检测程序在正常运行时产生的源序列为:V=v1,v2,…,vm(m≥k),则V可以看作由被检测程序在系统S中的每一个进程的执行过程合并而成。按执行的时间性将每一个进程的子执行过程合并排列,形成被检测程序在正常运行时产生的审计源序列V。假设被检测程序运行时有两个进程,则V有两个子串记为V1⊙V2。设P为程序指令元,其中存储的典型指令元序列或片断以源序列V为基础,可以采用滑动窗口技术获得。假设k为滑动窗口大小,则:P={(si,si+1, …,sj)|si, …,sj∈E,i≥1,j≤m,j-i+1=k,si=vi,si+1=vi+1,…,sj=vj},其中m为源序列 V 的长度,可见,程序指令元P中存储的是源序列V的子集[1]。
设EXE1的有效指令全集是F(1),EXE2的有效指令全集是 F(2),EXE3的有效指令全集是F(3),其中,F(1)∈F,F(2)∈F,F(3)∈F,F为包 括F(1)、F(2)和F(3)的 有效指令集。则,F(1)、F(2)、F(3)就是被检测的程序的数据源,它们分别为不同的源序列V,是被检测的对象。也即, 通过预先定义的程序指令元:VF={y1,y2,y3…yn,y(n+1)},将VF中的元素分别与数据源F(1)、F(2)、F(3)进行差异运算,即可实现被检测程序EXE1、EXE2、EXE3的执行检测。
采用滑动窗口、函数计算方式顺序获取待检测程序中能够完成特定功能或结果的指令元数据。假设k为滑动窗口的大小,被监控程序在运行时产生的源序列V:v1,v2,…,vm(m≥k),用滑动窗口在源序列 V上滑动,则滑动窗口内的k个事件序列(vi,vi+1,…,vi+k-1)即为待检测指令元数据序列。在不同的实例中,滑动窗口的大小k,或者所述指令元数据序列的长度是不同的,比较典型的k为 7~12,本文的k取值为 10,如图 3所示。
1.3 形成病毒指令基因数据库
v1、v2、v3、v4为具有相同或相似破坏方式的同一族已知病毒程序。
病毒程序v1的内存数据00,01,h1,44,b1,a1,33,c1,bw,0i,22,8i,11,2s,yy。
病毒程序v2的内存数据00,cc,ae,44,b1,q3,33,c1,kh,al,22,8i,11,s3,yy。
病毒程序v3的内存数据00,2c,3e,44,b1,w3,33,c1,nh,a0,22,8i,11,l3,yy。
病毒程序v4的内存数据00,24,3o,44,b1,wl,33,c1,0h,ui,22,8i,11,4n,yy。
将这些已知病毒程序的内存数据相互间具有相同或相似的部分提取出来,其中,该类病毒程序运行过程中的内存数据相互间具有相同的部分:0044,b133,c122,8i,该相同部分的有序排列表示为:#00#44,b1#33,c1#22,8i#。该类病毒运行过程中的内存数据相互间具有相似的部分是:病毒程序v1的内存数据末尾部分(11,2s,yy)相似于病毒v2的内存数据末尾部分(11,s3,yy)相似于病毒 v3的内存数据末尾部分(11,l3,yy)相似于病毒程序v4的内存数据末尾部分(11,4n,yy),该相似部分可用#11,**,yy#表示。符号“#”代表相同内存数据以外的内存数据,符号“*”代表相似内存数据中的不同部分。将#00#44,b1#33,c1#22,8i#存储进数据库;将#11,**,yy#存储进数据库。病毒的运行特征数据是将已知病毒程序运行过程中的内存数据相互间具有相同或相似的部分提取出来,且按序排列进行存储形成病毒指令基因数据库。
2 具体应用描述
无论是待检测程序还是病毒程序,其运行特征数据不仅仅只限于运行过程中的内存数据,例如某个程序被CPU执行过程中的独有的运行特征数据。CIH类型的病毒利用中断操作,从系统的用户层强行到系统的内核层,破坏计算机硬件。
因为此类病毒是从系统的用户层转到系统的内核层,因此在CPU内的高速缓存中存在从系统的用户层到系统的内核层区别于运行其他程序的迹象,即:正常的程序被执行时,高速缓存顺序从内存调取数据,一般情况下应用程序工作在系统的用户层,此类病毒程序利用处理器的中断操作从系统的用户层强行转到系统的内核层,因此在高速缓存中存在一些从系统的用户层向系统的内核层跳转的数据。但这些数据并非都是病毒程序,因为个别的正常程序也用到此方式,获取跳转到的内存相应的数据,并提取此类型病毒对于这部分数据所共有的部分。
(1)汇编指令:out 70h,al;in al,71h;xor ax,926h; ###jmp 2000:003;add al,bl→机器码:9i 7u 16 14 5h a7 3t###77 e1 77 6c 00 d8(假设“###”左边部分是利用中断操作从系统的用户层强行转到系统的内核层,“###”右边部分是对BIOS芯片的破坏操作)。假定待检测程序A的运行特征如下:[汇编指令:mov ax,1016h]→机器码:b8 31 2e;…;[汇编指令:out 70h,al]→机器码:9i 7u(与病毒相同的指令基因);[汇编指令:in al,71h]→机器码:16 14(与病毒相同的指令基因);[汇编指令:xor ax,926h]→机器码:5h a7 3t(与病毒相同的指令基因);…;[汇编指令:mov ah,0]→机器码:b4 00; …;[汇编指令:jmp 2000:003]→机器码:77 e1 77 6c(与病毒相同的指令基因);[汇编指令:add al,bl]→机器码:00 d8(与病毒相同的指令基因)。
(2)待检测程序 A的运行特征:机器码 b8 31 2e 0e 21 4d 8h 63 5h 9i 7u 16 14 5h a7 3t 00 7c 2d b8 20 4e 05 16 14 04 9c b4 00 77 e1 77 6c 00 d8,其 中,机 器码9i 7u 16 14 5h a7 3t是利用中断操作从系统的用户层强行转到系统的内核层;机器码77 e1 77 6c 00 d8是对芯片的破坏操作。
(3)待检测程序B的运行特征:机器码9i 02 11 6h 8i u8 e3 9i 7u 16 14 5h a7 3t b8 31 2e 0e 21 4d 8h 63 7c 2d b8 20 9c b4;虽然待检测程序B的机器码中也存在9i 7u 16 14 5h a7 3t,也同样利用中断操作从系统的用户层强行转到系统的内核层,但是检测程序B的机器码中不存在对芯片进行破坏的数据。
3 病毒的检测
将 (指令元 1+指令元 2+指令元 3)→(结果 1+结果2+结果 3)=最终结果,存储到所述的原则库中,同时在原则库中标示出病毒程序的最终结果,表1所示为指令元、有效代码序列(运行特征代码)、运行结果、危险系数的关系。
将获得的待检测程序的指令元数据与建立的原则库中的对应关系表达式相应部分进行比较,对比较成功的次数进行计数,当比较成功的次数等于或者超过设定的阀值时,判定所述待检测程序为病毒程序。
获得的待检测程序指令元数据是:指令元1+指令元2+...指令元X;
原则库中某项数据是:指令元 11+指令元 22+...指令元nn;
假定,指令元 1=指令元 11,指令元 2=指令元 22,则Y的值应该等于2。
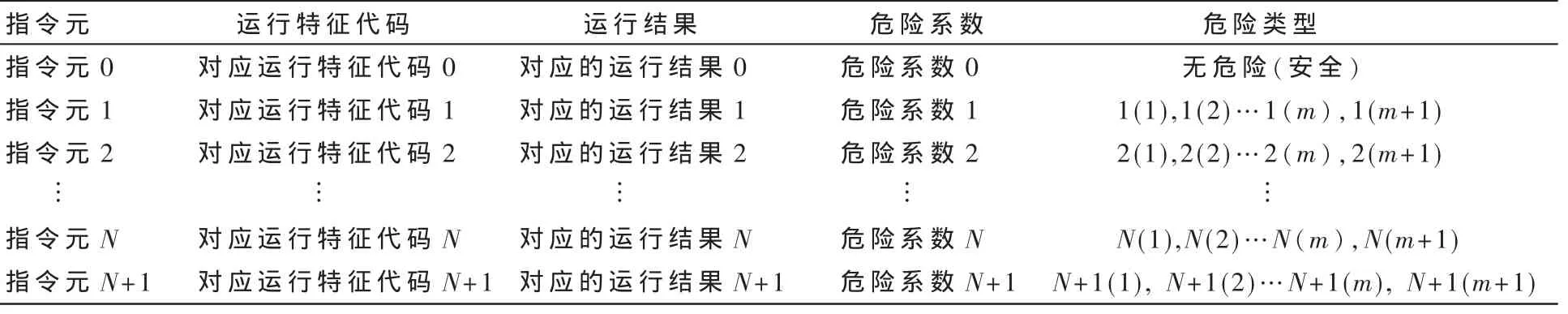
表1 程序指令元与程序运行结果的关系结构
第二个意义的阈值是:待检测程序的指令元数据或指令元数据的集合与所述的最终结果有关联关系或者待检测程序的指令元数据或指令元数据的集合能够导致所述的最终结果,此为第二个意义的阈值。如获得的待检测程序 i.exe指令元数据是:指令元 i1+指令元 i2+指令元i3;获得的待检测程序g.exe指令元数据是:指令元 g1+指令元 g2+指令元 g3+指令元 g4+指令元g5;原则库中某项数据是:(指令元1+指令元 2+指令元 3)→(结果1+结果 2+结果 3)=最终结果;其中,指令元(g1+指令元g2+指令元 g3+指令元 g4+指令元 g5)=(指令元 1+指令元2+指令元 3)→(结果 1+结果2+结果 3)=最终结果;(指令元 i1+指令元 i2+指令元 i3)≠(指令元1+指令元 2+指令元 3)。 因此,待检测程序 i.exe判定为不是病毒程序,待检测程序 g.exe判定为病毒程序。
分别获取待检测程序 l.exe与 m.exe的运行特征数据 :l.exe 的 运 行 特 征 数 据 是 :a0,qo,9i,80,5h,3h,jg,pq,ci,c1,8k,00,0k,ab,c3,ck;m.exe 的 运 行 特 征 数 据 是 :1a,2b,c3,4d,f5,6h,7k,j8,9k,10,11,22,33,44,55,6i;原则库中某项数据是:(#qo,9i,80,**,3h,jg#)→病毒运行后对系统造成的恶性结果;待检测程序 l.exe判定为病毒程序,m.exe判定为不是病毒程序。
4 实验过程与结果
由于采用的是基于指令基因的方式,在实验中不需真实且可运行的病毒体,可直接指定待检测出的指令基因数据集即可。Windows系统中可完成目标功能的指令基因元为n,形成有效组合为m,对5个进程进行检测,每个进程包含的指令元为N,有效组合为M,N>n,M>m。根据表2,平均准确率为 91.7%,平均误报率为0.19%,漏报率为0。检测分类表如表2所示。

表2 检测分类表(以下均为平均值)
本技术解决了目前世界上非特征码技术错误率高的技术难题。且能够直接检测程序运行过程中的内存数据,不需要对加壳病毒等进行解密、脱壳操作,极大地减少了对于系统资源的消耗。在实践应用中取得了较好的结果。
[1]张衡,卞洪流,吴礼发,等.基于 LSM 的程序行为控制研究[J].软件学报,2005,16(06):1151-1158.
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
当代陕西(2019年13期)2019-08-20 03:54:22
人大建设(2019年12期)2019-05-21 02:55:44
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
瞭望东方周刊(2017年42期)2017-12-05 18:49:38
环球时报(2017-03-30)2017-03-30 06:44:45
中国卫生(2015年3期)2015-11-19 02:53:32
机电信息(2014年27期)2014-02-27 15:53:56
测绘科学与工程(2014年5期)2014-02-27 07:06:14
