
Key Technologies in Mobile Visual Search and MPEG Standardization Activities
2012-05-22 03:37LingYuDuanJieChenChunyuWangRongrongJiTiejunHuangandWenGao
ZTE Communications 2012年2期
Ling-Yu Duan,Jie Chen,Chunyu Wang,Rongrong Ji,Tiejun Huang,and Wen Gao
(Institute of Digital Media,Peking University,Beijing 100871,China)
Abstract Visual search has been a long-standing problem in applications such as location recognition and product search.Much research has been done on image representation,matching,indexing,and retrieval.Key component technologies for visual search have been developed,and numerous real-world applications are emerging.To ensure application interoperability,the Moving Picture Experts Group(MPEG)has begun standardizing visual search technologies and is developing the compact descriptors for visual search(CDVS)standard.MPEG seeks to develop a collaborative platform for evaluating existing visual search technologies.Peking University has participated in this standardization since the 94th MPEG meeting,and significant progress has been made with the various proposals.A test model(TM)has been selected to determine the basic pipeline and key components of visual search.However,the first-version TM has high computational complexity and imperfect retrieval and matching.Core experiments have therefore been set up to improve TM.In this article,we summarize key technologies for visual search and report the progress of MPEG CDVS.We discuss Peking University's efforts in CDVSand also discuss unresolved issues.
Keyw ordsvisual search;mobile;visual descriptors;low bit rate;compression
1Visual Search
S earching for a specific object in a collection of images has been a long-standing problem with a wide range of applications in location recognition,scene retrieval,product search,and CDand book cover search.Smartphones and tablets have great potential for visual search because they have the integrated functionality of high-resolution embedded cameras,color displays,natural user interfaces,and 3G wireless connections.Most existing mobile visual search systems are deployed in a client-server architecture.The server end has a visual search system in which image representation and inverted index are based on a bag of words(BoW)model.In an online search,a mobile user can take a query photo and send it to a remote server that identifies the query image and its related description(Fig.1a).
Much research has been done on robust image representation,matching,indexing,retrieval,and geometric re-ranking.Fig.2 shows a typical flow chart for a visual search.Globalfeatures[1],[2]and/or local features[3]-[7]are extracted from database images at a server.The server looks for relevant images based on visual similarity between a query and database images,and inverted indexing speeds up the process(Fig.2a).Local features are particularly important in a visual search.Even though detecting global features is fast and little memory is required,matching and retrieval based on globalfeatures is often less accurate than matching and retrieving based on local features[8].Recently,Chen et al.showed that a visual search using both global and local features yields better results than using local features only[9].
Using brute force to match query features with database features is infeasible for large-scale databases,and a feature index is needed to improve search efficiency(Fig.2b)[3],[10]-[12].Other solutions include approximate nearest-neighbor search,such as k-D tree[3],[10],or locality-sensitive hashing[11],[12].In addition,a feature-space quantization scheme,such as k-means,and scalable vocabulary tree[13]-[15]have been widely used for scalable image search,in which two individual features are considered the same word if they fallinto the same cluster.
In online search,local features in a query image are extracted and used to search for the local features'nearest neighbors based on a database of reference images.Database images containing nearest neighbors are quickly collected using indexing and are ranked according to a similarity score(Fig.2c)[13]-[15].Finally,the top returned images are re-ranked through geometric by taking into account the location of local features(Fig.2d)[14],[16],[17].

▲Figure 1.(a)Mobile visualsearch pipeline.An image database and scalable image index is maintained at the server end.Aquery photo is transmitted to the remote server to identify reference images and relevant information.(b)Image matching involves feature extraction and feature matching.
Both academia and industry have made significant progress on visualsearch,and there is now a growing number of systems or prototypes,including Google Goggles and Nokia Point&Find.To ensure application interoperability,the Moving Picture Experts Group(MPEG)has begun standardizing visual search technologies,in particular,compact descriptors for visualsearch(CDVS)[18].CDVSis considered a core technique in augmented reality.
In section 2,we discuss MPEG's progress on CVDSand Peking University's(PKU's)responses to the MPEG CDVS call for proposals(CfP).We also describe the setups of PKU's core experiments.In section 3,we discuss compact descriptors and related issues such as indexing,retrieval,and geometric re-ranking.In section 4,we discuss open problems and challenges.Section 5 concludes the paper.
2 MPEG Compact Descriptors for Visual Search
2.1 Introduction to CDVS
Academia and industry have made progress on key components for visualsearch;however,severalissues still remain[2]-[4],[13]-[15].It is not clear,for example,how to make visual search applications compatible across a broad range of devices and platforms.This is one of the motivations for MPEG CDVSstandardization,which was discussed during the first and second Workshops on Mobile Visual Search hosted by Stanford University[19]and PKU[20],respectively.These workshops led to a formalrequest being made to MPEG for CDVSstandardization and a fleshing out of CDVS requirements.
At the 92nd to 96th MPEG meetings,CDVSexperts investigated potential applications,scope of standardization,requirements,and evaluation framework[21]-[24].At the 97th MPEG meeting,the CfPwas issued[25].To ensure interoperability,the CDVSstandard aims to define the format of compact visualdescriptors as wellas the pipeline for feature extraction and search process[22].
The visual descriptors need to be robust,compact,and easy to compute on a wide range of platforms.High matching accuracy must be achieved at least for images of rigid,textured objects;landmarks;and documents.Matching should also be accurate despite partial occlusions and changes in vantage point,camera parameters,and lighting.To reduce the amount of information transferred from the client end to the server end,and to alleviate query transmission latency,the descriptor length must be minimized.Descriptor extraction must allow adaptation of descriptor length so that the required performance level can be satisfied for different database.Extracting descriptors must not be complex in terms of memory and time so that they are deployable in most common platforms.
2.2 Evaluation Framework

▲Figure 2.Visualsearch pipeline in a client-server architecture,and basic components of feature(a)extraction,(b)indexing,(c)matching,and(d)re-ranking.
Here,we summarize the CDVSevaluation framework[26],which closely aligns with CDVSrequirements[22].Different proposals is evaluated using two types of experiments:retrievaland pairwise matching.The retrieval experiment is done to determine descriptor performance during image retrieval.Mean average precision(mAP)and success rate for top matches are the evaluation criteria.The pairwise matching experiment is done to determine the performance of descriptors during the matching of image pairs.The localization precision is assessed according to the ground-truth of localization annotations.Performance is measured by the success rate at a given false alarm rate(for example 1%),and localization precision.
Each proposal sent to MPEG needed to show the descriptor's scalability,and this is done by reporting the performances at six operating points of different query sizes:512 bytes,1 kB,2 kB,4 kB,8 kB,and 16 kB.Interoperability of the descriptors is also evaluated.Adescriptor generated at any of these six operating points should allow matching with descriptors generated at any other operating point.For each proposal,an experiment is conducted to evaluate pairwise matching of 1 kBdescriptor versus 4 kBdescriptor,and 2 kB descriptor versus 4 kB descriptor.To reduce time-related complexity,feature extraction must not be longer than two seconds,pairwise matching must not be longer than one second,and retrieval must not be longer than five seconds in a single thread the reference platform(Dell Precision workstation 7400-E5440).
Eight datasets are collected in the CDVSevaluation framework.These datasets are ZuBud,UKBench,Stanford,ETRI,PKU,Telecom Italia(TI),Telecom Sud Paris,and Huawei.There are 30,256 images categorized as mixed text and graphics,paintings,frames captured from video clips,landmarks,and common objects.Fig.3 shows these categories and the number of reference images.Each dataset provides ground-truth annotation of pairs of matching and non-matching images as well as ground-truth annotation of query images and corresponding reference images.For localization,the mixed text and graphics category provides bounding boxes for each matching pair.In the retrieval experiment,the discriminability of a descriptor is assessed using a distractor image set containing one million images of varying resolutions and content(collected from Flickr).
2.3 Progress on CDVSand Evidence from CDVSResearch
Remarkable progress has been made at MPEG CDVS Ad-Hoc Group meetings.At the 94th MPEG meeting,PKU proposed an extremely compact descriptor based on a bag-of-features histogram rather than features.This compact descriptor provides a much higher compression rate without serious loss of discriminability[27]-[30].To determine the lowest operating point for a promising visual search,geo-tag(a kind of side information)is used to produce very compact descriptors for visual searches of landmarks[29],
1Extra bits for coding locations are not counted as partof the 256 or 128 bits.In the
currentevaluation framework[39],each operating pointrefers to the length of overall bit streams,including visualdescriptors,locations,and other information.[30].A photo collection of landmarks is first segmented according to discrete geographical regions using a Gaussian mixture model.Then,ranking-sensitive vocabulary boosting is done to create a very compact codebook within each region.When entering a new geographicalregion,codebooks in the mobile device are downstream-adapted,which ensures compactness and discriminative power.This technique is called location-discriminative vocabulary coding(LDVC).With only hundreds of bits per query image,LDVC performs descriptor coding over the bag of scale-invariant feature transform(SIFT)features[29].Referring to such a small number of bits,the CDVSAd-hoc Group has determined that 512 bytes,is the lowest point(including space for coordinate information).

▲Figure 3.Image categories and the number of reference images in the corresponding CDVSevaluation dataset.
Beyond landmark search,visual statistics and rich contextual cues at the mobile end are exploited over the reference image database to determine multiple coding channels[28].A compression function is determined for each channel.Aquery is first described in a high-dimensional visual signature that is mapped to one or more channels for further compression.The compression function within each channelis determined according to a robust principle component analysis(PCA)scheme,and the retrieval ranking capability of the original signature is maintained.With hundreds of bits,the resulting descriptor has search accuracy that is comparable to that of the original SIFTfeatures[28].In summary,PKU's research has shown that extremely low bit-rate descriptors(128 or 256 bits per query image1)are possible using quantization and by establishing a small but discriminative codebook.
At the 98th MPEG meeting,proponents of CDVSsubmitted 11 proposals for compact descriptors.These proposals broadly fall into two categories.In the first category,compact descriptors are produced by compressing local descriptors,for example SIFTdescriptors,in a data-driven or data-independent way.Raw descriptors are first extracted using existing techniques.Then,raw descriptors are compressed to produce a compact descriptor.Proposals from TI[26],PKU[31],[32],and Stanford&Aptina[33]fall into this category.In the second category,distinct compact descriptors are produced at the first stage of raw-descriptor extraction;there is no additional and separate compression stage.NEC's proposalbelongs to this class[34].

▲Figure 4.Key components in CDVStest modelunder consideration.
Both TIand PKU proposed quantizing raw SIFTdescriptors with product quantization in which quantization tables are pre-learned on a training dataset[35],[36].The difference between the proposals from TIand PKU lies in how the raw segment of a SIFTdescriptor is subdivided.PKU divides a SIFTdescriptor into more segments,and each segment is quantized with a smaller codebook.In contrast,TIdivides a SIFTdescriptor into fewer segments,and each segment is quantized by a large codebook.TI's solution has greater matching and retrieval accuracy than PKU's;however,PKU's solution has greater localization accuracy than TI's.Moreover,TI's quantization table may take up 500 MB,which is much larger than PKU's at approximately 10 MB.
Stanford&Aptina[33]use type coding to compress SIFT-like descriptors.Compared with the product quantization of TIand PKU,type coding is data-independent and requires none of pre-learned quantization tables.Data-independent methods usually perform worse than data-driven methods,especially at lower operating points such as 512 bytes and 1 KB.
NEC[34]proposed a binary descriptor created by binarizing the histogram of quantized gradient orientations.The pairwise matching and localization of NEC's binary descriptor outperforms that of TIand PKU.However,retrieval is much worse than in other proposals at almost all operating points and datasets.Significant degeneration in retrieval can be attributed to severe loss of discriminative information when there is a huge number of distractors.
After the CDVSCfPissued at the Torino meeting,a test modelunder consideration(TMuC)based on product quantization was selected at the 98th MPEG meeting in Geneve[37].Crucial stages such as local descriptor extraction,feature selection,compression,and location coding have been identified in the TMuC[37].Fig.4 shows the modules and dataflow in the test model.The first two blocks extract raw local descriptors,including a multiscale key-point detector based on difference of Gaussian(DoG)and a feature descriptor SIFTbased on gradient-orientation histogram.Key-point selection filters in a subset of important key points fulfill the compactness and scalability requirements.Product quantization compresses a SIFT descriptor in a data-driven way,and coordinate coding compresses key point locations.In the TMuC,SIFTis used as local descriptors because it has excellent scale and rotation invariance.More than 1000 key points could be detected in a 640×480 VGA image.To create a very compact descriptor,a subset of useful key points is kept.The TMuC has shown that key-point selection is critical to maintain search accuracy at lower operating points because noise points can be filtered out without loss of performance.The descriptor at each key point is product quantized with pre-learnt tables.Descriptor length can be significantly reduced;for example,in PKU's proposal,more than 85%of bits are saved.Feature locations are finally compressed by quantization and context arithmetic coding.
Several issues remain open in the first version of the TMuC.First,quantization tables may consume up to 500 MB of memory,which is infeasible for most mobile phones.Second,the current TMuC is built on DoG-based interest-point detection and raw SIFTdescriptor.However,both these techniques are patented[38].UBC has granted both non-exclusive and exclusive field-of-use licenses to multiple companies.If UBC has already granted exclusive rights to commercialize SIFTin mobiles(where most likely MPEG CDVSwould be used),the patents would prevent widespread use of the standard and stymie competition.Fortunately,experts have shown that the current TMuC can be enhanced by replacing individual components with new technologies such as alternative interest-point detector and raw local descriptor.
2.4 Core Experiments
At the 99th MPEG meeting,six core experiments[39]were set up to investigate
·the effects of combining local descriptors with a global descriptor
·low memory solutions for descriptor compression
·improved feature-location compression efficiency
·key-point detection techniques to bypass intellectual property issues
·better uncompressed(raw)local descriptors
·more efficient retrieval pipeline.
Improvements in memory use,time complexity,search accuracy,and other aspects were verified at the 100th MPEGmeeting.Table 1 shows the timeline and milestones of MPEG CDVS.

▼Table 1.Timeline and milestones of MPEGCDVSstandardization
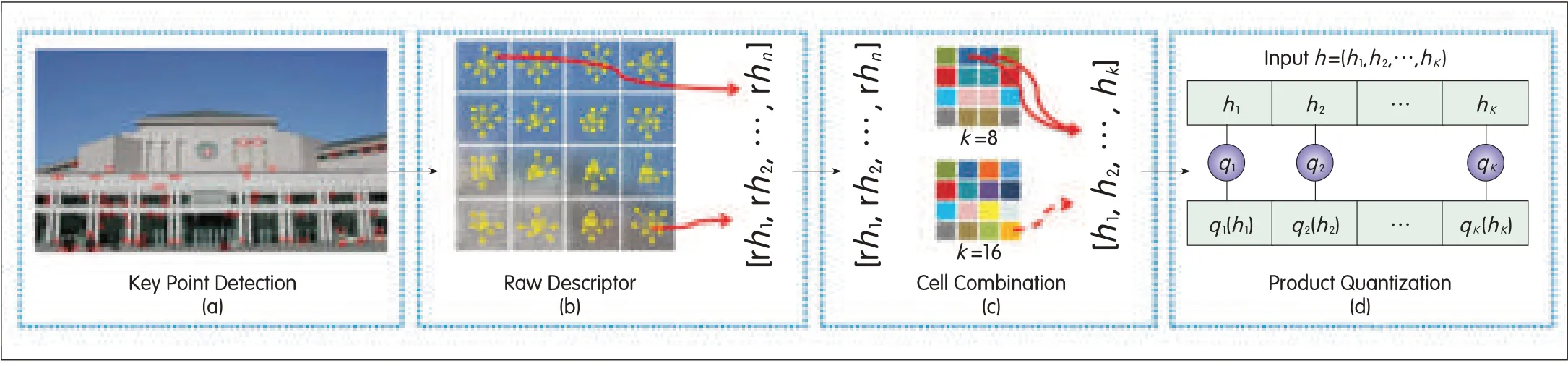
▲Figure 5.Product quantizing raw SIFTdescriptors in a data-driven way.
3 Compact Descriptors
To minimize the amount of information to be transferred,compact descriptors are desirable.Descriptor compactness relates to the number of local features and the size of a local feature.Typically,each local feature consists of visual descriptor and its location coordinates.Hence,descriptor size is determined by the compression rates of both visual descriptors and locations.Key-point selection is necessary to figure out a subset of important key points(Fig.4).Product quantization minimizes the length of local descriptors,and coordinate coding minimizes the length of location codes.In the following subsections,we introduce techniques for local descriptor compression,location coding,and key-point selection.We also discuss PKU's compact descriptors.
3.1 Local Descriptor Compression
Feature extraction starts by selecting key points in an image.State-of-the-art visual search algorithms are built on a DoG detector followed by SIFTdescription[3].Such algorithms were used(sometimes in slightly modified form)in the CDVSproposals.To achieve low-bit-rate visual search,SIFTdescriptors and other popular descriptors,such as sped-up robust features(SURF)[4]and PCA-SIFT[40],are oversized.The size of hundreds of these localdescriptors is often greater than the originalimage size.The objective of descriptor compression is to significantly reduce the descriptor size without deteriorating visual discriminative power.In general,there are two groups of algorithms for compressing local descriptors.Algorithms in the first group quantize raw descriptors in a data-independent way.Chandrasekhar et al.proposed a descriptor called compressed histogram of gradients(CHoG),which uses Huffman Tree,Gagie Tree[41],or type coding[42]to compress a local feature into approximate 50 bits.Type coding involves constructing a lattice of distributions(types),given by

where Kiis the number of points in each lattice of a predefined 2-D gradient partition.Thus,the probability of these lattice distributions is

where n is the number of points within the gradient partition.
The index of the type closest to the original distribution is then selected and transmitted[42].Prior to type coding,descriptors are L1-normalized so that the descriptor can be dealt with as a probability distribution.
Algorithms in the second group work are data-driven.A codebook to partition the descriptor space is first determined from training data.Quantized descriptors are represented by the nearest code word[13],[26],[28]-[32],[35].PKU's proposal[31],[32],[35]and TI's proposal[26]fall into this category.Fig.5 shows PKU's descriptor compression using product quantizing.Generally speaking,a data-driven approach may result in better pairwise matching and retrieval than a data-independent approach,but storing a codebook consumes more memory.
3.1.1 PKU's Proposal for Product Quantizing SIFT Descriptors
In product quantization,an input vector is divided into k segments,and those segments are independently quantized using k subquantizers[31].Each compressed descriptor is thus represented by k indexes comprising the nearest code words of k segments.A less-complex quantizer qjis associated with the j th segment of the input vector.Product quantization is used to compress raw descriptors,given by
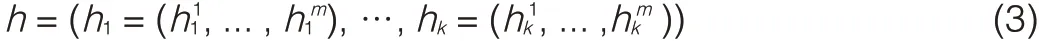
where hj=(hj1,...,hjm)is the histogram of the i th subsegment of length m.
The descriptor dimension is n=m×k.h is structured into k parts,each having m dimensions.The vectors are independently quantized from k parts using k subquantizers.The size z of subquantizer dictionaries is the same.The Cartesian representation space is given by zk.Each subquantizer q maps an m-dimensional vector hjto

where C is a set of reproduction values cjto represent original vector hjwith dimension m.The size of the dictionaries is z.
Quantizer quality is measured by the mean squared error(MSE)between an input vector and its reproduction value.Subquantizers are greedy learned by minimizing MSEusing Lloyd's algorithm.Consequently,the compressed descriptor is represented by a short code comprising the indexes in all the subquantizers.However,the descriptor compression in the TMuC is imperfect because product quantization requires large memory to store several tables.The size of quantization tables may reach up to 500 MB,which is unacceptable in mobile platforms.Reducing the size of quantization tables has been set up as a core experiment[39].
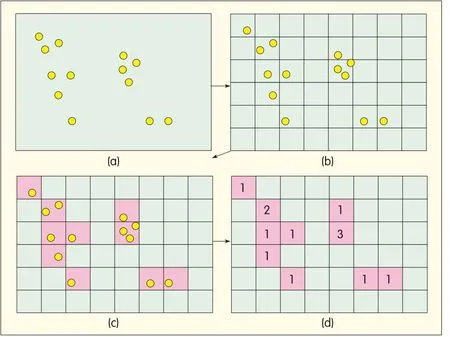
▲Figure 6.Coding location coordinates.(a)Spatialdistribution of local features,(b)coordinate space uniformly quantized with a 2Dgrid,(c)histogram map indicating emptiness on-emptiness of each block,and(d)histogram counting the number of features that fallinto each non-empty block.

▲Figure 7.Coding location coordinates according to an importancemap.(a)Spatial distribution of localfeatures.(b)The coordinate space is divided into blocks of different sizes,and the divisions are optimized by statistical learning.(c)Each block is assigned a unique number to identify differentlocations.(d)Block identifiers are sorted and are followed by difference-based entropy encoding.
3.2 Location Coordinate Coding
Each local feature comprises a visual descriptor and location coordinates.Avisualdescriptor is used to compute visual similarity,and the location part is for geometric verification when re-ranking returned images.Location compression is important in low bit-rate visual search.Take,for example,the lowest operating point of 512 bytes per query in the CDVSevaluation framework.For a 640×480 VGA image,20 bits are needed to encode a feature's location without compression.For an image comprising 500 local features,it would take about 1250 bytes to code location coordinates,which is more than 512 bytes
Tsaiet al.proposed lossy compression of feature locations[43].Location coordinates are quantized with a uniform partition of the 2D location space prior to coding(Fig.6b).The quantized location is converted into a location histogram comprising histogram map(Fig.6c)and histogram count(Fig.6d).The histogram map comprises empty and non-empty blocks,and the histogram count is the number of features in each non-empty block.Different block sizes lead to different quantization levels.The histogram map and histogram count are coded separately with context-based arithmetic coding.This scheme reduces bits by a factor of 2.8 compared with fixed-point representation.When run length,quad-tree,and context-based algorithms are compared,context-based coding performs the best,and gain decreases as block size becomes smaller.Run-length coding for a larger block size does not provide any gain.
Tsai's location coding algorithm treats all features equally;however,in real-world applications,a subset of features could be more important for robustness and information fidelity.Compression distortion of important features can be reduced at the risk of increasing distortion for unimportant features.Therefore,an importance map can be placed over an image.Important features are quantized to finer levels,and unimportant features are quantized to coarser levels(Fig.7).The definition of an importance map depends on applications.In our experiments,an importance map is a Gaussian function so that key points near the center of the image are emphasized.This definition is validated in subsequent key-point selection experiments.These experiments show that,compared with Tsai's approach,the importance map approach can reduce bits by 15%without seriously affecting performance(Fig.8)[44].Location coding was one of the core experiments at the 99th MPEG meeting.

▲Figure 8.Localization coding results for mixed datasets from differentmethods.
3.3 Key-Point Selection
Selection criteria may include a key point's location,peak value of DoG response,scale,dominant orientation,or descriptors.We conducted a systematic study[45],and Fig.9 shows some results of feature-point selection using the following approaches:
·Sequential selection.This involves selecting key points continuously from top left to bottom right.
·Spread selection.This involves selecting key points to maximize the spread of the points.
·Center selection.This involves selecting key points near the image center.
·Scale selection or peak selection.This involves selecting key points of larger scales or peak values.
·Fusion selection.This involves using a supervised approach to combine factors for better performance.Key points can be repeatedly detected and matched and are regarded as stable.The stability score of a key point is the number of images containing correctly matched points.A RankSVM2ranking modelis trained to sort key points according to their stability scores[46].
For operating points from 512 bytes to 16 kB,we set the maximum number of key points to 200,350,450,550,and 1000.If the number of key points in an image exceeds the limit,this number needs to be cut down to meet the limit.Four hundred images,including 100 objects from UKBench dataset,were used to generate features for RankSVM training.
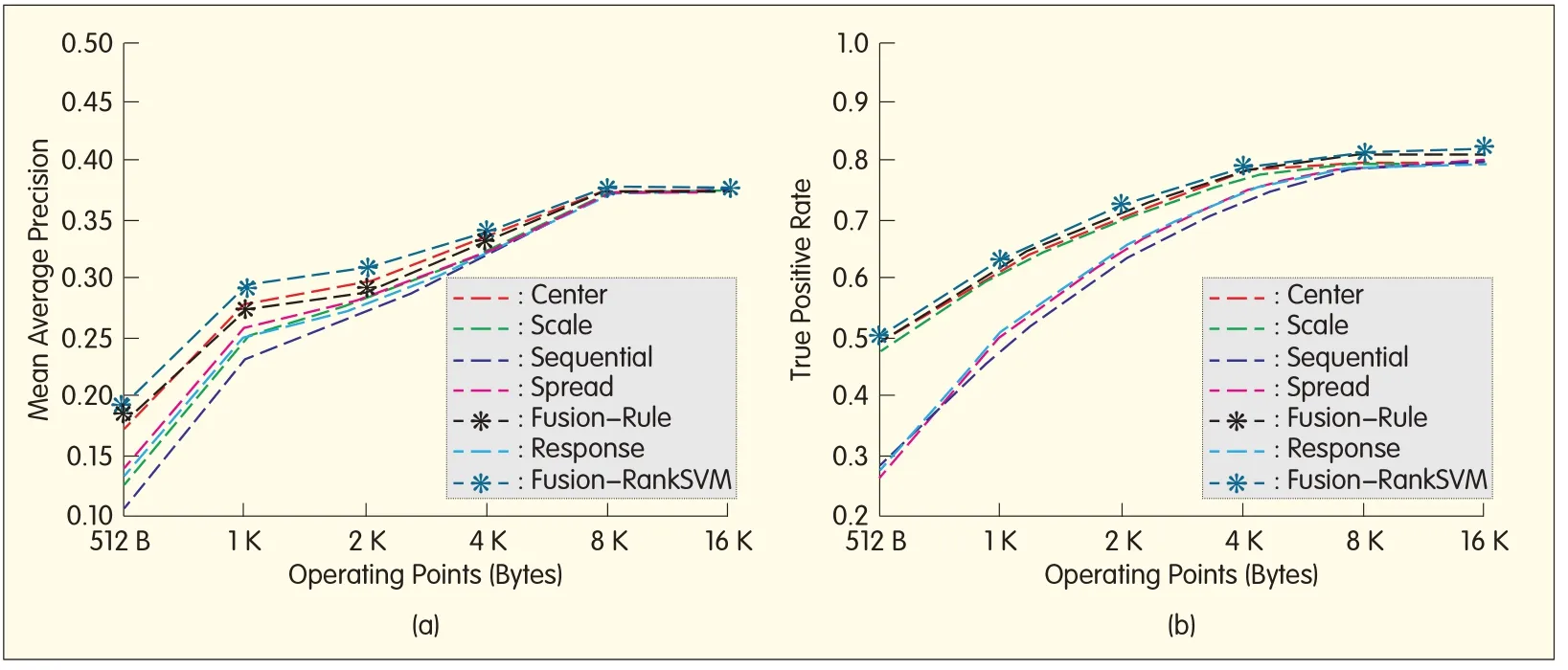
▲Figure 9.(a)Retrieval and(b)matching results with different key-pointselection algorithms.
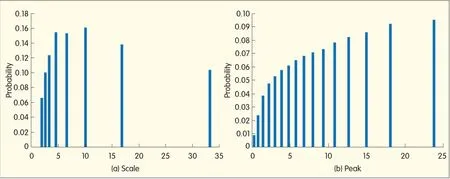
▲Figure 10.Statistics thatare helpful for feature selection:(a)Probability of a correct match as a function of scale.The scale is quantized into eight levels.(b)The probability of a correct match as a function of peak value.
The fusion selection approach performs the best,but center selection is also effective.In matching experiments,center selection and scale selection have about 10-30%gain at 512 bytes and outperform sequentialselection.The gain is less significant when the operating point goes up to 4 kB because there is no need to cut down the number of key points.The performance of peak selection is comparable to that of spread selection,with TPimproved by about 5-10%.Sequential selection performs the worst.Fusion based on RankSVM brings about slight gain,and similar results have been shown in retrieval experiments.However,scale selection performs much worse than center selection.
In summary,key-point selection significantly contributes to pairwise matching and retrieval,especially at very low operating points.Center selection basically works well;however,when the query object is far from the center,this approach is poor.A solution is to combine different factors.
In our model,each key point is characterized by scale,2RankSVM addresses a ranking problem by formulating a classification problem.A binary classifier is learntin order to determine which key pointis better.In training,the goal of optimization is to minimize the average number of inversions on training data.With the learntmodel,we obtain a relative order for any pair of key points.All key points are sorted according to minimum number of inversions(in terms of the predicted relative orders).
In our scenario,each setof training data contains a sequence of images of the same object,which may be shotatdifferentviewpoints or scales.Pairwise matching is applied,and we counthow many images are correctly matched with each feature.We use this number to estimate the feature's importance;the larger the number,the more importantthe feature.Afeature's scale,distance to center,and peak value are concatenated to form a vector to train RankSVM.dominant orientation,peak value of DoG,and distance to center.Using the training model,for each individual factor,we estimate the probability that a feature can be matched correctly to features in other images.Fig.10 shows these estimations based on scale and peak values.The probability of a correct match increases as the scale increases within a certain range,and this is consistent with our hand-crafted rule.The probability decreases as the scale exceeds the limit,and this is not taken into account in our current model.

◀Figure 11.Globalfeature extraction pipeline.
Other models are fused with a naive Bayesian approach;that is,probabilities for allfactors are multiplied to produce a score.Key points of higher scores are selected.
Instead of hand-crafted rules,as in[45],Gianluca et al.[26]exploit the difference statistics for correctly and incorrectly matched key points.The difference statistics are consistent across various large datasets[26].Training data contains images from the Pasadena buildings dataset,INRIA holidays dataset,and additional images of food labels and Italian buildings.Training data also contains video frames from movies.The training set is organized into a list of pairwise matching images.Each image undergoes key-point detection,matching,and geometric consistency check.The actual(true or false)matched pairs of features are grouped as inliers or outliers.Inliers are key points that have been correctly matched,and outliers are key points that have not been matched or have been incorrectly matched.Each feature is labeled according to whether the feature has been matched correctly(value 1)or not(value 0).
Key-point selection is important;however,more in-depth work is needed on how to make optimal combinations of factors.Key-point selection might be a core experiment in the upcoming 100th MPEG meeting.
3.4 Global Descriptors
State-of-the-art visual search applications usually use a BoWmodel based on localfeatures.Chen et al.showed that visual search accuracy can be improved by combining global and local features[9].Aglobal feature is generated from SIFT local descriptors.Some 190 centroids are generated by applying k-means clustering to SIFTdescriptors.Given an image,each SIFTdescriptor is quantized to its nearest centroid.The residual between the descriptor and the centroid is computed.For each centroid,the mean residual between the centroid and allquantized descriptors falling to this centroid is computed.To reduce the dimensions of residuals,linear discriminative analysis(LDA)is applied,and 32 of the most discriminative LDA eigenvectors are retained.The transformed values are binarized by the sign.Experiments show that incorporating global descriptors may improve performance,especially at lower operating points.
PKU has provided evidence that visual search accuracy can be improved by leveraging global descriptors[47].A global descriptor is generated by aggregating SIFT descriptors(Fig.11).For a given image,a subset of SIFTkey points is selected,and each 128-D SIFTdescriptor is reduced to 64-D eigenvectors by applying PCA.AGaussian mixture model(GMM)with 256 Gaussians is trained using an independent dataset.To form a global descriptor,an image is represented as a fixed-size Fisher vector generated from the gradient of the probability of the selected 64-D SIFT descriptors over the mean of the learned GMM.For each Fisher vector,PCA dimensions are reduced,and products are quantized to encode the global feature.When a CDVS evaluation framework is used,experiment results show that applying global descriptors to the retrievalstep and then applying local descriptors to the re-ranking step greatly improves performance at all operating points(Fig.12)[47].
4 Other Issues
Feature indexing,retrieval,and geometric re-ranking may not be included in the MEPG CDVSstandard.Proper handling of these issues will greatly improve retrieval scalability and accuracy.For fast search,database features must be indexed[3],[10]-[12].There are two kinds of indexing approaches.

▲Figure 12.Retrieval performance using combined local and global descriptors,and localdescriptors only on a mixed datasetwith 1 M distracters.
The first approach involves attempting to search for approximate nearest neighbors,for example,k-D tree[3],[10]and locality-sensitive hashing(LSH)[11],[12].The second approach involves a BoWmodel[13]-[15],and greater speed is achieved by quantizing feature space.k-D tree methods outperform BoWmethods in terms of run time and recognition accuracy.However,BoWmethods require much less storage space than k-D tree and LSH methods because inverted indexing based on BoWdoes not require feature vectors to be stored.LSHmethods generally result in better search accuracy than k-D tree methods but are inferior in terms of search time(which increases sharply as the database size increase).In the CDVSevaluation framework,memory use is limited to 16 GB.Neither k-D tree nor LSH is able to load the descriptors of all reference images(including one million distractors)into 16 GB memory.The current TMuC uses the BoWmodel.
In online search,local features in a query image are used to perform nearest-neighbor search.Database images are ranked by a scoring function that represents their visual similarity to nearest neighbors[13]-[15].Post-processing can be used to verify geometric consistency within a subset of top-ranked images[14],[16],[17],and subset images are re-ranked accordingly.Various re-ranking algorithms have been proposed for trading-off between accuracy and time complexity.In[14],spatial verification is used to estimate a transformation between a query region and each target image.Returned images are re-ranked according to discriminability of spatially verified visual words(inliers).In[16],Jegou et al.propose using angle and scale to adjust the similarity score of an image.The score decreases when a visual word is inconsistent with transformation and increases in the presence of consistently transformed points.Compared with re-ranking in[14],re-ranking in[16]is much faster,but there is a risk of higher false positive rate.
In the TMuC,the fast re-ranking algorithm in[17]is slightly modified.Feature pairs are formed by comparing descriptor classification paths in a scalable vocabulary tree,and a geometric verification score is computed for these pairs.A histogram of logarithmic distance ratios(LDRs)for pairs is used in the TMuC.Distribution of LDRs for pairs of inliers is different from that of LDRs of pairs of outliers,which are used to rate geometric consistency.
5 Conclusion
In this paper,we have discussed developments in visual search technologies.These developments include state-of-the-art,low bit rate visualsearch pipeline,and important components such as compact descriptors and efficient image-matching and retrieval algorithms.To facilitate interoperability between visual search applications,MPEG has made great efforts to standardize compact descriptors for visual search.We have reported a CDVS evaluation framework,which is a competitive and collaborative platform for evaluating visual search technologies and solutions and is a benchmark for crucial modules.
Despite significant progress on visual search within academia and industry,a few challenges remain.The size of visualqueries transmitted from a mobile device to servers needs to be minimized because of the bandwidth constraint of(3G)wireless networks.Under the CDVSumbrella,descriptor quantization[26],[27],[31],[32],[37],[41],[42],location coding[43],[44]and key-point selection[37],[45]have been attempted in order to produce more compact descriptors.Approximately 90%of bits can be saved using compact descriptors as opposed to using uncompressed SIFTdescriptors,and search performance is well maintained.In addition,a mobile device is constrained by battery life,so energy saving is crucial for feature extraction and compression.Because mobile phones usually have limited computing capability,operations on a mobile phone must not be too complex.A core experiment that has been set up to reduce quantization table size to less than 5 MB.Moreover,computing DoG is also time-consuming.Aptina[48]provided fast algorithms for key-point detection and descriptor generation,and these algorithms are targeted at system-on-chip(SoC)implementation.However,the robustness of a detector still needs to be evaluated.More importantly,the ongoing MPEG CDVSstandardization has attracted much interest from hardware manufacturers such as Aptina,Nvidia,and STMicroelectronics.
Acknowledgments:
We would like to thank the reviewers for their useful comments.This work was supported by National Basic Research(“973”)Program of China(2009CB320902),and in part by the Chinese National Nature Science Foundation(60902057).

- ZTE Communications的其它文章
- Emerging Technologies for Multimedia Coding,Analysis and Transmission
- Introduction to the High-Efficiency Video Coding Standard
- Recent MPEGStandardization Activities on 3DVideo Coding
- AVS 3DVideo Coding Technology and System
- Configurable Media Codec Framework:AStepping Stone for Fast and Stable Codec Development
- Lattice Vector Quantization Applied to Speech and Audio Coding