
Noise Feedback Coding Revisited:Refurbished Legacy Codecs and New Coding Models
2012-05-22 03:36StphaneRagotBalzsvesiandAlainLeGuyader
ZTE Communications 2012年2期
Stéphane Ragot,Balázs Kövesi,and Alain Le Guyader
(audiOvisual and sPEech foR quAlity(OPERA)Lab.,Orange Labs,Lannion,France)
Abstract Noise feedback coding(NFC)has attracted renewed interest with the recent standardization of backward-compatible enhancements for ITU-TG.711 and G.722.It has also been revisited with the emergence of proprietary speech codecs,such as BV16,BV32,and SILK,that have structures different from CELPcoding.In this article,we review NFC and describe a novel coding technique that optimally shapes coding noise in embedded pulse-code modulation(PCM)and embedded adaptive differential PCM(ADPCM).We describe how this new technique was incorporated into the recent ITU-TG.711.1,G.711 App.III,and G.722 Annex B(G.722B)speech-coding standards.
Keyw ords speech coding;noise shaping;noise feedback coding;G.711;G.722
1 Introduction
N oise shaping is a key technique for improving sound quality in telecommunications and multimedia.Analog noise reduction systems relied on companding/expanding in frequency bands to reduce recording noise from magnetic tapes[1].Pulse-code modulation(PCM)in ITU-T G.711 uses companding/expanding on the time domain magnitude to achieve a near-constant signal-to-noise ratio(SNR)over a large range of input levels[2].Even if PCM does not involve any noise shaping in the frequency domain,it exploits the human perception of an audio signal on a log scale.
In this paper,we describe noise feedback coding(NFC),a well-known noise shaping technique[3]-[5],[6],[7].The goalof NFCis to modify the input signal of scalar quantization by feeding back the filtered coding noise.NFC was introduced to shape the spectrum of the quantization noise in sample-based waveform coders such as PCM coders.A similar principle is used in sigma-delta analog-to-digital(A/D)converters,except that the filter is in the feedforward path[8]instead of the feedback path.NFC has attracted renewed interest with the recent standardization of backward-compatible enhancements to ITU-TG.711 and G.722[9],[10].It has also been revisited with the emergence of proprietary speech codecs such as Broad Voice(BV16 and BV32)[11],[12]and SILK[13],that have structures not based on code-excited linear prediction(CELP)coding.
In this paper,we give an overview of NFC and describe a novelspeech coding method that optimally combines NFC with embedded PCM or adaptive differential PCM(ADPCM).Important applications include the recent backward-compatible enhancements to G.711 and G.722.
In section 2,the principles of and approaches to noise shaping are discussed.In section 3,NFC is discussed in detail.In section 4,embedded coding and noise shaping enhancements to G.711 are described.In section 5,a counterpart to G.722 is proposed.In section 6,new codec structures inspired by NFC are discussed.Section 7 concludes the paper.
2 Noise Shaping Principles and Approaches
The basic idea of noise shaping is to exploit the limitations of the human auditory system,in particular,masking properties,to make coding noise inaudible.Different methods of noise shaping draw on the principles of psychoacoustics[14],[15].In this section,we give an overview of noise shaping in speech coding but not noise shaping in perceptual audio coding.In perceptual audio coding,noise shaping is performed in the frequency or sub-band domains by a masking model that determines appropriate bit allocation[16]-[18].

▲Figure 1.Spectrum of a narrowband female speech sample coded at64 kbit/s and resulting noise with and without noise shaping.
2.1 Noise Shaping in Speech Coding:G.711
Fig.1 shows noise shaping for a real-speech sample taken from a female who was speaking French.Two short-term spectral noise shapes are shown for PCM codecs operating at 64 kbit/s.In Fig.1(a),64 kbit/s PCM coding in G.711(A law)is used[19].The coding noise spectrum,shown in red,is nearly flat,and coding noise fills the low-energy spectral valleys of the input signal,which means the noise is clearly audible.In Fig.1(b),a modified G.711 encoder is used that is backward-compatible with G.711 decoders.The modified G.711 encoder is defined in G.711.1 and has the same 64 kbit/s bit rate as G.711[9],[19].The coding noise spectrum,shown in green,approximates the envelope of the signal spectrum,which means noise is present but barely audible because it has been properly shaped.
From Fig.1(a)and(b),a principle can be derived for perceptually optimizing speech codecs:The coding noise spectrum should approximate the signal spectrum so that a sufficient signal-to-noise ratio is maintained over each frequency range,including ranges where the signal has low energy.
2.2 Noise Shaping at the Encoder:Predictive Speech Coding
Noise shaping in speech coding is implemented according to the underlying coding model.For time-domain waveform coders such as PCM and ADPCM coders,noise can be shaped using NFC[3],[5];however,related standards,such as G.711 and G.722,do not incorporate NFC[2],[20].
The most common low-bit-rate speech coders are based on linear predictive coding(LPC)(short-term prediction)and pitch(long-term prediction).To the best of our knowledge,the first temporal predictive coder that included a short-term and long-term adaptive predictor was the adaptive predictive coder(APC)[21].In this coder,long-term prediction is performed first.If short-term prediction was performed first,the CELPsynthesis model would be obtained[22].Atal and Schroeder recognized the necessity of shaping the quantization noise spectrum:
“The quality of the reconstructed speech can thus be improved by a suitable shaping of the spectrum of the quantizing noise so that the signal-to-noise ratio(SNR)is more or less uniform over the entire frequency range of the input speech signal.”[21]
To achieve this goal,they suggested using a fixed pre-emphasis filter at the encoder side and an inverse filter at the decoder side.
Two important contributions to noise masking in speech coders were[23],[24],and these were extended by[25]-[27].These contributions showed that noise could be shaped at the encoder by subtracting the filtered noise from the quantizer input in a feedback loop.Hence,the technique was called noise feedback coding.
The main significance of[25]was that it showed how quantization noise Q(z)of an APC coder could be shaped by a prediction filter B(z)-1 and how a linear predictive feedback of noise could be added to the input signal to create the quantizer input that is forwarded to an APC coder with noise shg(APC-NS)[25,Fig.9].The reconstructed speechin the local decoder and in the(distant)decoder is obtained by adding the quantization noise,which is filtered by a moving-average(MA)FIRfilter,to the input speech.The reconstruction speech is given by

where S(z)is the input speech,B(z)is the filtered quantization noise,and Q(z)is the quantization noise.
In[6]and[7],the noise masking in ADPCM coding is implemented as in[25,Fig.9].In[26],the quantization noise is filtered by a predictor A(z),and the reconstruction noise is filtered by a predictor B(z).These noises are subtracted to the input signal in the feedback loop[26,Fig.3].Using the notation in[26],an autoregressive moving average(ARMA)noise shape is given by

The configuration in[26,Fig.3]leads to the same noise shaping as that in[25,Fig.9]when B(z)is set to 0.An improvement to[26,Fig.3]is shown in[26,Fig.7],and this improvement gives rise to a generalized predictive coder,including a long-term predictor,with the following short-term noise-shaping characteristics:

where Ps(z)is the linear predictor filter:

and Fs(z)is the weighted filter derived from Ps(z)using the weighting factorγ:

The ARMA noise shaping of the quantization noise Q(z)is usually done by the more flexible filter Hs(z),given by

The same type of noise-shaping filter has been used in the subsequent generation of speech coders,known as analysis-by-synthesis(Ab S)coders,first in multipulse coding[28]and then in CELPcoding[22].Ab Sis equivalent to minimizing the following CELPcriterion[29]:

where C(z)is the past reconstructed excitation signal,gcis the fixed codebook gain,Ck(z)is the code vector,gPis the adaptive codebook gain,T is the adaptive codebook lag,A(z)is the quantized LPC filter,and W(z)is the noise weighting filter(also called perceptual weighting filter).The distortion criterionεis minimized in order to whiten the weighted reconstructed noise(in square brackets,equation 7)and create a coding noise with a spectrum shape
Fig.2 shows the perceptual filter in narrowband predictive coding,and G.729A is used as an example.
The filter W(z)in Fig.2 is optimized so that formants get relatively lower weights;that is,more noise is tolerated in frequency ranges where the signal has more energy and can mask more noise.This masking method assumes that the masker(signal)is sufficiently well reconstructed.
Most narrowband CELPspeech coders,operating at 8 kHz,use a noise-shaping filter with the form W(z)=A(z/γ1)/A(z/γ2)or a version based on the quantized LPCfilter A(z).Eitherγ1orγ2can be set to 0.
In G.729,the filter W(z)=A(z/γ1)/A(z/γ2)is based on the unquantized LPC filter A(z)with adaptive values forγ1andγ2.In G.729A,W(z)is replaced by A(z)/A(z/γ),whereγ=0.75 and A(z)is a quantized LPCfilter used to reduce complexity.In 3GPPAMR-WB,γ2=0 and the weighting filter A(z/γ1),whereγ1=0.92 in the signal domain,corresponds to the effective weighting filter used for CELPcoding in a pre-emphasized signaldomain A(z/γ1)/(1-αz-1),where α=0.68.The cascade of pre-emphasis and LPC filters in AMR-WBis a special case of a technique introduced in[30].The pre-emphasis is set at 1-αz-1,whereαis not adaptive,and the weighting filter is computed only on the second filter of the cascade.

▲Figure 2.Perceptual weighting filter W(z)(γ=0.75)in G.729A.The coding noise spectrum approximates.
For details on predictive speech coding and Ab Sspeech coding(including CELP)see[31]-[34].Starting with the first CELPcoding scheme in[22],the synthesis filters and perceptual weighting filters can be combined in one filter[35],which results in the filtering matrix H and a matrix form of the CELPerror criterion.The CELPcodebook search can be further improved by backward filtering[36],using binary algebraic codes[36]-[38],or by using sparse algebraic codes that give rise to an algebraic CELP(ACELP)model[39],[31,section 17.11].The first real-time fixed-point implementation of an algebraic CELPcoder,including noise shaping,was reported in[38].
2.3 Noise Shaping at the Decoder Side
Noise shaping for coded speech can be performed at the decoder side using a postfilter after the speech decoder[40].Areview of postfilering for CELPcoders,including formant postfiltering,pitch postfilering,and gain control is given in[41].Postfiltering is based on speech-signal model parameters(LPC and pitch)that are available in typical LPC-based speech decoders but not in PCM or ADPCM coders.The underlying principle of postfiltering is to reinforce signal components and redistribute coding noise.Such filtering is described in G.729 and G.729A.In 3GPP AMR-WB,some quality-enhancement techniques are used inside the speech decoder,that is,in the LPC residual domain prior to LPC synthesis.
Noise reduction can also be used to improve quality at the decoder side.When a statisticalmodel is available for coding noise,good results can be obtained[42],[43].Strictly speaking,this technique is not a form of noise shaping but is a reduction of the noise levelby adaptive spectralattenuation,and extra delay is usually required for frequency-domain analysis and processing.If the noise is shaped at the encoder side,the resulting noise shapes need to be taken into account in decoder-side postprocessing.
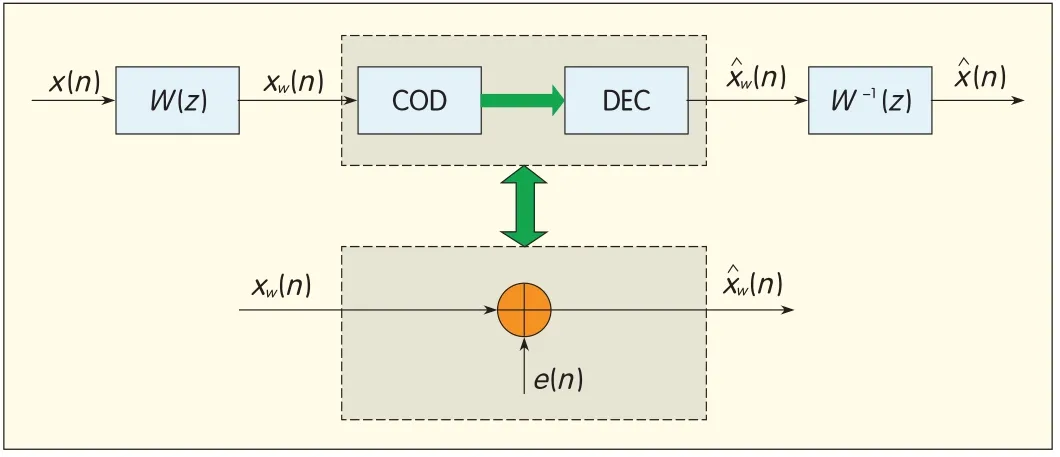
▲Figure 3.Noise shaping by pre/postprocessing.
2.4 Joint Encoder and Decoder Noise Shaping
Fig.3 shows the principle of noise shaping by prefiltering and postfiltering.If the codec is modeled using an additive noise model,the decoded signalis

Noise shaping is decoupled from actualquantization or coding.The(inner)encoder-decoder can be optimized to minimize mean-square error,and the resulting coding error E(z)has a nearly flat spectrum.The overallcoding noise is then shaped according to the frequency response of W-1(z).In practice,this basic linear modelis only an approximation because the filter coefficients are adapted per frame,and the actual process is non-linear.
Joint encoder/decoder processing is used in the transform coded excitation(TCX)model[44]and transform predictive coding(TPC)model[45].The perceptual filter W(z)is typically defined for LPC-based noise shaping:

The decoder needs to revert the preprocessing;therefore,the coefficients of A(z)are quantized of the linear predictive filter.This contrasts with the perceptualfilters discussed in section 3,which can use unquantized coefficients.
A similar idea was explored in[46]for audio coding.In[47],an LPCfilter derived from a model-based masking curve(a function of LPC and pitch)was investigated.In[48],the LPC-based perceptual weighting filter in TCXcoding is modified in the frequency domain by adaptive low-frequency emphasis.This is done to improve the quality of some high-pitched music signals.In[49],combined companding and expanding at 48 kbit/s in the spectral domain results in the same quality as G.722 at 64 kbit/s[20],[50].However,this technique implies that backward compatibility with existing coders is lost with the introduction of the new,improved coder,and extra delay and complexity are required for frequency-domain processing.
3 Noise Feedback Coding
In this section,we define NFC by detailing different filter structures.We also address the related problems of noise-shaping filter estimation and loop stability.The following notation is used:
x(n):input signal to(outer)encoder x′(n):input signal to(inner)encoder(modified signal including noise feedback)sl reconstructed by(inner)local decoder e(n)=-x(n):overall coding noise(or reconstructionnoise)q(n)=x(n)-x′(n):inner coding noise(or quantization noise)
3.1 Moving-Average Structure
Fig.4 shows noise fed back using a moving-average(MA)filter structure.The quantization noise q(n)is the error introduced by the inner encoder-localdecoder(COD-Local DEC)and is given by

The input signal x(n)is modified by adding the quantization noise filtered by HA(z)-1.The signal X′(z)is given by
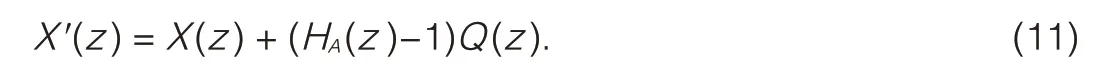
Replacing X′(z)with X(z)and Q(z)gives

Therefore,the overall reconstruction error X(z)-X(z)is the quantization noise q(n)shaped by the filter HA(z).If the bitrate is sufficient,the quantization noise can be considered white noise,and the spectrum of the reconstruction noise is close to
The value ep(n)corresponds to a prediction because the filter HA(z)-1 has a zero coefficient in z0,that is,for sample n.This property indicates that the loop filter is an MApredictor for the next quantization error,and this prediction is based on past samples of the quantization error signal q(n).
As in an APC coder,the inner coding noise-x′(n)is the quantization noise q(n).Fig.4 can be considered a generalization of[25,Fig.9]and[26,Fig.3 where A=0]because the noise feedback loop has been moved outside the coder.This is true when COD is a linear predictive coder without noise shaping,as in the original APC[21],PCM[2],and ADPCM[20]schemes.The structure in Fig.4 allows the introduction of noise shaping in these legacy codecs as external pre-processing,and the COD-Local DEC loop is not affected.

▲Figure 4.Noise feedback with moving-average structure.
▲Figure 5.Noise feedback with auto-regressive structure.
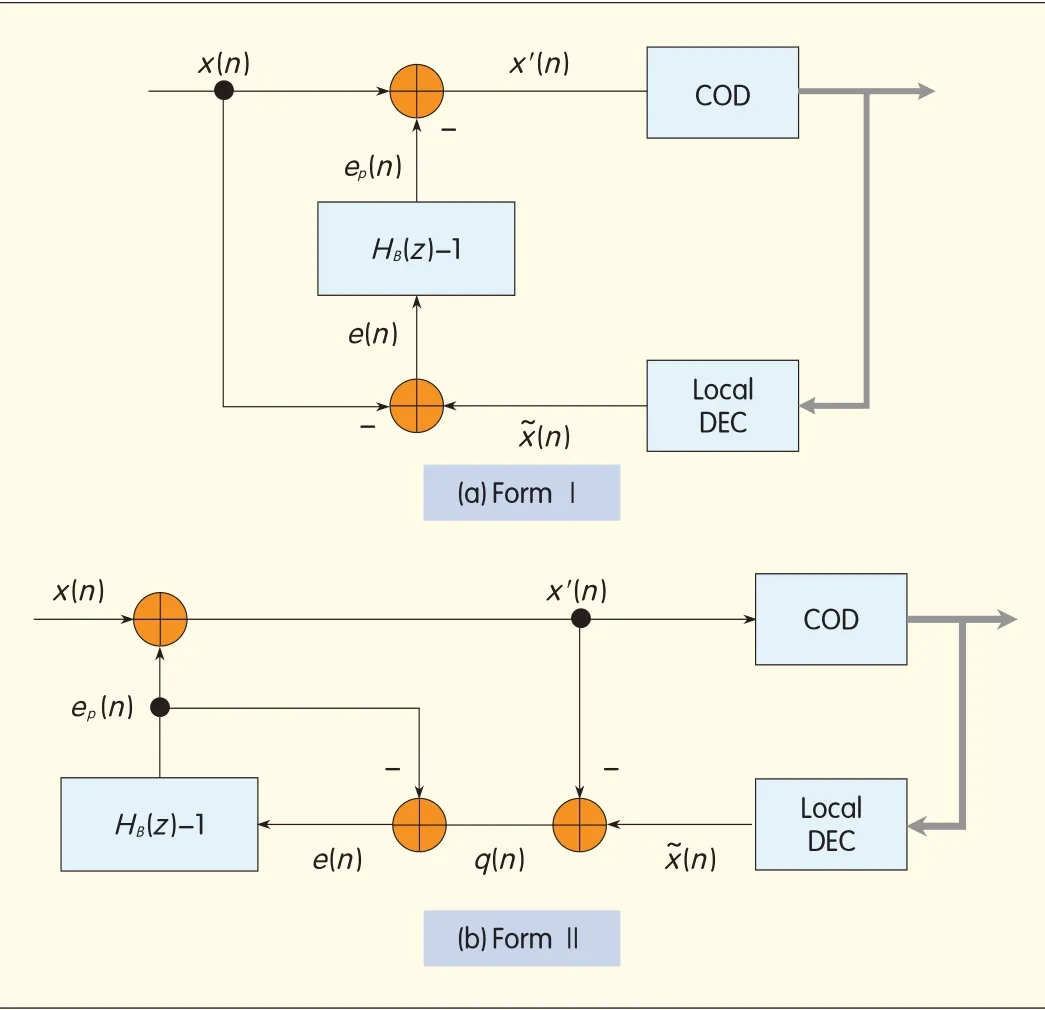
3.2 Auto-Regressive Structure
Fig.5 shows two equivalent auto-regressive(AR)filter structures.In form I,the decoded signal=X′(z)+Q(z)can be expanded:

which yields

Form IIgives the same result.The main advantage of form I is that it saves one subtraction per sample compared with form II.
Fig.5(a)is a special case of[26,Fig.3],where A=0 and the feedback loop has again been moved outside the
COD-Local DEC loop.Form IIis the same as that in Fig.4 when

Here,the loop filter is an ARpredictor for the next quantization error,and the prediction is based on past samples of the coding noise e(n).
3.3 Auto-Regressive Moving-Average Structure
Combining the structures in Figs.4 and 5(a)gives a general auto-regressive moving-average(ARMA)structure(Fig.6).The coding noise is given by

The noise shaping in Fig.6 can also be obtained using the structure in Figs.4 and 5(a)by introducing an ARMApredictor in the feedback loop and computing the noise prediction from the past quantization noise and reconstructed noise,as in[51,Figs.4 and 5].In[51,Fig.5]ARMAlong-term noise shaping was included in the feedback loop to improve the performance of legacy PCM and ADPCM coders for voice signals.
3.4 Loop Filter Design:HA and HB
The simplest design for the loop filter includes a fixed filter,such as HA(z)=1+z-1.In this case,the effective quantization noise is colored in a predefined way.For speech or audio signals,this approach is generally not optimal,and it is better to adapt the loop filter to the short-term spectral properties of the input signal[5].A detailed analysis using high-rate distortion theory(i.e.smallerrors)shows that,with certain assumptions,the optimal loop filter whitens the input signal[5].Hence,a linear predictive(LP)analysis can be used for loop-filter estimation.In[25]and[26],LPC techniques were used to obtain the weighting filters from the linear predictive coefficient.In[52],the weighting filter is an LPC filter computed on the adaptively pre-emphasized speech signal.
Because noise feedback is implemented at the encoder side,the loop filter estimation can be based on the original signal x(n).In cases such as embedded PCM,where a core coder and enhancement stages depend on the loop filter at both the encoder and decoder sides,it can bneficial to estimate the filter on the decoded core signal).This is the case of G.711.1,where the loop filter is estimated through an LPanalysis on the decoded core signal SL0(n)at the encoder and decoder.In G.722,the LPanalysis is done on the input signal x(n).
3.5 Loop Stability

▲Figure 6.Noise feedback with ARMAstructure.
As in any system with feedback,the noise feedback loop may become unstable in certain conditions.The quantization process is non-linear,and this makes it difficult to model the loop behavior.For the loop transfer function to be stable,the NFC transfer function must have its poles inside the unit circle.Astability analysis of the APCcoder with a parametric model of the APC system can be found in[53].
In[54],stability was analyzed for the embedded ADPCM with noise feedback.Perceptual input/output SNRof the coder is given by

▲Figure 7.AG.711.1 encoder[58].

where GPis the ADPCM prediction gain,SNRQis the SNRof the quantizer(about 24 d Bfor a 5-bit quantizer),and EDis the impulse response energy of the masking filter Hs(in the general case).When SNRPis low,the ADPCM coder is close to being unstable.
Because of this problem,the order of the loop filter is usually small.In recent G.711.1 and G.722B standardization work,an ARstructure is used with a loop filter of order 4,and some heuristic methods have been developed that limit loop instability by detecting specific signals,for example,chirps and combinations of sinusoids and frequency hops.These signals create instability or degrade performance compared with having no feedback.Stability issues are mitigated by detecting such signals,and the noise-shaping filter resonances are attenuated or the loop is turned off for a period of time[9],[10],[54].
4 Improving G.711 by Using Embedded PCM Coding with Noise Shaping
G.711[2]is the most widely deployed speech codec in fixed networks and voice-over-IP(VoIP)networks.In[2],the input linear PCM is coded at 8 bits/sample using either A-law or aμ-law.In 2007,ITU-TSG16 started a work item called G.711-WB(wideband)under the initiative of NTT.The objective of this work was to develop a 64-80-96 kbit/s embedded extension of G.711 that was low-delay,low-complexity,and capable of 50-7000 Hz wideband[55].The principles of embedded PCM,ADPCM,CELPcoders,and hierarchical coders such as G.729.1[56]can be found in[57].
4.1 Principle of G.711.1
The G.711.1 encoder receives 8 kHz or 16 kHz input signals.The input is divided into 5 ms frames.The encoding bit rate can be set at 64 kbit/s,80 kbit/s,or 96 kbit/s.The input signalis decomposed into two sub-bands using a quadrature mirror filter bank(QMF).The 0-4000 Hz lower band is coded by an embedded PCM encoder that is interoperable with G.711(Fig.7).The 4000-8000 Hz higher band is coded in the modified discrete cosine transform(MDCT)domain.
The bitstream structure of G.711.1 is defined in Table 1.More details on G.711.1 can be found in[9],[58].
4.2 Embedded PCM Coding Without Noise Shaping
The PCM coding in[2]is similar to the scientific notation;a given number of bits(resolution)in linear PCM is retained to form the mantissa,and an exponent value gives the correct scaling.In G.711,which has 8 bits per sample,5-bit precision is used for the signed mantissa,and this results in approximately 38 d B SNR(except for the smallest values in the first segment).The most significant bit(MSB)is always 1 in natural binary decomposition;therefore,it does not need to be transmitted.Only the next 4 bits(after MSB)are sent to the decoder;one bit is reserved for the sign,and the remaining 3 bits are used to encode 8 possible exponent values(segment indices).
In G.711.1,a 16 kbit/s,2 bit/sample enhancement layer was introduced to enhance the 0-4000 Hz lower band.In[55],two extra mantissa bits of the binary representation of input samples are extracted and transmitted to the extension layer,which gives an overall resolution of 6 bits in the first segment and 7 bits in the other segments.In the final tuning phase of G.711.1 standardization,a dynamic bit allocation was taken to allocate 1,2 or 3 bits per sample to the frame bit budget[9].
4.3 Embedded PCM Coding with Noise Shaping
In the 0-4000 Hz lower band of G.711.1,noise shaping was introduced to PCM coding to improve the quality of the interoperable core bitrate mode at 64 kbit/s and to improve the quality of the enhanced high-bitrate mode at 80 kbit/s.Inthis way,the 64 kbit/s core layer of G.711.1 can be decoded by a legacy G.711 decoder,and the quality of G.711 encoding and decoding can be significantly improved,especially for low-level clean speech.

▼Table 1.Bitstream structure of G.711.1
In the G.711.1 encoder,noise shaping is performed on the core-layer signal using the form IARstructure(Figs.5(a)and 7).The decoded core coder output is given by

The enhancement layer is defined in section 4.1,and noise shaping had to be performed on the enhancement signal at the decoder before being added to the core decoded signal.To prevent a mismatch between the decoder and the encoder,the perceptual filter F(z)in Fig.7 is calculated using the past decoded core signal available at both encoder and decoder side[51],[52].
In the encoder,the quantization noise of the core layer filtered by F(z)is fed back to be added to the input signal encoded using embedded PCM coding(Figs.5a and 7).Therefore,if the decoder decodes only the core layer,the quantization noise is already shaped when it is decoded by a G.711 decoder.If the enhancement layer is also decoded,the enhancement-layer contribution,that is,the difference between the core bitrate output and the higher bitrate output,has to be shaped at the decoder.It is thus shaped by the noise shaping filter 1/(1+F(z))prior to being added to the core layer output.Noise shaping is performed at the encoder side for the core layer and at the decoder side for the enhancement layer[51],[52].
In the G.711.1 core layer,the ordinary log-PCM encoding is replaced by a dead-zone quantizer encoding scheme[9,clause 7.3.3].Another way to enhance the quality of the PCM coding and reduce the perceptual impact of PCM quantization noise is to postfilter quantization noise at the decoder[42].This technique is detailed in[9,Appendix I].
4.4 G.711 App.III:Noise Shaping as Preprocessing to G.711 and Other Tools
Noise shaping was incorporated into the 64 kbit/s core coder in G.711.1;however,it can also be performed externally as preprocessing to G.711.This preprocessing approach,together with other tools such as the postfiltering of G.711.1 App.I,form G.711 Appendix III[19].
5 Improving G.722 by Using Embedded ADPCM Coding with Noise Shaping
G.722 was the first normalized 50-7000 Hz wideband(WB)speech codec[20].This coder is based on a sub-band embedded ADPCM coding scheme[50].The input signal of G.722,sampled at 16 kHz,is decomposed by a QMFinto two sub-bands:0-4000 Hz and 4000-8000 Hz.Each sub-band is coded separately using ADPCM coding.The totalbit rate is 64,56 or 48 kbit/s,depending on the number of bits allocated to the lower band.The block diagram of the G.722 encoder and decoder can be found in[50,Figs.9 and 12].G.722 is the wideband codec specified for DECTnew Generation(DECT-NG)terminals,which are also called Cordless Advanced Technology—Internet and quality terminals.This codec provides better audio quality than the legacy narrowband DECTcodec(G.726).To further improve call quality,50-14,000 Hz superwideband(SWB)coding is the next step.In 2008,the ITU-Tlaunched the G.711.1/G.722 SWB work item under the initiative of France Telecom and NTT.This activity resulted in G.722 Annex B(G.722B)[10],[59].We focus here on improvements made to G.722 as part of G.722B development.The principle of embedded coding is explained in[57].

▲Figure 8.Bitstream structure of G.722B.
5.1 Principle of G.722 Annex B
G.722-SWB standardization is aimed at developing an embedded scalable SWB extension of G.722 operating at 64,80,and 96 kbit/s.The 64 kbit/s bit rate of G.722B was specifically designed to fit into existing 64 kbit/s CAT-iq transport channels which comprise wideband G.722 at 56 kbit/s and 8 kbit/s for an SWB enhancement layer.Fig.8 shows the embedded bitstream structure of G.722B.Here we only discuss the part of G.722B that corresponds to the G.722 core bitstream layer at 56 kbit/s and 64 kbit/s.
The main objective of G.722Bis to extend G.722 to SWB.As with G.711.1,it was necessary to improve G.722 because artifacts in the lower band are reinforced when higher-band extensions are added.At 64 kbit/s,G.722B operates with a 56 kbit/s G.722 core coder that has an 8 kbit/s enhancement layer split into a G.722 high-band enhancement(EL0)and an SWBenhancement(SWBL0).At 80 or 96 kbit/s,G.722B operates with a 64 kbit/s G.722 core coder that has two high-band enhancement layers:G722EL0 and G722EL1,and three SWBenhancement layers:SWBL0,SWBL1,and SWBL2.
As shown in Fig.9,the G.722B coder includes an enhanced G.722 coder for the wideband(WB)part,which enhances the G.722 4000-8000 Hz higher band,and a bandwidth extension in the MDCTdomain.
In the original G.722 coder[20],[50],the lower sub-band is coded by an embedded ADPCM coder at 6,5 or 4 bit/sample,and the higher sub-band is coded by an ADPCM coder at 2 bit/sample.G.722 relies on plain ADPCM coding with no noise shaping.In the following,we describe the G.722 lower-band(LB)coder and the G.722 higher-band(HB)coder,including noise shaping.
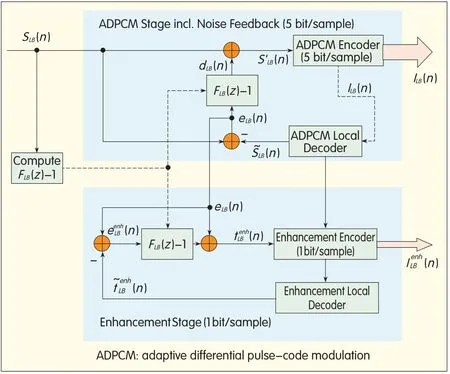
▲Figure 10.Lower band coding in G.722B.
5.2 Improved 0-4000 Hz Lower-Band Embedded ADPCM Coding Including Noise Feedback
Fig.10 shows a modified LB ADPCM coder,including noise shaping.In the case of G.722B at 64 kbit/s,the G.722 LB encoder operates at 5 bit/sample,and in the case of G.722B at 80 or 96 kbit/s,the G.722 LB encoder operates at 6 bit/sample.To shape the coding noise at 5 and 6 bit/sample in a coherent and optimal way,embedded ADPCM coding is modified so that it operates in two optimal stages.A noise feedback loop is included in the first stage,and Ab Sis done in the second stage.Therefore,a noise feedback loop is used with the ADPCM coder operating at a reduced bitrate of 40 kbit/s(5 bit/sample).In Fig.10,noise shaping is performed on the core layer signal using form Iof the ARstructure shown in Fig.5(a).The COD is an ADPCM coder with 5 bit/sample,and the Local DEC is an ADPCM local decoder with 5 bit/sample.An enhancement encoder using Ab Sand operating at 1 bit/sample brings the bit rate to 48 kbit/s(6 bits/sample)[10],[60].
Thus,the modified G.722 LBencoder relies on embedded scalar quantization,which is done by Ab Sin a perceptually weighted domain.Both stages use the same noise shaping filter FLB(z)-1 derived from a linear predictive coding(LPC)filter FLB(z)with an order of 4.
5.3 Improved 4000-8000 Hz Higher-Band ADPCM Coding(G.722 HB and EL0/EL1)
Fig.11 shows the HBencoder.The core G.722 HB encoder corresponds to the G.722 HBADPCM encoder operating at 16 kbit/s(2 bit/sample).The ADPCM signal-to-noise ratio in the higher band is low because the allocated bitrate is 2 bit/sample as opposed to 5 or 6 bit/sample for G.722 LB ADPCM coding.This difference in bitrate means that contrary to the G.722 lower band,no noise feedback is used in higher-band ADPCM coding.For noise feedback to be efficient,a bit rate higher than 2 bit/sample is desirable.If additional bit rate is available to improve the quality of the G.722,these extra bits are allocated to the higher band.The quantization resolution can be improved by the enhanced G.722 HBencoder,which relies on embedded scalar quantizers of 0.475 bit/sample(EL0)and 1 bit/sample(EL1).
The G.722 HB ADPCM encoder can be extended by a scalable or embedded bitstream.This extension is done in two embedded stages using Ab S,which is similar to the approach used for low-band enhancement.The first extension stage,G722EL0,is performed at 3.8 kbit/s,and 19 of the 40 samples are used only in non-transient frames to enhance quality with 1 bit/sample.This forms the G722EL0 layer,which is used in all superwideband layers(Fig.8).The G722EL0 layer is disabled in the case of transient signal segments,where the spare 19 bits are allocated to SWB extension.The second extension stage,G722EL1,is performed at 8 kbit/s(1 bit/sample)to further refine the quantization of the G.722 higher band,and this forms the G722EL1 layer that is only used in G.722B at 96 kbit/s.
5.4 Analyzing the Core Coder Enhancement Layer with Analysis-by-Synthesis in Embedded ADPCM Coding
Here,we explain how the LB embedded ADPCM coder in G.722 Annex B[10]is modified to allow backward-compatible noise shaping.As described in Section V.Bof the G.722 standard,the G.722 LD encoder is split into a core coder with noise shaping at 56 kbit/s(5 bit/sample)and an Ab Senhancement to reach 6 bit/sample.
The legacy ADPCM localdecoder at 5 bit/sample reconstructs the output signal by adding the scaled ADPCM quantizer output at 5 bit/sample to the prediction obtained at 4 bit/sample.To obtain the 6th bit in the legacy coder(without noise shaping),the embeddedness of the ADPCM quantizer can be used to find the two scaled and adequate 6-bit quantizer levels.The predicted signalcan be added to the quantizer output to give two possible synthesized signals,and then a search can be done to determine which of the two signals is the closest to the input signal sLB(n).Ab Sis done to find the extension layers of the core coder bit by bit,and it does not involve any noise shaping.
To introduce a weighted-error criterion[60],the extension-stage error criterion is

where SLB(z)is the core coder reconstructed signal,ξLB(z)is the z-transform of the enhancement output signal,and W(z)is the weighting filter equal to.The signal(z)is equal to the past outputs of the enhancement layer for n′<n,that is,n)in Fig.10,and is equal to the ith enhancement candidate[10,B.6-32].The noise spectrum of SLB(z)(z)at theoutput of the enhancement stage has the shap.The signal SLB(z)-(z)in the bracket in the error criterion is equal to eLB(n)in Fig.10.
Although the coding structure in Figs.10 and 11 use AbS,this technique is quite different from CELPcoding because the sample-by-sample gain is provided by the core layer.Also,for each sample n,the enhancement codebook is obtained from the ADPCM index of the core layer and the possible preceding enhancement layers.It is obtained using the embeddedness of the ADPCM quantizers[10,B.6-32].
The same method can be used for the high-band ADPCM encoding.Because the method is based on Ab Swith noise shaping,the results can be extended to minimize error of(Eq.19)on a block basis and to increase the efficiency of the noise shaping.If care is taken in embedded quantization,the reconstructed,enhanced codebook with two entriesn)i=0,1(19)can be extended to a binary algebraic tree codebook,which allows fast algorithms to be derived for minimizing the error criterion[61].Computation load is only slightly increased.Therefore,it is possible to further improve the quality of the G722EL0 and G722EL1 layers.
5.5 Experimental Results
In the official ITU-Ttests for G.722B,only SWB cases were tested.In[62],some additional wideband tests were done to assess the backward compatibility of G.722Bwith G.722.
6 New Codec Structures
The principles of noise feedback were recently revisited in an effort to develop new codec structures,for example,BV16,BV32[11],[12]and SILK[13].
6.1 BV16 and BV32 Coders
The BV16 and BV32 coders[11],[12]are based on a synthesis model that includes a long-term(LTP)synthesis filter and a short-term(LPC)synthesis filter.The first predictive speech codecs that used noise shaping[25],[26]relied on a scalar quantization and a short-term noise-feedback filter to shape the spectral envelope of the coding noise.In contrast,the two-stage noise feedback coding(TSNFC)in[11]and[12]relies on two NFC stages in a nested loop.In the first NFC stage,short-term prediction and short-term noise spectral shaping(spectral envelope shaping)is performed.In the second(nested)NFC stage,long-term prediction and long-term noise spectral shaping(harmonic shaping)is performed.
In Fig.12,the long-term noise shaping predictor Nl(z)-1 is located around the quantizer,as in[25,Fig.7].This implies MA long-term noise shaping by Nl(z).The short-term noise-shaping predictor Fs(z)acts on the noise of the long-term quantizer loop so that the noise is shaped by
1-Fs(z).Thus,the short term filter 1-Ps(z)is a pre-emphasis,and the coding noise is shaped b[21].To more precisely describe the z-transform of the overall system,the output speech is given in terms of the input:

MA long-term noise shaping and ARMA short-term noise shaping depend on the LPC predictor Ps(z),so the amount of noise shaping is obtained from the damping factorγused in Fs(z).An alternative ARMA long-term noise shaping and more flexible ARMA short-term noise shaping is described in[51,Fig.5].Further details on the BV16 or BV32 coders can be found in[11],[12]and[31].
6.2 SILK Coder
SILK is a speech codec designed for VoIP[13].The synthesis model for a SILK coder is based on a long-term synthesis filter and a short-term synthesis filter.The excitation signal is obtained by range-coded quantization,which is similar to arithmetic-coded quantization.Fig.13 shows the noise shaping of the SILK codec.

▲Figure 12.Noise shaping in BV32 coder.

▲Figure 13.SILKcoder.
The noise-shaping predictor W2(z)is in a feedback path around an inner coder.This inner coder has a generalized predictor filter P(z)that includes LPC and LTP.Therefore,the quantization noise Q(z)is filtered b.The filter 1-W1(z)acts as a pre-filter whose inverse is not present in the local decoder,as in the classical pre-filter in[21].As a consequence,the spectralcontent of the input speech is
modified by the codec.This can be confirmed by writing the input/output z-transform of Fig.13 as

If G is set at 1 and W1(z)=W2(z),the coder of Fig.5(a)is obtained.Noise shaping in SILK involves modifying the input signal.This is similar to postfiltering the input as in[41],where the filter has a short-term and long-term section and gain is controlled by G,and shaping the noise,as in NFC.
The SILK noise shaping structure can be obtained by transforming the structure in Fig.5(a).In the structure in Fig.5(a),noise is shaped in the vector case by minimizing the weighted error criterion between the input and output signals.The structure in Fig.13 allows the levels of the decoded speech formants to be matched with the levels of the original speech formants.The levels of the spectral valleys are decreased relative to the levels of the spectralpeaks,including speech formants and harmonics.To obtain both long-term and short-term noise shaping,W1(z)and W2(z)should be of the form

where SHi=1,2(z)is the short-term predictor and LTi=1,2(z)is the long-term predictor.Then Wi=1,2(z)appears to be the product of the short-term and long-term inverse filters minus one.
7 Conclusion
Two applications of NFC were described:the improvement of existing coders,for example,G.711 and G.722 by making them backward-compatible,and the development of new codec structures that are alternatives to the ubiquitous CELPcoding model.
The improvement of legacy codecs is an important research topic,and significant gains are possible with refurbished codecs.Versions of G.711 and G.722 using both encoder-side and decoder-side techniques have been standardized by the ITU-T[9],[10],[19].
As part of enhanced voice standardization(EVS),3GPP SA4 is also considering improving the 3GPPAMR-WB standard by making it bit-stream interoperable.
Acknowledgment
The authors would like to thank colleagues involved in the ITU-TG.711.1 and G.711.1/G.722-SWBwork as well as one reviewer for helpful comments to improve this article.

- ZTE Communications的其它文章
- Emerging Technologies for Multimedia Coding,Analysis and Transmission
- Introduction to the High-Efficiency Video Coding Standard
- Recent MPEGStandardization Activities on 3DVideo Coding
- AVS 3DVideo Coding Technology and System
- Configurable Media Codec Framework:AStepping Stone for Fast and Stable Codec Development
- Lattice Vector Quantization Applied to Speech and Audio Coding